

선물(직업 등)
검색 강화 세대(RAG)은 대규모 언어 모델의 장점과 지식창고에서 관련 정보를 검색하는 기능을 결합한 강력한 기술입니다. 이 접근 방식은 검색된 특정 정보를 기반으로 생성된 응답의 품질과 정확성을 향상시킵니다.a 이 노트북은 RAG에 대한 명확하고 간결한 소개를 제공하기 위한 것으로, 이 기술을 이해하고 구현하려는 초보자에게 적합합니다.
RAG 프로세스
시작
노트북
이 리포지토리에서 제공하는 노트북을 실행할 수 있습니다. https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_Basic_RAG
채팅 애플리케이션
- 종속성을 설치합니다:
pip install -r requirements.txt - 애플리케이션을 실행합니다:
python app.py - 동적 데이터 가져오기:
python app.py --ingest --data_dir /path/to/documents
서버(컴퓨터)
다음 명령을 사용하여 서버를 실행합니다:
python server.py
서버는 두 개의 엔드포인트를 제공합니다:
/api/ingest/api/query
기관차
기존의 언어 모델은 학습 데이터에서 학습한 패턴을 기반으로 텍스트를 생성합니다. 그러나 구체적이고 업데이트되거나 전문화된 정보가 필요한 쿼리에 직면했을 때 정확한 답변을 제공하는 데 어려움을 겪을 수 있으며, RAG는 언어 모델에 관련 컨텍스트를 제공하여 보다 정확한 답변을 생성하는 검색 단계를 도입함으로써 이러한 한계를 해결합니다.
방법론적 세부 사항
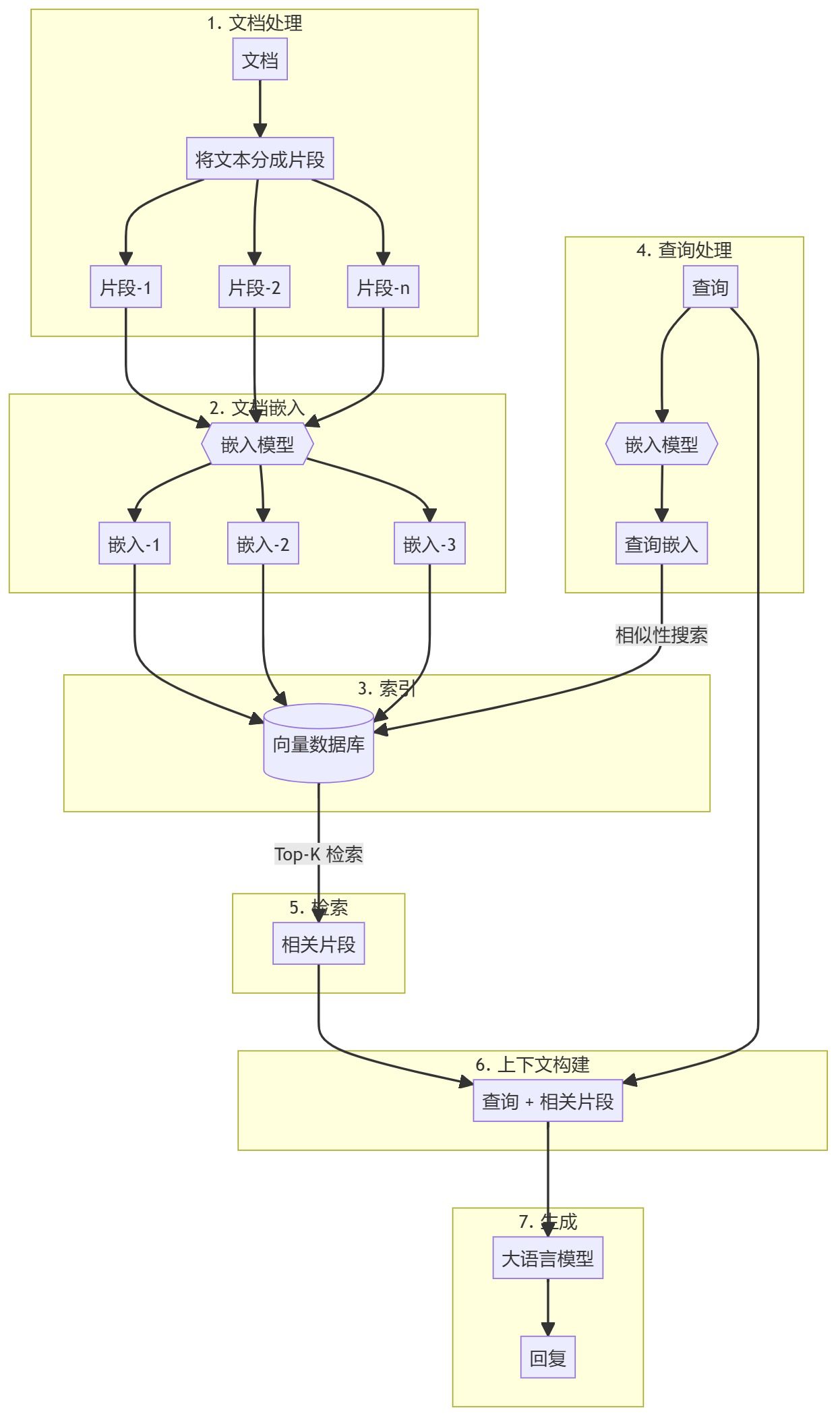
문서 전처리 및 벡터 저장소 생성
- 문서 청크지식창고 문서(예: PDF, 문서)를 관리하기 쉬운 덩어리로 사전 처리하고 분할합니다. 이렇게 하면 효율적인 검색 프로세스를 위한 검색 가능한 코퍼스가 만들어집니다.
- 임베딩 생성각 블록은 사전 학습된 임베딩(예: OpenAI의 임베딩)을 사용하여 벡터 표현으로 변환됩니다. 그런 다음 이러한 문서는 효율적인 유사도 검색을 위해 벡터 데이터베이스(예: Qdrant)에 저장됩니다.
검색 증강 생성(RAG) 워크플로
- 문의 입력:: 사용자가 답변이 필요한 쿼리를 제공합니다.
- 검색 단계문서와 동일한 임베딩 모델을 사용하여 쿼리를 벡터로 임베드합니다. 그런 다음 벡터 데이터베이스에서 유사성 검색을 수행하여 가장 관련성이 높은 문서 블록을 찾습니다.
- 생성 단계:: 검색된 문서 청크는 대규모 언어 모델(예: GPT-4)에 추가 컨텍스트로 전달됩니다. 모델은 이 컨텍스트를 사용하여 보다 정확하고 관련성 높은 응답을 생성합니다.
RAG의 주요 기능
- 문맥 관련성검색된 실제 정보를 기반으로 응답을 생성함으로써 RAG 모델은 보다 맥락에 적합하고 정확한 답변을 생성할 수 있습니다.
- 확장성검색 단계를 확장하여 대규모 지식 기반을 처리할 수 있으므로 모델이 방대한 양의 정보에서 콘텐츠를 추출할 수 있습니다.
- 사용 사례 유연성RAG는 Q&A, 요약 생성, 추천 시스템 등 다양한 애플리케이션 시나리오에 적용할 수 있습니다.
- 정확도 향상:: 검색과 생성을 결합하면 특히 특정 정보나 콜드 정보가 필요한 쿼리의 경우 더 정확한 결과를 얻을 수 있습니다.
이 방법의 장점
- 검색과 생성의 장점 결합RAG는 검색 기반 접근 방식과 생성 모델을 효과적으로 결합하여 정확한 사실 검색과 자연어 생성을 모두 지원합니다.
- 롱테일 쿼리 처리 개선이 방법은 구체적이고 흔하지 않은 정보가 필요한 쿼리에 특히 효과적입니다.
- 도메인 적응검색 메커니즘을 특정 도메인에 맞게 조정하여 가장 관련성이 높고 정확한 도메인별 정보를 기반으로 응답이 생성되도록 할 수 있습니다.
평결에 도달하기
검색 증강 생성(RAG)은 검색과 생성 기술의 혁신적인 융합으로, 관련 외부 정보를 기반으로 출력을 생성하여 언어 모델의 기능을 효과적으로 향상시킵니다. 이 접근 방식은 정확하고 맥락을 인식하는 답변이 필요한 응답 시나리오(예: 고객 지원, 학술 연구 등)에서 특히 유용합니다. AI가 계속 발전함에 따라 RAG는 더욱 안정적이고 상황에 민감한 AI 시스템을 구축할 수 있는 잠재력을 지니고 있습니다.
사전 조건
- 선호되는 Python 3.11
- 주피터 노트북 또는 주피터랩
- LLM API 키
- 모든 LLM을 사용할 수 있습니다. 이 노트북에서는 OpenAI와 GPT-4o-mini를 사용합니다.
이러한 단계를 통해 실제 최신 정보를 통합하는 기본 RAG 시스템을 구현하여 다양한 애플리케이션에서 언어 모델의 효율성을 높일 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...