

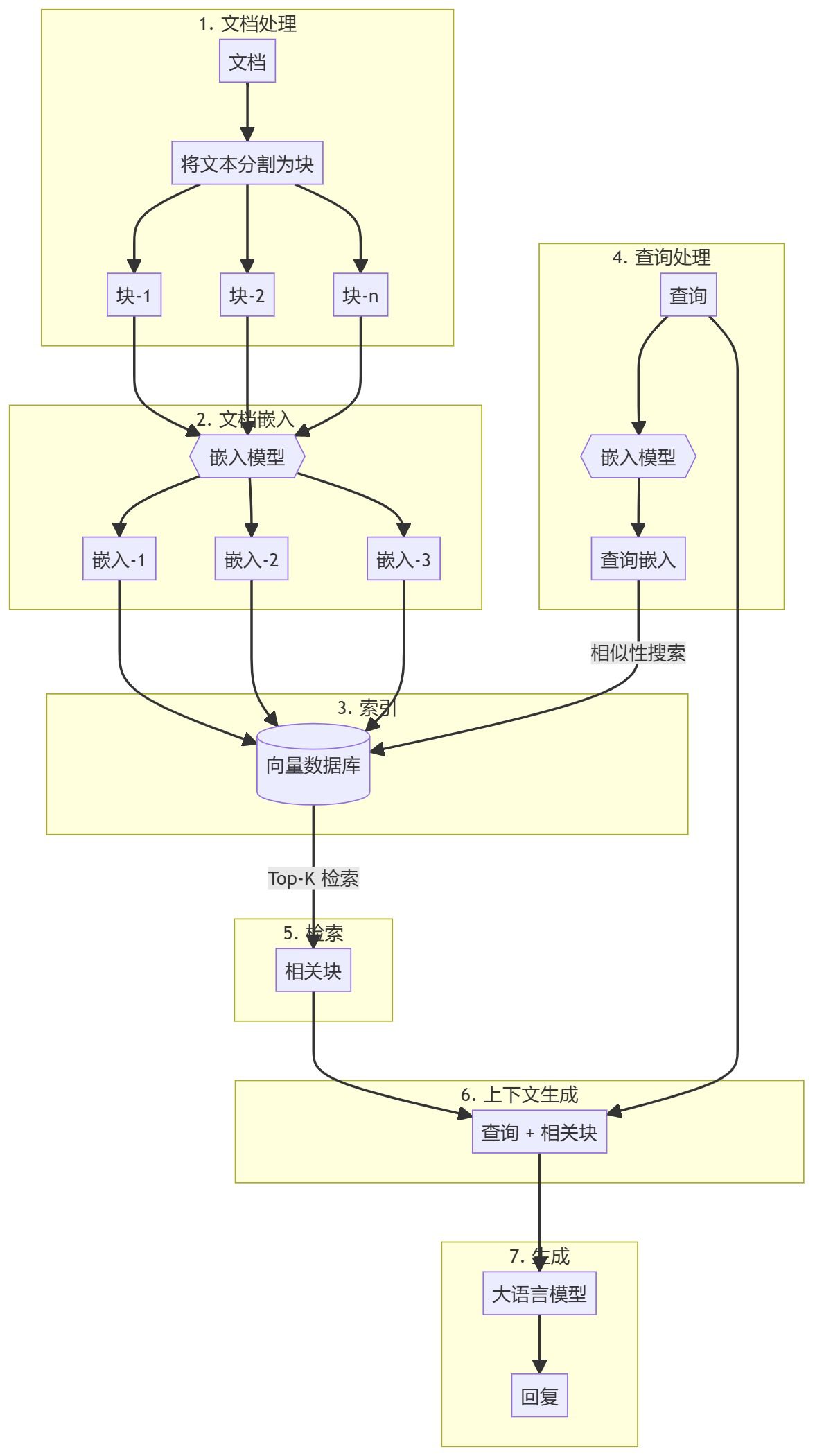
개요
이 가이드에서는 순수 Python을 사용하여 간단한 검색 개선 사항 생성을 만드는 방법을 안내합니다(RAG) 시스템을 사용합니다. 임베딩 모델과 대규모 언어 모델(LLM)을 사용하여 관련 문서를 검색하고 사용자 쿼리에 따라 응답을 생성합니다.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/00_RAG_from_Scratch
관련 단계
전체 프로세스는 두 가지 주요 단계로 나눌 수 있습니다:
- 지식창고 생성
- 생성된 부품
지식창고 생성
먼저 지식창고(문서, PDF, 위키 페이지)를 준비해야 합니다. 이는 언어 모델(LLM)의 기본 데이터입니다. 구체적인 프로세스는 다음과 같습니다:
- 청크: 텍스트를 작은 하위 문서 덩어리로 분할하여 처리를 간소화합니다.
- 임베딩쿼리의 의미적 유사성을 파악하기 위해 각 하위 문서 블록에 대한 숫자 임베딩을 계산합니다.
- 비축: 이러한 임베딩을 빠르게 검색할 수 있는 방식으로 저장합니다. 벡터 저장소/데이터베이스를 사용하는 것이 일반적이지만, 이 튜토리얼에서는 꼭 그럴 필요는 없음을 보여줍니다.
생성된 부품
사용자 쿼리가 입력되면 쿼리에 대한 임베딩이 계산되고 지식창고에서 가장 관련성이 높은 하위 문서 블록이 검색됩니다. 이러한 관련 청크가 사용자 쿼리에 추가되어 컨텍스트를 형성하고 LLM에 공급되어 응답을 생성합니다.
1. 환경 설정
시작하기 전에 설치해야 하는 몇 가지 패키지가 있습니다.
sentence-transformers문서 및 쿼리용 임베딩을 생성하는 데 사용됩니다.numpy를 사용하여 유사도 비교를 수행합니다.scipy를 사용하여 고급 유사도 계산을 수행합니다.wikipedia-api위키피디아 페이지를 지식 베이스로 로드하는 데 사용됩니다.textwrap: 출력 텍스트 서식을 지정하는 데 사용됩니다.
!pip install -q sentence-transformers
!pip install -q wikipedia-api
!pip install -q numpy
!pip install -q scipy
2. 임베딩 모델 로드하기
임베디드 모델을 로드해 보겠습니다. 이 튜토리얼에서는 gte-base-en-v1.5.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("Alibaba-NLP/gte-base-en-v1.5", trust_remote_code=True)
모델 정보
gte-base-en-v1.5 모델은 Alibaba NLP 팀에서 제공하는 오픈 소스 영어 모델입니다. 다양한 자연어 처리 작업을 위한 고품질 임베딩을 생성하기 위해 설계된 GTE(Generic Text Embedding) 제품군의 일부입니다. 이 모델은 영어 텍스트의 의미적 의미를 파악하는 데 최적화되어 있으며 문장 유사성, 의미 검색 및 클러스터링과 같은 작업에 사용할 수 있습니다.trust_remote_code=True 매개변수를 사용하면 모델과 관련된 사용자 지정 코드를 사용하여 모델이 예상대로 작동하도록 할 수 있습니다.
3. Wikipedia에서 텍스트 콘텐츠 가져오기 및 준비하기
- 위키백과 문서는 먼저 지식창고로 로드됩니다. 텍스트는 보통 단락별로 관리하기 쉬운 청크(하위 문서)로 분할됩니다.
from wikipediaapi import Wikipedia wiki = Wikipedia('RAGBot/0.0', 'en') doc = wiki.page('Hayao_Miyazaki').text paragraphs = doc.split('\n\n') # 分块 - 사용 가능한 청킹 전략은 다양하지만, 많은 전략이 적용되지 않을 수도 있습니다. 가장 적합한 전략을 결정하려면 지식창고(KB)를 확인하는 것이 가장 좋습니다. 이 예에서는 단락별로 청크합니다.
- 이러한 블록이 어떻게 생겼는지 확인하려면
textwrap라이브러리를 열고 문단별로 인쇄하세요.import textwrap for i, p in enumerate(paragraphs): wrapped_text = textwrap.fill(p, width=100) print("-----------------------------------------------------------------") print(wrapped_text) print("-----------------------------------------------------------------") - 문서에 이미지와 표가 포함되어 있는 경우 시각적 모델을 사용하여 별도로 추출하여 임베드하는 것이 좋습니다.
4. 문서 퍼가기
- 다음으로, 모델의 모델을 생성하기 위해
encode메서드(예paragraphs)를 임베디드로 코딩했습니다.docs_embed = model.encode(paragraphs, normalize_embeddings=True) - 이러한 임베딩은 텍스트의 조밀한 벡터 표현으로, 의미적 의미를 포착하고 모델이 수학적 형태로 텍스트를 이해하고 처리할 수 있게 해줍니다.
- 여기에서 임베딩을 정상화합니다.
- 정규화란 무엇인가요? 정규화는 임베딩 값을 단위 패러다임(즉, 벡터 길이가 1)이 되도록 조정하는 프로세스입니다.
- 왜 정규화할까요? 정규화된 임베딩은 벡터 사이의 거리가 크기보다는 방향의 차이를 주로 반영하도록 합니다. 이렇게 하면 텍스트 간의 '근접성' 또는 '유사성'을 비교하는 유사성 검색 작업에서 모델의 성능이 향상됩니다.
- 결국
docs_embed는 텍스트 데이터의 벡터 표현 모음으로, 각 벡터는 다음에 해당합니다.paragraphs목록의 단락입니다. - 활용
shape명령을 사용하여 각 임베딩 벡터의 블록 수와 크기를 확인할 수 있습니다(임베딩 벡터의 크기는 임베딩 모델 유형에 따라 다릅니다).docs_embed.shape - 또한 정규화된 값의 집합인 실제 임베딩이 어떻게 보이는지도 확인할 수 있습니다.
docs_embed[0]
5. 쿼리 삽입하기
임베드된 문서와 유사한 방식으로 예제 사용자 쿼리를 임베드합니다.
query = "What was Studio Ghibli's first film?"
query_embed = model.encode(query, normalize_embeddings=True)
다음을 확인할 수 있습니다. query_embed 모양을 사용하여 포함된 쿼리의 차원을 확인합니다.
query_embed.shape
6. 쿼리와 가장 가까운 단락 찾기
가장 관련성이 높은 콘텐츠 덩어리를 검색하는 가장 쉬운 방법 중 하나는 문서 임베딩과 쿼리 임베딩의 도트 곱을 계산하는 것입니다.
a. 도트 곱 계산
도트 곱은 두 벡터(또는 행렬)의 해당 요소를 곱하고 합하는 수학적 연산입니다. 두 벡터 간의 유사성을 측정하는 데 자주 사용됩니다.
(도트 곱은 다음과 같이 계산됩니다. query_embed (벡터의 전치).
import numpy as np
similarities = np.dot(docs_embed, query_embed.T)
b. 도트 제품과 그 모양 이해하기
NumPy 배열의 .shape 속성은 배열의 차원을 나타내는 튜플을 반환합니다.
similarities.shape
이 코드에서 예상되는 모양은 다음과 같습니다:
- 다음과 같은 경우
docs_embed의 모양은 (n_docs, n_dim)입니다:- n_docs는 문서 수입니다.
- n_dim은 각 문서에 포함된 차원입니다.
query_embed.T는 단일 쿼리와 비교하기 때문에 (n_dim, 1) 모양을 갖습니다.- 도트 제품
similarities배열의 모양은 (n_docs,)로, n_docs 요소를 포함하는 1차원 배열(벡터)임을 나타냅니다. 각 요소는 쿼리와 특정 문서 간의 유사성 점수를 나타냅니다. - 모양을 확인하는 이유는 무엇인가요? 모양이 예상과 같은지 확인하면(n_docs,) 도트 곱이 올바르게 수행되었고 각 문서의 유사도 점수가 올바르게 계산되었는지 확인할 수 있습니다.
인쇄할 수 있습니다. similarities 배열을 사용하여 유사도 점수를 확인하며, 각 값은 도트 곱 결과에 해당합니다:
print(similarities)
c. 도트 곱의 해석
두 벡터(임베딩) 사이의 도트 곱은 유사성을 측정합니다. 값이 클수록 쿼리와 문서 간의 유사성이 높다는 것을 의미합니다. 임베딩이 정규화된 경우, 이 값은 벡터 간의 코사인 유사도에 정비례합니다. 정규화되지 않은 경우에도 여전히 유사성을 나타내지만 임베딩의 크기도 반영합니다.
d. 가장 유사한 문서 3개를 식별합니다.
유사도 점수를 기준으로 가장 유사한 문서 3개를 찾으려면 다음 코드를 사용하면 됩니다:
top_3_idx = np.argsort(similarities, axis=0)[-3:][::-1].tolist()
- np.argsort(유사성, 축=0). 이 함수는
similarities배열의 인덱스가 정렬됩니다. 예를 들어, 다음과 같은 경우similarities = [0.1, 0.7, 0.4](수학.) 속np.argsort가 반환됩니다.[0, 2, 1]최소값과 최대값의 인덱스는 각각 0과 1입니다. - [-3:]: 이 슬라이싱 작업은 유사도 점수가 가장 높은 3개의 인덱스(정렬 후 마지막 3개의 요소)를 선택합니다.
- [::-1]: 이 작업은 순서를 반대로 하여 인덱스가 유사도 내림차순으로 정렬됩니다.
- tolist(). 인덱싱된 배열을 파이썬 목록으로 변환합니다. 결과:
top_3_idx가장 유사한 문서 3개가 포함된 인덱스(유사도 내림차순)입니다.
e. 가장 유사한 문서 추출
most_similar_documents = [paragraphs[idx] for idx in top_3_idx]
- 파생상품을 나열합니다: 이 줄은 다음과 같은 이름의 파일을 만듭니다.
most_similar_documents목록은 다음과 같습니다.paragraphs에 해당하는 목록은top_3_idx인덱스의 실제 단락입니다. - paragraphs[idx]. 와 관련하여
top_3_idx이 작업은 인덱스의 각 인덱스에 해당하는 단락을 검색합니다.
f. 가장 유사한 문서 서식 지정 및 표시
CONTEXT 변수는 처음에 빈 문자열로 초기화된 다음 열거 루프에서 가장 유사한 문서의 개행 텍스트가 추가됩니다.
CONTEXT = ""
for i, p in enumerate(most_similar_documents):
wrapped_text = textwrap.fill(p, width=100)
print("-----------------------------------------------------------------")
print(wrapped_text)
print("-----------------------------------------------------------------")
CONTEXT += wrapped_text + "\n\n"
7. 응답 생성하기
이제 쿼리와 관련 콘텐츠 블록이 대규모 언어 모델(LLM)에 함께 전달됩니다.
a. 검색 신고
query = "What was Studio Ghibli's first film?"
b. 프롬프트 만들기
prompt = f"""
use the following CONTEXT to answer the QUESTION at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
CONTEXT: {CONTEXT}
QUESTION: {query}
"""
c. OpenAI 설정
- 대규모 언어 모델(LLM)에 액세스하고 사용하려면 OpenAI를 설치하세요.
!pip install -q openai - OpenAI API 키에 대한 액세스를 사용 설정합니다(Google Colab에서 비밀로 설정 가능).
from google.colab import userdata userdata.get('openai') import openai - OpenAI 클라이언트를 만듭니다.
from openai import OpenAI client = OpenAI(api_key=userdata.get('openai'))
d. API를 호출하여 응답을 생성합니다.
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": prompt},
]
)
- client.chat.completions.create. 이 메서드는 대규모 채팅 기반 언어 모델을 호출하여 새 답장을 작성(생성)합니다.
- 클라이언트. 서비스에 연결하는 API 클라이언트 객체(이 경우 OpenAI)를 나타냅니다.
- chat.completions.create. 채팅 기반 세대 생성을 요청한다고 지정합니다.
메서드에 전달되는 매개변수에 대한 자세한 내용은
- 모델="GPT-4O". 응답을 생성하는 데 사용되는 모델을 지정합니다." gpt-4o"는 GPT-4 모델의 특정 변형입니다. 모델마다 동작, 미세 조정 방법 또는 기능이 다를 수 있으므로 원하는 출력을 얻으려면 모델을 지정하는 것이 중요합니다.
- 메시지. 이 매개변수는 대화 기록을 나타내는 메시지 객체 목록입니다. 이를 통해 모델은 채팅의 맥락을 이해할 수 있습니다. 이 예에서는 목록에 하나의 메시지만 제공합니다:
{"role": "user", "content": prompt}. - 역할. '사용자'는 메시지 발신자의 역할, 즉 모델과 상호 작용하는 사용자를 나타냅니다.
- 콘텐츠. 사용자가 보낸 메시지의 실제 텍스트를 포함합니다. 변수 프롬프트에는 이 텍스트가 저장되며, 모델이 응답을 생성할 때 입력으로 사용합니다.
e. 수신된 회신과 관련하여
OpenAI GPT 모델과 같은 API에 요청하여 채팅 응답을 생성하면 일반적으로 응답은 구조화된 형식(일반적으로 사전)으로 반환됩니다.
이 구조에는 일반적으로 다음이 포함됩니다:
- 선택. 모델에서 생성된 여러 개의 가능한 응답을 포함하는 목록(배열)입니다. 이 목록의 각 항목은 가능한 응답 또는 완료를 나타냅니다.
- 메시지. 모델에 의해 생성된 메시지의 실제 내용을 포함하는 각 선택 항목의 개체 또는 사전입니다.
- 콘텐츠. 메시지의 텍스트 콘텐츠, 즉 모델에 의해 생성된 실제 답장 또는 완료 내용입니다.
f. 인쇄된 응답
print(response.choices[0].message.content)
당사는 다음을 선택합니다. choices 목록의 첫 번째 항목에 액세스한 다음 message 객체에 액세스합니다. 마지막으로 message 정곡을 찌르세요 content 필드에는 모델에 의해 생성된 실제 텍스트가 포함됩니다.
평결에 도달하기
이것으로 RAG 시스템을 처음부터 구축하는 방법에 대한 설명이 끝났습니다. 이러한 시스템의 작동 방식을 더 잘 이해하려면 먼저 순수 Python으로 초기 RAG 설정을 구축하는 것이 좋습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...