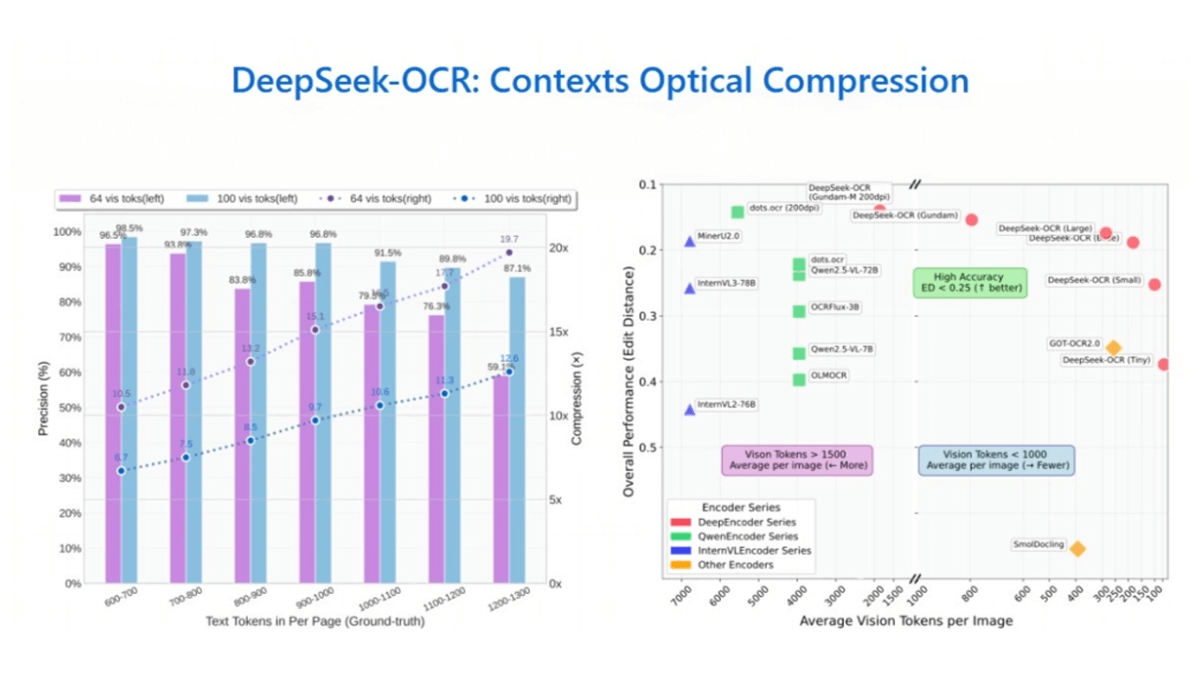
DeepSeek-OCR - 딥시크릿 오픈 소스 광학 문자 인식 모델
딥시크-OCR은 딥시크 팀이 오픈소스화한 고급 광학 문자 인식(OCR) 모델로, '문맥 광학 압축' 기술을 통해 텍스트를 이미지로 변환하고 압축 및 디코딩에 비주얼 토큰을 사용해 긴 텍스트를 효율적으로 처리합니다.

비타벤치 - MMT 롱캣 오픈소스 대화형 에이전트 리뷰 벤치마크
비타벤치는 메이투안의 롱캣 팀이 발표한 복잡한 생활 시나리오를 위한 최초의 대화형 에이전트 평가 벤치마크로, 실제 생활 시나리오에서 대규모 모델 지능의 종합적인 기능을 평가합니다. 테이크아웃 주문, 레스토랑 식사, 여행의 세 가지 빈도가 높은 생활 시나리오는 패키지를 구축하기 위한 캐리어로 사용됩니다....
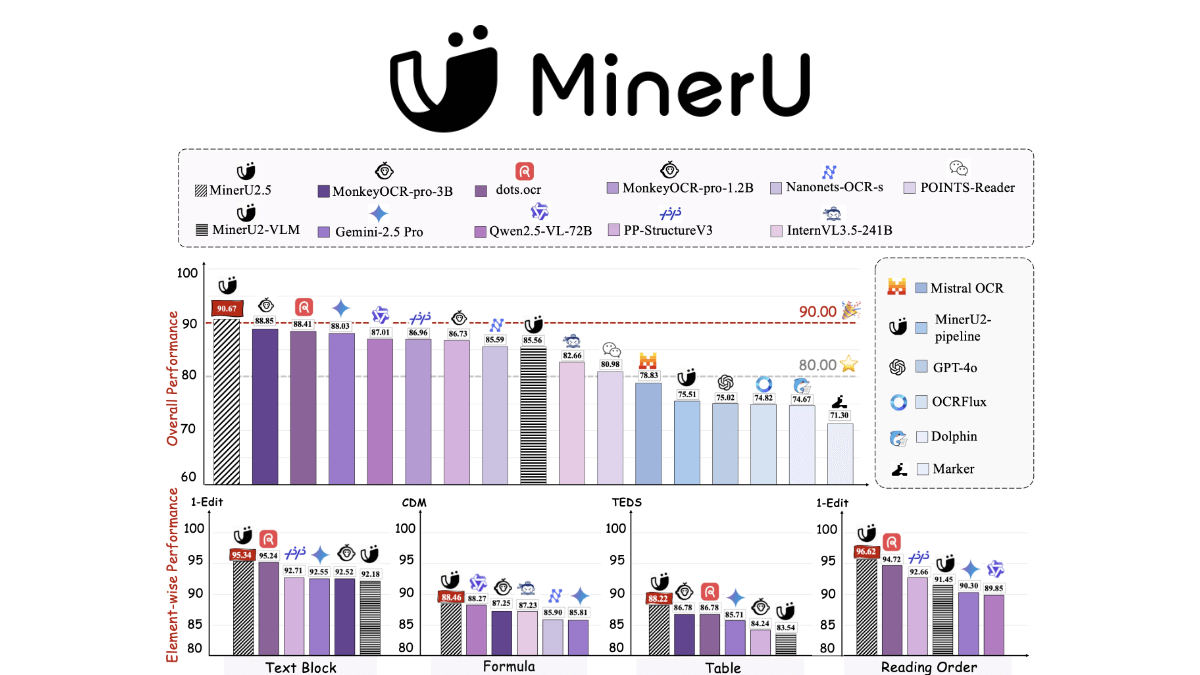
MinerU2.5 - 상하이 AI Lab과 북경대학교 오픈 소스 문서 구문 분석 모델
MinerU2.5는 상하이 인공지능 연구소와 북경대학교 팀이 공동으로 개발한 분리형 시각 언어 모델로, 고해상도 문서 이미지 구문을 효율적으로 처리하는 데 중점을 두고 있습니다. 핵심 혁신은 "글로벌 레이아웃 감지 후 로컬 콘텐츠 인식"의 2단계 설계에 있습니다. 첫 번째 단계는 저해상도...

롱캣-오디오 코덱 - 메이투안 롱캣 오픈 소스 음성 코덱 솔루션
롱캣-오디오 코덱은 메이투안의 롱캣 팀이 개발한 오픈소스 음성 코덱 솔루션입니다. 이 솔루션은 의미론적 및 음향학적 이중 토큰 병렬 추출 메커니즘을 통해 음성의 의미론적 및 음향학적 특징을 고려한 음성 대규모 언어 모델(Speech LLM)용으로 설계되었습니다 ...

PaddleOCR-VL - 바이두 오픈 소스 초경량 시각 언어 모델
PaddleOCR-VL은 문서 구문 분석 시나리오에 최적화된 바이두의 오픈 소스 초경량 시각 언어 모델입니다. 이 모델은 동적 고해상도 시각 코더와 경량 ERNIE 언어 모델의 융합을 통해 0.9억 개의 파라미터만 포함하며, 높은 정확도를 유지하고 계산 오버헤드를 크게 줄입니다.
유니픽셀 - 홍콩 폴리테크닉, 텐센트, 중국과학원 등이 오픈소스로 제공하는 픽셀 수준의 멀티모달 모델입니다.
유니픽셀은 픽셀 수준의 시각 언어 이해를 달성하기 위해 홍콩 폴리테크닉 대학교, 텐센트, 중국과학원, Vivo가 공동으로 제안한 새로운 멀티모달 모델입니다. 객체 참조 및 분할 기능을 통합하여 이미지 분할, 비디오 분할, 영역 이해 및 파이분할과 같은 다양한 세분화된 작업을 지원합니다.
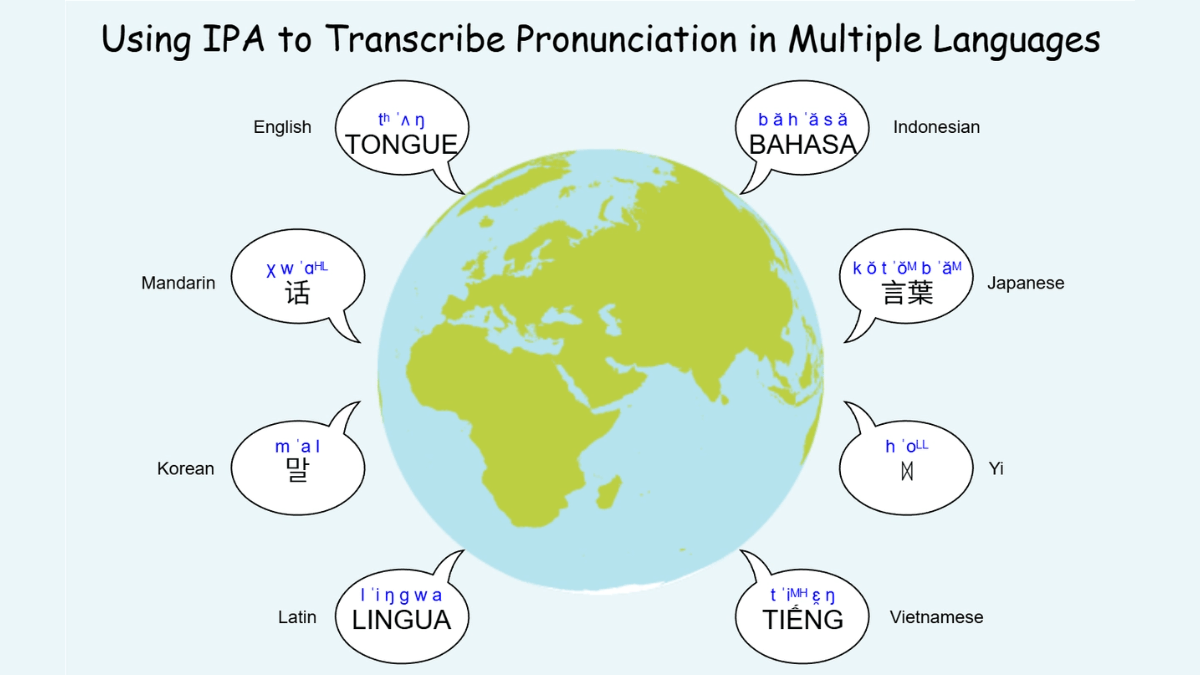
DiaMoE-TTS - 칭화 및 거대 네트워크 오픈 소스 다중 방언 음성 합성 프레임워크
DiaMoE-TTS는 방언 데이터 부족, 직교 불일치, 복잡한 음운 변화 문제를 해결하기 위해 칭화대학교와 거대 네트워크가 공동으로 오픈소스화한 다중 방언 음성 합성 프레임워크로, 국제 음성 알파벳(IPA)을 기반으로 합니다. 통합된 IPA 프런트엔드 표준화된 음소 표현을 통해 방언 간 차이를 제거하여 ...
칸딘스키 5.0 - 러시아 AI 팀의 오픈 소스 비디오 생성 모델 시리즈
칸딘스키 5.0은 러시아 AI 팀이 개발한 최신 비디오 생성 모델 시리즈로, 가벼운 디자인과 고성능 성능에 중점을 두고 있습니다. 이 시리즈의 첫 번째 모델인 칸딘스키 5.0 비디오 라이트는 매개 변수가 20억 개에 불과하지만, 특히 유사한 14억 개에 달하는 모델을 능가합니다.

송블룸 - 홍콩중문대 및 NTU와 협력한 텐센트의 오픈 소스 곡 생성 모델
송블룸은 홍콩 중문대학교(선전) 및 난징대학교와 협력하여 Tencent AI Lab에서 개발한 오픈 소스 노래 생성 모델로, AI 음악 생성의 '가소성' 문제를 해결하고 구조적으로 완벽한 고품질의 노래를 생성할 수 있습니다. 10초 분량의 레퍼런스 오디오와 해당 가사를 입력하기만 하면...

Pyscn - Python 개발자를 위한 무료 AI 코드 품질 분석 도구 오픈 소스
Pyscn은 파이썬 개발자가 코드의 잠재적 문제를 감지하여 유지보수성을 개선할 수 있도록 설계된 지능형 코드 품질 분석 도구입니다. 제어 흐름도를 통해 데드 코드를 분석하고, APTED+LSH 알고리즘을 사용하여 중복 코드를 식별하고, 모듈 결합 및 원 복잡도와 같은 메트릭을 계산합니다....