
ColBERT(BERT 기반의 맥락화된 포스트 문화적 상호작용)는 기존의 고밀도 임베딩 모델과는 다릅니다. 다음은 콜버트의 작동 방식에 대한 간략한 설명입니다:
- 토큰 레이어 임베딩전체 문서나 쿼리에 대해 개별 벡터를 직접 생성하는 것과 달리, ColBERT는 각 문서나 쿼리에 대해 단일 벡터를 생성합니다. 토큰 임베딩 벡터를 생성합니다.
- 상호 작용 후쿼리와 문서 간의 유사성을 계산할 때, 전체 벡터를 직접 비교하는 대신 각 쿼리 토큰을 각 문서 토큰과 비교합니다.
- MaxSim 작동콜버트는 각 쿼리 토큰에 대해 문서의 모든 토큰과 최대 유사성을 찾아 합산하여 유사성 점수를 구합니다.
참고: https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/10_ColBERT_RAG
다음 단계는 콜버트가 어떻게 사용되는지 일러스트레이션과 함께 자세히 보여드리는 것입니다. RAG 는 토큰 레벨 처리와 사후 상호작용 메커니즘을 강조하는 프로세스에서 작동합니다.
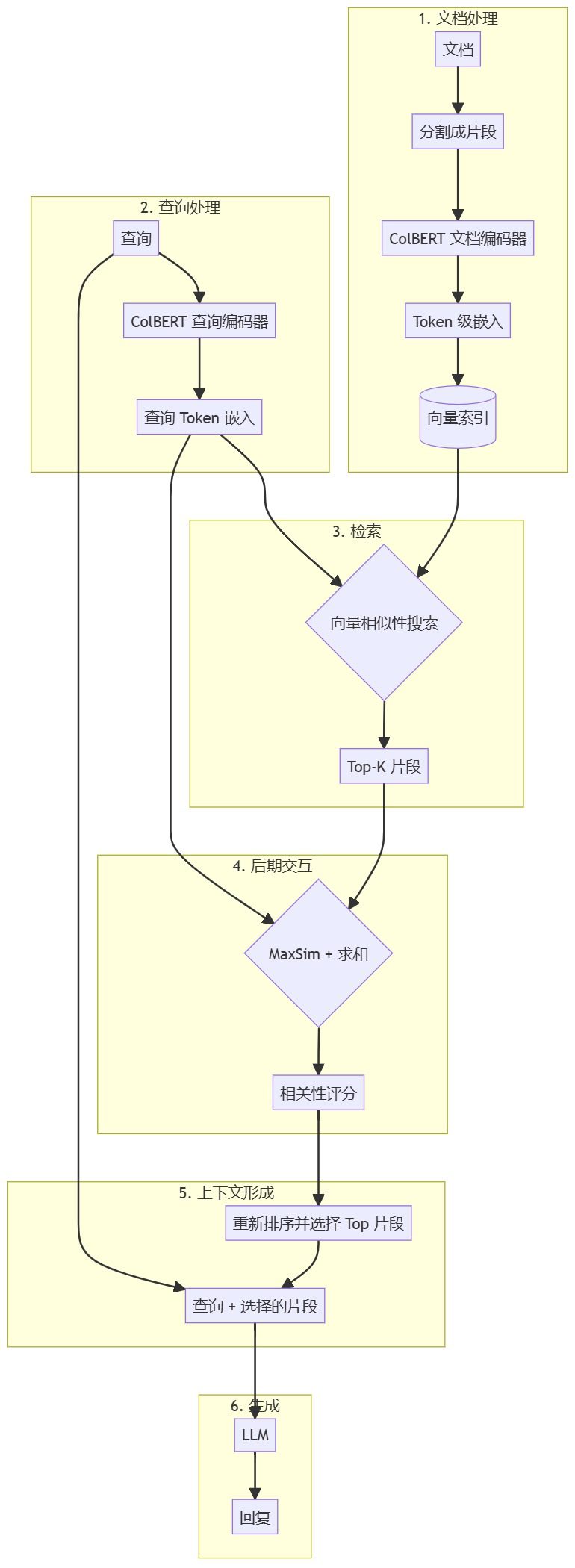
이 다이어그램은 콜버트 기반 RAG 파이프라인의 전체 아키텍처를 보여주며, 콜버트 접근 방식에서 토큰 수준 처리와 사후 상호작용을 강조합니다.
이제 콜버트의 토큰 레벨 임베딩과 포스트 인터랙션 메커니즘을 강조하는 더 자세한 다이어그램을 만들어 보겠습니다:

이 차트는 다음과 같습니다:
- 문서와 쿼리가 BERT 및 선형 계층을 통해 토큰 수준의 임베딩으로 처리되는 방식.
- 사후 상호작용 메커니즘에서 각 쿼리 토큰이 각 문서 토큰과 비교되는 방식.
- MaxSim 연산과 그 후속 합산 단계를 거쳐 최종 상관관계 점수를 생성합니다.
이 다이어그램은 콜버트가 RAG 파이프라인 내에서 어떻게 작동하는지 보다 정확하게 보여주며, 토큰 수준의 접근 방식과 후기 상호 작용 메커니즘을 강조합니다. 이러한 접근 방식을 통해 ColBERT는 쿼리와 문서에서 더 세분화된 정보를 보유할 수 있으므로 기존의 고밀도 임베딩 모델에 비해 더 상세한 일치 항목과 잠재적으로 더 우수한 검색 성능을 제공합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서




댓글 없음...