
개요
데이터 청킹은 검색 증강 생성(RAG) 시스템의 핵심 단계입니다. 효율적인 색인, 검색 및 처리를 위해 큰 문서를 관리하기 쉬운 작은 조각으로 나눕니다. 이 README는 다음을 제공합니다. RAG 파이프라인에서 사용할 수 있는 다양한 청킹 방법에 대한 개요입니다.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_Data_Ingestion
RAG에서 청크의 중요성
효과적인 청킹은 RAG 시스템에서 매우 중요합니다:
- 일관성 있는 독립적인 정보 단위를 만들어 검색 정확도를 향상하세요.
- 임베딩 생성 및 유사성 검색의 효율성 개선.
- 응답을 생성할 때 보다 정확한 컨텍스트를 선택할 수 있습니다.
- 언어 모델 및 임베디드 시스템 관리 지원 토큰 제한 사항.
청크 방법
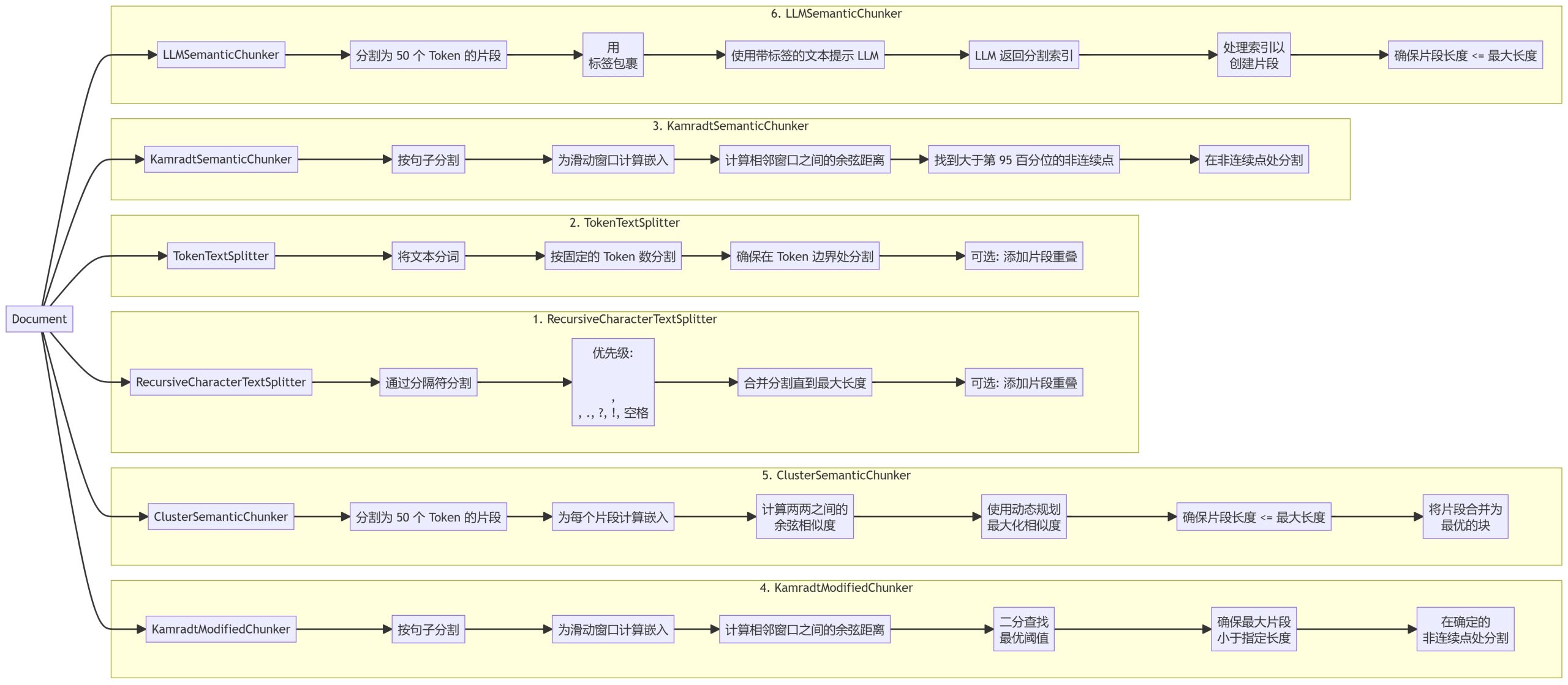
저희는 각각 다른 장점과 사용 시나리오를 가진 6가지 청킹 방법을 구현했습니다:
- 리커시브 문자 텍스트 스플리터
- 토큰 텍스트 스플리터
- 캄라트 시맨틱 청커
- 캄라트수정청커
- 클러스터 시맨틱 청커
- LLM세맨틱청커
청크
1. 리커시브 문자 텍스트 스플리터
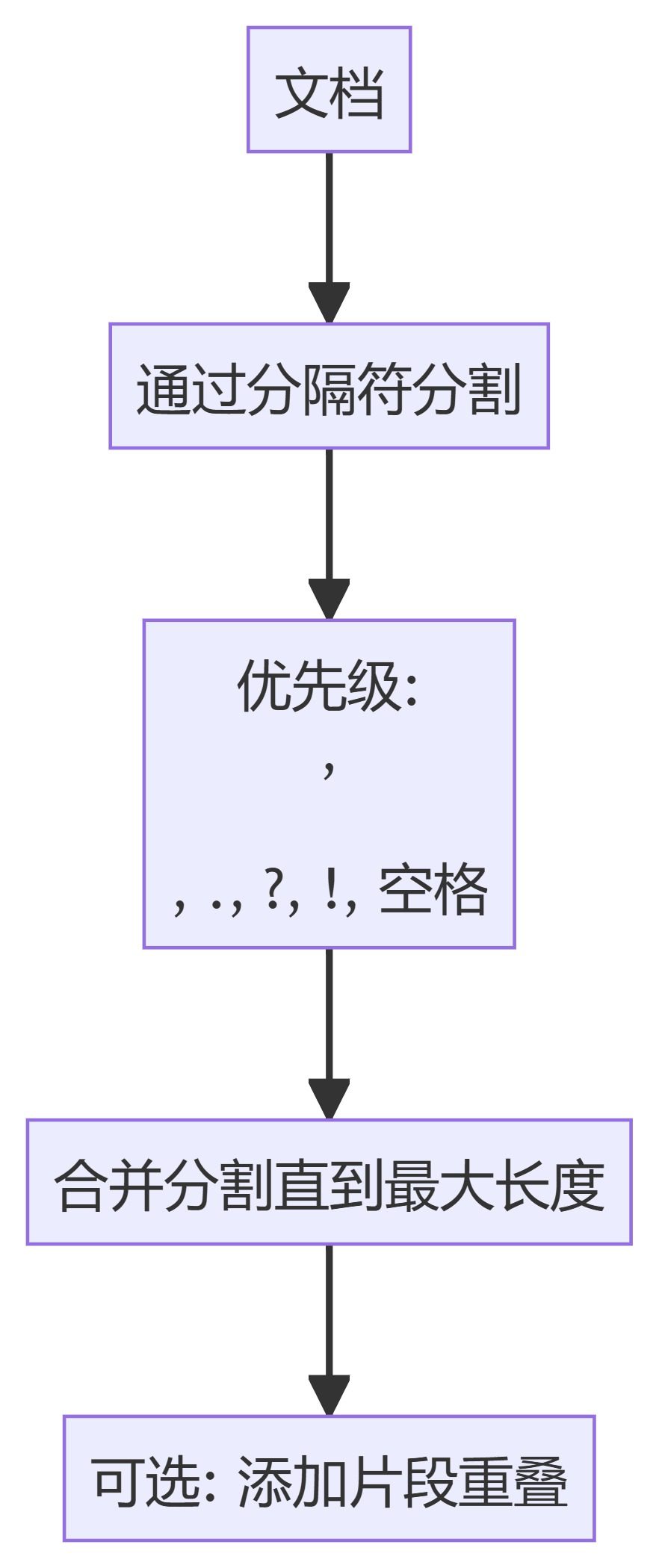
2. 토큰 텍스트 스플리터

3. 캄라트 시맨틱 청커
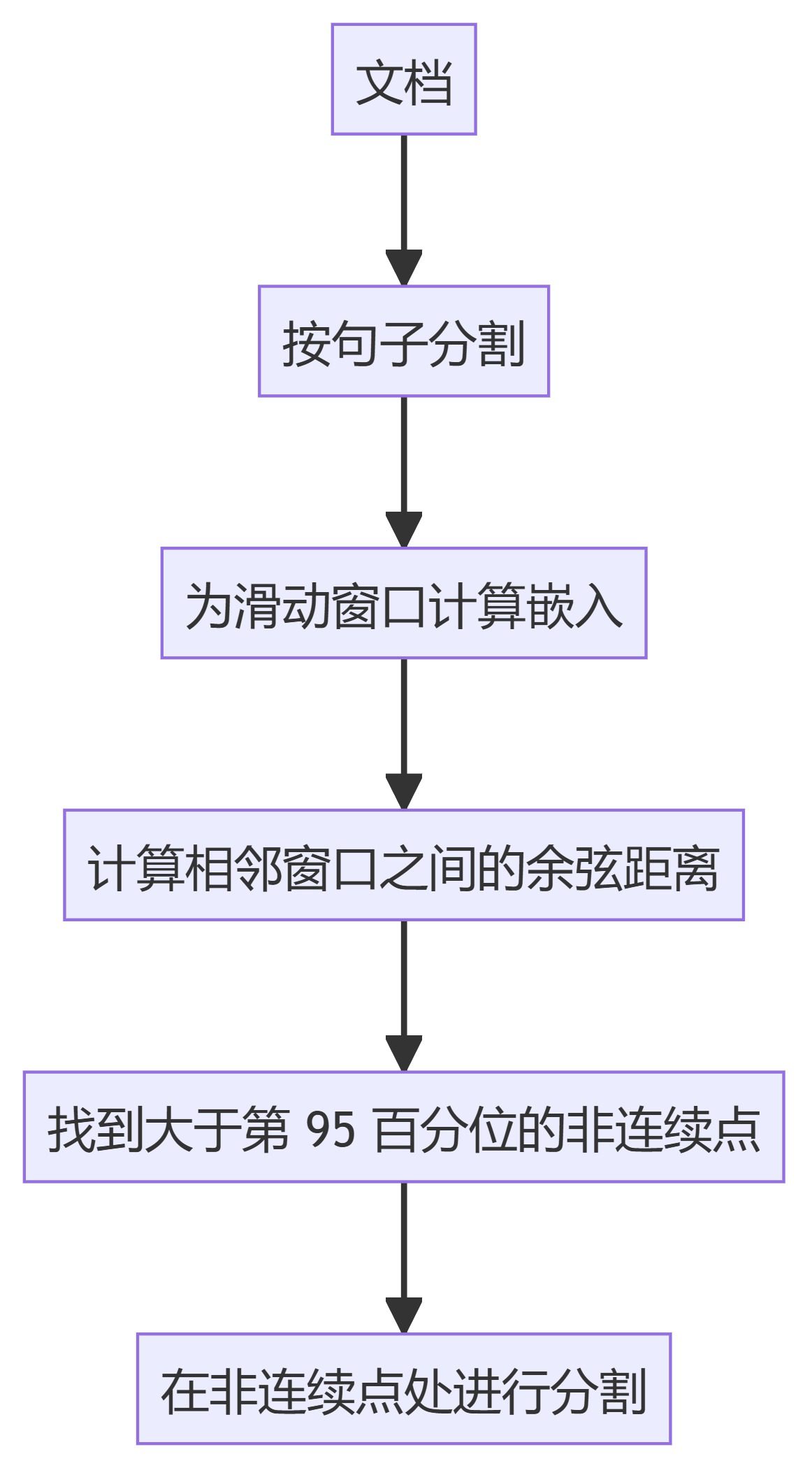
4. 캄라트수정청커
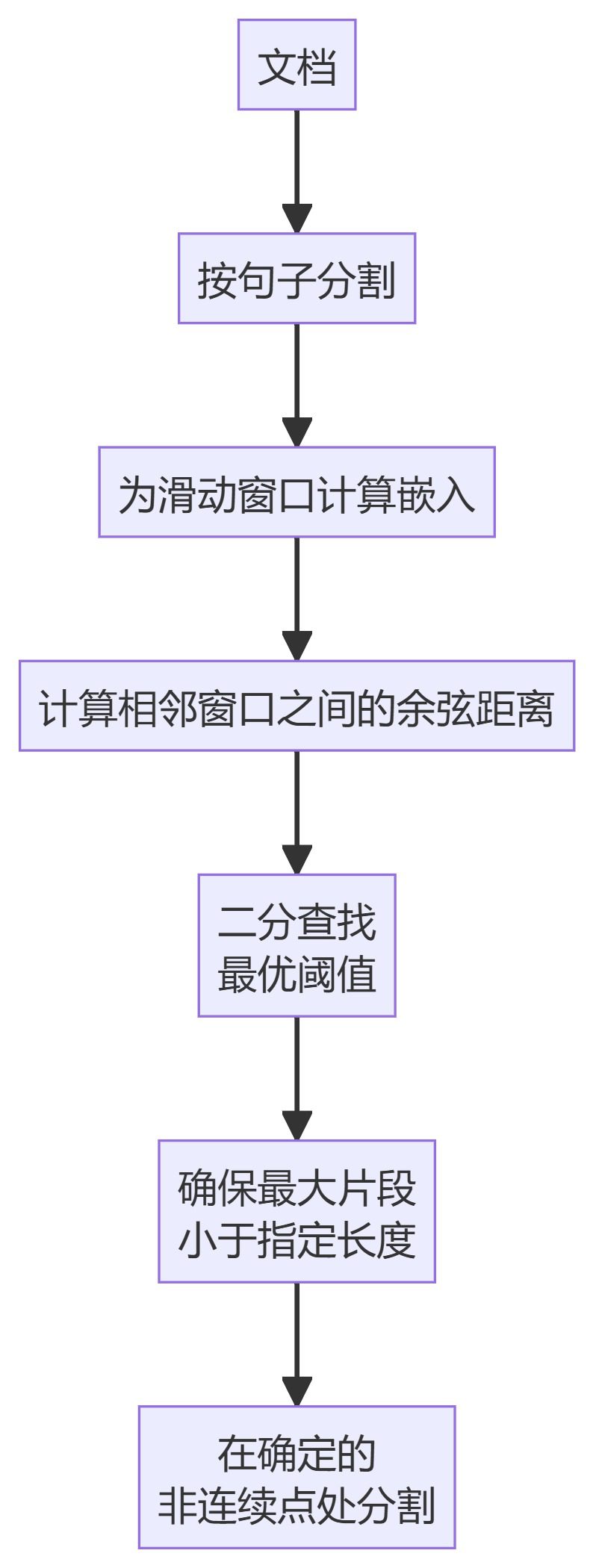
5. 클러스터 시맨틱 청커
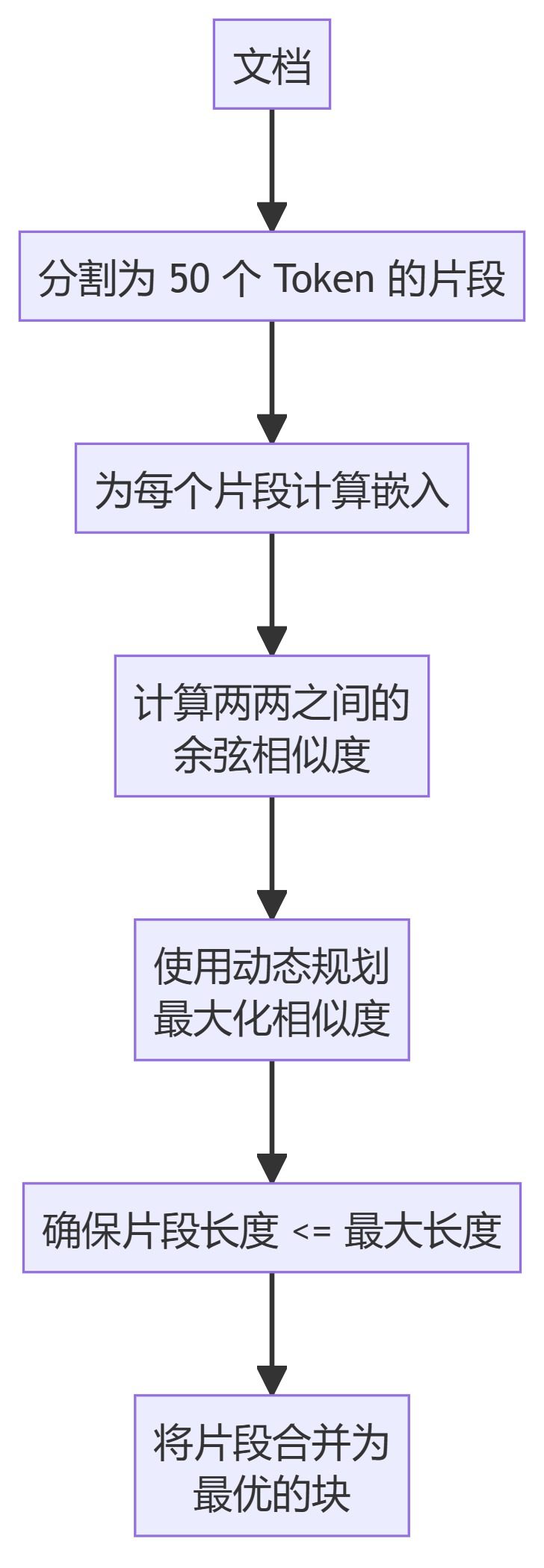
6. LLM세맨틱청커
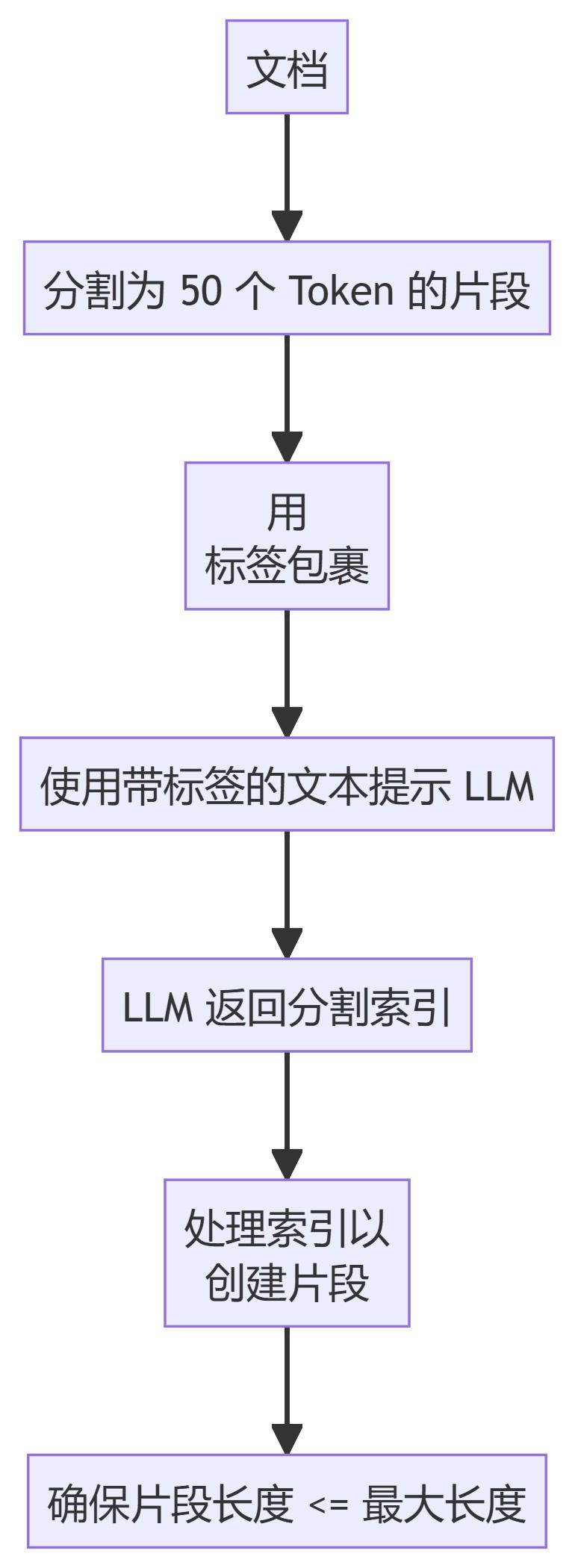
메서드 설명
- 리커시브 문자 텍스트 스플리터: 구분 기호 계층 구조를 기반으로 텍스트를 분할하여 문서에서 자연스러운 중단점을 우선순위로 지정합니다.
- 토큰 텍스트 스플리터: 텍스트를 고정된 수의 토큰 블록으로 분할하여 토큰 경계에서 분할이 이루어지도록 합니다.
- 캄라트 시맨틱 청커슬라이딩 창 임베딩을 사용하여 의미적 불연속성을 식별하고 그에 따라 텍스트를 분할합니다.
- 캄라트수정청커이분할 검색을 사용하여 세분화를 위한 최적의 임계값을 찾는 KamradtSemanticChunker의 개선된 버전입니다.
- 클러스터 시맨틱 청커텍스트를 청크로 분할하고, 임베딩을 계산하고, 동적 프로그래밍을 사용하여 의미적 유사성을 기반으로 최적의 청크를 생성합니다.
- LLM세맨틱청커언어 모델링을 사용하여 텍스트에서 적절한 세분화 지점을 식별합니다.
사용법
RAG 프로세스에서 이러한 청크 방법을 사용하려면 다음과 같이 하세요:
- 통해 (틈새)
chunkers모듈을 사용하여 필요한 청커를 가져올 수 있습니다. - 적절한 매개변수(예: 최대 청크 크기, 겹침)를 사용하여 청커를 초기화합니다.
- 청크 결과를 보려면 문서를 청커에 전달하세요.
예시:
from chunkers import RecursiveCharacterTextSplitter
chunker = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = chunker.split_text(your_document)
청킹 방법 선택 방법
청크 방법 선택은 특정 사용 사례에 따라 다릅니다:
- 간단한 텍스트 분할의 경우, RecursiveCharacterTextSplitter 또는 TokenTextSplitter를 사용할 수 있습니다.
- 시맨틱 인식 세그멘테이션이 필요한 경우 KamradtSemanticChunker 또는 KamradtModifiedChunker를 고려하세요.
- 보다 고급 시맨틱 청킹을 사용하려면 ClusterSemanticChunker 또는 LLMSemanticChunker를 사용하세요.
방법을 선택할 때 고려해야 할 요소:
- 문서 구조 및 콘텐츠 유형
- 필수 청크 크기 및 겹침
- 사용 가능한 컴퓨팅 리소스
- 검색 시스템의 특정 요구 사항(예: 벡터 기반 또는 키워드 기반)
다양한 방법을 시도해보고 문서화 및 검색 요구사항에 가장 적합한 방법을 찾을 수 있습니다.
RAG 시스템과의 통합
청킹을 완료한 후에는 일반적으로 다음 단계가 수행됩니다:
- 각 청크에 대한 임베딩을 생성합니다(벡터 기반 검색 시스템의 경우).
- 선택한 검색 시스템(예: 벡터 데이터베이스, 반전 인덱스)에서 이러한 청크를 색인화합니다.
- 쿼리에 답변할 때는 검색 단계에서 색인 청크를 사용합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...