
일반 소개
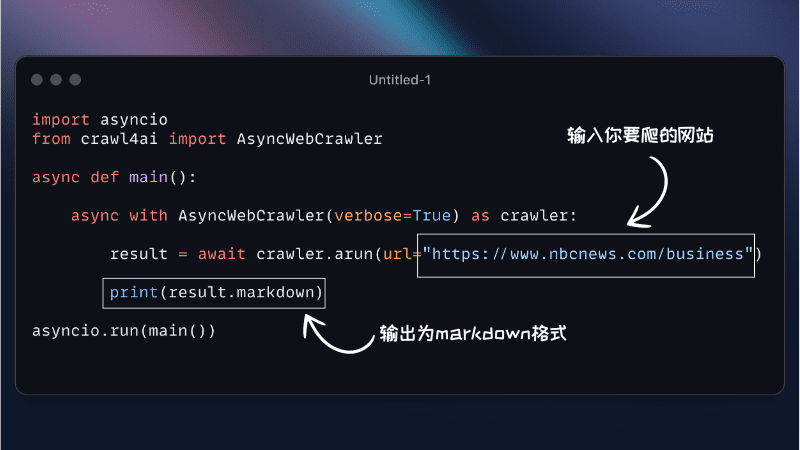
Crawl4AI는 대규모 언어 모델(LLM) 및 인공 지능(AI) 애플리케이션을 위해 설계된 오픈 소스 비동기 웹 크롤러 도구입니다. 웹 크롤링 및 데이터 추출 프로세스를 간소화하고 효율적인 웹 크롤링을 지원하며 JSON, 정리된 HTML 및 Markdown과 같은 LLM 친화적인 출력 형식을 제공합니다.Crawl4AI는 다양한 데이터 크롤링 요구에 적합한 완전 무료 오픈 소스이며 동시에 여러 URL을 크롤링할 수 있도록 지원합니다.
기능 목록
- 비동기식 아키텍처: 여러 웹 페이지의 효율적인 처리, 빠른 데이터 크롤링
- 여러 출력 형식: JSON, HTML, 마크다운 지원
- 멀티 URL 크롤링: 여러 웹 페이지를 동시에 크롤링합니다.
- 미디어 태그 추출: 이미지, 오디오 및 비디오 태그 추출
- 링크 추출: 모든 외부 및 내부 링크 추출
- 메타데이터 추출: 페이지에서 메타데이터 추출하기
- 사용자 정의 후크: 인증, 요청 헤더 및 페이지 수정 지원
- 사용자 에이전트 사용자 지정: 사용자 에이전트 사용자 지정
- 페이지 스크린샷: 크롤링 페이지의 스크린샷
- 사용자 정의 JavaScript 실행: 크롤링하기 전에 여러 개의 사용자 정의 자바스크립트를 실행합니다.
- 프록시 지원: 개인정보 보호 및 액세스 강화
- 세션 관리: 복잡한 다중 페이지 크롤링 시나리오 처리하기
도움말 사용
설치 프로세스
Crawl4AI는 다양한 사용 시나리오에 맞는 유연한 설치 옵션을 제공합니다. Python 패키지로 설치하거나 Docker를 사용할 수 있습니다.
핍으로 설치
- 기본 설치
pip install crawl4ai이렇게 하면 기본적으로 웹 크롤링에 Playwright를 사용하는 비동기 버전의 Crawl4AI가 설치됩니다.
- Playwright 수동 설치(필요한 경우)
playwright install또는
python -m playwright install chromium
Docker로 설치하기
- Docker 이미지 가져오기
docker pull unclecode/crawl4ai - 도커 컨테이너 실행
docker run -it unclecode/crawl4ai
사용 가이드라인
- 기본 사용
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() results = crawler.crawl(["https://example.com"]) print(results) - 사용자 지정 설정
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler( user_agent="CustomUserAgent", headers={"Authorization": "Bearer token"}, custom_js=["console.log('Hello, world!')"] ) results = crawler.crawl(["https://example.com"]) print(results) - 특정 데이터 추출
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() results = crawler.crawl(["https://example.com"], extract_media=True, extract_links=True) print(results) - 세션 관리
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() session = crawler.create_session() session_results = session.crawl(["https://example.com"]) print(session_results)
Crawl4AI는 다양한 웹 크롤링 및 데이터 크롤링 요구사항에 맞는 풍부한 기능과 유연한 구성 옵션을 제공합니다. 자세한 설치 및 사용 가이드를 통해 사용자는 쉽게 시작하고 도구의 강력한 기능을 최대한 활용할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...