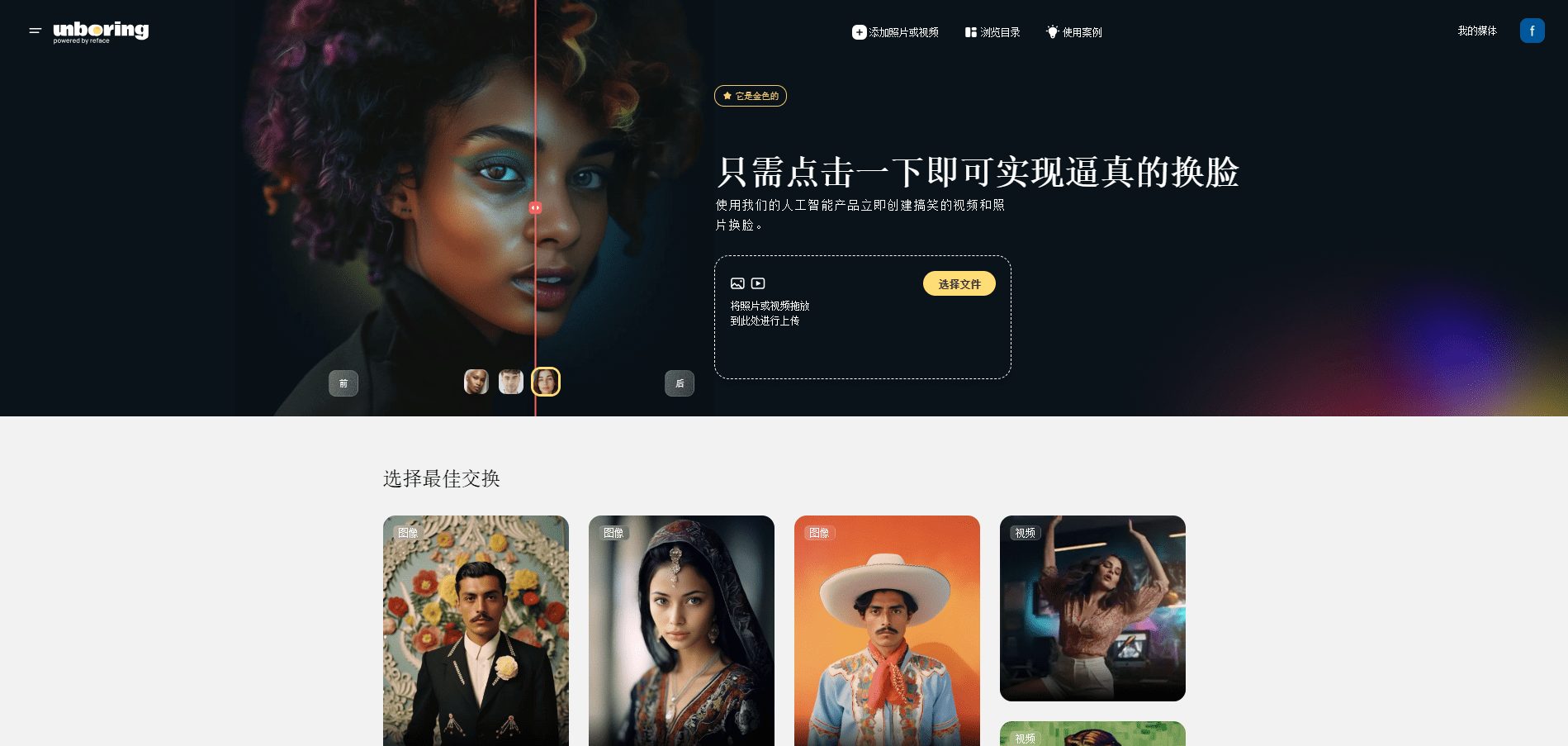

일반 소개
Describe Anything은 NVIDIA와 여러 대학에서 개발한 오픈 소스 프로젝트로, 그 핵심은 DAM(Describe Anything Model)입니다. 이 도구는 사용자가 이미지나 동영상에 표시한 영역(예: 점, 상자, 그래피티, 마스크)을 기반으로 자세한 설명을 생성합니다. 정지 이미지의 세부 사항을 설명할 뿐만 아니라 시간에 따른 동영상 속 영역의 변화도 캡처합니다.

기능 목록
- 다양한 영역 라벨링 방법 지원: 사용자는 점, 상자, 낙서 또는 마스크로 이미지 또는 동영상의 설명 영역을 지정할 수 있습니다.
- 이미지 및 동영상 설명: 정지 이미지에 대한 자세한 설명을 생성하거나 동영상의 특정 영역에서 동적 변화를 분석할 수 있습니다.
- 오픈 소스 모델 및 데이터 세트: 공동 이미지 및 비디오 처리를 지원하기 위해 DAM-3B 및 DAM-3B-Video 모델을 사용할 수 있습니다.
- 대화형 인터페이스: Gradio를 통해 웹 인터페이스가 제공되어 사용자가 마스크를 그리고 실시간으로 설명을 받을 수 있습니다.
- API 지원: 다른 애플리케이션에 쉽게 통합할 수 있도록 OpenAI 호환 서버 인터페이스를 제공합니다.
- DLC-벤치 평가: 이 영역에 설명된 모델의 성능을 평가하기 위한 전문 벤치마킹 도구가 포함되어 있습니다.
- SAM 통합: 운영 효율성을 높이기 위한 자동 마스크 생성을 위한 통합 SAM(Segment Anything) 모델(옵션)입니다.
도움말 사용
설치 프로세스
디스크립트 애니씽은 Python 환경에서 설치할 수 있으며, 종속성 충돌을 피하기 위해 가상 환경을 사용하는 것이 좋습니다. 자세한 설치 단계는 다음과 같습니다:
- Python 환경 만들기::
Python 3.8 이상을 사용하여 새 가상 환경을 만듭니다:python -m venv dam_env source dam_env/bin/activate # Linux/Mac dam_env\Scripts\activate # Windows
- 무엇이든 설명하기 설치::
두 가지 마운팅 옵션이 있습니다:- 핍을 통해 직접 설치하세요:
pip install git+https://github.com/NVlabs/describe-anything - 리포지토리를 복제하여 로컬에 설치합니다:
git clone https://github.com/NVlabs/describe-anything cd describe-anything pip install -v .
- 핍을 통해 직접 설치하세요:
- 세그먼트 아무거나 설치(선택 사항)::
마스크를 자동으로 생성해야 하는 경우 SAM 종속성을 설치해야 합니다:cd demo pip install -r requirements.txt - 설치 확인::
설치가 완료되면 다음 명령을 실행하여 성공 여부를 확인합니다:python -c "from dam import DescribeAnythingModel; print('Installation successful')"
사용법
Describe Anything은 명령줄 스크립팅, 대화형 인터페이스, API 호출 등 다양한 방법으로 사용할 수 있습니다. 다음은 주요 기능에 대한 자세한 안내입니다:
1. 대화형 라디오 인터페이스
그라디오 인터페이스는 초보자에게 적합하며 사용자가 이미지를 업로드하고 마스크를 수동으로 그려서 설명을 얻을 수 있습니다.
- 실행 인터페이스::
다음 명령을 실행하여 Gradio 서버를 시작합니다:python demo_simple.py명령이 실행되면 브라우저는 로컬 웹 페이지(일반적으로
http://localhost:7860). - 절차::
- 이미지 업로드: 업로드 버튼을 클릭하여 로컬 이미지 파일을 선택합니다.
- 마스크 그리기: 브러시 도구를 사용하여 이미지의 관심 영역에 원을 그립니다.
- 설명 가져오기: 제출을 클릭하면 '빨간 털을 가진 개, 은색 인식표 목걸이를 하고 뛰고 있음'과 같이 해당 지역에 대한 자세한 설명이 시스템에 생성됩니다.
- SAM 통합 옵션: SAM을 활성화하면 이미지의 점을 클릭하면 시스템이 자동으로 마스크를 생성합니다.
- 주의::
- 이미지가 RGBA 형식이고 마스크가 알파 채널을 통해 처리되었는지 확인합니다.
- 설명의 세부 수준은 매개변수를 조정하여 조정할 수 있습니다(예
max_new_tokens) 제어.
2. 명령줄 스크립트
명령줄 스크립트는 일괄 처리 또는 개발자가 사용하기에 적합하며 유연성이 뛰어납니다.
- 이미지 설명::
다음 명령을 실행하여 이미지에 대한 설명을 생성합니다:python examples/dam_with_sam.py --image_path <image_file> --input_points "[[x1,y1],[x2,y2]]"예시:
python examples/dam_with_sam.py --image_path dog.jpg --input_points "[[500,300]]"시스템은 마스크를 생성하고 지정된 지점을 기반으로 설명을 출력합니다.
- 동영상 설명::
연합 모델을 사용하여 비디오 처리하기:python examples/query_dam_server_video.py --model describe_anything_model --server_url http://localhost:8000 --video_path <video_file>프레임에 영역을 지정하기만 하면 시스템이 자동으로 영역 변경을 추적하고 설명합니다.
- 매개변수화::
--temperature: 설명의 창의성을 제어하며 권장 값은 0.2입니다.--top_p: 다양성 생성을 제어하며 권장 값은 0.9입니다.--max_new_tokens설명의 최대 길이를 설정합니다(기본값은 512).
3. API 호출
Describe Anything은 다른 애플리케이션에 통합하기에 적합한 OpenAI 호환 API를 제공합니다.
- 서버 시작::
다음 명령을 실행하여 DAM 서버를 시작합니다:python dam_server.py --model-path nvidia/DAM-3B --conv-mode v1 --prompt-mode focal_prompt서버는 기본적으로
http://localhost:8000. - 요청 보내기::
Python 및 OpenAI SDK를 사용하여 요청을 보냅니다:from openai import OpenAI client = OpenAI(base_url="http://localhost:8000", api_key="not-needed") response = client.chat.completions.create( model="describe_anything_model", messages=[ {"role": "user", "content": [ {"type": "image_url", "image_url": {"url": "data:image/png;base64,<base64_image>"}}, {"type": "text", "text": "Describe the region in the mask"} ]} ] ) print(response.choices[0].message.content)상호 호환성
<base64_image>이미지에 대한 Base64 인코딩.
4. DLC-벤치 평가
DLC-Bench는 영역 설명 모델을 평가하기 위한 벤치마킹 도구입니다.
- 데이터 세트 다운로드::
git lfs install git clone https://huggingface.co/datasets/nvidia/DLC-Bench - 운영 평가::
다음 명령을 사용하여 모델 출력을 생성하고 평가합니다:python get_model_outputs.py --model_type dam --model_path nvidia/DAM-3B결과는
model_outputs_cache/폴더.
주요 기능 작동
- 초점 프롬프트DAM은 초점 프롬프트 기술을 사용하여 글로벌 이미지 컨텍스트와 로컬 영역 세부 정보를 결합하여 보다 정확한 설명을 생성합니다. 사용자는 프롬프트를 수동으로 조정할 필요가 없으며 시스템이 자동으로 최적화합니다.
- 게이트 교차 주의게이트 교차 주의 메커니즘을 통해 모델은 복잡한 장면에서 특정 영역에 집중하여 관련 없는 정보의 간섭을 피할 수 있습니다.
- 비디오 모션 설명프레임에 특정 영역을 표시하기만 하면 DAM이 자동으로 해당 영역이 동영상에서 어떻게 변화하는지 추적하고 설명합니다(예: "소의 다리 근육이 속도에 따라 강하게 움직입니다").
애플리케이션 시나리오
- 의료 이미지 분석
의사는 무엇이든 설명하기를 사용하여 CT나 MRI와 같은 의료 이미지의 특정 영역에 주석을 달아 진단에 도움이 되는 자세한 설명을 생성할 수 있습니다. 예를 들어, 폐의 비정상적인 부위에 라벨을 지정하여 "가장자리가 흐릿한 불규칙한 음영 영역, 염증일 가능성이 있음"이라고 설명할 수 있습니다. - 도시 계획
기획자는 항공 동영상을 업로드하여 건물이나 도로 구역에 라벨을 붙이고 "밀집된 상업용 건물로 둘러싸인 넓은 4차선 고속도로"와 같은 설명을 얻을 수 있습니다. 이는 도시의 레이아웃을 분석하는 데 도움이 됩니다. - 콘텐츠 제작
동영상 제작자는 무엇이든 설명하기를 사용하여 "날개를 펴고 날아가는 독수리, 배경에 눈 덮인 산"과 같은 동영상 클립의 특정 개체에 대한 설명을 생성할 수 있습니다. 이러한 설명은 캡션 또는 스크립팅에 사용할 수 있습니다. - 데이터 어노테이션
데이터 과학자는 DAM을 사용해 이미지나 동영상에 있는 객체에 대한 설명을 자동으로 생성할 수 있으므로 수동 라벨링의 필요성을 줄일 수 있습니다. 예를 들어, 데이터 세트에서 차량에 라벨을 붙이면 '빨간 차, 헤드라이트 켜짐'이라는 문구가 생성됩니다.
QA
- 디스크립트 애니씽은 어떤 입력 형식을 지원하나요?
PNG, JPEG와 같은 일반적인 이미지 형식과 MP4와 같은 동영상 형식이 지원됩니다. 이미지는 알파 채널로 지정된 마스크가 있는 RGBA 모드여야 합니다. - 설명의 정확성을 높이려면 어떻게 해야 하나요?
보다 정밀한 마스크(예: SAM을 통해 자동 생성된 마스크)를 사용하고temperature노래로 응답top_p매개변수를 사용하여 설명의 창의성과 다양성을 제어할 수 있습니다. - 실행하려면 GPU가 필요하나요?
가속 추론에는 NVIDIA GPU(예: RTX 3090)를 사용하는 것이 좋지만 CPU도 느린 속도로 실행할 수 있습니다. - 동영상에서 멀티프레임 설명을 처리하는 방법은 무엇인가요?
한 프레임에 영역을 표시하기만 하면 DAM이 자동으로 후속 프레임에서 해당 영역이 어떻게 변화하는지 추적하고 설명합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...