
Depth Anything 3 - 바이트홉 시드 오픈소스를 위한 3D 시각적 재구성 모델
뎁스 애니씽 3(DA3)은 Byte Jump Seed 팀이 개발하여 오픈소스화한 3D 시각적 재구성 모델입니다. 단일 트랜스포머 아키텍처를 통해 모든 시점에서 공간 지오메트리를 재구성할 수 있으며, 뎁스 맵과 레이 맵만 예측하면 3D 장면을 복원할 수 있습니다.
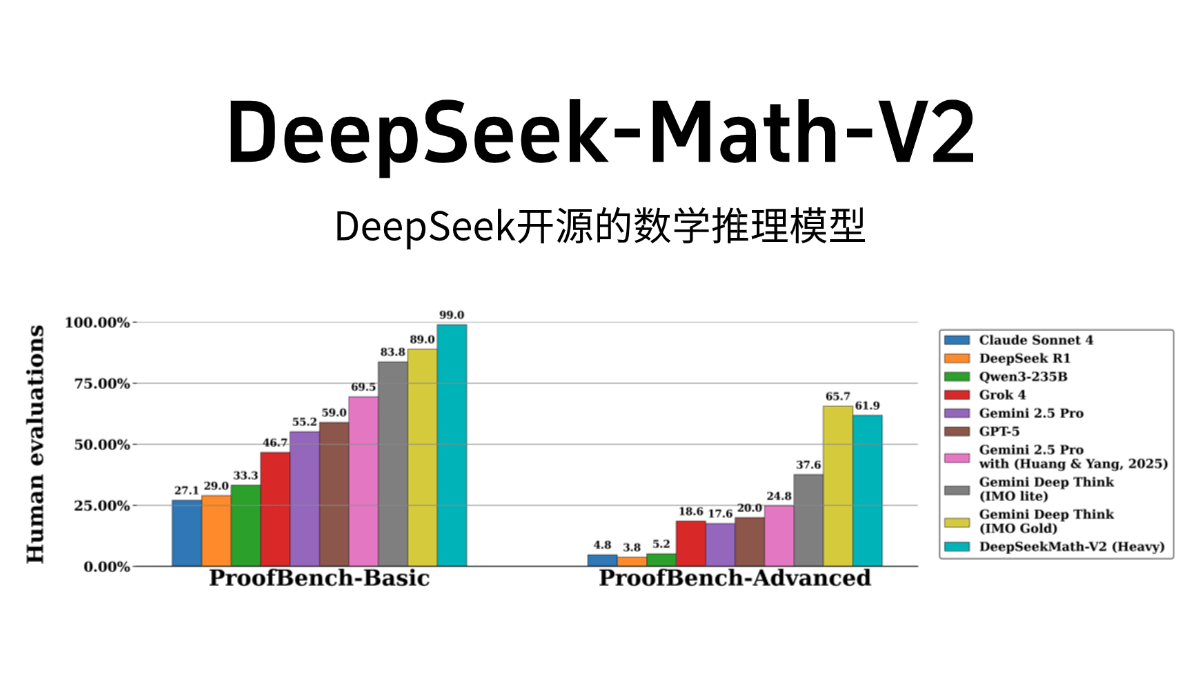
DeepSeek-Math-V2 - 딥시크 오픈 소스 수학적 추론 모델
DeepSeek-Math-V2는 팬텀 큐브 산하의 인공지능 회사 딥시크의 오픈소스 수학 추론 모델로, 최신 버전은 딥시크-V3.2-Exp-Base를 기반으로 개선되어 제미니 딥씽크의 성능을 능가하는 국제적인 수치를 달성했습니다....

Z-Image - 알리 통이 연구소의 오픈 소스 이미지 생성 모델
Z-Image는 효율적이고 빠르며 강력한 이미지 생성 기능을 갖춘 알리 통이 연구소의 오픈 소스 이미지 생성 모델입니다. 단일 스트림 확산 트랜스포머 아키텍처(S3-DiT)를 사용하여 텍스트, 시각적 의미 및 이미지 VAE 토큰을 통합된 입력 스트림으로 통합합니다....

ROCK - 지능형 신체 훈련 환경을 위한 알리바바의 오픈 소스 샌드박스
ROCK(Reinforcement Open Construction Kit)은 알리바바의 인공지능 훈련 환경을 위한 오픈소스 샌드박스로, 실제 환경에서 인공지능을 대규모로 훈련할 수 없는 문제를 해결하며, 매우 안정적인 샌드박스 관리 서비스를 제공합니다....

홍콩대학교의 오픈 소스 멀티 인텔리전트 바디 비디오 생성 프레임워크인 ViMax
ViMax는 홍콩대학교 데이터 과학 연구소의 오픈 소스 다중 지능 바디 비디오 생성 프레임워크로, 크리에이티브 입력부터 비디오 출력까지 전체 프로세스를 자동화할 수 있습니다. 스크립트 생성, 장면 디자인, 샷 계획 및 비디오 렌더링 등을 통합하여 사용자가 자연어 설명을 통해 일관된 영화 및 텔레비전 등급 비디오를 생성할 수 있도록 지원합니다.

FLUX.2 - 블랙 포레스트 오픈 소스 이미지 생성 및 편집 모델
FLUX.2는 블랙 포레스트 랩에서 출시한 오픈 소스 이미지 생성 및 편집 모델로, 텍스트 원시 이미지, 다중 이미지 참조, 풍부한 디테일, 선명한 질감, 안정적인 조명으로 이미지 편집을 지원합니다. FLUX.2 [프로](최상위 클로즈드 소스에 필적하는...
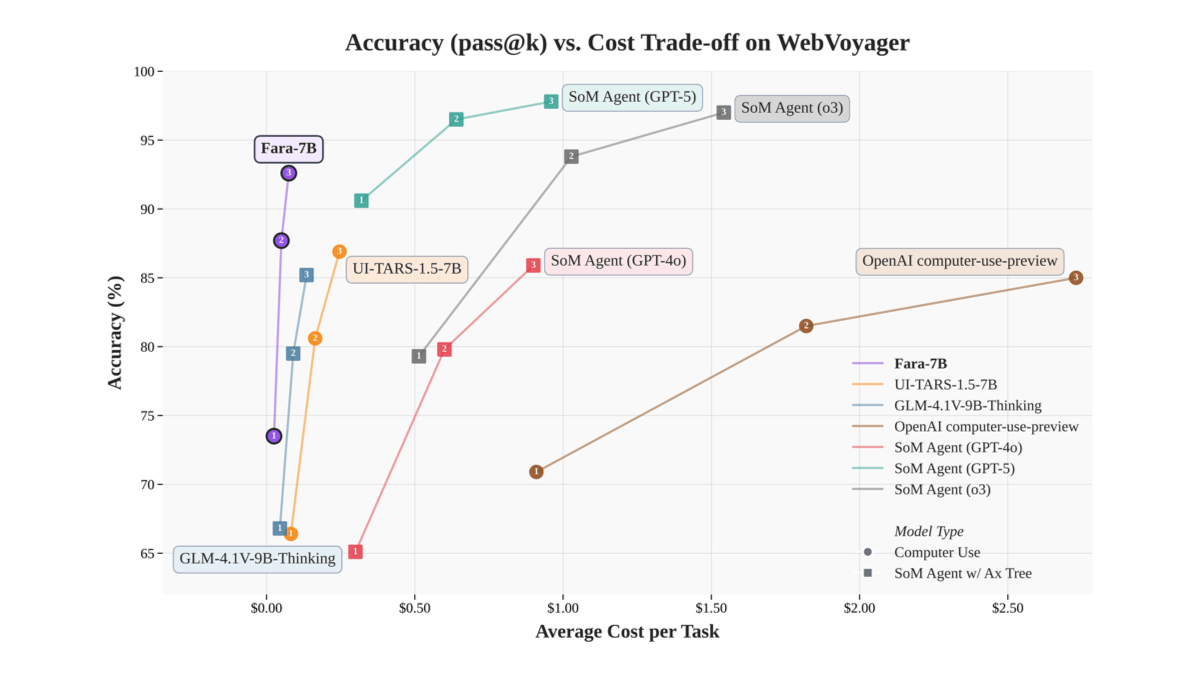
Fara-7B - Microsoft의 오픈 소스 컴퓨터 운영 에이전트 어시스턴트 모델
Fara-7B는 Qwen 2.5-VL-7B 아키텍처를 기반으로 하는 70억 개 매개변수 규모의 컴퓨터 운영 에이전트(CUA) 모델의 Microsoft 오픈 소스 릴리스입니다. 웹 페이지의 스크린샷을 시각적으로 구문 분석하고 화면에서 클릭, 입력 등을 수행함으로써 추가적인 접근성 트리나 여러 개의 대형 모델에 의존할 필요가 없습니다....

HunyuanOCR - 광학 문자 인식을 위한 텐센트의 오픈 소스 전문가 모델
훈위안OCR은 텐센트 하이브리드 팀이 오픈소스화한 고성능 광학 문자 인식 모델로, 10억 개의 레퍼런스만 보유하고 있습니다. 하이브리드 멀티모달 아키텍처를 기반으로 개발된 이 모델은 엔드투엔드 설계를 채택하여 텍스트 감지, 인식 및 문서 구문 분석 작업을 효율적으로 처리할 수 있습니다. 이 모델은 복잡한 문서 테스트에서 94.1점을 획득하여 ...

슈퍼토닉 - 빠른 속도로 오프라인에서 실행되는 오픈 소스 고성능 AI 텍스트 음성 변환 시스템입니다.
슈퍼토닉은 로컬 장치에서 빠른 음성 생성에 초점을 맞춘 오픈 소스 고성능 텍스트 음성 변환(TTS) 시스템입니다. ONNX 런타임 기술을 사용하여 휴대폰, 컴퓨터, 심지어 라즈베리 파이와 같은 장치에서 실행할 수 있고 23개 언어와 음성 클론을 지원하며 네트워크가 필요하지 않습니다....

MiMo-Embodied - 샤오미의 오픈 소스 크로스 도메인 구현 인텔리전스 페데스탈 모델
MiMo-Embodied는 샤오미 그룹이 오픈소스화한 세계 최초의 교차 구현형 기본 모델로, 구현형 AI와 자율주행을 성공적으로 통합했습니다. 이는 구현형 AI와 자율 주행 간의 지식 마이그레이션 문제를 해결하고 두 영역의 작업을 통합 모델링합니다.