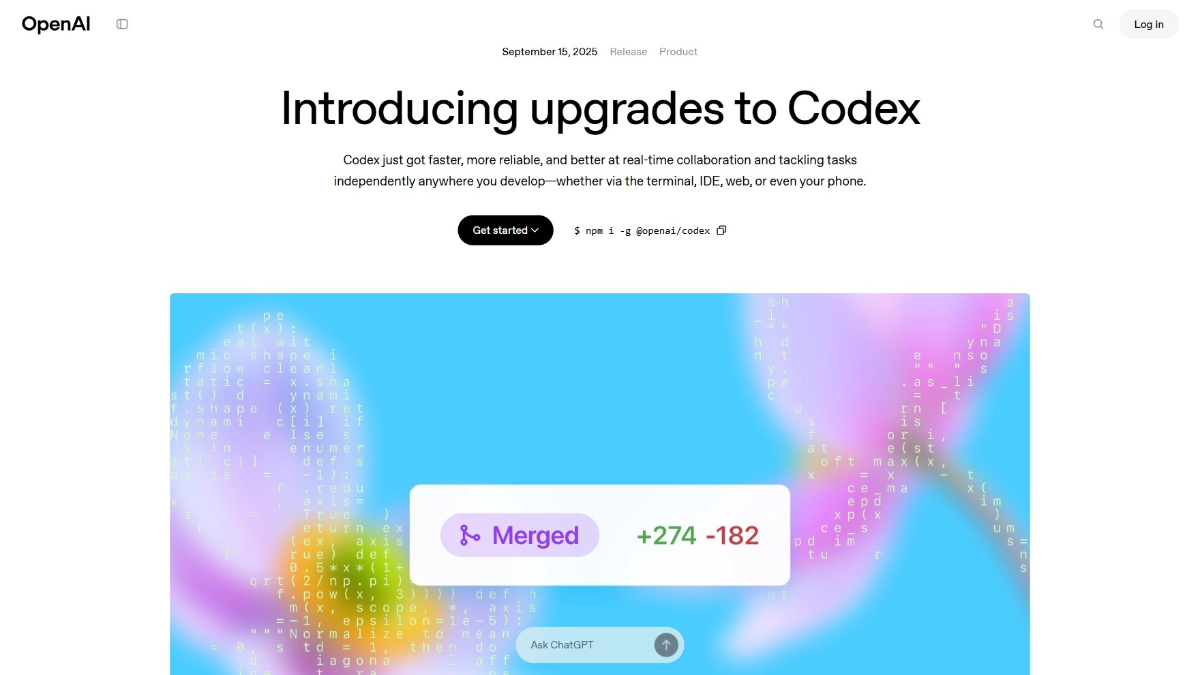
GPT-5-Codex - OpenAI가 도입한 가장 강력한 프로그래밍 모델
GPT-5-Codex는 소프트웨어 엔지니어를 위해 설계된 OpenAI의 강력한 프로그래밍 최적화 모델로, GPT-5에 의해 더욱 강화되었습니다. 이 모델은 고품질 코드를 신속하게 생성하고 여러 프로그래밍 언어를 지원하며 기존 코드를 최적화하여 성능을 향상시킵니다.

미니막스 뮤직 1.5 - 미니막스의 최신 AI 음악 생성 모델!
미니맥스 뮤직 1.5는 사용자의 자연어 설명을 기반으로 최대 4분 분량의 음악 생성을 지원하는 고급 AI 음악 생성 도구입니다. 이 모델은 다양한 음악 스타일과 분위기 사용자 지정을 지원하며 자연스럽고 완전한 보컬 톤, 부드러운 전환 및 풍부한 레이어 편곡을 생성합니다....
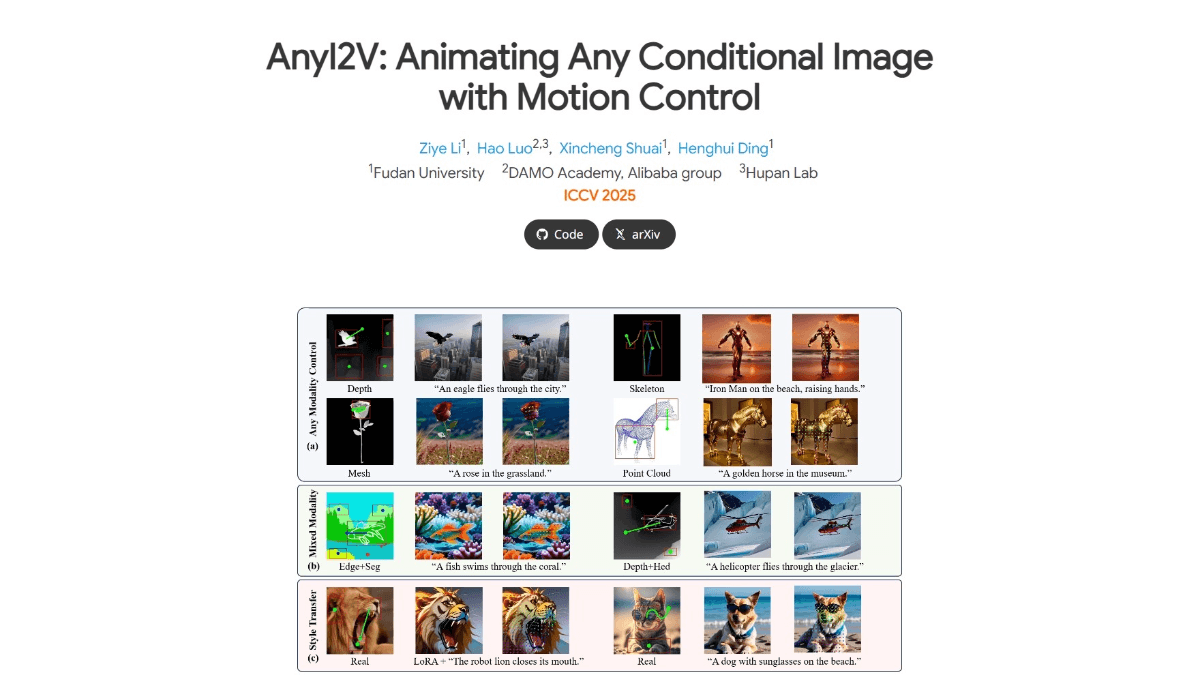
AnyI2V - 푸단 및 알리 다르마 연구소 및 기타 오픈 소스 지능형 이미지 애니메이션 생성 프레임워크
AnyI2V는 푸단대학교, 알리바바 다모 아카데미 등이 공동으로 출시한 이미지 애니메이션 생성 프레임워크로, 복잡한 학습 과정과 많은 양의 데이터 없이도 정적인 조건부 이미지(예: 그리드, 포인트 클라우드 등)를 동적인 동영상으로 변환할 수 있도록 지원합니다.
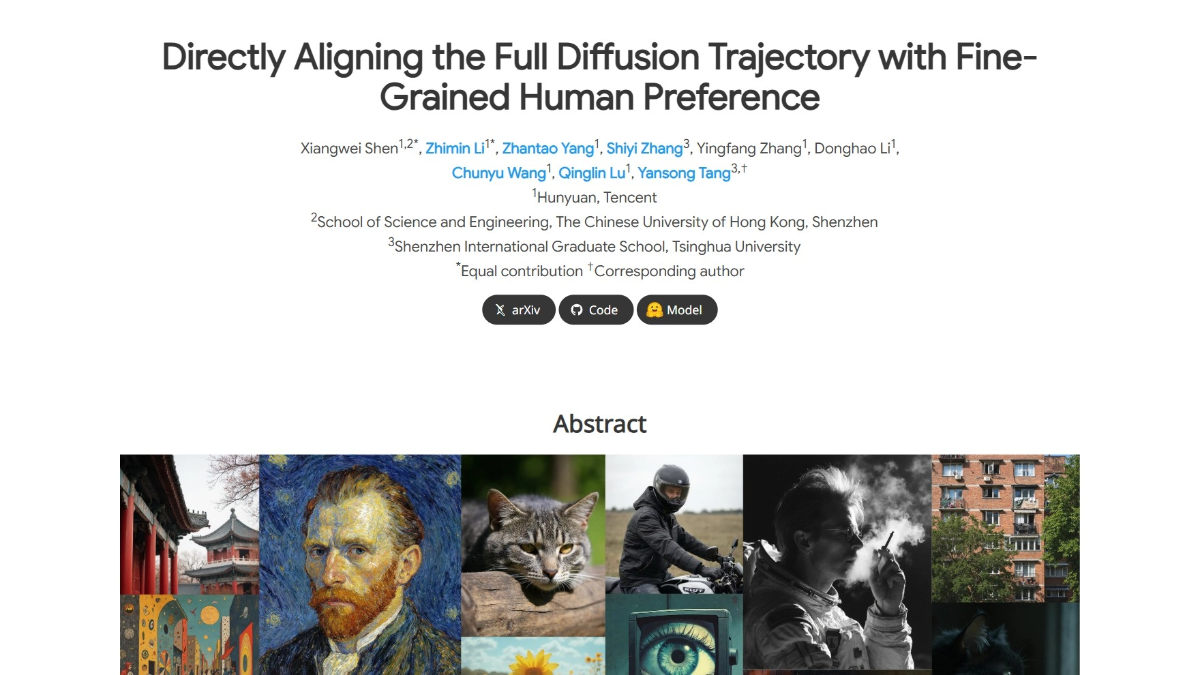
SRPO - 텐센트 하이브리드에서 출시한 텍스트-이미지 생성 모델
SRPO(Semantic Relative Preference Optimization)는 텐센트 혼합 메타에서 도입한 텍스트-이미지 생성 모델로, 텍스트 조건부 신호를 통해 보상 메커니즘을 최적화하여 온라인에서 보상을 조정하고 오프라인 미세 조정 의존도를 낮춥니다.
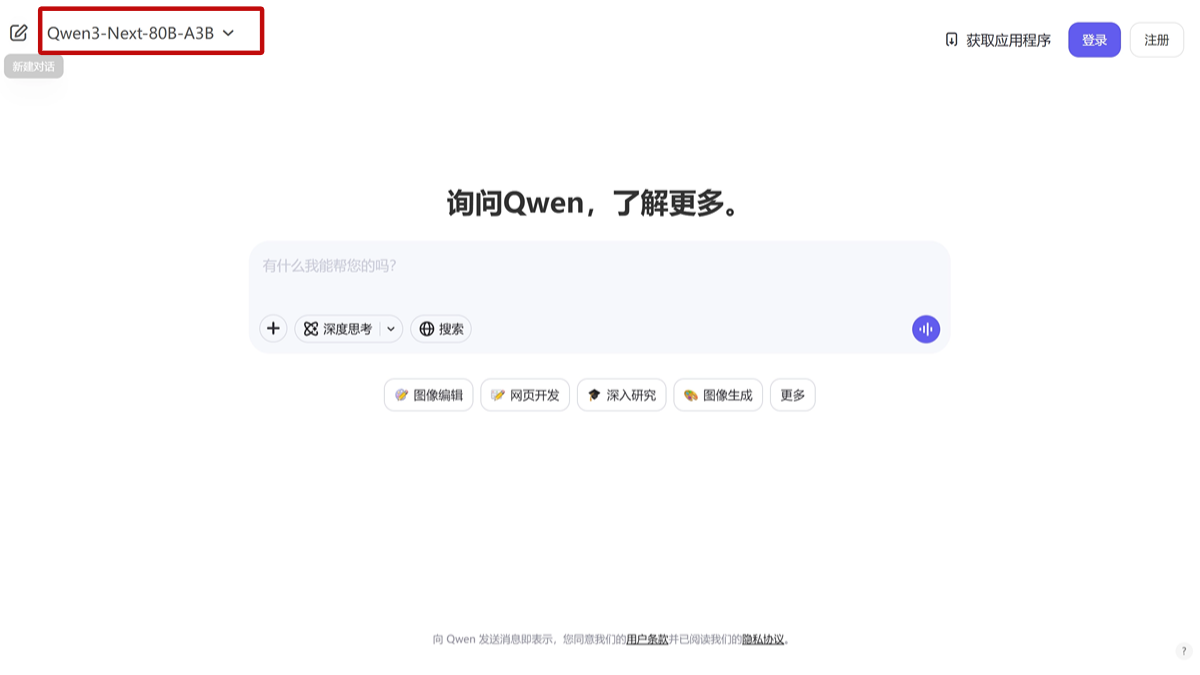
Qwen3-Next - 알리 통이가 출시한 최신 기본 모델
Qwen3-Next는 알리 통이가 오픈소스화한 차세대 하이브리드 아키텍처 빅 모델로, 긴 텍스트 처리, 빠른 추론, 계산 리소스 절약에 능한 Gated DeltaNet과 Gated Attention 기술을 결합한 것입니다.
웬신 빅 모델 X1.1 - 더 나은 이해를 위한 바이두의 딥씽킹 모델
웬신 빅 모델 X1.1은 언어 이해와 생성을 개선하는 데 중점을 둔 하이브리드 강화 학습 프레임워크를 기반으로 바이두에서 출시한 심층 사고 모델입니다. 이 모델은 복잡한 질문을 처리하고, 지시를 따르고, 지능의 행동을 시뮬레이션하는 데 탁월하며, 지식이 풍부한 답변과 고품질 텍스트 콘텐츠를 정확하게 제공할 수 있습니다.

하이브리드 이미지 2.1 - 텐센트의 오픈 소스 벤더 그래프 모델
훈위안이미지 2.1은 고품질 이미지 생성을 위해 설계된 텐센트의 오픈 소스 그래픽 모델입니다. 이 모델은 기본 2K 해상도를 지원하며 복잡한 장면과 디테일을 정확하게 렌더링하여 캐릭터의 표정과 움직임을 생생하게 재현할 수 있습니다.
어니스트 응의 LLM 애플리케이션 개발용 LangChain 무료 강좌
LLM 애플리케이션 개발을 위한 LangChain은 LangChain 창립자 해리슨 체이스와 앤드류 응이 진행하는 온라인 강좌로, DeepLearning.AI에서 제공합니다.
엔다 우의 Transformer LLM 작동 방식에 대한 무료 강좌
트랜스포머 LLM은 딥러닝닷에이아이와 '대규모 언어 모델 실습'의 저자인 제이 알라마르와 마틴 그루텐드가 함께 만든 원리로 작동합니다...

Bytes에서 출시한 최신 이미지 생성 모델인 Seedream 4.0
Seedream 4.0은 바이트댄스에서 출시한 고급 이미지 생성 및 편집 도구로, 정확한 명령어 편집, 높은 기능 보존, 깊은 의도 이해 등의 강력한 기능을 갖춘 생성 및 편집의 통합에 중점을 두고 있습니다.