
인스턴스어셈블 - 리틀 레드북과 푸단대학교 오픈 소스 레이아웃 제어 생성 기술
인스턴스어셈블은 샤오홍슈와 푸단대학교가 공동으로 오픈소스화한 레이아웃 제어 생성 기술로, '인스턴스 어셈블 주의' 메커니즘을 통해 단순한 레이아웃에서 복잡한 레이아웃, 희박한 레이아웃에서 조밀한 레이아웃까지 정확한 이미지 생성을 달성합니다. 먼저 이미지 배경에 2단계 캐스케이드 아키텍처를 채택한 다음 하나씩 하나씩 ...
Zen Browser - 파이어폭스 커널 기반의 오픈 소스 AI 웹 브라우저
Zen 브라우저는 Firefox 커널 기반의 오픈 소스 브라우저로, 세로 탭 표시줄 및 작업 공간 분리와 같은 핵심 기능을 통해 간단하고 효율적인 브라우징 경험에 중점을 두고 있습니다. 사이드바 디자인으로 50개 이상의 탭의 전체 제목을 명확하게 표시하고 다중 창 분할 화면 브라우징을 지원합니다.
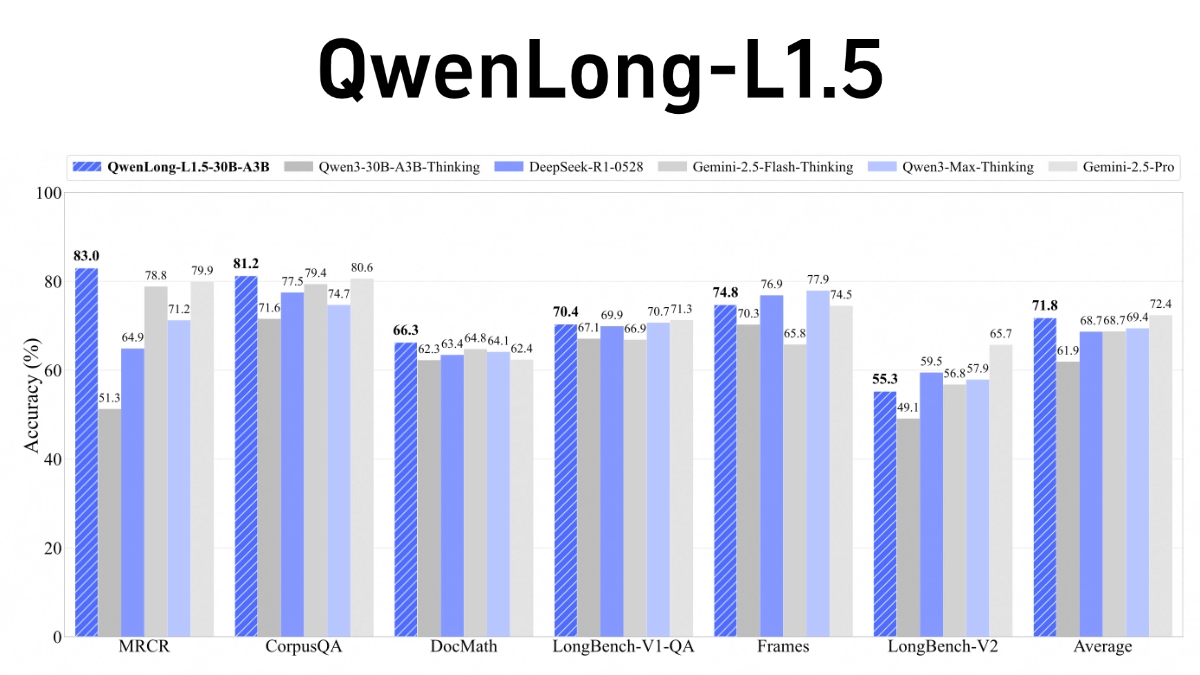
QwenLong-L1.5 - 알리 통이 연구소 오픈 소스 긴 텍스트 추론 모델
QwenLong-L1.5는 알리바바 통이 연구소의 오픈 소스 긴 텍스트 추론 모델로, 매우 긴 컨텍스트(예: 100만~4백만 토큰)의 복잡한 추론 문제를 해결하는 데 중점을 둡니다. 핵심 혁신은 지식 그래프, SQL 구문 분석 및 다중 지능을 통한 학습 후 단계의 세 가지 주요 혁신에 있습니다 ...
인포그래픽 - Ali AntV 팀 오픈 소스 인포그래픽 생성 프레임워크
인포그래픽은 G2 및 앤트 디자인 개발을 기반으로 한 차세대 Ali AntV 팀 오픈 소스 프레임워크로, 고품질 인포그래픽의 빠른 생성에 중점을 두고 30개 이상의 레이아웃 템플릿, 120개 이상의 사전 설정 테마 및 AI 지능형 생성 기능을 제공합니다.
opcode - 클로드 코드용으로 설계된 오픈 소스 그래픽 데스크톱 애플리케이션
opcode는 클로드 코드 오픈 소스 그래픽 데스크톱 애플리케이션, Tauri 2 + React 18 + Rust 개발을 기반으로 한 개발자 winfunc를 위해 설계되었습니다. 클로드 코드 프로젝트를 관리하기위한 시각적 인터페이스 제공, 생성 지원 ...
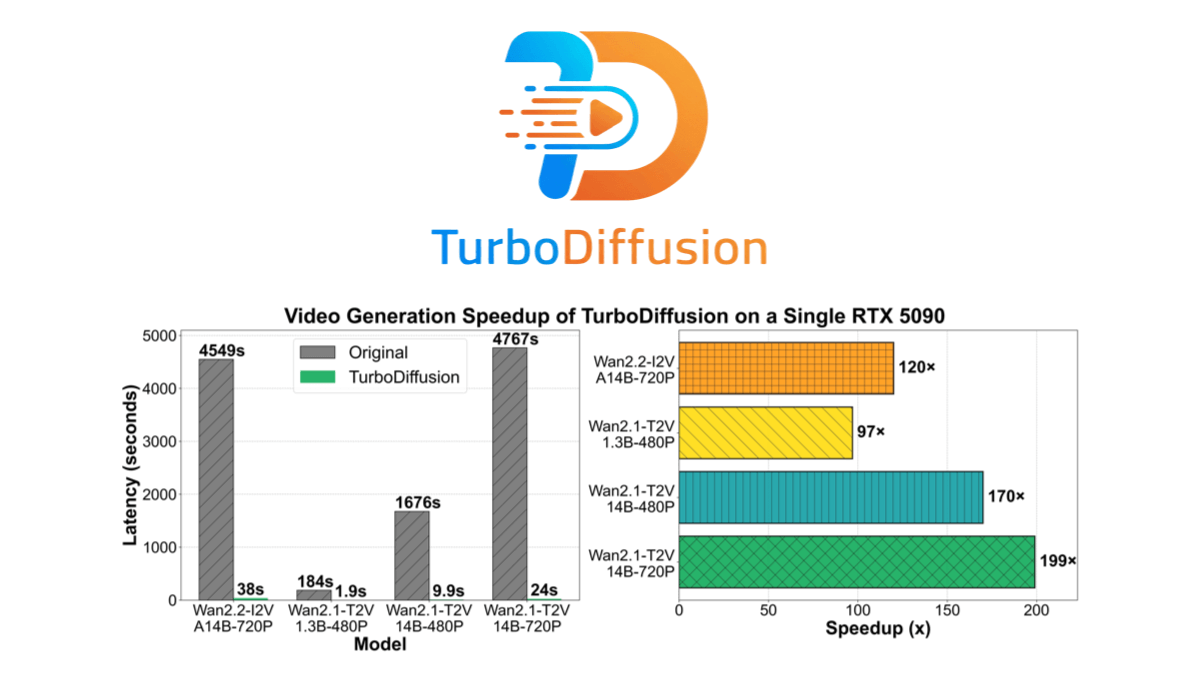
TurboDiffusion - 원시 디지털 기술, 칭화 및 기타 오픈 소스 비디오 생성 가속 프레임워크
터보디퓨전은 칭화대학교, 바이오디지털 테크놀로지, UC버클리가 공동으로 오픈소스화한 동영상 생성 가속 프레임워크로, 거의 무손실 화질을 유지하면서 동영상 생성 속도를 100~200배까지 향상시킬 수 있습니다. 스파스 선형 주의, 샘플 단계 증류 및 8비트...

MedASR - Google의 오픈 소스 의료 음성 인식 모델
MedASR은 구글이 오픈소스화한 1억 5천만 개의 파라미터 의료 음성 인식 모델로, 5,000시간의 감작된 임상 말뭉치를 기반으로 미세 조정되어 약물, 용량 및 해부학 용어에 최적화되어 있으며, 6그램의 의료 언어 모델이 내장되어 있고 민간 방사선 데이터 세트 RAD-DICT에서 단어 오류율이 4.6에 불과합니다....

Fun-Audio-Chat-8B - 알리 통이의 오픈 소스 엔드투엔드 음성 인터랙션 매크로 모델
Fun-Audio-Chat-8B는 알리 통이 팀의 오픈 소스 80억 매개 변수 엔드 투 엔드 음성 빅 모델, 음성 출력에서 직접 음성, ASR + LLM + TTS 접합 필요 없음, 중국어와 영어에 유창하며 지연 시간이 짧고 자연스러운 음색을 가진 이중 언어입니다. 25Hz의 이중 해상도 공유 LLM 사용...

PromptFill - AI 페인팅을 위해 설계된 오픈 소스 구조화된 큐 워드 생성 AI 도구
PromptFill은 AI 드로잉을 위해 설계된 구조화된 큐 생성 도구로, 시각적 '빈칸 채우기' 상호 작용을 통해 복잡한 프롬프트를 빠르게 구축, 관리 및 반복하여 AI 이미지 생성의 효율성과 품질을 향상시킵니다.PromptFill의 핵심 기능...
GLM-4.7 - Wisdom Spectrum AI 오픈 소스의 최신 세대 플래그십 대형 모델
GLM-4.7은 AI 프로그래밍, 복잡한 추론 및 지능형 신체 작업에 심도 있게 최적화된 스마트 스펙트럼 AI에서 출시하고 오픈소스로 제공하는 최신 플래그십 그랜드 모델입니다. 이 모델은 다국어 코딩, 장거리 작업 계획 및 도구 협업 기능을 통해 200k 컨텍스트 길이와 최대 128k 출력을 지원합니다....