

개요
자동 병합 검색기는 다음과 같습니다.향상된 검색 생성(RAG) 프레임워크의 높은 수준의 구현 이 접근 방식은 잠재적으로 파편화되고 작은 컨텍스트를 보다 크고 포괄적인 컨텍스트로 통합하여 AI가 생성한 응답의 컨텍스트 인식 및 일관성을 향상시키는 것을 목표로 합니다.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/05_Auto_Merging_RAG
배경 동기 부여
기존의 증강 검색 생성 시스템은 여러 텍스트 세그먼트에 걸쳐 있는 정보를 처리할 때 더 큰 맥락에서 일관성을 유지하는 데 어려움을 겪거나 성능이 저하되는 경우가 많습니다. 자동 병합 검색기는 특정 임계값을 초과하는 상위 노드를 참조하는 하위 노드 집합을 재귀적으로 병합함으로써 이러한 한계를 해결하여 검색 및 생성 프로세스에서 보다 포괄적이고 일관된 컨텍스트를 제공합니다.
방법론적 세부 사항
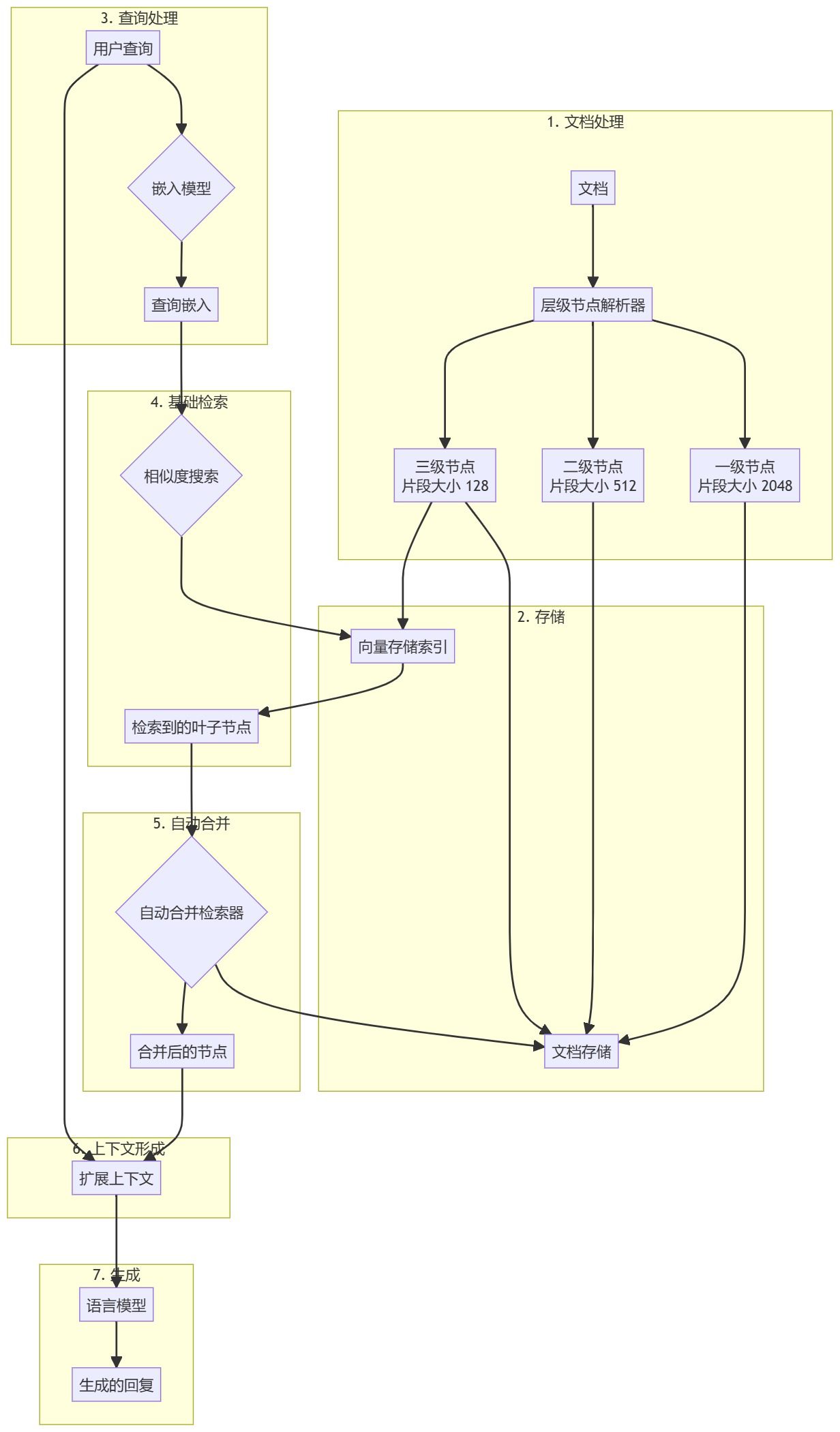
문서 전처리 및 계층 구조 생성
- 문서 로드입력 문서(예: PDF 파일)를 로드하고 처리합니다.
- 계층적 해상도사용
HierarchicalNodeParser문서에서 노드 계층구조를 만듭니다:- 레벨 1: 블록 크기 2048
- 레벨 2: 블록 크기 512
- 레벨 3: 블록 크기 128
- 노드 스토리지모든 노드를 문서 저장소에 저장하고 리프 노드도 벡터 저장소에 색인화합니다.
향상된 검색 생성 워크플로
- 쿼리 전처리문서 블록과 동일한 임베딩 모델을 사용하여 사용자 쿼리를 처리합니다.
- 기본 검색기본 검색기는 초기 유사도 검색을 수행하여 관련 리프 노드를 찾습니다.
- 자동 병합::
AutoMergingRetriever검색된 리프 노드 집합을 분석하고 주어진 임계값을 넘어 상위 노드를 참조하는 리프 노드의 하위 집합을 재귀적으로 '병합'합니다. - 컨텍스트 확장(컴퓨팅)병합된 노드는 확장된 컨텍스트를 형성하고 원래 쿼리와 병합됩니다.
- 응답 생성하기확장 컨텍스트와 쿼리를 LLM(대규모 언어 모델)에 입력하여 응답을 생성합니다.
자동 병합 검색기의 주요 기능
- 계층적 문서 표현문서 블록의 다단계 계층 구조를 유지합니다.
- 효율적인 기본 검색벡터 유사도 검색을 사용하여 빠르고 정확한 예비 정보 검색을 달성합니다.
- 동적 컨텍스트 확장관련 텍스트 블록을 더 크고 일관된 컨텍스트로 자동 병합합니다.
- 유연한 실현다양한 문서 유형 및 언어 모델에 사용할 수 있습니다.
이 방법의 장점
- 컨텍스트 일관성 향상관련 텍스트 덩어리를 병합하여 더 큰 언어 모델에 보다 일관되고 완전한 컨텍스트를 제공합니다.
- 유연한 검색 적응성병합 프로세스는 쿼리 및 검색 결과에 따라 자동으로 조정되어 문맥에 맞는 정보를 제공합니다.
- 효율적인 스토리지 구조계층 구조를 유지하면서 리프 노드의 기본 검색을 빠르게 구현합니다.
- 응답 품질 개선 가능성확장된 컨텍스트는 보다 정확하고 상세한 언어 모델 응답으로 이어질 것으로 기대됩니다.
결과
실험 결과에 따르면 자동 병합 검색기와 기본 검색기를 비교하면 다음과 같습니다:
- 정확성, 관련성, 정확성 및 의미적 유사성 메트릭에서 유사한 성능을 보였습니다.
- 쌍별 비교에서는 52.5% 사용자가 자동 병합 검색기의 응답을 더 선호했습니다.
이러한 결과는 자동 병합 검색기의 성능이 기존 검색 방법과 비슷하거나 약간 더 우수하다는 것을 보여줍니다.
평결에 도달하기
자동 병합 검색기는 고급 방법으로 RAG 검색 프로세스를 개선합니다. 관련 텍스트 블록을 보다 크고 일관된 문맥으로 동적으로 병합함으로써 기존 텍스트 블록 기반 검색 방법의 몇 가지 한계를 해결합니다. 초기 결과는 긍정적인 전망을 보여주고 있지만, 추가 연구와 최적화를 통해 응답 품질과 일관성을 크게 개선할 수 있을 것으로 기대됩니다.
사전 조건
이 시스템을 구현하려면 다음이 필요합니다:
- 텍스트를 생성할 수 있는 대규모 언어 모델(예: GPT-3.5-turbo, GPT-4).
- 텍스트 블록과 쿼리를 벡터 표현으로 변환하기 위한 임베딩 모델입니다.
- 효율적인 유사도 검색을 위한 벡터 데이터베이스(예: FAISS).
- 전체 노드 계층 구조를 저장하기 위한 문서 저장소입니다.
- offer
LlamaIndex라이브러리에는HierarchicalNodeParser노래로 응답AutoMergingRetriever실현. - 대량의 문서 모음을 처리하고 저장하기에 충분한 컴퓨팅 리소스.
- 구현 및 테스트를 위한 Python 프로그래밍 언어에 익숙해야 합니다.
사용 예
from llama_index.core import StorageContext, VectorStoreIndex
from llama_index.core.node_parser import HierarchicalNodeParser
from llama_index.core.retrievers import AutoMergingRetriever
# 将文档解析为节点层级
node_parser = HierarchicalNodeParser.from_defaults()
nodes = node_parser.get_nodes_from_documents(docs)
# 设置存储上下文
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
# 创建基础索引和检索器
leaf_nodes = get_leaf_nodes(nodes)
base_index = VectorStoreIndex(leaf_nodes, storage_context=storage_context)
base_retriever = base_index.as_retriever(similarity_top_k=6)
# 创建自动合并检索器
retriever = AutoMergingRetriever(base_retriever, storage_context, verbose=True)
# 在查询引擎中使用自动合并检索器
query_engine = RetrieverQueryEngine.from_args(retriever)
response = query_engine.query(query_str)© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...