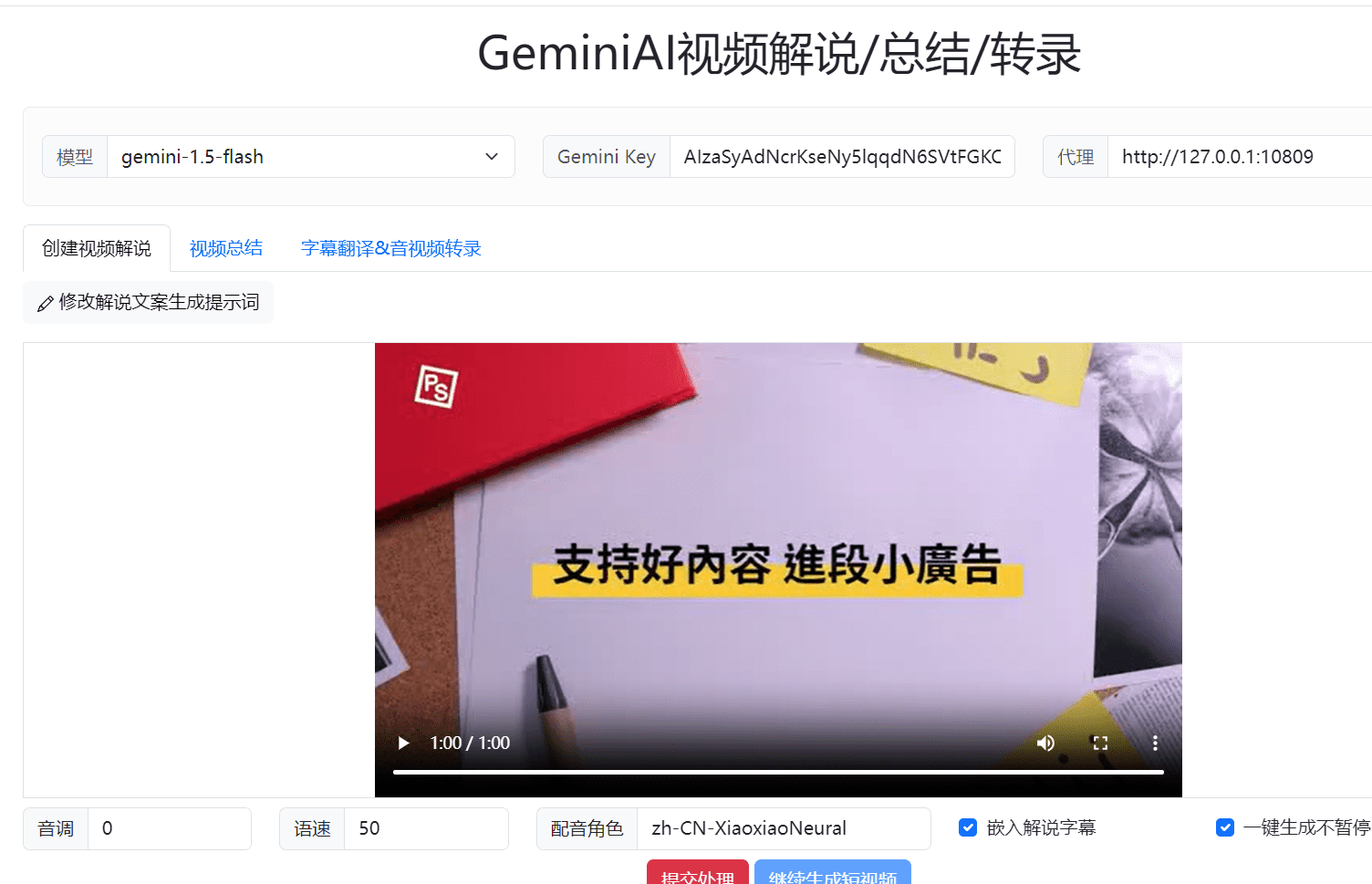

일반 소개
Chonkie는 개발자가 쉽고 빠르게 텍스트를 청킹할 수 있도록 설계된 가볍고 효율적인 RAG(검색 증강 생성) 텍스트 청킹 라이브러리입니다. 이 라이브러리는 토큰, 단어, 문장, 의미적 유사성 기반 청킹을 포함한 다양한 청킹 방법을 지원하며, 광범위한 텍스트 처리 및 자연어 처리 작업에 적합합니다. 기본 설치 시 21MB만 필요합니다(다른 유사 제품은 80~171MB 필요) 모든 주요 청커를 지원합니다.
기능 목록
- 토큰청커: 텍스트를 고정 크기 마커 블록으로 분할합니다.
- 워드청커단어에 따라 텍스트를 청크로 나눕니다.
- 문장 청커문장을 기준으로 텍스트를 청크로 나눕니다.
- 시맨틱청커: 의미적 유사성에 따라 텍스트를 청크로 분할합니다.
- SDPMChunker시맨틱 이중 병합 접근 방식을 사용하여 텍스트를 분할합니다.
도움말 사용
마운팅
촌키를 설치하려면 다음 명령을 실행하면 됩니다:
pip install chonkie
촌키는 최소한의 기본 설치 원칙을 따르며 필요에 따라 특정 청커를 설치하거나 종속성을 고려하지 않으려는 경우 모든 청커를 설치하는 것을 권장합니다(권장하지 않음).
pip install chonkie[all]
활용
다음은 빠르게 시작하는 데 도움이 되는 기본 예제입니다:
- 먼저 원하는 청커를 가져옵니다:
from chonkie import TokenChunker - 즐겨 사용하는 토큰라이저 라이브러리를 가져옵니다(자동 토큰라이저, 틱토큰, 자동 틱토큰라이저가 지원됩니다):
from tokenizers import Tokenizer tokenizer = Tokenizer.from_pretrained("gpt2") - 청커를 초기화합니다:
chunker = TokenChunker(tokenizer) - 텍스트 청크하기:
chunks = chunker("Woah! Chonkie, the chunking library is so cool! I love the tiny hippo hehe.") - 청크 결과에 액세스합니다:
for chunk in chunks: print(f"Chunk: {chunk.text}") print(f"Tokens: {chunk.token_count}")
지원 방법
촌키는 다양한 청커를 제공하여 자신만의 청크를 효율적으로 생성하고 배포할 수 있도록 도와줍니다. RAG 애플리케이션이 텍스트를 분할합니다. 다음은 사용 가능한 청커에 대한 간략한 개요입니다:
- 토큰청커: 텍스트를 고정 크기 마커 블록으로 분할합니다.
- 워드청커단어에 따라 텍스트를 청크로 나눕니다.
- 문장 청커문장을 기준으로 텍스트를 청크로 나눕니다.
- 시맨틱청커: 의미적 유사성에 따라 텍스트를 청크로 분할합니다.
- SDPMChunker시맨틱 이중 병합 접근 방식을 사용하여 텍스트를 분할합니다.
벤치마킹
Chonkie는 여러 벤치마크에서 우수한 성능을 발휘합니다:
- 크기기본 설치 용량은 9.7MB(다른 버전의 경우 80~171MB)에 불과하며, 시맨틱 청킹을 포함하더라도 경쟁 제품보다 여전히 가볍습니다.
- 템포태그 청킹은 가장 느린 대안보다 33배, 문장 청킹은 경쟁사보다 거의 2배, 시맨틱 청킹은 다른 방법보다 2.5배 더 빠릅니다.
세부 운영 절차
- 설치 관리자: pip를 통해 촌키와 필요한 태거 라이브러리를 설치합니다.
- 라이브러리 가져오기파이썬 스크립트에서 Chonkie와 태거 라이브러리를 가져옵니다.
- 청커 초기화하기: 필요에 따라 적절한 청커를 선택하고 초기화합니다.
- 덩어리 텍스트: 초기화된 청커를 사용하여 텍스트를 청크합니다.
- 결과추가 처리 또는 분석을 위해 청크 결과를 반복합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...