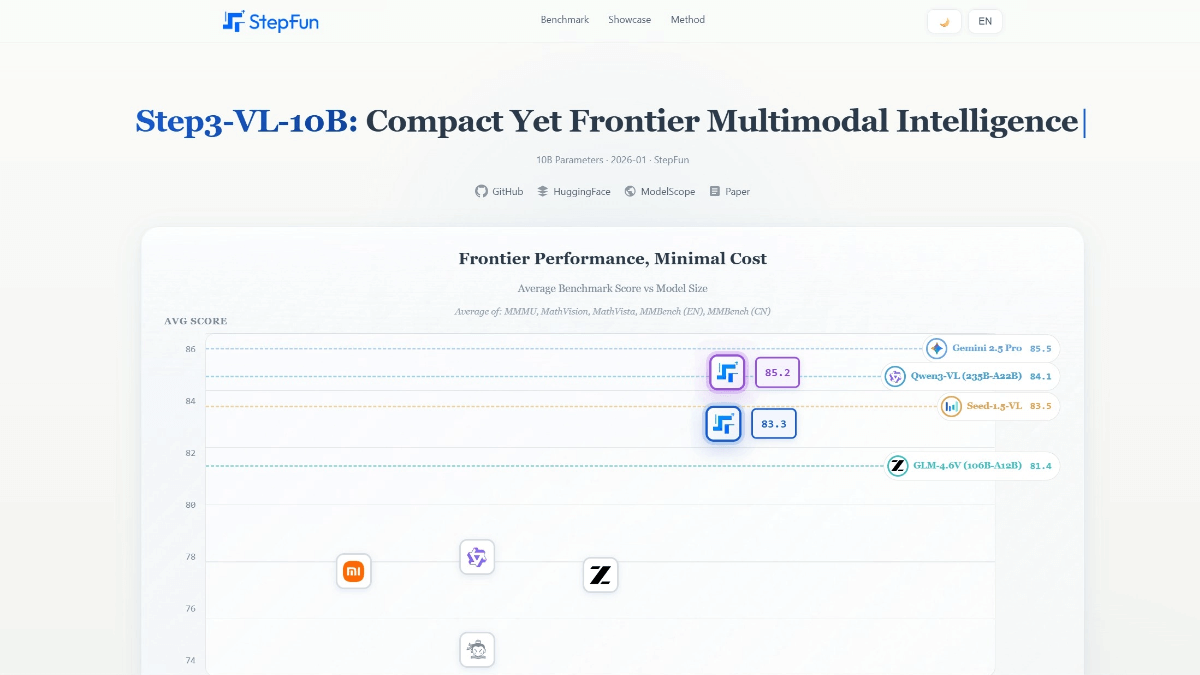

일반 소개
AudioX는 Zeyue Tian 등의 오픈 소스 프로젝트로, 공식 논문은 arXiv(논문번호 2503.10522)에 게재되어 있습니다. 텍스트, 비디오, 이미지, 오디오 등 다양한 입력으로부터 고품질의 오디오와 음악을 생성할 수 있는 확산 트랜스포머 기술을 기반으로 하며, 단일 입력만 지원하는 것이 아니라 멀티 모달 데이터의 처리를 통합하고 자연어 제어를 통해 결과를 생성하는 것이 AudioX만의 특징입니다. 이 프로젝트는 학습 데이터 부족 문제를 해결하는 두 가지 데이터 세트인 vggsound-caps(190,000개의 오디오 설명)와 V2M-caps(6,000,000개의 음악 설명)를 제공하며, AudioX는 개발자, 연구자 및 크리에이터를 위해 코드와 사전 학습된 모델을 오픈소스로 공개합니다.

기능 목록
- 오디오 생성을 위한 다중 입력 지원: 텍스트, 비디오, 사진 또는 오디오를 사용하여 해당 오디오 또는 음악을 생성할 수 있습니다.
- 자연어 제어: "가벼운 피아노 음악" 등의 텍스트 설명으로 오디오 콘텐츠 또는 스타일을 조정합니다.
- 고품질 출력: 생성된 오디오 및 음악 음질은 전문가 수준에 가까운 고품질입니다.
- 통합 멀티모달 처리: 다양한 유형의 입력을 동시에 처리하고 일관된 결과를 생성할 수 있는 기능입니다.
- 오픈 소스 리소스: 전체 코드, 사전 학습된 모델 및 데이터세트를 사용하여 2차 개발을 용이하게 할 수 있습니다.
- 기본 데모 지원: Gradio를 통한 대화형 인터페이스로 기능을 쉽게 테스트할 수 있습니다.
도움말 사용
AudioX는 약간의 프로그래밍 지식이 필요하며 Python 경험이 있는 사용자에게 적합합니다. 다음은 시작하는 데 도움이 되는 자세한 설치 및 사용 안내서입니다.
설치 프로세스
- 코드 다운로드
터미널에 다음 명령을 입력하여 AudioX 리포지토리를 복제합니다:
git clone https://github.com/ZeyueT/AudioX.git
그런 다음 프로젝트 디렉토리로 이동합니다:
cd AudioX
- 환경 만들기
AudioX에는 Python 3.8.20이 필요합니다. Conda를 사용하여 가상 환경을 생성합니다:
conda create -n AudioX python=3.8.20
환경을 활성화합니다:
conda activate AudioX
- 종속성 설치
프로젝트에 필요한 라이브러리를 설치합니다:
pip install git+https://github.com/ZeyueT/AudioX.git
오디오 처리 도구를 다시 설치합니다:
conda install -c conda-forge ffmpeg libsndfile
- 사전 학습된 모델 다운로드
모델 폴더를 만듭니다:
mkdir -p model
모델 및 구성 파일을 다운로드합니다:
wget https://huggingface.co/HKUSTAudio/AudioX/resolve/main/model.ckpt -O model/model.ckpt
wget https://huggingface.co/HKUSTAudio/AudioX/resolve/main/config.json -O model/config.json
- 설치 확인
환경이 정상인지 테스트합니다:
python -c "import audiox; print('AudioX installed successfully')"
오류가 보고되지 않으면 설치에 성공한 것입니다.
주요 기능
AudioX는 텍스트-오디오 변환(T2A), 비디오-음악 변환(V2M) 등 다양한 생성 작업을 지원합니다. 구체적인 작동 방법은 다음과 같습니다.
텍스트에서 오디오 생성
- 다음과 같은 Python 파일을 만듭니다.
text_to_audio.py. - 다음 코드를 입력합니다:
from audiox import AudioXModel
model = AudioXModel.load("model/model.ckpt", "model/config.json")
text = "敲击键盘的声音"
audio = model.generate(text=text)
audio.save("keyboard.wav")
- 스크립트를 실행합니다:
python text_to_audio.py
- 생성된 오디오는 다음과 같이 저장됩니다.
keyboard.wav를 클릭하면 플레이어로 효과를 확인할 수 있습니다.
동영상에서 음악 생성
- 다음과 같은 동영상 파일을 준비합니다.
sample.mp4. - 스크립트 만들기
video_to_music.py입력:
from audiox import AudioXModel
model = AudioXModel.load("model/model.ckpt", "model/config.json")
audio = model.generate(video="sample.mp4", text="为视频生成音乐")
audio.save("video_music.wav")
- 실행 중입니다:
python video_to_music.py
- 생성된 음악은 다음과 같이 저장됩니다.
video_music.wav.
Gradio 로컬 데모 실행
- 터미널에 입력합니다:
python3 run_gradio.py --model-config model/config.json --share
- 명령이 실행되면 로컬 링크가 생성됩니다(예: http://127.0.0.1:7860). 링크를 열면 웹 인터페이스를 통해 AudioX를 테스트할 수 있습니다.
- 인터페이스에 텍스트(예: "피아노와 바이올린을 위한 음악")를 입력하거나 동영상을 업로드하고 생성을 클릭하면 결과를 들을 수 있습니다.
스크립트 추론의 예
보다 복잡한 생성 작업을 위한 자세한 추론 스크립트가 공식적으로 제공됩니다:
- 문서 만들기
generate.py입력:
import torch
from stable_audio_tools import get_pretrained_model, generate_diffusion_cond
device `Truncated`torch.torch.torch.torch.torch.torch.torch.torch.torch_torch.torch.torch_torch.torch.torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model, config = get_pretrained_config("HKUSTAudio/AudioX")
model = model.to(device)
sample_rate = config["sample_rate"]
sample_size = config["sample_size"]
video_path = "sample.mp4"
text_prompt = "为视频生成钢琴音乐"
conditioning = [{"video_prompt": [read_video(video_path, 0, 10, config["video_fps"]).unsqueeze(0)],
"text_prompt": text_prompt,
"seconds_start": 0,
"seconds_total": 10}]
output = generate_diffusion_cond(model, steps=250, cfg_scale=7, conditioning=conditioning, sample_size=sample_size, device=device)
output = output.to(torch.float32).div(torch.max(torch.abs(output))).clamp(-1, 1).mul(32767).to(torch.int16).cpu()
torchaudio.save("output.wav", output, sample_rate)
- 실행 중입니다:
python generate.py
- 생성된 오디오는 다음과 같이 저장됩니다.
output.wav.
구성 예시
다음은 다양한 작업에 대한 입력 구성입니다:
- 텍스트를 오디오로 변환::
text="敲击键盘的声音",video=None - 동영상에서 음악으로::
video="sample.mp4",text="为视频生成音乐" - 혼합 입력::
video="sample.mp4",text="海浪声和笑声"
주의
- GPU는 생성 속도를 크게 향상시키므로 권장됩니다.
- 동영상 형식은 MP4, 오디오 출력은 wav여야 합니다.
- 네트워크가 안정적인지 확인하세요. 모델을 다운로드하는 데 몇 분 정도 걸릴 수 있습니다.
애플리케이션 시나리오
- 음악 작곡
"슬픈 바이올린 곡"과 같은 텍스트 설명을 입력하면 음악 클립을 빠르게 생성할 수 있습니다. - 비디오 사운드트랙
동영상을 업로드하여 어울리는 배경 음악이나 음향 효과를 생성하세요. - 연구 개발(R&D)
오픈 소스 코드와 데이터 세트를 사용하여 오디오 생성 기술을 개선합니다.
QA
- 중국어를 지원하나요?
예, '가벼운 피아노 음악'과 같은 중국어 입력을 지원합니다. - 얼마나 많은 저장 공간이 필요하나요?
코드와 모델은 약 2~3GB이며, 전체 데이터 세트에는 수십 GB가 추가로 필요합니다. - 생성하는 데 시간이 얼마나 걸리나요?
GPU에서는 몇 초에서 몇 분이 걸리고, CPU에서는 몇 분이 걸릴 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...