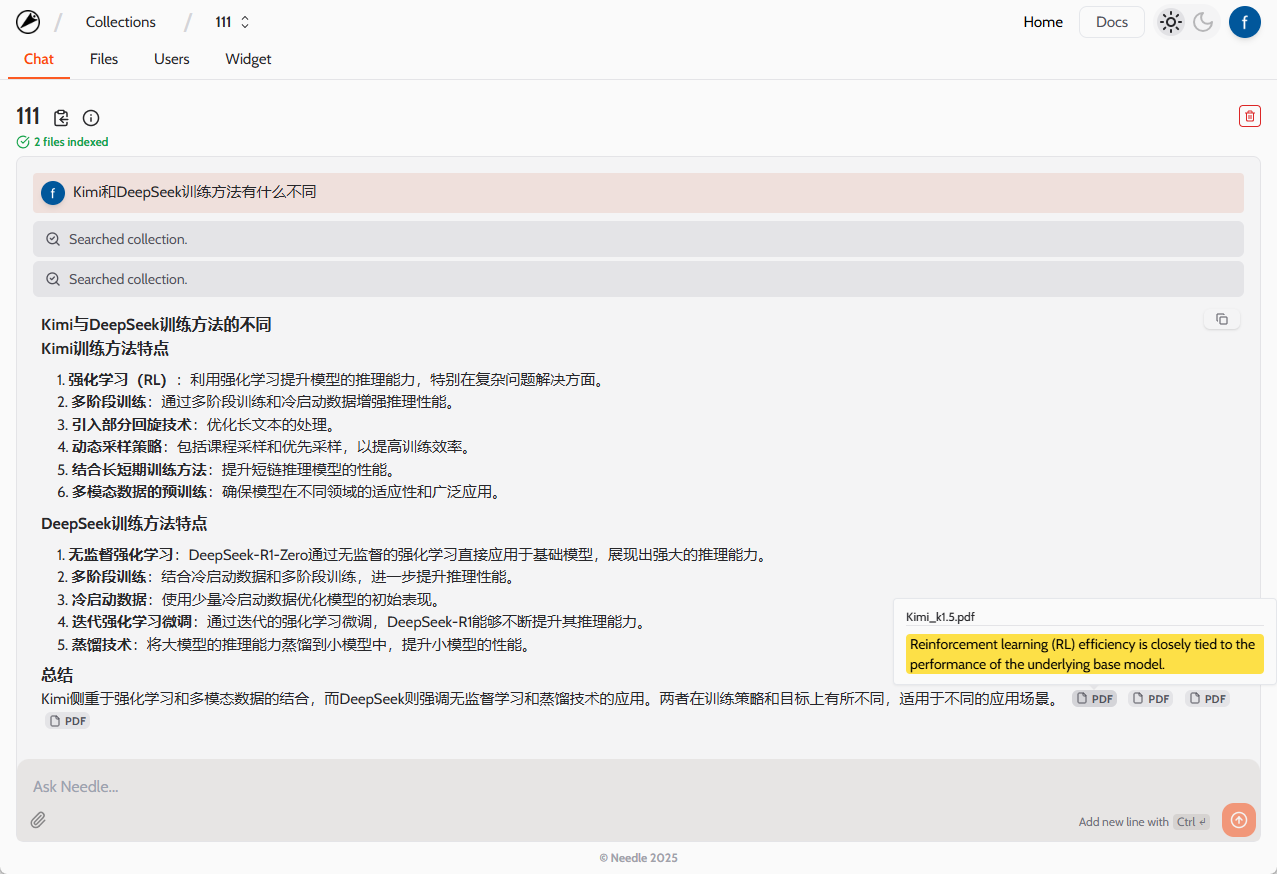
DualPipe: 대규모 AI 모델 학습의 효율성을 향상시키는 양방향 파이프라인 병렬 알고리즘(DeepSeek 오픈 소스 주간 4일차)

일반 소개
DualPipe는 대규모 AI 모델 학습의 효율성 향상에 초점을 맞춰 DeepSeek-AI 팀이 개발한 오픈 소스 기술입니다. 이는 혁신적인 양방향 파이프라인 병렬 알고리즘으로, 주로 DeepSeek-V3와 R1 모델 훈련에서 계산과 통신의 완전한 중복을 달성하여 파이프라인의 '버블'(즉, 대기 시간)을 효과적으로 줄여 훈련 과정을 가속화하는 데 사용됩니다. Jiashi Li, Chengqi Deng, Wenfeng Liang이 개발한 이 프로젝트는 GitHub에서 오픈 소스화되어 AI 커뮤니티의 주목을 받고 있습니다. DualPipe의 핵심 장점은 최적화된 스케줄링을 통해 멀티노드 GPU 클러스터에서 모델 훈련을 효율적으로 실행할 수 있어 수조 개의 파라미터 모델 훈련 시나리오에 적합하고 AI 연구자와 개발자에게 새로운 가능성을 제공한다는 점입니다. 듀얼파이프는 AI 연구자와 개발자를 위한 새로운 병렬 패러다임을 제공합니다.
기능 목록
- 양방향 파이프라인 스케줄링파이프라인 양쪽 끝에서 마이크로 배치의 동시 입력을 지원하여 계산과 통신 간의 고도의 중첩을 가능하게 합니다.
- 조립 라인 기포 감소알고리즘 최적화를 통해 훈련 중 유휴 대기 시간을 줄입니다.
- 대규모 모델 트레이닝 지원이 시스템은 DeepSeek-V3와 같은 초대형 모델에 적용하여 수조 개의 매개변수 학습 요구에 대응할 수 있습니다.
- 계산 및 통신 중첩연산 및 통신 작업을 순방향 및 역전파 방식으로 병렬 처리하여 GPU 활용도를 향상시킵니다.
- 오픈 소스 지원개발자가 자유롭게 다운로드, 수정 및 통합할 수 있는 완전한 Python 구현이 제공됩니다.
도움말 사용
DualPipe는 개발자를 위한 고급 도구로, 독립형 그래픽 인터페이스는 없지만 코드 베이스로 사용할 수 있는 GitHub 오픈 소스 프로젝트입니다. 아래는 개발자가 빠르게 시작하고 AI 학습 프로젝트에 통합하는 데 도움이 되는 자세한 사용 가이드입니다.
설치 프로세스
DualPipe를 설치하려면 기본적인 Python 및 딥 러닝 환경이 필요합니다. 단계는 다음과 같습니다:
- 환경 준비
- 시스템에 Python 3.8 이상이 설치되어 있는지 확인합니다.
- GitHub에서 코드를 다운로드하려면 Git을 설치하세요.
- 다음 명령과 종속성 충돌을 피하려면 가상 환경을 사용하는 것이 좋습니다:
python -m venv dualpipe_env source dualpipe_env/bin/activate # Linux/Mac dualpipe_env\Scripts\activate # Windows
- 복제 코드 리포지토리
터미널에 다음 명령을 입력하여 듀얼파이프 리포지토리를 로컬로 다운로드합니다:git clone https://github.com/deepseek-ai/DualPipe.git cd DualPipe
- 종속성 설치
DualPipe는 일반적인 딥 러닝 라이브러리에 의존하며, 특정 종속성은 저장소에 명시적으로 나열되어 있지 않지만 기능에 따라 PyTorch와 같은 환경이 필요한 것으로 가정합니다. 다음 명령어를 사용해 기본 종속 요소를 설치할 수 있습니다:pip install torch torchvision특정 라이브러리가 누락되었다는 오류가 발생하면 안내에 따라 추가 설치를 진행하세요.
- 설치 확인
DualPipe는 독립형 애플리케이션이 아닌 알고리즘 코드이므로 직접 검증을 실행할 수 없습니다. 그러나 코드 파일(예dualpipe.py)를 클릭하여 다운로드가 완료되었는지 확인합니다.
사용법
듀얼파이프의 핵심은 스케줄링 알고리즘으로, 개발자가 기존 모델 트레이닝 프레임워크(예: PyTorch 또는 DeepSpeed)에 통합해야 합니다. 작동 방식은 다음과 같습니다:
1. 코드 구조 이해
- 쇼(티켓)
DualPipe폴더에 있는 경우, 메인 코드는dualpipe.py또는 이와 유사한 문서에 있습니다. - 알고리즘 로직을 이해하려면 코드 주석과 DeepSeek-V3 기술 보고서(GitHub 리포지토리 설명에 링크)를 읽어보세요. 이 보고서에는 DualPipe 스케줄링 예제(예: 8개의 파이프라인 수준 및 20개의 마이크로배치)가 언급되어 있습니다.
2. 교육 프레임워크에 통합
- 모델 및 데이터 준비파이토치 기반 모델과 데이터 세트가 이미 있다고 가정합니다.
- 교육 주기 수정하기: 듀얼파이프의 스케줄링 로직을 트레이닝 코드에 삽입합니다. 다음은 간단한 예시입니다:
# 伪代码示例 from dualpipe import DualPipeScheduler # 假设模块名 import torch # 初始化模型和数据 model = MyModel().cuda() optimizer = torch.optim.Adam(model.parameters()) data_loader = MyDataLoader() # 初始化 DualPipe 调度器 scheduler = DualPipeScheduler(num_ranks=8, num_micro_batches=20) # 训练循环 for epoch in range(num_epochs): scheduler.schedule(model, data_loader, optimizer) # 调用 DualPipe 调度 - 구현은 실제 코드에 맞게 조정해야 하며, GitHub 리포지토리에 있는 예제(있는 경우)를 참조하는 것이 좋습니다.
3. 하드웨어 환경 구성하기
- DualPipe는 멀티노드 GPU 클러스터용으로 설계되었으며 최소 8개 이상의 GPU(예: NVIDIA H800)와 함께 사용하는 것이 좋습니다.
- 통신 최적화의 이점을 최대한 활용하려면 클러스터가 InfiniBand 또는 NVLink를 지원하는지 확인하세요.
4. 운영 및 시운전
- 터미널에서 교육 스크립트를 실행합니다:
python train_with_dualpipe.py - 로그 출력을 관찰하고 계산과 통신이 성공적으로 겹치는지 확인합니다. 성능 병목 현상이 있는 경우 마이크로 배치 수 또는 파이프라인 수준을 조정하세요.
주요 기능 작동
양방향 파이프라인 스케줄링
- 구성 파일 또는 코드에서 설정
num_ranks(파이프라인 레벨 수) 및num_micro_batches(마이크로 배치 수). - 구성 예시: 8단계, 20개 마이크로 배치, 기술 보고서의 스케줄링 다이어그램을 참조하세요.
전산 통신 중첩
- 수동으로 개입할 필요 없이 DualPipe는 자동으로 양수 계산을 수행합니다(예
F)를 역으로 계산(예B) 중복되는 커뮤니케이션 작업을 제거합니다. - 로그의 타임스탬프를 확인하여 통신 시간이 계산에 숨겨져 있는지 확인합니다.
조립 라인 기포 감소
- 마이크로배치 크기를 조정(예: 20개에서 16개로)하고 훈련 시간의 변화를 관찰하여 최적의 구성을 찾았습니다.
주의
- 하드웨어 요구 사항단일 카드로는 듀얼파이프의 장점을 충분히 활용할 수 없으므로 멀티 GPU 환경을 권장합니다.
- 문서 지원GitHub 페이지에는 현재 정보가 부족하므로 DeepSeek-V3 기술 보고서(arXiv: 2412.19437)와 함께 자세히 살펴볼 것을 권장합니다.
- 커뮤니티 지원GitHub 이슈 페이지에서 질문하거나 X 플랫폼에서 관련 토론을 참조하세요(예: @deepseek_ai의 게시물).
개발자는 이 단계를 따라 듀얼파이프를 프로젝트에 통합하고 대규모 모델 훈련의 효율성을 크게 향상시킬 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...