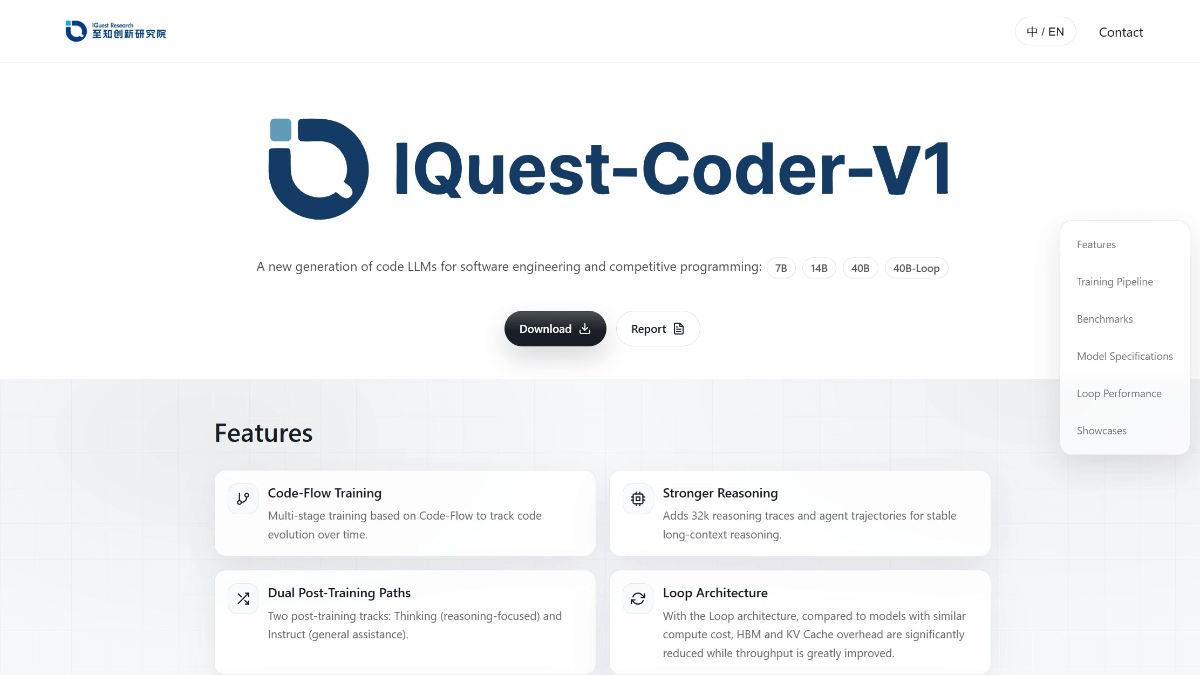
IQuest-Coder-V1 - 至知创新研究院开源的代码大模型系列
IQuest-Coder-V1是九坤投资旗下至知创新研究院研发的开源代码大模型系列,专注于代码智能领域,具备自动编程、Bug修复和代码解释等能力。模型采用创新的Code-Flow训练范式,从代码库演化...

혼합 모션 1.0 - 텐센트 혼합 모션 팀 오픈 소스 텍스트 생성 3D 모션 모델
하이브리드 모션1.0(HY-Motion1.0)은 텐센트 하이브리드 팀의 오픈 소스 텍스트 생성 3D 액션 모델로, 10억 개의 파라미터 확산 트랜스포머 아키텍처를 사용하여 고품질 3D 캐릭터 애니메이션의 자연어 설명을 통해 직접 생성할 수 있습니다.
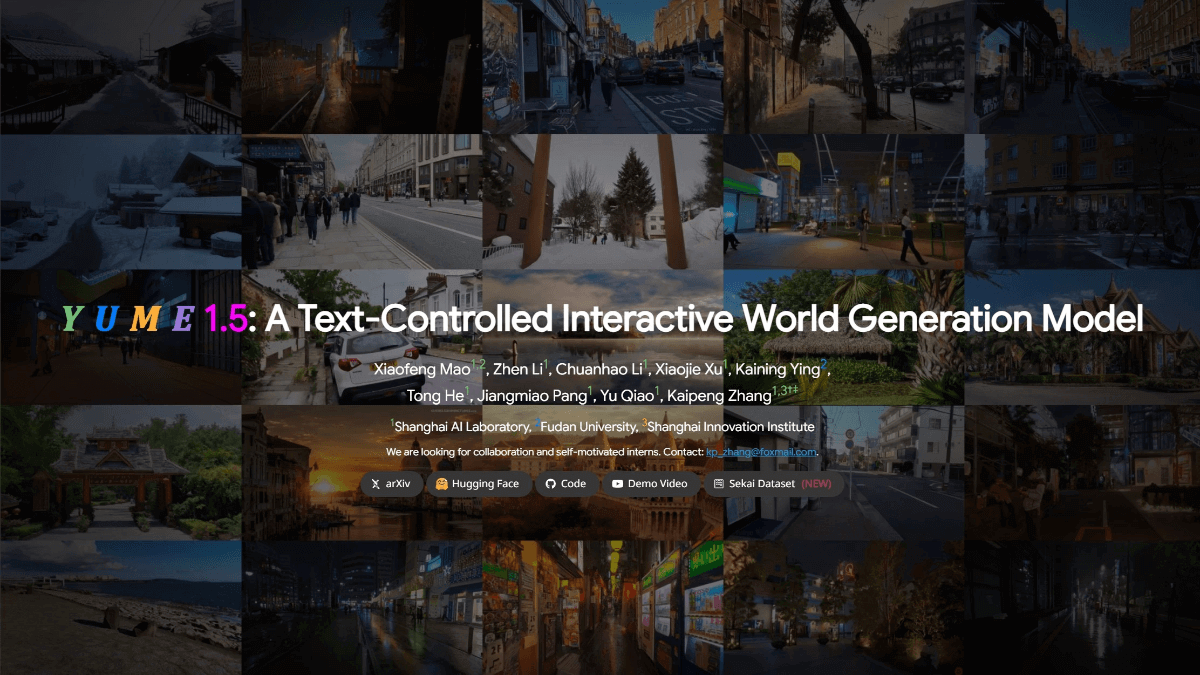
Yume1.5 - 상하이 인공지능 연구소와 푸단대학교에서 오픈소스화한 인터랙티브 월드 제너레이션 모델
Yume 1.5는 상하이 인공지능 연구소, 푸단대학교, 상하이 혁신 연구소가 공동 개발한 오픈 소스 인터랙티브 월드 생성 모델로, 실시간 인터랙티브 렌더링(단일 카드에서 12FPS)이 가능합니다. 컨텍스트 길이가 증가하더라도 공동 시공간 채널 모델링(TSCM) 기술을 채택하여...

AutoMV - 베이퍄오, NU 등과 연계한 M-A-P 오픈 소스 무료 뮤직비디오 생성 시스템
AutoMV는 M-A-P 팀이 여러 대학과 협력하여 개발한 오픈 소스 뮤직비디오 생성 시스템으로, 교육 없이도 완성된 곡을 기반으로 일관된 뮤직비디오를 자동으로 생성할 수 있으며, 음악 분석, 대본 작성, 연출 및 품질 관리 모듈을 포함한 다중 지능 협업 모델을 채택하여 가사, 비트 등을 정확하게 분석할 수 있습니다....

Tencent-HY-MT1.5 - 텐센트 하이브리드 오픈 소스 번역 모델 시리즈
텐센트 하이브리드 오픈 소스 번역 모델 버전 1.5는 1.8B와 7B 두 가지 모델을 포함하여 33 개 국제 언어와 5 가지 중국어 및 중국어 / 방언 번역을 지원하는 텐센트 하이브리드 오픈 소스 번역 모델 버전 1.5입니다.1.8B 모델은 휴대 전화 및 기타 소비자 등급 장치에 특별히 최적화되어 있으며 1GB의 RAM 만 얻을 수 있습니다.
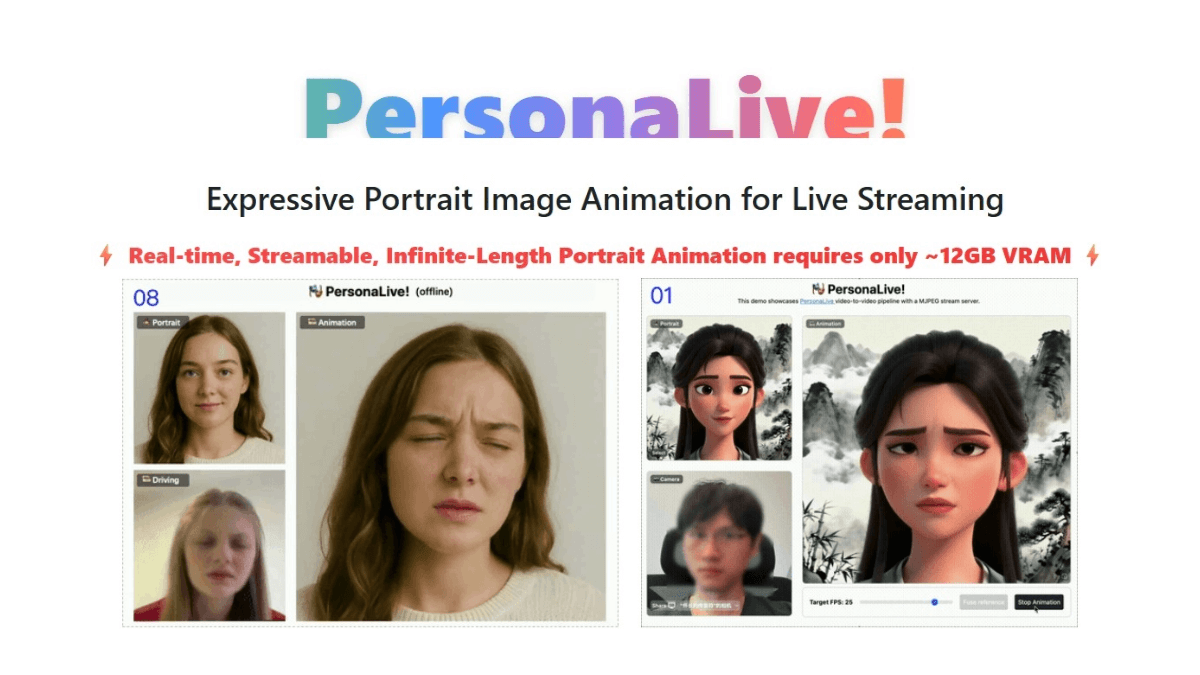
페르소나라이브 - 마카오 대학교 및 기타 오픈 소스 실시간 AI 인물 애니메이션 생성 라이브 프레임워크
페르소나라이브는 마카오 대학교, dzine.ai, 그레이터 베이 지역 대학교의 GVC 랩이 공동 개발한 오픈 소스 실시간 AI 얼굴 교체 라이브 스트리밍 프레임워크입니다. 일반 소비자용 그래픽 카드(12GB 비디오 메모리)에서 지연 시간이 짧고 프레임 속도가 빠른 디지털 퍼스널 드라이브를 구현할 수 있으며 카메라를 통한 실시간 스트리밍을 지원합니다....

컴퓨터 사용 미리보기 - Google의 오픈 소스 AI 브라우저 자동화 도구
컴퓨터 사용 미리보기는 자연어 명령을 통해 웹 페이지 상호 작용을 달성하기 위해 쌍둥이 자리 모델에 기반한 Google의 오픈 소스 AI 브라우저 자동화 도구입니다. 시각적 인식 프로세스의 "스크린 샷 → 분석 → 실행"을 사용하여 Playwrigh ...
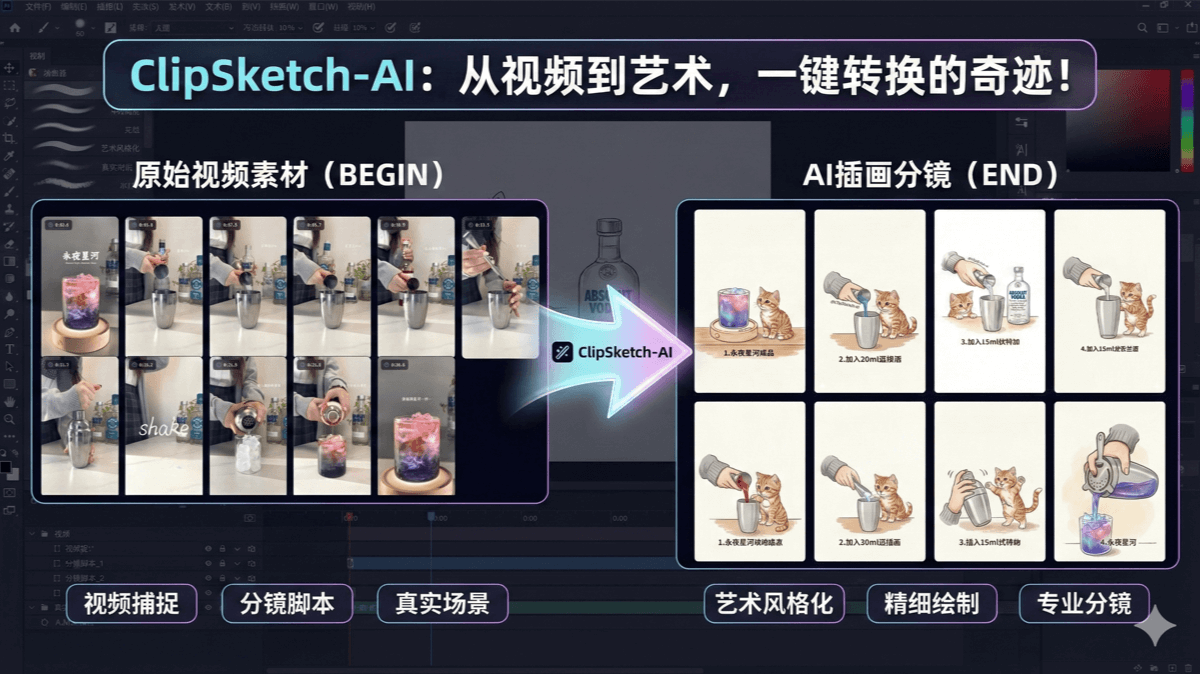
ClipSketch AI - 오픈 소스 AI 비디오를 손으로 그린 분할 화면 도구로 변환, B 스테이션, 작은 빨간 책 지원
ClipSketch AI는 짧은 동영상 제작자를 위해 설계된 오픈 소스 동영상에서 손으로 그린 분할 화면 도구입니다. B 스테이션, 샤오홍슈 및 기타 플랫폼의 동영상을 한 번의 클릭으로 손으로 그린 스타일의 스토리보드로 변환하고, 키 프레임 표시, 서브 장면 자동 생성 및 소셜 카피를 지원하며, 사용자 정의 역할을 통합할 수 있습니다.
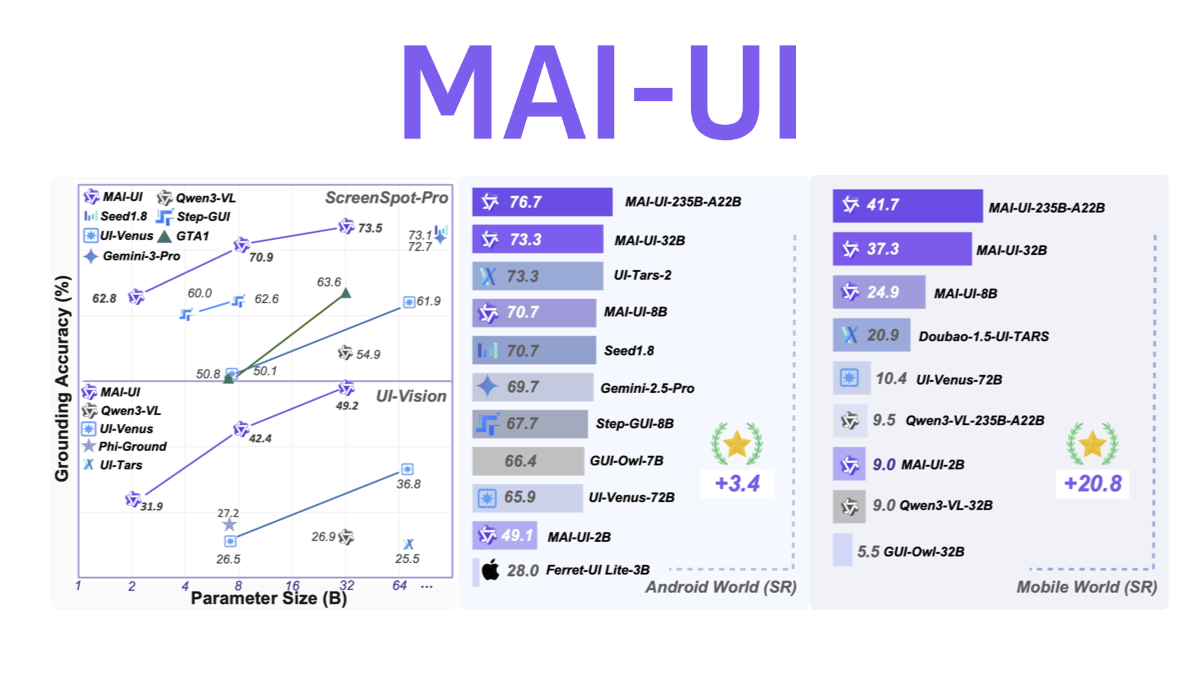
MAI-UI - 알리 통이 연구소의 오픈 소스 범용 GUI 지능형 바디 기본 모델
MAI-UI는 알리바바 통이 연구소의 오픈 소스 범용 GUI 지능형 바디 기반 모델로, 애플리케이션 간 작동, 퍼지 의미 이해, 능동적 사용자 상호 작용 및 다단계 프로세스 조정이라는 네 가지 주요 기능을 갖추고 있습니다. 엔드 클라우드 협업 아키텍처를 채택한 경량 모델은 장치에 상주하여 일상적인 작업을 처리하고 복잡한 작업은 클라우드를 대규모로 호출할 수 있습니다.
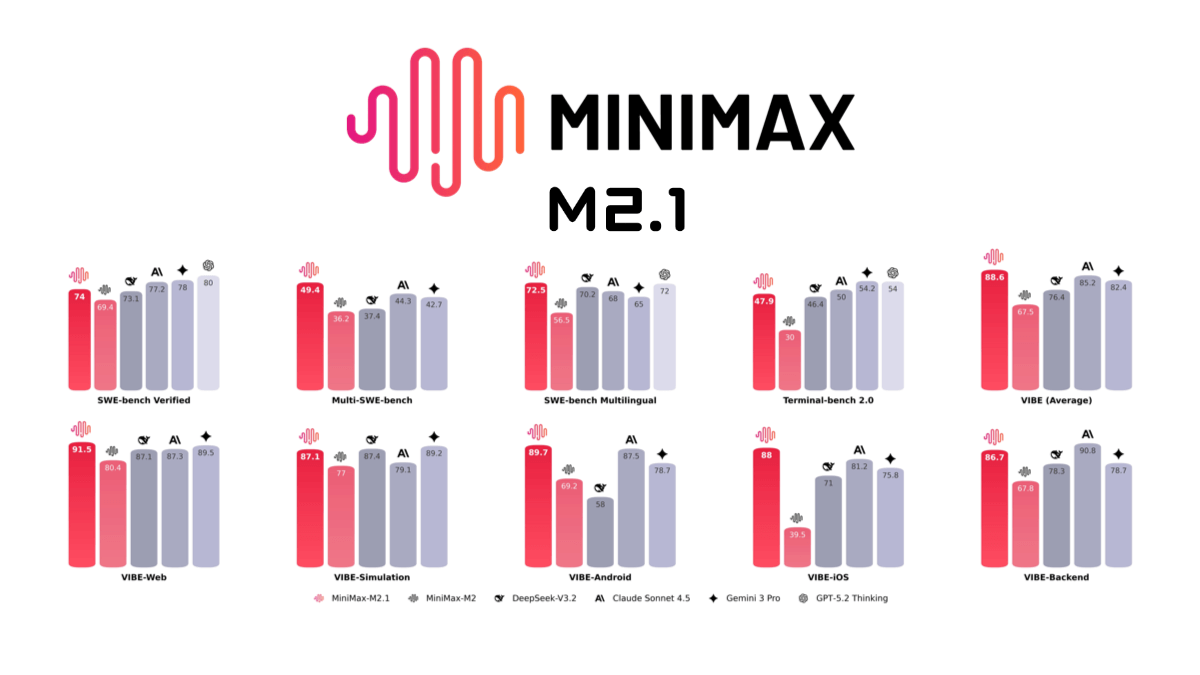
MiniMax M2.1 - MiniMax 오픈 소스 코딩 및 에이전트 모델
MiniMax M2.1은 100억 건의 활성화를 달성한 MiniMax의 오픈 소스 코딩 및 에이전트 모델이며 Rust, Java, Golang, C++, Kotlin, Objective-C, TypeS 등 여러 주요 프로그래밍 언어를 지원합니다....