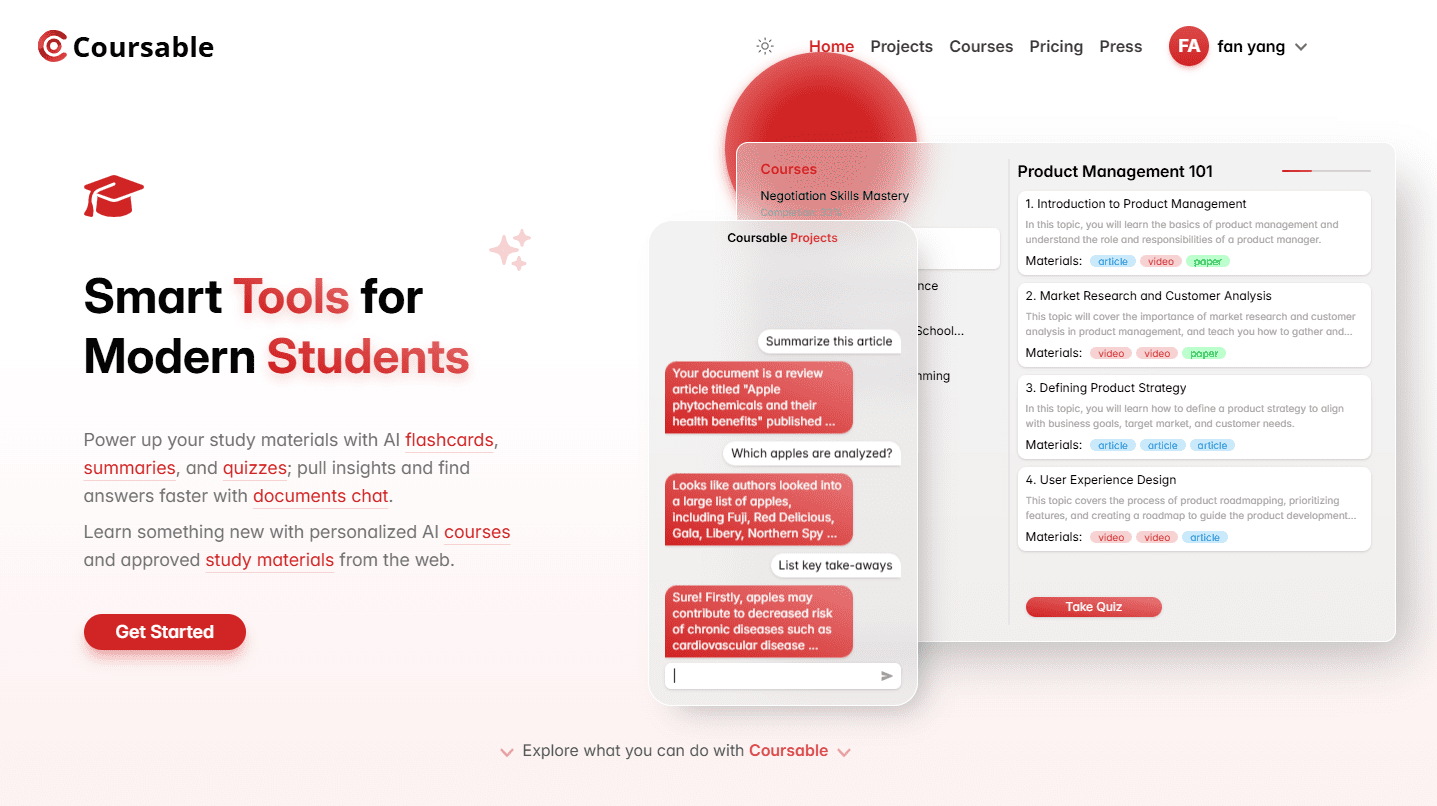

일반 소개
아프로디테 엔진은 피그말리온AI의 공식 백엔드 엔진으로, 피그말리온AI 사이트를 위한 추론 엔드포인트를 제공하고 허깅 페이스 호환 모델의 신속한 배포를 지원하도록 설계되었습니다. 이 엔진은 vLLM의 Paged Attention 기술을 활용하여 효율적인 K/V 관리와 순차적 배치 처리를 가능하게 하여 추론 속도와 메모리 활용도를 크게 향상시킵니다. 아프로디테 엔진은 광범위한 양자화 형식과 분산 추론을 지원하며 다양한 최신 GPU 및 TPU 장치에 적합합니다.
기능 목록
- 연속 배치 처리여러 요청을 효율적으로 처리하고 추론 속도를 개선합니다.
- 호출 주의메모리 사용률 향상을 위해 K/V 관리를 최적화합니다.
- CUDA에 최적화된 커널추론 성능 향상.
- 정량적 지원AQLM, AWQ, 비트샌드바이트 등 여러 양자화 형식을 지원합니다.
- 분산 추론높은 컨텍스트 길이와 높은 처리량 요구 사항을 위한 8비트 KV 캐시 지원.
- 멀티 디바이스 지원NVIDIA, AMD, Intel GPU 및 Google TPU와 호환됩니다.
- 도커 배포: 배포 프로세스를 간소화하기 위해 Docker 이미지를 제공합니다.
- API 호환기존 시스템에 쉽게 통합할 수 있도록 OpenAI 호환 API를 지원합니다.
도움말 사용
설치 프로세스
- 종속성 설치::
- 시스템에 Python 버전 3.8~3.12가 설치되어 있는지 확인하세요.
- Linux 사용자의 경우 다음 명령어를 사용하여 종속 요소를 설치하는 것이 좋습니다:
sudo apt update && sudo apt install python3 python3-pip git wget curl bzip2 tar- Windows 사용자의 경우 WSL2 설치를 권장합니다:
wsl --install sudo apt update && sudo apt install python3 python3-pip git wget curl bzip2 tar - 아프로디테 엔진 설치::
- pip를 사용하여 설치합니다:
pip install -U aphrodite-engine - 프라이밍 모델::
- 다음 명령을 실행하여 모델을 시작합니다:
bash
aphrodite run meta-llama/Meta-Llama-3.1-8B-Instruct - 이렇게 하면 기본 포트가 2242인 OpenAI 호환 API 서버가 생성됩니다.
- 다음 명령을 실행하여 모델을 시작합니다:
Docker로 배포하기
- Docker 이미지 가져오기::
docker pull alpindale/aphrodite-openai:latest
- 도커 컨테이너 실행::
docker run --runtime nvidia --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p 2242:2242 \
--ipc=host \
alpindale/aphrodite-openai:latest \
--model NousResearch/Meta-Llama-3.1-8B-Instruct \
--tensor-parallel-size 8 \
--api-keys "sk-empty"
주요 기능
- 연속 배치 처리::
- 아프로디테 엔진은 연속 일괄 처리 기술을 통해 여러 요청을 동시에 처리할 수 있어 추론 속도가 크게 향상됩니다. 사용자는 시작 시 일괄 처리 매개변수를 지정하기만 하면 됩니다.
- 호출 주의::
- 이 기술은 K/V 관리를 최적화하고 메모리 사용률을 개선합니다. 사용자가 추가로 구성할 필요가 없으며 시스템에서 자동으로 최적화를 적용합니다.
- 정량적 지원::
- AQLM, AWQ, 비트샌드바이트 등 여러 양자화 형식이 지원됩니다. 사용자는 모델을 시작할 때 원하는 양자화 형식을 지정할 수 있습니다:
aphrodite run --quant-format AQLM meta-llama/Meta-Llama-3.1-8B-Instruct - 분산 추론::
- 높은 컨텍스트 길이와 높은 처리량 요구 사항을 위해 8비트 KV 캐시를 지원합니다. 사용자는 다음 명령으로 분산 추론을 시작할 수 있습니다:
aphrodite run --tensor-parallel-size 8 meta-llama/Meta-Llama-3.1-8B-Instruct - API 통합::
- 아프로디테 엔진은 기존 시스템에 쉽게 통합할 수 있도록 OpenAI 호환 API를 제공합니다. 사용자는 다음 명령어로 API 서버를 시작할 수 있습니다:
bash
aphrodite run --api-keys "your-api-key" meta-llama/Meta-Llama-3.1-8B-Instruct
- 아프로디테 엔진은 기존 시스템에 쉽게 통합할 수 있도록 OpenAI 호환 API를 제공합니다. 사용자는 다음 명령어로 API 서버를 시작할 수 있습니다:
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...