
탠덤 랭체인 오픈 딥서치 큐워드

프로젝트 실행 프로세스를 하나로 묶고 큐 워드 지침을 번역하려면 프로젝트의 기반이 되어야 합니다.prompts.py파일을 사용하여 각 단계의 실행 흐름과 그에 해당하는 큐워드 지침을 자세히 설명합니다.
프로젝트 실행 프로세스 및 해당 큐 워드 지침
1. 보고서 계획에 도움이 되는 검색 쿼리 생성하기
- 프롬프트:
report_planner_query_writer_instructions = """ 你是一名专家技术写手,正在帮助计划一份报告。 <报告主题> {topic} </报告主题> <报告组织> {report_organization} </报告组织> <任务> 你的目标是生成 {number_of_queries} 个搜索查询,以帮助收集全面的信息来规划报告部分。 这些查询应当: 1. 与报告主题相关 2. 帮助满足报告组织中规定的要求 使查询足够具体,以找到高质量、相关的资源,同时覆盖报告结构所需的广度。 </任务> """
2. 보고서 생성 계획
- 프롬프트:
report_planner_instructions = """ 我需要一个报告计划。 <任务> 生成一个报告部分的列表。 每个部分应当包含以下字段: - 名称 - 报告部分的名称。 - 描述 - 本部分涵盖的主要主题的简要概述。 - 研究 - 是否需要为本部分报告进行网络研究。 - 内容 - 本部分的内容,现在可以留空。 例如,介绍和结论将不需要研究,因为它们将从报告的其他部分提炼信息。 </任务> <主题> 报告的主题是: {topic} </主题> <报告组织> 报告应遵循此组织: {report_organization} </报告组织> <上下文> 以下是用于规划报告部分的上下文: {context} </上下文> <反馈> 以下是对报告结构的审查反馈(如果有): {feedback} </反馈> """
3. 검색어 준비
- 프롬프트:
query_writer_instructions = """ 你是一名专家技术写手,正在编写有针对性的网络搜索查询,以收集撰写技术报告部分的全面信息。 <部分主题> {section_topic} </部分主题> <任务> 你的目标是生成 {number_of_queries} 个搜索查询,以帮助收集有关本部分主题的全面信息。 这些查询应当: 1. 与主题相关 2. 检查该主题的不同方面 使查询足够具体,以找到高质量、相关的资源。 </任务> """
4. 보고서 작성 구성 요소
- 프롬프트:
section_writer_instructions = """ 你是一名专家技术写手,正在撰写技术报告的一个部分。 <部分主题> {section_topic} </部分主题> <现有部分内容(如果已填写)> {section_content} </现有部分内容> <源材料> {context} </源材料> <撰写指南> 1. 如果现有部分内容未填写,则从头撰写新的部分。 2. 如果现有部分内容已填写,请撰写一个新的部分,将现有内容与新信息综合起来。 <长度和风格> - 严格限制在150-200字 - 不使用营销语言 - 技术重点 - 使用简单、清晰的语言 - 用**加粗**的最重要的见解开头 - 使用简短的段落(每段最多2-3句话) - 使用 ## 作为部分标题(Markdown格式) - 仅在有助于澄清观点时使用一个结构元素: * 要么是比较2-3个关键项目的集中表格(使用Markdown表格语法) * 要么是使用正确的Markdown列表语法的简短列表(3-5项): - 使用 `*` 或 `-` 表示无序列表 - 使用 `1.` 表示有序列表 - 确保正确的缩进和间距 - 以参考以下源材料的###来源结束: * 列出每个来源的标题、日期和URL * 格式:`- 标题 : URL` </长度和风格> <质量检查> - 恰好150-200字(不包括标题和来源) - 仔细使用一个结构元素(表格或列表),仅在有助于澄清观点时 - 一个具体的例子/案例研究 - 以加粗见解开头 - 在创建部分内容之前不作任何序言 - 在结尾引用来源 </质量检查> """
5. 보고 구성 요소 평가
- 프롬프트:
section_grader_instructions = """ 审核相对于指定主题的报告部分: <部分主题> {section_topic} </部分主题> <部分内容> {section} </部分内容> <任务> 评估该部分是否通过检查技术准确性和深度,充分涵盖了主题。 如果该部分未满足任何标准,请生成具体的后续搜索查询以收集缺失的信息。 </任务> <格式> grade: Literal["pass","fail"] = Field( description="评估结果,指示响应是否符合要求('通过')或需要修订('失败')。" ) follow_up_queries: List[SearchQuery] = Field( description="后续搜索查询列表。", ) </格式> """
6. 최종 보고서 섹션 작성
- 프롬프트:
final_section_writer_instructions = """ 你是一名专家技术写手,正在撰写综合报告其他部分信息的部分。 <部分主题> {section_topic} </部分主题> <可用报告内容> {context} </可用报告内容> <任务> 1. 部分特定方法: 对于介绍: - 使用 # 作为报告标题(Markdown格式) - 50-100字限制 - 使用简单和清晰的语言 - 重点介绍报告的核心动机,1-2段 - 使用清晰的叙述弧线介绍报告 - 不使用任何结构元素(无列表或表格) - 不需要来源部分 对于结论/总结: - 使用 ## 作为部分标题(Markdown格式) - 100-150字限制 - 对于比较报告: * 必须包含使用Markdown表格语法的集中比较表 * 表格应提炼报告中的见解 * 保持表格条目清晰简洁 - 对于非比较报告: * 仅在有助于提炼报告中的要点时使用一个结构元素: * 要么是比较报告中项目的集中表格(使用Markdown表格语法) * 要么是使用正确的Markdown列表语法的简短列表: - 使用 `*` 或 `-` 表示无序列表 - 使用 `1.` 表示有序列表 - 确保正确的缩进和间距 - 以具体的下一步或影响结束 - 不需要来源部分 3. 撰写方法: - 使用具体细节而非一般陈述 - 每个字都要有意义 - 重点突出最重要的一点 </任务> <质量检查> - 对于介绍:50-100字限制,# 作为报告标题,无结构元素,无来源部分 - 对于结论:100-150字限制,## 作为部分标题,仅使用一个结构元素,无来源部分 - Markdown格式 - 不在响应中包含字数或任何序言 </质量检查> """
탠덤 실행 프로세스
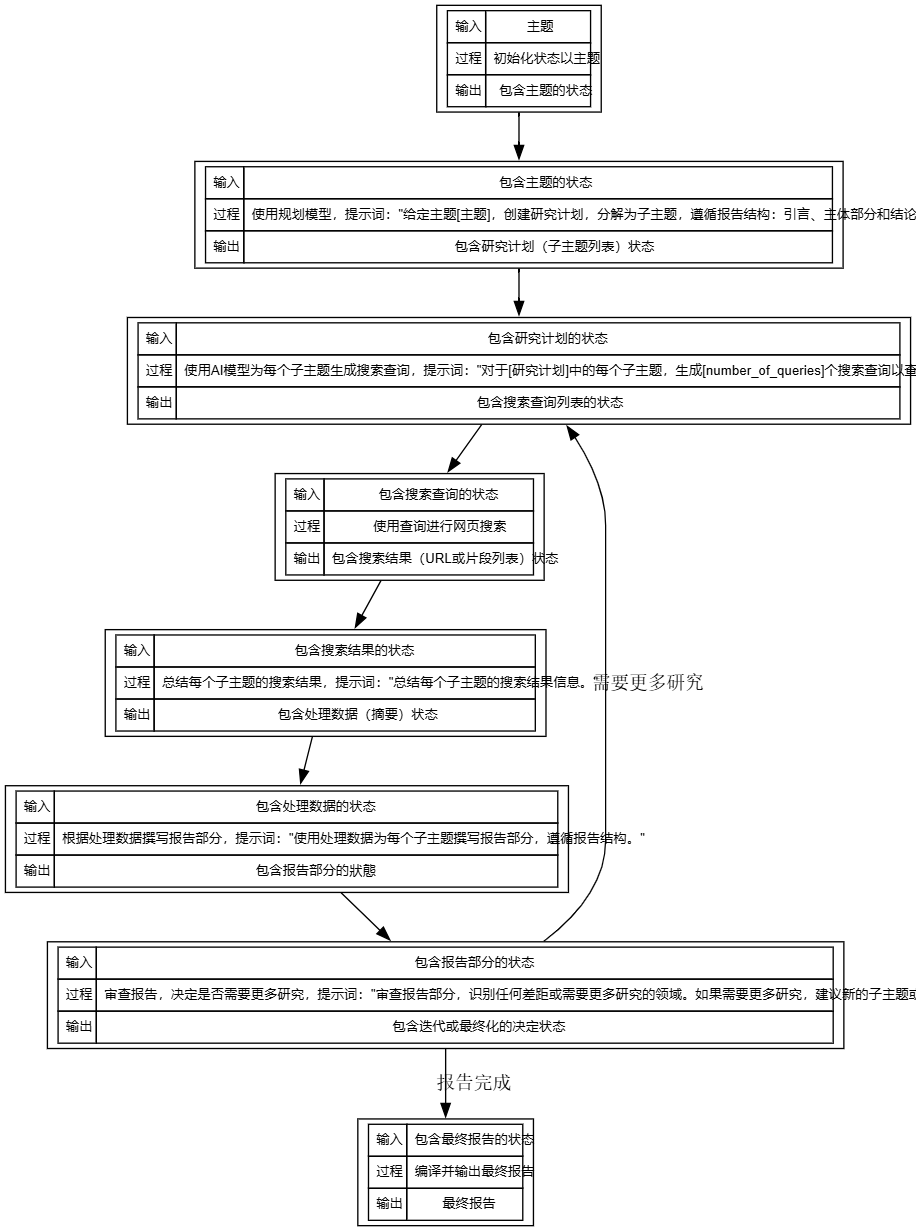
1. 초기화(시작)
- 가져오기 "Fireworks, Together.ai, Groq을 중심으로 한 AI 추론 시장 개요"와 같은 사용자 제공 주제.
- 이벤트 진행 과정 시스템이 상태를 초기화하고 AI 모델 호출 없이 토픽을 상태의 일부로 저장합니다.
- 수출 : 후속 단계에서 사용할 주제의 상태를 포함합니다.
2. 계획
- 가져오기 : 피사체의 상태를 포함합니다.
- 이벤트 진행 과정 기본 OpenAI o3-mini 또는 Groq의 deepseek-r1-distill-llama-70b와 같은 계획 모델을 사용하여 연구 계획을 생성합니다. "주제[테마]가 주어지면 서론, 본문 섹션, 결론이라는 보고서 구조를 따르는 하위 주제로 세분화된 연구 계획을 작성하세요."라는 메시지가 표시됩니다.
- 수출 연구 프로그램(하위 주제 목록)을 포함하도록 업데이트된 상태(예: "1. AI 추론 시장의 정의, 2. 파이어폭스의 역할, 3. 함께.ai의 사례 연구" 등을 참조하세요.
- 큐워드의 출처 구성.py의 기본_보고서_구조를 보면 구조는 서론, 본문 섹션, 결론으로 구성되며 본문 섹션에서는 주요 개념, 정의 및 예제를 다뤄야 합니다.
3. 쿼리 생성
- 가져오기 연구 프로그램 현황이 포함되어 있습니다.
- 이벤트 진행 과정 AI 모델을 사용하여 "[연구 계획]의 각 하위 주제에 대해 관련 정보를 찾기 위해 [number_of_queries] 검색 쿼리를 생성하세요."라는 프롬프트 문구와 함께 각 하위 주제에 대한 검색 쿼리를 생성합니다. 기본 number_of_queries는 2입니다.
- 수출 "AI 추론 시장 정의 2023", "불꽃놀이 AI 서비스 사례" 등의 검색어 목록이 포함되도록 상태가 업데이트되었습니다.
- 큐워드의 출처 : 프로젝트 문서에서 프롬프트 단어가 생성된 쿼리의 일반적인 형태라고 가정하고 쿼리 수를 구성할 수 있다고 언급되어 있습니다.
4. 웹 검색
- 가져오기 : 검색 쿼리의 상태를 포함합니다.
- 이벤트 진행 과정 검색 API(예: 기본 Tavily)를 사용하여 각 쿼리를 실행하여 웹 검색 결과를 얻습니다. 도구를 통해 직접 실행되는 AI 모델 호출이 없습니다.
- 수출 상태는 Tavily에서 반환한 페이지 요약과 같은 검색 결과(URL 또는 스니펫 목록)를 포함하도록 업데이트됩니다.
- 기술 세부 정보 tavily-python >= 0.5.0에 대한 종속성, TAVILY_API_KEY를 구성해야 합니다.
5. 데이터 처리
- 가져오기 : 검색 결과의 상태를 포함합니다.
- 이벤트 진행 과정 "각 하위 주제에 대한 검색 결과 정보를 요약하세요."라는 프롬프트 문구와 함께 AI 모델을 사용하여 각 하위 주제에 대한 검색 결과를 요약합니다.
- 수출 처리 데이터(요약)를 포함하도록 상태 업데이트, 예: "AI 추론 시장 정의: 실시간 예측을 위해 AI 모델을 사용하는 산업을 의미하며 2023년까지 빠르게 성장하고 있습니다."
- 큐워드의 출처 보고서 생성을 위한 프로젝트 목표에 따라 요약 작업에 대한 일반 프롬프트에 대한 가정입니다.
6. 보고서 작성
- 가져오기 처리된 데이터의 상태를 포함합니다.
- 이벤트 진행 과정 쓰기 모델 사용(예: 기본 Anthropic). Claude 3.5 소네트) "처리된 데이터를 사용하여 보고서 구조에 따라 각 하위 주제에 대한 보고서 섹션을 작성하십시오."라는 메시지가 표시된 상태에서 처리된 데이터를 기반으로 보고서 섹션을 작성합니다.
- 수출 상태 업데이트: "소개: AI 추론 시장은 AI 도입에 있어 중요한 영역, 본문 섹션 1: Fireworks는 클라우드 배포를 포함한 사례를 통해 효율적인 추론 서비스를 제공합니다." 등의 보고서 섹션을 포함하도록 업데이트되었습니다.
- 큐워드의 출처 기본_보고서_구조와 함께 보고서에는 개요, 주요 개념 및 예시가 포함되어야 합니다.
7. 반사
- 가져오기 보고서 섹션의 상태를 포함합니다.
- 이벤트 진행 과정 "보고서 섹션을 검토하고 더 많은 연구가 필요한 부분이나 부족한 부분을 파악하세요."라는 안내 멘트와 함께 AI 모델을 사용하여 보고서를 검토하고 추가 연구가 필요한지 여부를 결정합니다. 더 많은 연구가 필요한 경우 새로운 하위 주제 또는 쿼리를 제안하세요."라는 메시지가 표시됩니다.
- 수출 반복 결정(예: 추가 조사 필요) 또는 최종 보고서를 포함하도록 업데이트된 상태입니다. 반복이 필요한 경우 새로운 하위 주제 또는 쿼리 제안을 출력합니다.
- 큐워드의 출처 프로젝트 문서에서 큐워드가 일반적인 형태의 검토 및 추천이라고 가정하여 반영과 반복이 지원된다고 언급합니다.
8. 출력
- 가져오기 최종 보고서의 상태를 포함합니다(리플렉션에서 보고서가 완료되었다고 판단한 경우).
- 이벤트 진행 과정 모든 보고서 섹션을 컴파일하여 AI 모델 호출 없이 마크다운 형식으로 최종 보고서를 생성합니다.
- 수출 최종 보고서(예: 사용자가 다운로드하거나 볼 수 있는 전체 마크다운 문서).
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...