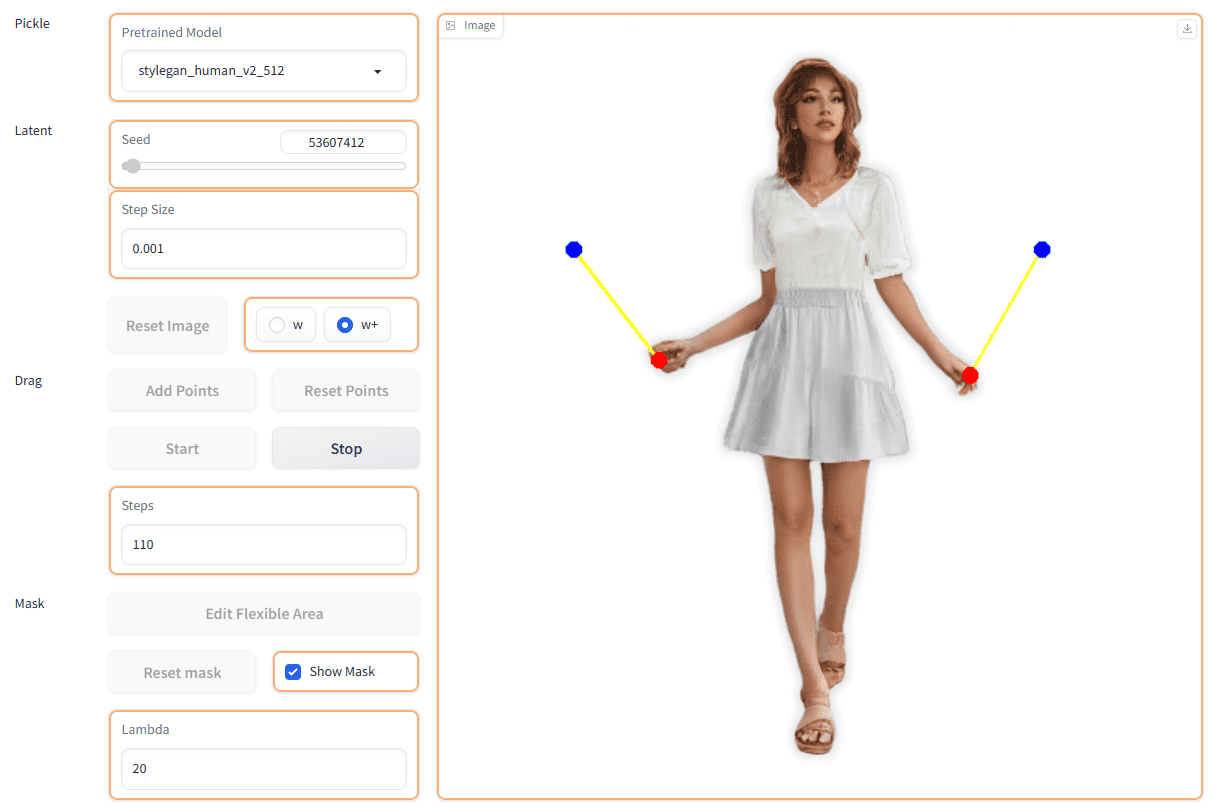

일반 소개
딥 리콜은 대규모 언어 모델(LLM)을 위해 설계된 오픈 소스 엔터프라이즈급 메모리 프레임워크입니다. 효율적인 컨텍스트 검색 및 통합을 통해 초개인화된 응답성을 제공합니다. 이 프레임워크는 메모리 서비스, 추론 서비스, 코디네이터를 포함한 3계층 아키텍처를 채택하고 GPU에 최적화된 추론 및 벡터 데이터베이스 통합을 지원하며, 딥 리콜은 클라우드 및 로컬 배포에 모두 적합하고 자동화된 확장을 통해 고성능과 안정성을 보장합니다. 모델의 상황 인식을 향상시킬 뿐만 아니라 사용자 기록과 선호도에 따라 맞춤형 응답을 생성하므로 고도로 개인화된 상호 작용이 필요한 시나리오에 이상적입니다.

기능 목록
- 효율적인 문맥 검색: 과거 사용자 상호 작용에서 관련 정보를 빠르게 추출합니다.
- 개인화된 응답 생성: 사용자 선호도 및 과거 데이터를 기반으로 맞춤형 응답을 생성합니다.
- GPU 최적화 추론: GPU를 사용하여 추론 프로세스를 가속화하고 처리 속도를 개선합니다.
- 벡터 데이터베이스 통합: 대규모 벡터 데이터의 효율적인 저장 및 쿼리를 지원합니다.
- 자동 확장: 다양한 부하 수요에 맞춰 리소스 할당을 동적으로 조정할 수 있습니다.
- RESTful API 지원: 메모리 관리 및 검색을 위한 편리한 인터페이스를 제공합니다.
- 종합적인 모니터링 및 유지관리: 안정적인 시스템 운영을 보장하는 모니터링 도구가 내장되어 있습니다.
- 보안 스캐닝 시스템: 종속성 스캐닝, 코드 분석 등을 통해 코드 보안을 보장합니다.
도움말 사용
설치 프로세스
딥 리콜을 사용하려면 Python을 지원하는 환경에서 관련 종속 요소를 설치하고 구성해야 합니다. 자세한 설치 단계는 다음과 같습니다:
- 복제 코드 리포지토리
터미널에서 다음 명령을 실행하여 딥 리콜 소스 코드를 가져옵니다:git clone https://github.com/jkanalakis/deep-recall.git cd deep-recall - 가상 환경 만들기
종속성 충돌을 피하려면 Python 가상 환경을 만드는 것이 좋습니다:python -m venv venv source venv/bin/activate # Linux/macOS venv\Scripts\activate # Windows - 종속성 설치
프로젝트에 필요한 런타임 및 개발 종속성을 설치합니다:pip install -r requirements.txt pip install -r requirements-dev.txt - 프리 커밋 훅 구성하기
코드 품질을 보장하려면 사전 커밋 훅을 설치하세요:pre-commit install - 설치 확인
설치가 완료되면 테스트 케이스를 실행하여 환경이 올바르게 구성되었는지 확인할 수 있습니다. 프로젝트의CONTRIBUTING.md파일을 실행하여 테스트 명령을 실행합니다:pytest
주요 기능
1. 문맥 검색 및 개인화된 응답
딥 리콜의 핵심 기능은 사용자의 상호작용 이력을 기반으로 개인화된 응답을 생성하는 것입니다. 사용자가 RESTful API를 통해 메모리 서비스를 호출하면 시스템이 벡터 데이터베이스에서 관련 컨텍스트를 검색하고 현재 입력에 따라 응답을 생성합니다. 단계는 다음과 같습니다:
- API 호출POST 요청을 사용하여 다음 주소로 메시지를 보냅니다.
/memory/retrieve엔드포인트가 사용자 ID와 쿼리를 전송합니다. 예시:curl -X POST http://localhost:8000/memory/retrieve \ -H "Content-Type: application/json" \ -d '{"user_id": "user123", "query": "推荐一部电影"}' - 응답 처리API는 개발자가 직접 파싱하여 사용자에게 표시할 수 있는 컨텍스트와 생성된 응답이 포함된 JSON 데이터를 반환합니다.
- 구성 개인화: 구성 파일에서
config/memory_config.json를 사용하여 컨텍스트 창 크기 또는 유사성 임계값과 같은 검색 매개 변수를 조정할 수 있습니다.
2. GPU에 최적화된 추론
딥 리콜은 훨씬 빠른 처리를 위해 GPU 가속 추론을 지원합니다. 시스템에 CUDA 및 관련 드라이버가 설치되어 있는지 확인해야 합니다. 구성 단계:
- GPU 종속성 설치: 설치하는 동안 다음을 확인합니다.
requirements.txtPyTorch와 같은 GPU 관련 라이브러리가 올바르게 설치되었습니다. - 추론 서비스 시작: 프로젝트 루트 디렉터리에서 실행합니다:
python -m deep_recall.inference_service --gpu - GPU 사용량 확인: 추론 서비스가 GPU 리소스를 사용하고 있는지 로그를 통해 확인합니다.
3. 벡터 데이터베이스 통합
딥 리콜은 벡터 데이터베이스를 사용하여 사용자 상호작용 데이터를 저장하고 효율적인 쿼리를 지원합니다. 운영 프로세스:
- 데이터베이스 초기화하기: 초기화 스크립트를 실행하여 벡터 인덱스를 생성합니다:
python scripts/init_vector_db.py - 데이터 가져오기API 또는 스크립트를 통해 사용자 기록 데이터를 데이터베이스로 가져옵니다. API 호출 예시:
curl -X POST http://localhost:8000/memory/store \ -H "Content-Type: application/json" \ -d '{"user_id": "user123", "data": "用户喜欢科幻电影"}' - 데이터 쿼리검색 API를 사용하여 저장된 벡터 데이터를 필요에 따라 쿼리할 수 있습니다.
4. 자동 확장
딥 리콜은 부하가 많은 시나리오를 위한 동적 리소스 할당을 지원합니다. 사용자는 파일을 구성할 수 있습니다. config/scaling_config.json 최대 인스턴스 수 또는 로드 임계값과 같은 확장 정책을 설정합니다. 코디네이터 서비스를 시작합니다:
python -m deep_recall.orchestrator
코디네이터는 로드에 따라 추론 서비스 인스턴스 수를 자동으로 조정합니다.
주요 기능 작동
보안 스캔 시스템
Deep Recall에는 코드 품질을 보장하기 위한 포괄적인 보안 검사 도구가 내장되어 있습니다. 작동 방식:
- 종속성 검사 실행파이썬 종속성에서 알려진 취약점을 확인합니다:
safety check - 코드 보안 분석Bandit을 사용하여 코드의 보안 문제를 스캔하세요:
bandit -r deep_recall - 보고서 보기스캔 결과는 JSON 및 마크다운 형식으로 저장됩니다.
reports/사용자 리뷰용 카탈로그.
API 클라이언트 예제
딥 리콜은 API 통합을 간소화하기 위해 Python 및 JavaScript 클라이언트 라이브러리를 제공합니다. Python 코드 샘플:
from deep_recall_client import DeepRecallClient
client = DeepRecallClient("http://localhost:8000")
response = client.retrieve_memory(user_id="user123", query="推荐一部电影")
print(response["reply"])
사용자는 프로젝트의 React 대화형 인터페이스를 빠르게 구축할 수 있는 프런트엔드 예시입니다.
주의
- 네트워크 연결이 안정적인지 확인하세요. 네트워크 문제로 인해 API 호출이 실패할 수 있습니다.
- 벡터 데이터베이스를 정기적으로 백업하려면 다음을 참조하세요.
docs/backup.md자동 백업을 구성합니다. - 프로브
config/security_config.json를 클릭하고 보안 검색 규칙을 사용자 지정하세요.
애플리케이션 시나리오
- 고객 서비스 로봇
딥 리콜은 고객 서비스 봇에 사용자의 과거 질문과 선호도를 기록하는 메모리 기능을 제공하여 사용자의 요구와 더 관련성이 높은 응답을 생성합니다. 예를 들어, 이커머스 플랫폼에서 봇은 사용자의 과거 구매 내역을 기반으로 제품을 추천할 수 있습니다. - 개인 맞춤형 교육 플랫폼
온라인 교육에서 딥 리콜은 학생의 진도와 관심사를 저장하여 맞춤형 학습 제안을 생성합니다. 예를 들어, 학생의 수준에 맞는 연습 문제를 제안합니다. - 지능형 어시스턴트 개발
개발자는 딥 리콜을 사용하여 사용자 습관을 기록하고 상황에 맞는 제안을 제공하는 지능형 어시스턴트를 구축할 수 있습니다. 예를 들어, 어시스턴트는 사용자의 일정에 따라 회의나 작업을 상기시켜 줄 수 있습니다. - 콘텐츠 추천 시스템
딥 리콜은 사용자의 검색 기록을 분석하여 관련 기사, 동영상 또는 제품을 추천하는 콘텐츠 추천 엔진을 구축하는 데 적합합니다. 예를 들어, 뉴스 플랫폼은 사용자의 읽기 선호도에 따라 개인화된 정보를 푸시할 수 있습니다. - 엔터프라이즈 지식 관리
조직은 딥 리콜을 사용하여 내부 지식 기반을 구축하고, 직원 상호 작용에 대한 데이터를 저장하고, 과거 정보를 빠르게 검색할 수 있습니다. 예를 들어 기술 지원팀은 이 시스템을 사용하여 과거 해결책을 찾을 수 있습니다.
QA
- 딥 리콜은 어떤 대형 모델을 지원하나요?
딥 리콜은 LLaMA, 미스트랄, BERT 등 여러 오픈 소스 매크로 모델과 호환되며, 이에 대한 자세한 내용은 공식 문서를 참조하세요.docs/model_support.md전체 지원 목록을 확인하세요. - 데이터 프라이버시를 어떻게 보장하나요?
딥 리콜은 사용자가 제어하는 서버에 데이터를 저장하는 로컬 배포를 지원합니다. 사용자는 암호화된 볼륨 또는 구성된 방화벽을 통해 데이터 개인 정보를 더욱 안전하게 보호할 수 있습니다. - 실행하려면 GPU가 필요하나요?
GPU는 추론을 가속화할 수 있지만 필수는 아니며, CPU 환경에서도 처리 속도가 약간 느리지만 딥 리콜을 실행할 수 있습니다. 부하가 많은 시나리오에는 GPU를 사용하는 것이 좋습니다. - API 호출 실패는 어떻게 처리하나요?
네트워크 연결 및 API 엔드포인트 구성을 확인하세요. 문제가 지속되면 로그 파일을 검토하세요.logs/service.log또는 공식 지원 이메일로 문의하세요. - 다국어 데이터를 지원하나요?
예, 딥 리콜의 벡터 데이터베이스는 국제화된 애플리케이션 시나리오를 위한 다국어 텍스트 저장 및 검색을 지원합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...