
Youtu-Embedding - 텐센트 유튜브 오픈소스 일반 텍스트 표현 모델
Youtu-Embedding은 엔터프라이즈급 애플리케이션을 위해 설계된 Tencent의 Youtu Labs에서 개발한 오픈 소스 범용 텍스트 표현 모델입니다. 텍스트는 심층 신경망에 의해 고차원 벡터 공간에 매핑되어 의미적으로 유사한 문장이 해당 공간에서 서로 가깝게 배치되어 정확한 의미 검색을 달성합니다.

SAIL-VL2 - ByteHop의 오픈 소스 멀티모달 시각 언어 모델
SAIL-VL2는 이미지와 텍스트와 같은 멀티모달 입력의 공동 모델링에 중점을 둔 Byte Jump 팀의 오픈 소스 멀티모달 시각 언어 모델입니다. 전문가(MoE) 아키텍처와 점진적 훈련 전략의 희소 혼합을 사용하여 2B~8B의 매개변수 규모, 특히 그래픽 이해, 수학적 이해에서 높은 성능을 달성합니다.

MineContext - 바이트 오픈 소스 액티브 컨텍스트 인식 AI 파트너
MineContext는 사용자가 방대한 양의 정보를 효율적으로 관리하고 지식 업무의 효율성을 개선할 수 있도록 돕기 위해 ByteDance Viking 팀이 오픈소스로 제공하는 적극적인 상황 인식 AI 파트너입니다. 스크린샷 및 콘텐츠 이해 기술을 통해 사용자의 일상적인 작업(예: 웹 검색, 문서 편집 등)을 자동으로 기록하고, 지원...

나노챗 - Karpathy의 무료 오픈소스 저비용 모델 교육 프로젝트
나노챗은 AI의 전설이자 전 테슬라 AI 디렉터인 안드레이 카르파티가 공개한 오픈 소스 프로젝트로, 개인이 매우 저렴한 비용과 단순함으로 작은 ChatGPT와 유사한 언어 모델을 빠르게 훈련할 수 있도록 해줍니다. 전체 프로젝트는 약 800개만 사용합니다.
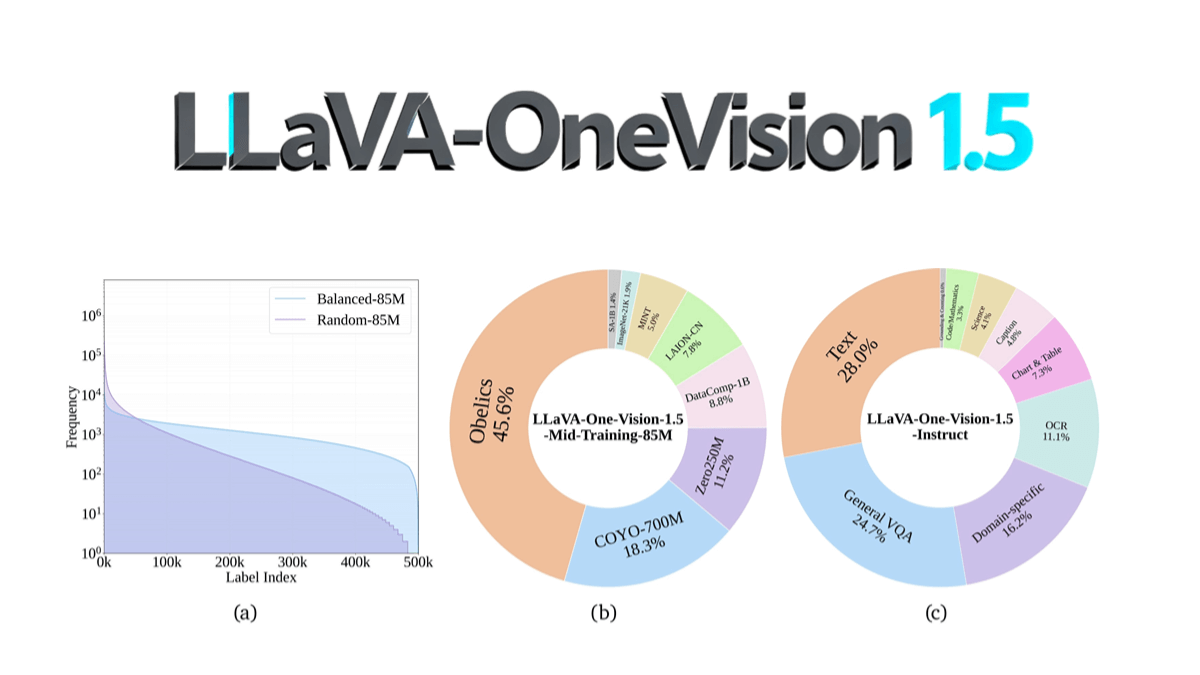
LLaVA-OneVision-1.5 - 고성능 멀티모달 이해를 위한 무료 오픈 소스 멀티모달 모델
LLaVA-OneVision-1.5는 128개의 A800...에서 8B 파라미터 스케일을 사용하는 EvolvingLMMS-Lab 팀의 오픈 소스 멀티모달 모델로, 컴팩트한 3단계 훈련 프로세스(언어-이미지 정렬, 개념 평형화 및 지식 주입, 명령어 미세 조정)를 통해 학습합니다.
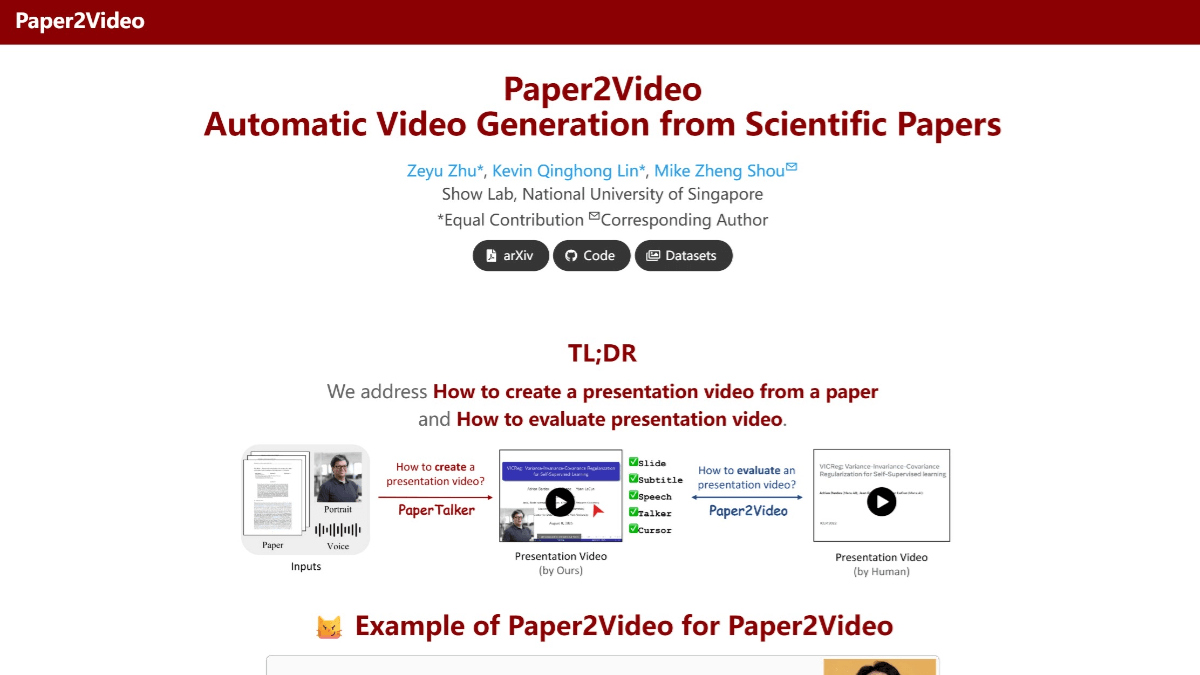
Paper2Video - 학술 논문의 데모 동영상을 자동으로 생성하는 NUS 오픈 소스 프로젝트
Paper2Video는 싱가포르 국립대학교 쇼 랩에서 학술 논문을 위한 자동 프레젠테이션 비디오 생성을 위한 오픈 소스 프로젝트입니다. PaperTalker 다중 지능 프레임워크를 사용하여 논문을 슬라이드, 자막, 음성 해설 및 발표자 아바타가 포함된 완전한 프레젠테이션 비디오로 변환합니다....

NeuTTS Air - 오프라인 CPU 실행을 지원하는 무료 경량 음성 합성 모델
NeuTTS Air는 Neuphonic 팀이 개발한 오픈 소스 경량 음성 합성 모델로, 클라우드에 의존하지 않고 로컬 장치(예: 휴대폰, 노트북, 라즈베리파이)에서 실시간으로 실행할 수 있습니다. 0.5B 매개변수 Qwen 아키텍처와 자체 개발한 NeuCodec 코덱 사용...

KAT-Dev-72B-Exp - 레이서 오픈 소스 무료 프로그래밍 전용 모델
KAT-Dev-72B-Exp는 레이서 팀에서 출시한 오픈소스 프로그래밍 전용 대규모 언어 모델로, 강화 학습 기법을 기반으로 최적화되어 SWE-Bench Verified 벤치마크 테스트에서 현재 오픈소스 모델 중 최고 성능인 74.6%의 정확도를 달성했습니다. 이 모델은 혁신적인...

잠바 추론 3B - 이스라엘 AI21 랩의 오픈 소스 경량 추론 모델
잠바 추론 3B는 이스라엘의 AI 스타트업 AI21 Labs에서 오픈소스로 제공하는 경량 추론 모델로, 강력한 성능과 다양한 애플리케이션에 적용할 수 있는 잠재력을 갖추고 있습니다. 이 모델은 Trans...를 결합한 하이브리드 SSM-트랜스포머 아키텍처를 사용합니다.
에른스트 우의 에이전틱 AI의 최신 인텔리전스에 대한 무료 강좌
에이전틱 AI는 어니스트 응이 출시한 지능형 바디에 관한 최신 강좌로, 반영, 도구 사용, 계획 및 다중 지능형 바디 협업의 네 가지 설계 패턴을 다루는 지능형 바디의 설계 및 구축에 중점을 둡니다. 학습자는 이론적 설명과 코드 실습을 통해 지능형 바디가 출력을 확인하고 자율적으로 조정하는 방법을 익히게 됩니다....