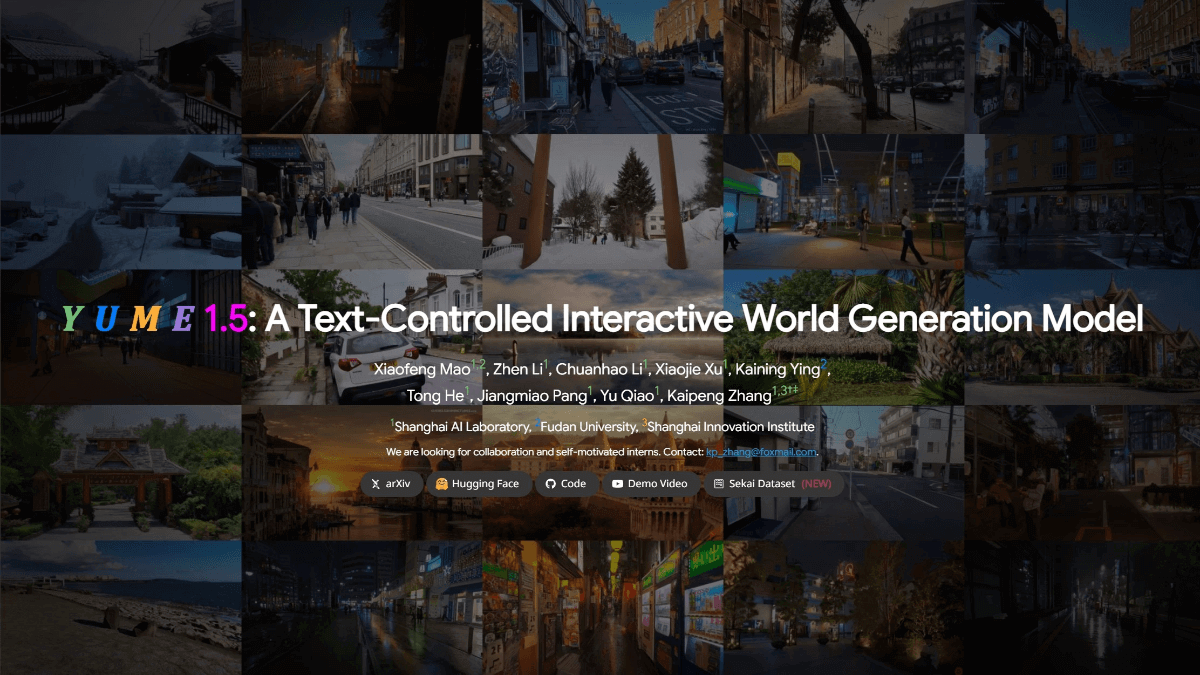

뎁스 애니씽 3란 무엇인가요?
뎁스 애니씽 3(DA3)은 바이트 점프 시드 팀이 개발하여 오픈소스화한 3D 시각적 재구성 모델입니다. 단일 트랜스포머 아키텍처를 통해 모든 시점에서 공간 형상 재구성을 달성하기 위해 깊이 맵과 광선 맵만 예측하면 3D 장면을 복원할 수 있으며, 기존 방식에 비해 35.7%의 정확도, 126 FPS의 작동 효율을 향상시키고, 멀티태스킹 모듈 없이 "깊이-광선" 통합 특성화 방법을 사용하여 단일 사진에서 멀티뷰 비디오까지 지원하는 것이 혁신적입니다. 이 모델은 멀티태스킹 모듈 없이도 단일 이미지에서 멀티뷰 비디오까지 유연하게 처리할 수 있으며 자동 주행, SLAM 및 기타 시나리오에 적용할 수 있습니다. 이 모델은 시각적 지오메트리 벤치마크에서 기존 방식보다 우수한 성능을 보였으며 관련 코드와 데모가 공개되었습니다.

뎁스 애니씽 3의 특징
- 미니멀리즘 건축 디자인복잡한 아키텍처 수정 없이 단일 공통 변환기(예: DINOv2)를 백본 네트워크로 사용하여 효율적인 공간 지오메트리 예측.
- 뎁스 라이트 표현복잡한 카메라 포즈 추정 문제를 심도-조명 표현을 통해 픽셀 수준의 예측 작업으로 단순화하여 복잡한 멀티태스크 학습을 피하고 모델의 일반성과 정확성을 향상시킵니다.
- 뛰어난 멀티태스킹 성능단안 깊이 추정, 멀티뷰 깊이 추정, 카메라 포즈 추정 등 여러 작업에서 우수한 성능을 발휘하여 VGGT 및 DA2와 같은 이전 최고의 모델을 종합적으로 능가합니다.
- 강력한 일반화 기능모든 모델은 공개 학술 데이터 세트만을 사용하여 학습되며 실내, 실외, 객체 중심, 현장 시나리오 등 다양한 시나리오에 적용할 수 있으며 일반화 성능이 우수합니다.
- 유연한 모델 범위다양한 응용 시나리오의 요구 사항을 충족하기 위해 메인 제품군(광범위한 시각 기하학 작업에 적합), 메트릭 제품군(메트릭 깊이 추정 중심), 단안 제품군(고품질 단안 깊이 추정 중심) 등 다양한 모델 제품군을 사용할 수 있습니다.
- 사용자 친화적인 코드 기반대화형 웹 UI와 유연한 명령줄 인터페이스(CLI)를 지원하며, 다양한 출력 형식(예
glb및npz, 깊이 이미지 등)를 사용하여 연구 및 실용적인 애플리케이션 개발을 용이하게 합니다. - 고품질 3D 재구성 및 렌더링가상 현실, 증강 현실 및 기타 영역에서 임의의 시점으로 고품질 3D 재구성 및 시각적 렌더링을 생성하는 기능은 시각적 지오메트리 작업을 강력하게 지원합니다.
뎁스 애니씽의 핵심 이점 3
- 미니멀리즘 아키텍처백본 네트워크로 단일 공통 컨버터(예: DINOv2)를 사용하면 복잡한 아키텍처를 수정할 필요 없이 효율적이고 간단한 모델링이 가능합니다.
- 뎁스 라이트 표현심도-광 표현을 도입하면 복잡한 카메라 포즈 추정 문제를 픽셀 수준 예측 작업으로 변환하여 복잡한 기하학적 변환과 멀티태스크 학습을 피할 수 있습니다.
- 뛰어난 성능단안 깊이 추정, 멀티뷰 깊이 추정, 카메라 포즈 추정 등 여러 작업에서 DA3는 VGGT 및 DA2와 같은 이전 최고 모델을 종합적으로 능가하여 기하학적 및 포즈 정확도를 크게 향상시킵니다.
- 강력한 일반화 기능공개 학술 데이터셋만을 사용하여 학습된 DA3는 실내, 실외, 객체 중심, 현장 시나리오 등 다양한 시나리오에 적응할 수 있어 강력한 일반화 기능을 보여줍니다.
- 다양한 멀티태스킹 기능단안 깊이 추정, 멀티뷰 깊이 추정, 카메라 포즈 추정, 3D 가우시안 추정과 같은 여러 시각 지오메트리 작업을 각 작업마다 별도로 학습할 필요 없이 단일 모델로 수행할 수 있습니다.
- 고품질 3D 재구성가상 현실, 증강 현실 및 기타 애플리케이션을 위해 모든 시점에서 고품질 3D 재구성 및 시각적 렌더링을 지원하여 충실도 높은 시각 효과를 제공합니다.
- 사용자 친화적대화형 웹 UI와 유연한 명령줄 인터페이스(CLI)를 제공하고, 다양한 출력 형식을 지원하며, 연구 및 실용적인 애플리케이션 개발을 용이하게 합니다.
- 확장성코드 베이스는 유연하게 설계되어 향후 새로운 기능의 연구 및 통합을 지원하므로 사용자가 필요에 따라 쉽게 사용자 지정하고 확장할 수 있습니다.
뎁스 애니씽 3의 공식 웹사이트는 무엇인가요?
- 프로젝트 웹사이트:: https://depth-anything-3.github.io/
- GitHub 리포지토리:: https://github.com/ByteDance-Seed/depth-anything-3
- arXiv 기술 논문:: https://arxiv.org/pdf/2511.10647
- 온라인 경험 데모:: https://huggingface.co/spaces/depth-anything/depth-anything-3
뎁스 애니씽 3의 대상
- 컴퓨터 비전 연구원여러 시각 기하학 작업에서 DA3의 뛰어난 성능은 깊이 추정, 카메라 포즈 추정, 3D 재구성과 같은 영역을 탐구하는 연구자에게 강력한 도구가 될 수 있습니다.
- 인공 지능 개발자유연한 아키텍처와 강력한 기능을 통해 AI 개발자는 DA3를 다양한 프로젝트에 빠르게 통합하여 효율적인 시각적 지오메트리 처리를 수행할 수 있습니다.
- 가상 현실(VR) 및 증강 현실(AR) 개발자DA3는 모든 시점에서 고품질 3D 재구성 및 시각적 렌더링을 생성하여 몰입감 넘치는 VR 및 AR 경험을 제작하는 데 적합합니다.
- 3D 모델링 및 애니메이션 전문가DA3가 제공하는 고품질 3D 재구성 기능은 3D 모델러와 애니메이터가 고정밀 3D 모델을 빠르게 생성하고 작업 효율성을 높일 수 있도록 도와줍니다.
- 문화유산 보존가DA3의 3D 재구성 기능은 문화유산의 디지털 보존에 활용되어 유적지와 유물을 문서화하고 재구성하는 데 도움이 됩니다.
- 건축 및 엔지니어링 전문가DA3는 다양한 장면의 3D 재구성을 처리할 수 있으며 건축 설계, 엔지니어링 시각화 및 시공 모니터링에 적합합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...