
Qwen-TTS - 알리 통이 첸첸이 출시한 음성 합성 모델
Qwen-TTS는 알리 통이가 도입한 고급 음성 합성 모델입니다. 이 모델은 텍스트를 자연스럽고 부드러운 음성으로 효율적으로 변환하여 중국어, 영어, 베이징 방언 등 여러 언어와 방언을 지원하여 다양한 지역과 장면의 요구를 충족할 수 있습니다. 대규모 말뭉치 학습에 의존하는 이 모델의 음성 출력은 고품질의 운율이 있는 고품질입니다.

멀티에이전트PPT - 오픈 소스 AI 프레젠테이션 생성 시스템
멀티에이전트PT는 오픈 소스 다중 지능형 AI 프레젠테이션 생성 시스템입니다. 사용자는 주제만 입력하면 시스템이 다중 지능형 협업을 기반으로 개요 생성, 주제 분할, 병렬 연구 및 내용 요약 및 기타 단계를 자동으로 완료하여 고품질 PPT를 신속하게 생성합니다....

Ovis-U1 - Ali에서 출시한 멀티모달 통합 AI 모델
Ovis-U1은 알리바바 그룹의 Ovis 팀이 30억 개의 매개변수 규모로 도입한 멀티모달 통합 모델입니다. 이 모델은 멀티모달 이해, 텍스트-이미지 생성, 이미지 편집의 세 가지 핵심 기능을 갖추고 있으며 고급 아키텍처 설계와 협업 및 통합 교육 방법을 통해 고충실도 이미지 구현을 지원합니다.
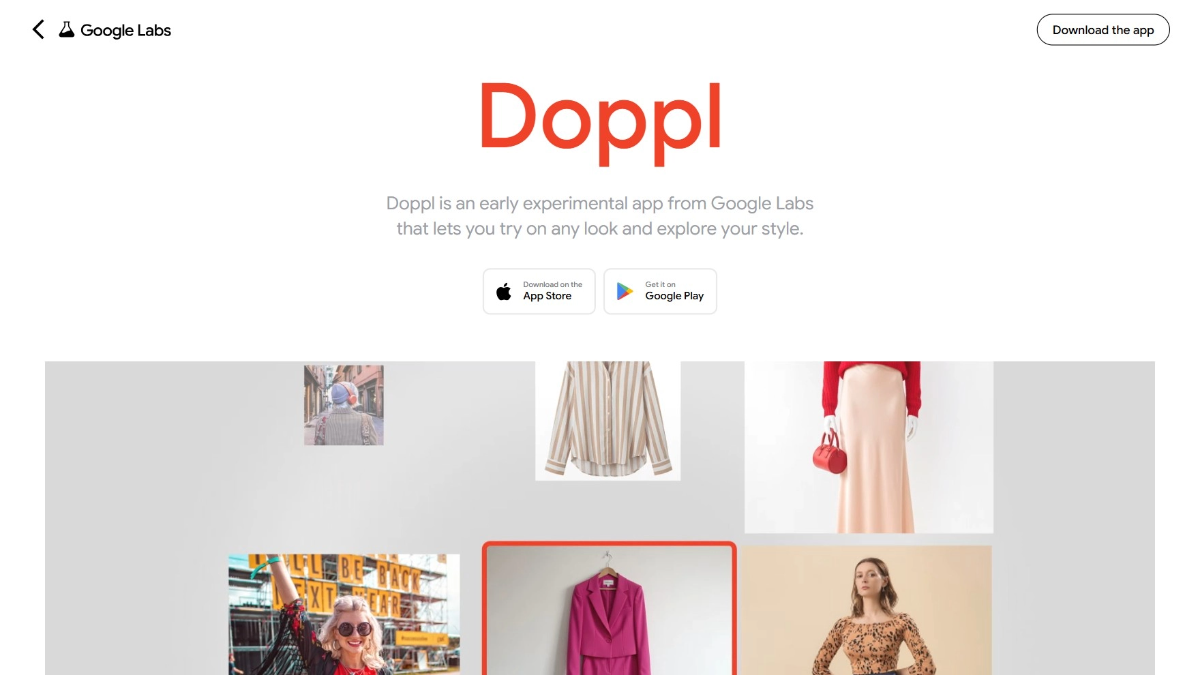
Doppl - Google의 AI 가상 피팅 앱
도플은 구글의 AI 가상 피팅 앱입니다. 사용자가 전신 사진을 업로드하면 애플리케이션은 자신의 신체 디지털 버전에 옷 사진이나 스크린샷을 '착용'하고, 정적인 사진에서 AI가 생성한 동영상으로 변환하여 사용자가 옷이 신체에 미치는 효과를 더욱 실감나게 느낄 수 있도록 지원합니다.

쉰레이 MCP - 쉰레이에서 출시한 AI 자동 다운로드 서비스
쉰레이 MCP는 AI 기술을 기반으로 한 자동 다운로드 서비스인 쉰레이가 출시한 서비스입니다. 서비스를 지원하는 AI 애플리케이션의 사용자가 음성 또는 텍스트 입력으로 다운로드 요청을 하면 AI가 자동으로 네트워크 리소스를 검색하고 다운로드를 시작합니다. 쉰레이 MCP는 기존의 다운로드 방식을 탈피하여 PC 버전의 쉰레이와 NAS 쉰레이를 지원하며, 이를 통해 ...
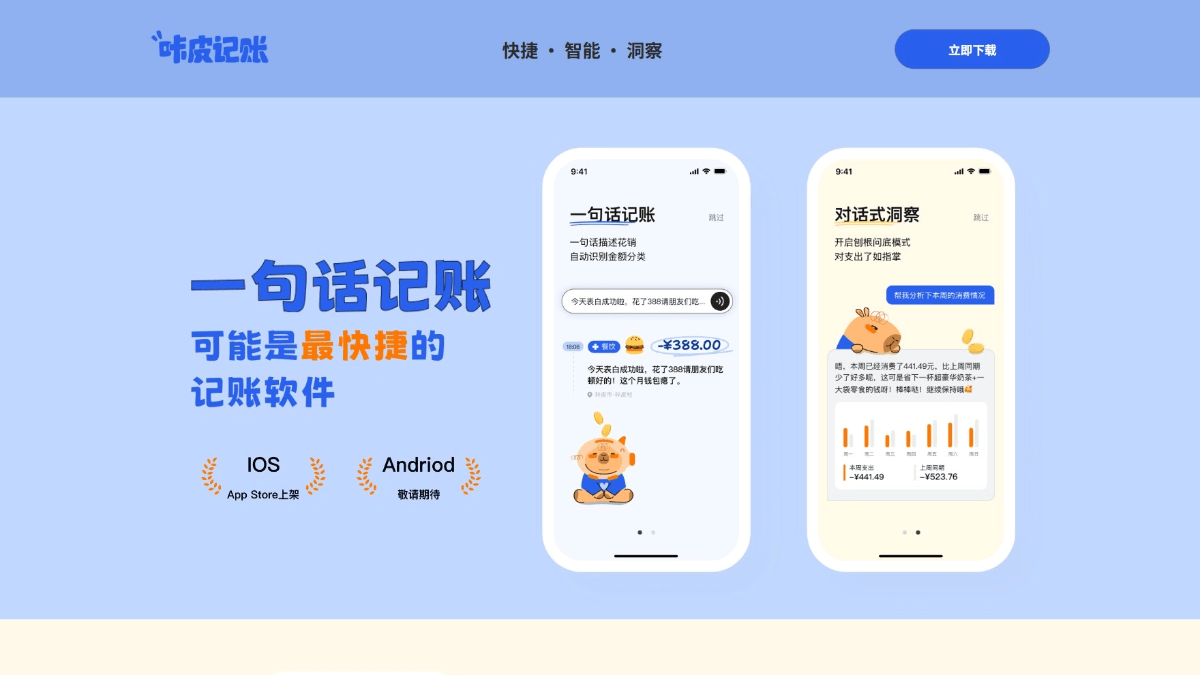
카피 부기 - ShangTech의 지능형 AI 부기 앱
카피 부기는 샹탕 테크놀로지에서 출시한 지능형 AI 부기 애플리케이션입니다. 이 애플리케이션은 자동 부기 기능을 핵심 기능으로 삼아 금액과 카테고리를 자동으로 식별하고 음성 입력을 지원하여 쉽고 편리하게 부기를 할 수 있습니다. 카피 부기는 청구 데이터를 지능적으로 분석하고 정기적으로 개인화된 소비 요약 및 재정 조언을 푸시하여 사용자가 더 나은 ...

Gemini CLI - 구글 오픈 소스 프로그래밍 에이전트
Gemini CLI는 개발자에게 강력한 AI 기능을 제공하기 위해 Gemini 빅 모델을 개발자의 엔드포인트에 통합한 Google의 오픈 소스 AI 프로그래밍 도구입니다. 이 도구는 코드를 이해하고, 파일을 조작하고, 명령을 실행하고, 동적으로 문제를 해결하여 개발자가 효율적으로 생성 코드를 작성할 수 있도록 도와줍니다.
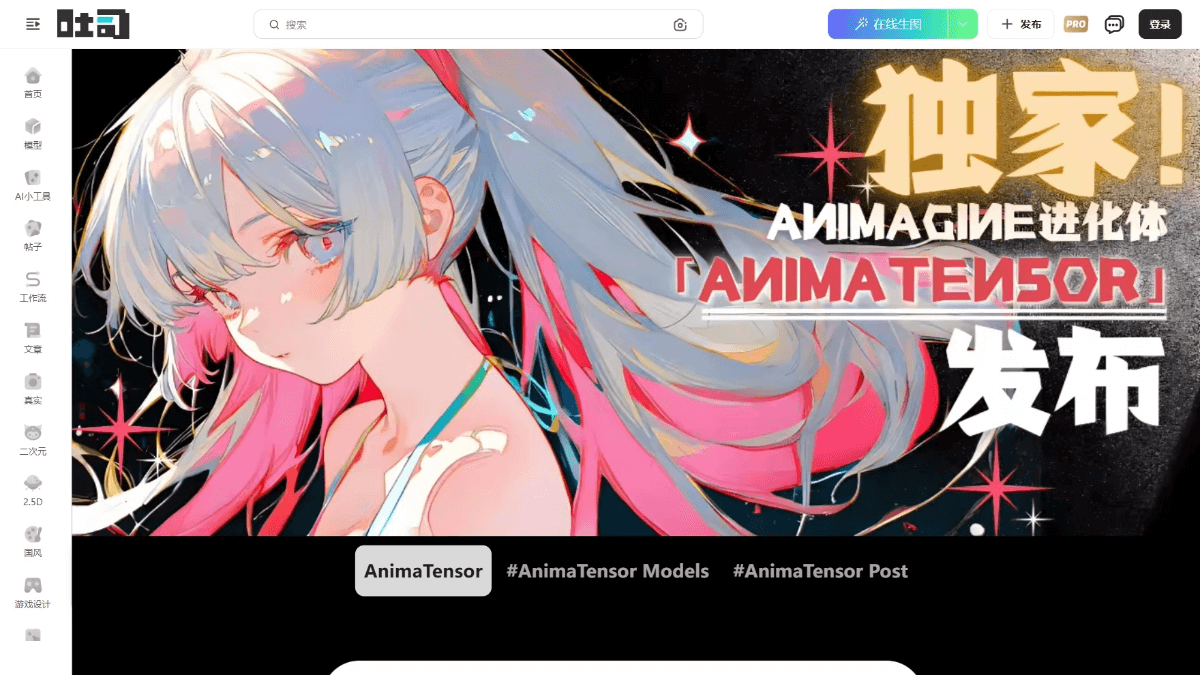
AnimaTensor - Toast AI 등의 2진법 이미지 생성 모델
애니마텐서는 이미지 생성 프로세스의 '속도'를 예측해 노이즈 스케줄링을 최적화하는 혁신적인 V-예측 기법을 기반으로, 칼리오스트로랩 팀이 텐서아트와 협력해 개발한 2차원 이미지 생성 모델입니다....

제미니 로보틱스 온디바이스 - Google, 로컬에서 실행되는 최초의 구현형 인텔리전스 모델 출시
제미니 로보틱스 온디바이스는 구글 딥마인드의 비전 언어 액션 모델로, 로봇의 로컬 실행을 지원합니다. 이 모델은 오프라인에서 작업을 수행하여 자연어 명령에 따라 옷을 접거나 가방을 여는 등의 미세한 작업을 완료할 수 있습니다....
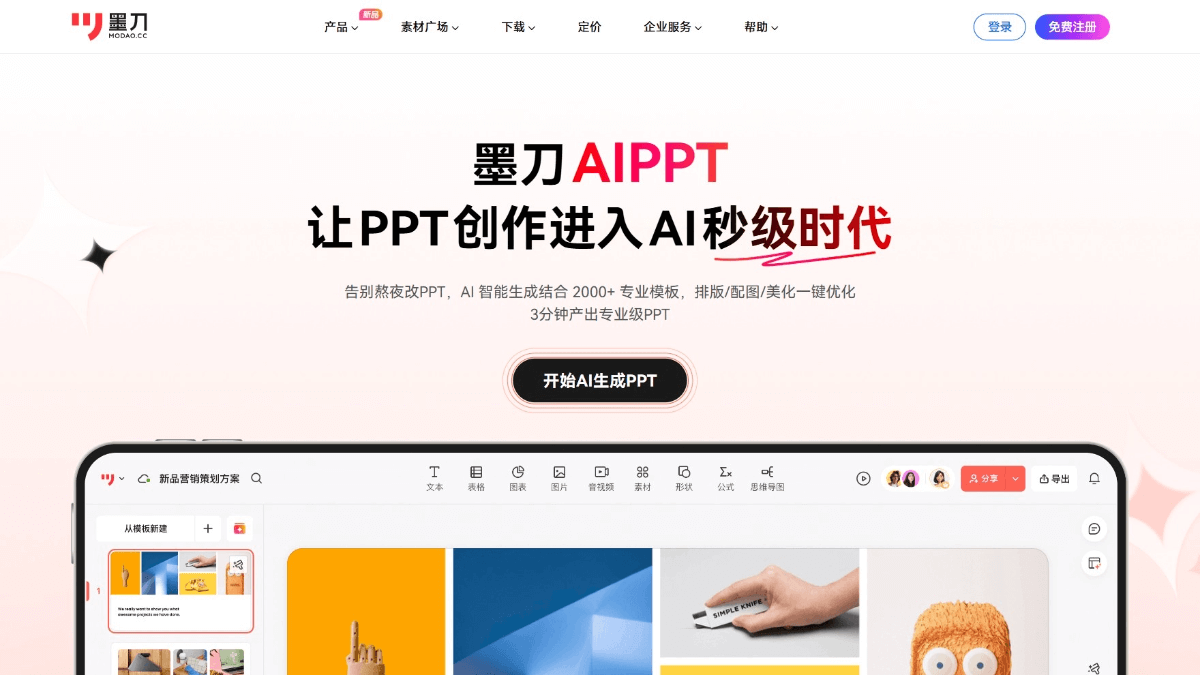
잉크블레이드 AIPPT - 잉크블레이드의 AI PPT 제작 도구는 지능형 레이아웃, 일러스트레이션 및 미화를 지원합니다.
잉크블레이드 AIPPT는 지능형 기술을 기반으로 한 잉크블레이드가 출시한 AI PPT 제작 도구로, PPT 제작 과정을 간소화합니다. 사용자는 테마를 입력하거나 문서를 가져 오기 만하면 AI가 완전한 구조, 디자인 통일성 및 콘텐츠가 풍부한 PPT를 신속하게 생성 할 수 있습니다. 지능형 일치 복사, 차트 및 다이어그램 생성 키가있는 도구, 자체 ...