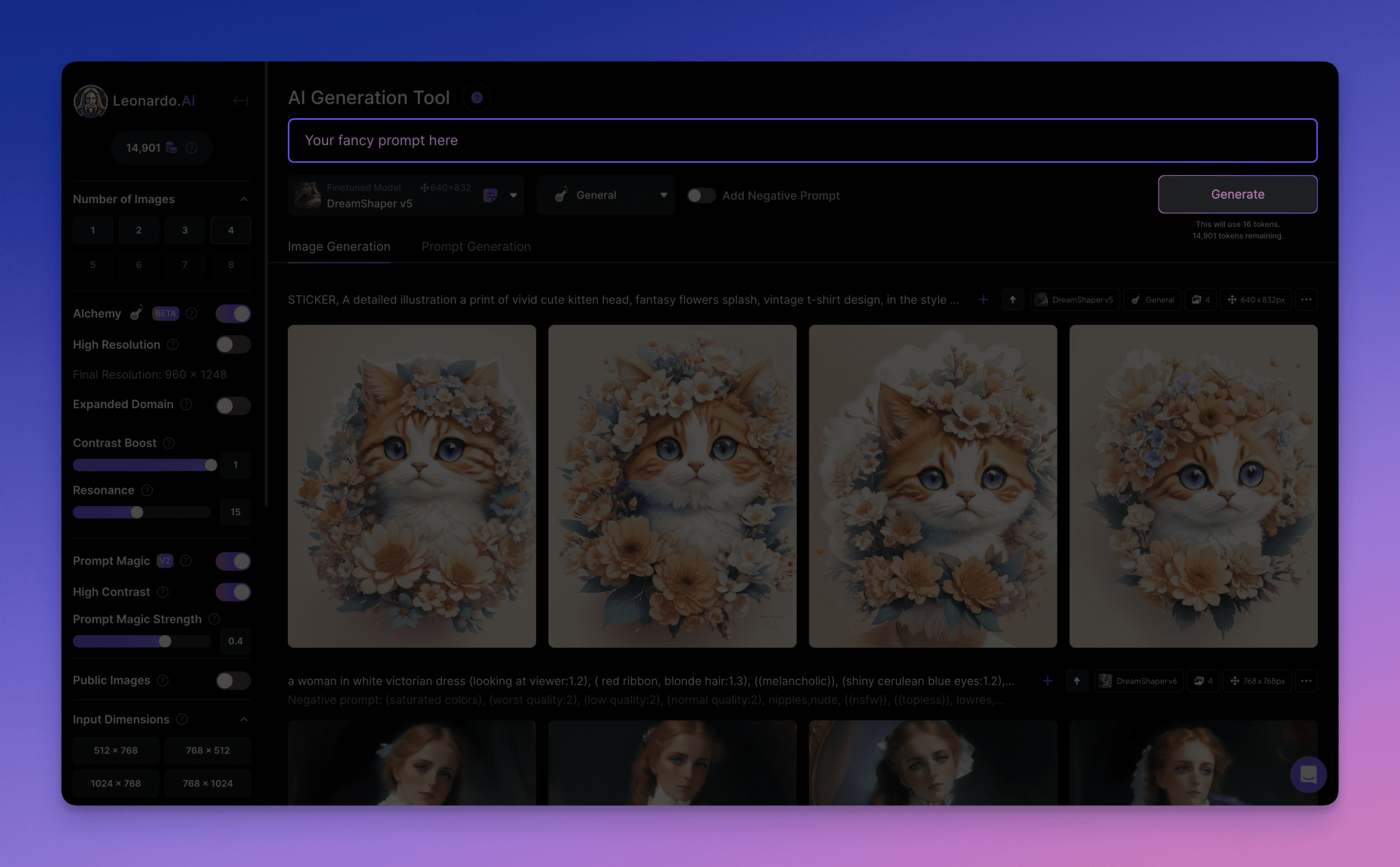
ChatOllama 노트 | 생산성 및 Redis 기반 문서 데이터베이스를 위한 고급 RAG 구현하기

채팅올라마 LLM을 기반으로 하는 오픈 소스 챗봇입니다. ChatOllama에 대한 자세한 설명을 보려면 아래 링크를 클릭하세요.
ChatOllama | Ollama 기반 100% 로컬 RAG 애플리케이션
채팅올라마 초기 목표는 사용자에게 100% 네이티브 RAG 애플리케이션을 제공하는 것이었습니다.
성장함에 따라 점점 더 많은 사용자가 소중한 요구 사항을 제시했습니다. 이제 `ChatOllama`는 다음과 같은 여러 언어 모델을 지원합니다:
ChatOllama를 사용하면 사용자는 다음을 수행할 수 있습니다:
- 올라마 모델 관리(가져오기/삭제)
- 지식창고 관리(만들기/삭제)
- LLM과의 자유로운 대화
- 개인 지식창고 관리하기
- 개인 지식창고를 통해 LLM과 소통하기
이 글에서는 프로덕션용 고급 RAG를 구현하는 방법을 살펴보겠습니다. RAG의 기본 및 고급 기술을 배웠지만 RAG를 프로덕션에 도입하려면 여전히 처리해야 할 사항이 많습니다. ChatOllama에서 수행한 작업과 RAG를 프로덕션에 도입하기 위해 준비한 내용을 공유하겠습니다.

ChatOllama | RAG 구성 실행
ChatOllama 플랫폼에서 우리는LangChain.js를 사용하여 RAG 프로세스를 조작할 수 있습니다. ChatOllama의 지식창고에서는 원래 RAG 이외의 상위 문서 검색기가 사용됩니다. 그 아키텍처와 구현 세부 사항에 대해 자세히 살펴보겠습니다. 도움이 되셨기를 바랍니다.
상위 문서 검색기 유틸리티
상위 문서 검색기가 실제 제품에서 작동하도록 하려면 핵심 원칙을 이해하고 제작 목적에 맞는 저장 요소를 선택해야 합니다.
상위 문서 검색기의 핵심 원칙
검색 요구에 따라 문서를 분할할 때 상충되는 요구 사항이 종종 발생합니다:
- 임베드된 콘텐츠가 그 의미를 가장 정확하게 표현할 수 있도록 문서의 크기를 최대한 작게 만드는 것이 좋습니다. 콘텐츠가 너무 길면 임베드된 정보가 의미를 잃을 수 있습니다.
- 또한 각 단락에 완전한 전체 텍스트 환경을 제공할 수 있을 만큼 충분히 긴 문서가 필요합니다.
LangChain.js 제공ParentDocumentRetriever이 균형은 문서를 청크로 분할함으로써 달성됩니다. 검색할 때마다 청크를 추출한 다음 각 청크에 해당하는 상위 문서를 조회하여 더 큰 범위의 문서를 반환합니다. 일반적으로 상위 문서는 문서 ID로 청크에 연결됩니다. 이 작동 방식에 대해서는 나중에 자세히 설명하겠습니다.
여기서는parent document작은 소스 문서 조각을 의미합니다.
빌드
상위 문서 검색기의 전체 아키텍처 다이어그램을 살펴보겠습니다.
각 청크는 처리되어 벡터 데이터로 변환된 다음 벡터 데이터베이스에 저장됩니다. 이러한 청크를 검색하는 프로세스는 원래 RAG 설정에서 수행했던 것과 동일합니다.
상위 문서(블록-1, 블록-2, ...... 블록-m)은 더 작은 부분으로 분할됩니다. 여기서 두 가지 텍스트 분할 방법이 사용된다는 점에 주목할 필요가 있습니다. 상위 문서에는 더 큰 방법을, 작은 블록에는 더 작은 방법을 사용합니다. 각 상위 문서에는 문서 ID가 부여되고 이 ID는 해당 청크에 메타데이터로 기록됩니다. 이렇게 하면 각 청크가 메타데이터에 저장된 문서 ID를 사용하여 해당 상위 문서를 찾을 수 있습니다.
상위 문서를 검색하는 과정은 이와 동일하지 않습니다. 유사성 검색 대신 문서 ID가 제공되어 해당 상위 문서를 찾습니다. 이 경우 키-값 저장 시스템으로 충분합니다.

상위 문서 검색기
저장소 섹션
저장해야 하는 데이터에는 두 가지 유형이 있습니다:
- 소규모 벡터 데이터
- 문서 ID가 포함된 상위 문서의 문자열 데이터
모든 주요 벡터 데이터베이스를 사용할 수 있습니다. 'ChatOllama' 중에서 저는 크로마를 선택했습니다.
상위 문서 데이터의 경우, 가장 널리 사용되고 확장성이 뛰어난 키-값 스토리지 시스템인 Redis를 선택했습니다.
LangChain.js에서 누락된 기능
LangChain.js는 바이트 및 문서 저장소를 통합하는 다양한 방법을 제공합니다:
키-값 쌍으로 데이터를 저장하는 것은 빠르고 효율적이며 LLM 애플리케이션을 위한 강력한 도구입니다. 기본 리포지토리...
'아이오레디스' 지원:
이 예는 RedisByteStore 기본 리포지토리 통합을 사용하여 채팅 기록을 위한 저장소를 설정하는 방법을 보여줍니다.
RedisByteStore에서 누락된 부분은collection메커니즘.
서로 다른 지식창고의 문서를 처리할 때 각 지식창고는 다음과 같이 처리됩니다.collection컬렉션은 컬렉션 형태로 구성되며, 같은 라이브러리에 있는 문서는 벡터 데이터로 변환되어 다음 중 하나의 크로마와 같은 벡터 데이터베이스에 저장됩니다.collection어셈블리에서.
지식창고를 삭제하고 싶다고 가정해 보겠습니다. Chroma 데이터베이스에서 '컬렉션' 컬렉션은 확실히 삭제할 수 있습니다. 하지만 지식창고의 크기에 따라 문서 저장소를 어떻게 정리할 수 있을까요? RedisByteStore와 같은 컴포넌트는 `컬렉션` 기능을 지원하지 않기 때문에 직접 구현해야 했습니다.
채팅올라마 레디스닥스토어
Redis에는 `collection`이라는 기본 제공 기능이 없습니다. 개발자는 일반적으로 접두사 키를 사용하여 `collection` 기능을 구현합니다. 다음 그림은 접두사를 사용하여 다양한 컬렉션을 식별하는 방법을 보여줍니다:

접두사가 있는 Redis 키 표현
이제 이를 어떻게 구현했는지 살펴보겠습니다.Redis의 문서 저장 기능을 백그라운드에서 사용할 수 있습니다.
핵심 메시지:
- 각 `RedisDocstore`는 `namespace` 매개변수로 초기화됩니다. (네임스페이스와 컬렉션의 이름은 현재 표준화되어 있지 않을 수 있습니다.)
- 키는 가져오기 및 설정 작업 모두에 대해 먼저 '네임스페이스'가 처리됩니다.
"@langchain/core/documents"에서 { 문서 }를 가져옵니다;
"@langchain/core/stores"에서 { BaseStoreInterface }를 가져옵니다;
"ioredis"에서 { Redis }를 가져옵니다.
"@/server/store/redis"에서 { createRedisClient }를 가져옵니다;내보내기 클래스 RedisDocstore는 BaseStoreInterface를 구현합니다.
{
_네임스페이스: 문자열;
_client: Redis.생성자(네임스페이스: 문자열) {
this._namespace = 네임스페이스;
this._client = createRedisClient();
}serializeDocument(doc: 문서): 문자열 {
JSON.stringify(doc)를 반환합니다;
}deserializeDocument(jsonString: 문자열): Document {
const obj = JSON.parse(jsonString);
새 문서(객체)를 반환합니다;
}getNamespacedKey(키: 문자열): 문자열 {
${이름공간}:${키}`를 반환합니다;
}getKeys(): Promise {
반환 새 프로미스((해결, 거부) => {{
const stream = this._client.scanStream({ match: this._namespace + '*' });const keys: 문자열[] = [];
stream.on('data', (resultKeys) => {
keys.push(... .resultKeys);
});stream.on('end', () => {{
해결(키).
});stream.on('error', (err) => {
reject(err);
});
});
}추가 텍스트(키: 문자열, 값: 문자열) {
this._client.set(this.getNamespacedKey(key), value);
}async search(search: 문자열): Promise {
const result = await this._client.get(this.getNamespacedKey(search));
if (!result) {
새로운 오류(`ID ${search}를 찾을 수 없습니다.`)를 던집니다;
} else {
const document = this.deserializeDocument(result);
문서를 반환합니다;
}
}/**
* :: 스토어에 새 문서를 추가합니다.
* 매개변수 텍스트 키는 문서 ID이고 값은 문서 자체인 객체입니다.
* @리턴 무효
*/
async add(text: Record): Promise {
for (const [key, value] of Object.entries(text)) {
console.log(`${키}를 스토어에 추가 중: ${이것.serializeDocument(value)}`);
}const keys = [... .await this.getKeys()];
const overlapping = Object.keys(text).filter((x) => keys.includes(x));if (overlapping.length > 0) {
새로운 오류(`이미 존재하는 아이디를 추가하려고 했습니다: ${중첩}`)를 던집니다;
}for (const [key, value] of Object.entries(text)) {
this.addText(key, this.serialiseDocument(value)); this.
}
}async mget(keys: string[]): Promise {
반환 Promise.all(keys.map((key) => {
const document = this.search(key);
문서를 반환합니다;
}));
}async mset(keyValuePairs: [string, Document][]): Promise {
await Promise.all(
keyValuePairs.map(([키, 값]) => this.add({ [키]: 값 }))
);
}async mdelete(_keys: string[]): Promise {
새로운 에러("구현되지 않았습니다.")를 던집니다;
}// eslint-disable-next-line require-yield
async *yieldKeys(_prefix?: 문자열): AsyncGenerator {
새로운 에러("구현되지 않음")를 던집니다;
}async deleteAll(): Promise {
반환 새 프로미스((해결, 거부) => {{
let 커서 = '0';const scanCallback = (err, result) => {{
if (err) {
reject(err);
반환합니다;
}const [nextCursor, keys] = 결과;
// 접두사와 일치하는 키 삭제
keys.forEach((key) => {
this._client.del(키);
});// 커서가 '0'이면 모든 키를 반복한 것입니다.
if (nextCursor === '0') {
resolve().
} else {
// 계속하기 다음 커서로 스캔
this._client.scan(nextCursor, 'MATCH', `${this._namespace}:*`, scanCallback);
}
};// 초기 스캔 작업 시작
this._client.scan(cursor, 'MATCH', `${this._namespace}:*`, scanCallback);
});
}
}
이 컴포넌트는 부모도큐먼트 리트리버와 함께 원활하게 사용할 수 있습니다:
retriever = 새로운 부모 문서 리트리버({
벡터스토어: 크로마클라이언트.
docstore: 새로운 RedisDocstore(collectionName),
parentSplitter: new RecursiveCharacterTextSplitter({
청크오버랩: 200,
청크 크기: 1000,
}),
childSplitter: new RecursiveCharacterTextSplitter({
청크오버랩: 50.
청크 크기: 200,
}),
childK: 20.
parentK: 5.
});
이제 '크로마', '레디스'와 함께 고급 RAG, 부모 문서 검색기를 위한 확장 가능한 스토리지 솔루션을 갖추게 되었습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...