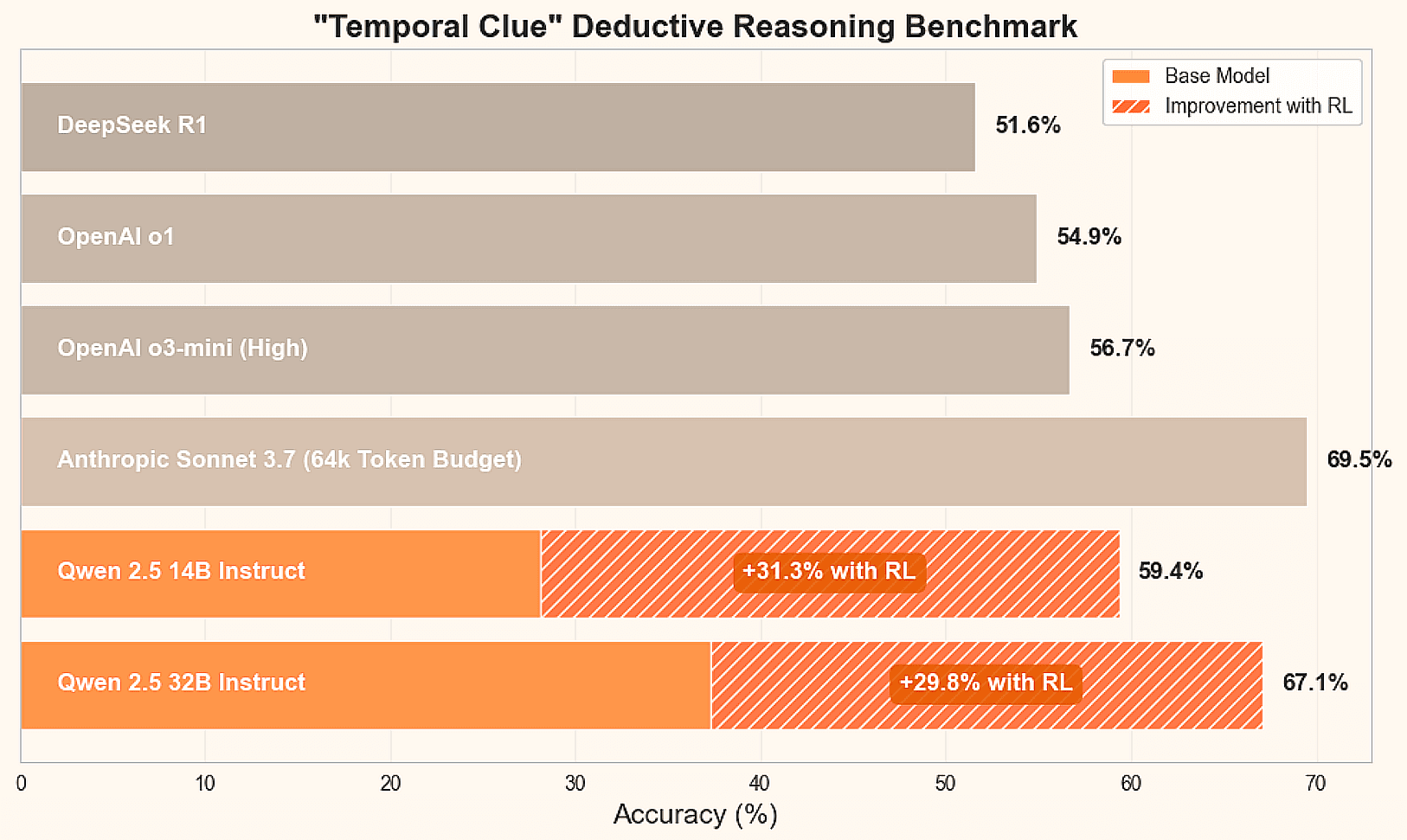

소개
LLM(대규모 언어 모델)의 애플리케이션 영역, 특히 검색 강화 생성 영역(RAG) 시스템에서 텍스트 청킹은 중요한 역할을 합니다. 텍스트 청킹의 품질은 문맥 정보의 유효성과 직결되며, 이는 다시 LLM이 생성하는 답변의 정확성과 완전성에 영향을 미칩니다. 고정 크기 문자 청킹이나 재귀적 텍스트 분할과 같은 기존의 텍스트 청킹 방식은 문장이나 의미 단위 중간에 끊어져 문맥 손실과 의미적 일관성을 잃는 등 내재적 한계를 노출합니다. 이 백서에서는 보다 지능적인 청킹 전략인 에이전틱 청킹에 대해 살펴봅니다. 이 접근 방식은 인간의 판단 과정을 모방하여 의미적으로 일관된 텍스트 청크를 생성함으로써 RAG 시스템의 성능을 크게 개선하는 것을 목표로 합니다. 또한 독자들이 쉽게 시작할 수 있도록 자세한 코드 예제가 제공됩니다.
참고 읽기:간단하고 효과적인 RAG 검색 전략: 희소 + 고밀도 하이브리드 검색 및 재배치, '큐 캐싱'을 사용해 텍스트 청크에 대한 전체 문서 관련 컨텍스트를 생성합니다.
에이전트 청킹이란 무엇인가요?
에이전트 청킹 은 텍스트 분할 과정에서 인간의 이해와 판단을 모방하여 의미적으로 일관된 텍스트 덩어리를 생성하는 것을 목표로 하는 최첨단 LLM 기반 청킹 방법입니다. 핵심 아이디어는 문자, 조직 등과 같은 텍스트의 '에이전트' 요소에 집중하고 이러한 에이전트 요소와 관련된 문장을 취합하여 의미 있는 의미 단위를 형성하는 것입니다.
핵심 아이디어: 에이전트 청킹의 핵심은 단순히 문자 수나 미리 정의된 구분 기호에 의존해 텍스트를 분할하지 않는다는 점입니다. 대신, LLM의 의미 이해 기능을 활용하여 의미적으로 밀접하게 연관된 문장을 청크로 결합하며, 이러한 문장이 원본 텍스트에서 연속된 위치에 있지 않더라도 마찬가지입니다. 이 접근 방식은 텍스트의 내재적 구조와 의미적 연관성을 보다 정확하게 포착합니다.
에이전트 청킹이 필요한 이유는 무엇인가요?
기존의 텍스트 청크 방식에는 무시하기 어려운 몇 가지 한계가 있습니다:
- 고정 크기 문자 청크(고정 크기 캐릭터 청크):
- 이 방식은 텍스트를 미리 정의된 고정 길이의 블록으로 기계적으로 분할합니다. 이렇게 하면 문장 중간이나 단어 내에서 문자 사이가 잘려서 텍스트의 의미적 무결성이 심각하게 손상될 수 있습니다.
- 제목, 목록 등과 같은 문서의 본질적인 구조를 완전히 무시하여 문서의 논리적 구조와 단절된 청크 결과를 초래합니다.
- 또한 임의로 세분화하면 같은 텍스트 블록에 서로 관련이 없는 주제가 섞여 문맥의 일관성을 더욱 떨어뜨릴 수 있습니다.
- 재귀적 텍스트 분할:
- 재귀적 텍스트 세분화는 문단, 문장, 단어 등과 같이 미리 정의된 계층적 구분 기호에 따라 세분화합니다.
- 이 방식은 다단계 제목, 표 등과 같은 복잡한 문서 구조를 효과적으로 처리하지 못해 구조적 정보가 손실될 수 있습니다.
- 문단이나 글머리 기호 목록과 같은 의미 단위의 중간에 잘림이 발생하여 의미 무결성에 영향을 줄 수 있습니다.
- 결정적으로, 재귀적 텍스트 세분화는 텍스트의 의미론에 대한 심층적인 이해가 부족하고 세분화를 위해 표면 구조에만 의존합니다.
- 시맨틱 청크:
- 시맨틱 청킹은 임베딩 벡터의 유사성을 기반으로 문장을 그룹화하여 의미적으로 연관성 있는 청크를 생성하는 것을 목표로 합니다.
- 그러나 한 문단 내의 문장이 의미가 크게 다를 경우 의미 청크가 이러한 문장을 다른 청크로 잘못 분류하여 문단 내의 일관성이 손상될 수 있습니다.
- 또한 시맨틱 청킹은 일반적으로 많은 수의 유사성 계산을 필요로 하며, 특히 대용량 문서를 처리할 때 계산 비용이 크게 증가합니다.
에이전트 청킹은 위에서 언급한 기존 방법의 한계를 다음과 같은 장점을 통해 효과적으로 극복합니다:
- 의미적 일관성: 에이전트 청킹은 의미적으로 더 의미 있는 텍스트 청크를 생성하여 관련 정보 검색의 정확도를 크게 향상시킬 수 있습니다.
- 문맥 보존: 텍스트 블록 내에서 문맥의 일관성을 더 잘 보존하여 LLM이 보다 정확하고 맥락에 맞는 응답을 생성할 수 있도록 합니다.
- 유연성: 에이전트 청킹 방식은 다양한 길이, 구조 및 콘텐츠 유형의 문서에 적용할 수 있는 높은 수준의 유연성을 보여 주며, 광범위한 애플리케이션에 적용할 수 있습니다.
- 견고성: 에이전트 청킹은 완벽한 보호 메커니즘과 폴백 메커니즘을 갖추고 있어 비정상적으로 복잡한 문서 구조나 LLM 성능 제약이 있는 경우에도 청킹의 효과와 안정성을 보장할 수 있습니다.
에이전트 청킹의 작동 방식
에이전트 청킹의 워크플로우는 다음과 같은 주요 단계로 구성됩니다:
- 미니 청크 생성:
- 첫째, 에이전트 청킹은 재귀적 텍스트 분할 기술을 사용하여 입력 문서를 처음에 더 작은 마이크로 청크로 분할합니다. 예를 들어 각 마이크로 청크의 크기는 약 300자로 제한할 수 있습니다.
- 세분화 과정에서 에이전트 청킹은 기본적인 의미 무결성을 유지하기 위해 미니어처 청크가 문장 중간에 잘리지 않도록 특별한 주의를 기울입니다.
- 미니 청크 표시하기:
- 다음으로 각 마이크로블록에 고유한 마커가 추가됩니다. 이 마킹은 LLM이 후속 처리 과정에서 각 마이크로블록의 경계를 식별하는 데 도움이 됩니다.
- LLM은 텍스트를 더 많이 처리한다는 점에 유의하는 것이 중요합니다. 토큰 보다 정확한 문자 수보다는 텍스트의 구조적, 의미론적 패턴을 인식하는 데 능숙합니다. 마이크로 블록을 표시하면 문자를 정확히 계산할 수 없더라도 LLM이 블록 경계를 인식하는 데 도움이 됩니다.
- LLM 지원 청크 그룹화:
- 태그가 지정된 문서를 구체적인 지침과 함께 LLM에 제공합니다.
- 이 시점에서 LLM의 임무는 미니어처 청크의 순서를 심층적으로 분석하고 의미적 연관성을 기반으로 의미적으로 일관된 더 큰 텍스트 청크로 결합하는 것입니다.
- 그룹화 과정에서 각 블록에 포함되는 최대 마이크로블록 수와 같은 제약 조건을 설정하여 실제 요구 사항에 따라 블록의 크기를 제어할 수 있습니다.
- 청크 어셈블리:
- LLM에서 선택한 마이크로 블록을 결합하여 에이전트 청킹의 최종 결과물인 텍스트 블록을 구성합니다.
- 이러한 텍스트 블록을 더 잘 관리하고 활용하기 위해 원본 문서의 소스 정보, 문서 내 텍스트 블록의 색인 위치 등과 같은 관련 메타데이터를 각 블록에 추가할 수 있습니다.
- 컨텍스트 보존을 위한 청크 오버랩:
블록 간 문맥의 일관성을 보장하기 위해 최종적으로 생성된 블록은 일반적으로 앞뒤의 마이크로블록과 어느 정도 겹칩니다. 이러한 중첩 메커니즘은 LLM이 인접한 텍스트 블록을 처리할 때 문맥 정보를 더 잘 이해하고 정보 조각화를 방지하는 데 도움이 됩니다. - 가드레일 및 폴백 메커니즘:
- 블록 크기 제한: 최대 블록 크기를 강제로 설정하여 생성된 텍스트 블록이 항상 LLM의 입력 길이 제한 내에 있도록 함으로써 지나치게 긴 입력으로 인한 문제를 방지합니다.
- 컨텍스트 창 관리: 길이가 LLM 컨텍스트 창 제한을 초과하는 매우 긴 문서의 경우, 에이전트 청킹은 지능적으로 관리 가능한 여러 부분으로 분할하고 일괄 처리하여 처리 효율성과 효과를 보장할 수 있습니다.
- 유효성 검사: 청킹이 완료된 후 에이전트 청킹은 모든 마이크로청크가 최종 텍스트 블록에 올바르게 포함되었는지 확인하기 위한 유효성 검사 프로세스도 수행하여 정보가 누락되지 않도록 합니다.
- 재귀적 청킹으로의 폴백: 어떤 이유로든 LLM 처리가 실패하거나 사용할 수 없는 경우 에이전트 청킹은 기존의 재귀적 텍스트 청킹 방법으로 우아하게 폴백하여 모든 경우에 기본 청킹 기능이 제공되도록 할 수 있습니다.
- 병렬 처리: 에이전트 청킹은 병렬 처리 모드를 지원하며, 멀티 스레딩 및 기타 기술을 사용하여 텍스트 청킹의 처리 속도를 크게 가속화할 수 있으며, 특히 대용량 문서 처리에서 이점이 더 분명할 때 유용합니다.
에이전트 청킹의 적용
에이전트 청킹 기술은 다양한 분야에 적용될 수 있는 강력한 잠재력을 보여줍니다:
1. 학습 향상
- 정의 및 설명: 에이전틱 RAG는 복잡한 정보를 관리 가능한 단위로 세분화하여 학습자의 이해도와 유지력을 향상시킴으로써 학습 과정을 최적화합니다. 이 접근 방식은 텍스트의 '에이전틱' 요소(예: 문자, 조직)에 특히 주의를 기울이며, 이러한 핵심 요소를 중심으로 정보를 구성함으로써 에이전틱 RAG는 보다 일관성 있고 접근하기 쉬운 학습 콘텐츠를 만들 수 있습니다.
- 학습 과정에서의 역할: 에이전트 RAG 프레임워크는 현대 교육 방법에서 점점 더 중요한 역할을 하고 있습니다. 교육자는 RAG 기술을 기반으로 하는 지능형 에이전트를 사용하여 다양한 학습자의 개별 요구 사항을 정확하게 충족하도록 콘텐츠를 보다 유연하게 조정할 수 있습니다.
- 교육 분야에서의 활용: 점점 더 많은 교육 기관에서 교육 전략을 혁신하고, 더 매력적이고 개인화된 커리큘럼을 개발하고, 교육 및 학습 성과를 개선하기 위해 에이전틱 RAG 기술을 사용하고 있습니다.
- 학생 참여에 미치는 영향: 에이전트 청킹은 명확하게 구조화되고 이해하기 쉬운 텍스트 블록으로 정보를 제시하여 학습에 대한 학생의 집중력, 동기 부여 및 흥미를 높이는 데 효과적입니다.
- 효과적인 패턴 인식: 교육에서 에이전트 RAG 시스템을 사용할 때 효과적인 패턴을 심층적으로 분석하고 식별하는 것은 교육 결과를 지속적으로 최적화하는 데 필수적입니다.
2. 정보 보존성 향상
- 인지 프로세스: 에이전트 RAG 기술은 정보를 정리하고 연관시키는 인간의 인지 과정의 자연스러운 경향을 활용하여 정보 보존을 향상시킵니다. 뇌는 데이터를 관리 가능한 단위로 정리하는 것을 선호하기 때문에 정보 검색 및 기억 과정을 크게 간소화할 수 있습니다.
- 기억 회상력 향상: 학습자는 텍스트와 관련된 '주체적' 요소(예: 개인 또는 조직)에 집중함으로써 학습 자료를 기존 지식과 더 쉽게 연결하여 학습한 정보를 더 효과적으로 기억하고 통합할 수 있습니다.
- 장기 유지 전략: 에이전틱 RAG 기술을 일상적인 학습 관행에 통합하면 지속적인 학습과 지식 축적을 위한 효과적인 전략을 수립하여 장기적인 지식 유지 및 개발이 가능합니다.
- 실제 적용 사례: 교육 및 비즈니스 교육과 같은 영역에서 최적의 정보 전달 및 활용을 위해 특정 대상의 요구에 맞게 에이전틱 RAG의 콘텐츠 프레젠테이션을 맞춤화할 수 있습니다.
3. 효율적인 의사 결정
- 비즈니스 애플리케이션: 비즈니스 세계에서 에이전틱 RAG 시스템은 의사결정을 위한 구조화된 프레임워크를 제공함으로써 비즈니스 리더의 의사결정 패러다임을 혁신적으로 바꾸고 있습니다. 이 시스템은 전략 계획과 운영 효율성의 과학성을 크게 향상시키는 프레임워크를 제공합니다.
- 의사 결정 프레임워크: 에이전틱 RAG는 복잡한 비즈니스 데이터와 정보를 더 작고 관리하기 쉬운 조각으로 분해하여 조직의 의사 결정권자가 핵심 요소에 집중하고, 방대한 정보 속에서 길을 잃지 않으며, 의사 결정 효율성을 개선할 수 있도록 도와줍니다.
- 비즈니스 리더를 위한 혜택: 에이전틱 RAG는 비즈니스 리더가 시장 트렌드와 고객의 니즈를 더 깊이 이해할 수 있도록 지원하여 기업의 전략적 조정 및 시장 대응을 위한 보다 정확한 의사 결정을 지원합니다.
- 구현 단계:
- 에이전틱 RAG 기술이 조직에 가치를 더할 수 있는 주요 비즈니스 영역을 파악하세요.
- 조직의 전략적 목표에 부합하는 맞춤형 에이전트 RAG 구현을 개발합니다.
- 에이전트 RAG 시스템 애플리케이션에 대한 직원 교육을 실시하여 시스템이 효과적으로 구현되고 적용될 수 있도록 합니다.
- 에이전트 RAG 시스템의 운영 효과를 지속적으로 모니터링하고 실제 적용 상황에 따라 최적화 전략을 조정하여 시스템 성능을 극대화할 수 있습니다.
에이전트 청킹의 이점
- 의미적 일관성: 에이전트 청킹은 의미적으로 더 의미 있는 텍스트 청크를 생성하여 검색된 정보의 정확도를 크게 향상시킵니다.
- 문맥 보존: 에이전트 청킹은 텍스트 블록 내에서 문맥의 일관성을 효과적으로 유지하여 LLM이 보다 정확하고 맥락에 맞는 응답을 생성할 수 있도록 합니다.
- 유연성: 에이전트 청킹은 다양한 길이, 구조 및 콘텐츠 유형의 문서에 유연하게 적용할 수 있는 뛰어난 유연성을 보여줍니다.
- 견고성: 에이전트 청킹에는 보호 및 폴백 메커니즘이 내장되어 있어 문서 구조 이상이나 LLM 성능 제한이 발생하는 경우에도 안정적인 시스템 운영을 보장합니다.
- 적응성: 에이전트 청킹은 다양한 LLM과 원활하게 통합되며 특정 애플리케이션 요구 사항에 맞게 세밀하게 조정된 최적화를 지원합니다.
에이전트 청킹의 실제 적용
- 잘못된 가정 92% 감소: 기존 청킹 방법의 단점은 부정확한 청킹으로 인해 AI 시스템이 잘못된 가정을 내릴 수 있다는 것입니다. 에이전트 청킹은 이러한 오류를 무려 92%까지 성공적으로 줄입니다.
- 향상된 답변 완성도: 에이전트 청킹은 답변의 완성도를 크게 향상시켜 사용자에게 보다 포괄적이고 정확한 답변을 제공하고 사용자 경험을 크게 개선합니다.
에이전트 청킹 구현(Python 예제)
이 섹션에서는 Langchain 프레임워크에 기반한 에이전트 청킹 파이썬 코드 구현 예제와 독자들이 빠르게 시작할 수 있도록 단계별로 자세한 코드 설명을 제공합니다.
전제 조건:
- Langchain 및 OpenAI Python 라이브러리가 설치되어 있는지 확인합니다:
pip install langchain openai - OpenAI API 키를 구성합니다.
샘플 코드:
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain import hub
# 1. 文本命题化 (Propositioning)
# 示例文本
text = """
On July 20, 1969, astronaut Neil Armstrong walked on the moon.
He was leading NASA's Apollo 11 mission.
Armstrong famously said, "That's one small step for man, one giant leap for mankind" as he stepped onto the lunar surface.
Later, he planted the American flag.
The mission was a success.
"""
# 从 Langchain hub 获取命题化提示模板
obj = hub.pull("wfh/proposal-indexing")
# 使用 GPT-4o 模型
llm = ChatOpenAI(model="gpt-4o")
# 定义 Pydantic 模型以提取句子
class Sentences(BaseModel):
sentences: list[str]
# 创建结构化输出的 LLM
extraction_llm = llm.with_structured_output(Sentences)
# 创建句子提取链
extraction_chain = obj | extraction_llm
# 将文本分割成段落 (为简化示例,本文假设输入文本仅包含一个段落,实际应用中可处理多段落文本。)
paragraphs = [text]
propositions = []
for p in paragraphs:
sentences = extraction_chain.invoke(p)
propositions.extend(sentences.sentences)
print("Propositions:", propositions)
# 2. 创建 LLM Agent
# 定义块元数据模型
class ChunkMeta(BaseModel):
title: str = Field(description="The title of the chunk.")
summary: str = Field(description="The summary of the chunk.")
# 用于生成摘要和标题的 LLM (这里可以使用温度较低的模型)
summary_llm = ChatOpenAI(temperature=0)
# 用于块分配的 LLM
allocation_llm = ChatOpenAI(temperature=0)
# 存储已创建的文本块的字典
chunks = {}
# 3. 创建新块的函数
def create_new_chunk(chunk_id, proposition):
summary_prompt_template = ChatPromptTemplate.from_messages(
[
(
"system",
"Generate a new summary and a title based on the propositions.",
),
(
"user",
"propositions:{propositions}",
),
]
)
summary_chain = summary_prompt_template | summary_llm
chunk_meta = summary_chain.invoke(
{
"propositions": [proposition],
}
)
chunks[chunk_id] = {
"chunk_id": chunk_id, # 添加 chunk_id
"summary": chunk_meta.summary,
"title": chunk_meta.title,
"propositions": [proposition],
}
return chunk_id # 返回 chunk_id
# 4. 将命题添加到现有块的函数
def add_proposition(chunk_id, proposition):
summary_prompt_template = ChatPromptTemplate.from_messages(
[
(
"system",
"If the current_summary and title is still valid for the propositions, return them."
"If not, generate a new summary and a title based on the propositions.",
),
(
"user",
"current_summary:{current_summary}\ncurrent_title:{current_title}\npropositions:{propositions}",
),
]
)
summary_chain = summary_prompt_template | summary_llm
chunk = chunks[chunk_id]
current_summary = chunk["summary"]
current_title = chunk["title"]
current_propositions = chunk["propositions"]
all_propositions = current_propositions + [proposition]
chunk_meta = summary_chain.invoke(
{
"current_summary": current_summary,
"current_title": current_title,
"propositions": all_propositions,
}
)
chunk["summary"] = chunk_meta.summary
chunk["title"] = chunk_meta.title
chunk["propositions"] = all_propositions
# 5. Agent 的核心逻辑
def find_chunk_and_push_proposition(proposition):
class ChunkID(BaseModel):
chunk_id: int = Field(description="The chunk id.")
allocation_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You have the chunk ids and the summaries. "
"Find the chunk that best matches the proposition. "
"If no chunk matches, return a new chunk id. "
"Return only the chunk id.",
),
(
"user",
"proposition:{proposition}\nchunks_summaries:{chunks_summaries}",
),
]
)
allocation_chain = allocation_prompt | allocation_llm.with_structured_output(ChunkID)
chunks_summaries = {
chunk_id: chunk["summary"] for chunk_id, chunk in chunks.items()
}
# 初始chunks可能为空,导致allocation_chain.invoke报错
if not chunks_summaries:
# 如果没有已存在的块,直接创建新块
next_chunk_id = 1
create_new_chunk(next_chunk_id, proposition)
return
best_chunk_id = allocation_chain.invoke(
{"proposition": proposition, "chunks_summaries": chunks_summaries}
).chunk_id
if best_chunk_id not in chunks:
# 如果返回的 chunk_id 不存在,创建新块
next_chunk_id = max(chunks.keys(), default=0) + 1 if chunks else 1
create_new_chunk(next_chunk_id, proposition)
else:
add_proposition(best_chunk_id, proposition)
# 遍历命题列表,进行分块
for i, proposition in enumerate(propositions):
find_chunk_and_push_proposition(proposition)
# 打印最终的块
print("\nFinal Chunks:")
for chunk_id, chunk in chunks.items():
print(f"Chunk {chunk_id}:")
print(f" Title: {chunk['title']}")
print(f" Summary: {chunk['summary']}")
print(f" Propositions: {chunk['propositions']}")
print("-" * 20)
코드 설명:
- 명제화:
- 코드 예시에서는 먼저 hub.pull("wfh/proposal-indexing")을 사용해 랭체인 허브에서 미리 정의된 프롬프트 템플릿을 로드합니다.
- 다음으로, 더 나은 성능을 위해 GPT-4o 모델을 선택하여 ChatOpenAI(model="gpt-4o")를 사용하여 LLM 인스턴스를 초기화했습니다.
- LLM에서 출력되는 문장 목록의 구조화된 구문 분석을 위한 문장 피단틱 모델을 정의합니다.
- 힌트 템플릿과 LLM 추출_체인 사이의 연결 체인을 구축합니다.
- 예제를 단순화하기 위해 이 글에서는 입력 텍스트에 단락이 하나만 포함되어 있다고 가정하고 실제 애플리케이션은 여러 단락의 텍스트를 처리할 수 있다고 가정합니다. 코드는 샘플 텍스트가 단락 목록으로 나뉘어져 있습니다.
- 단락을 반복하고 추출_체인을 사용하여 단락을 명제 목록으로 변환합니다.
- LLM 에이전트를 생성합니다:
- 청크메타 피단틱 모델을 정의하고 블록 메타데이터 구조(제목 및 요약)를 정의합니다.
- summary_llm과 allocation_llm의 두 가지 LLM 인스턴스를 생성합니다. summary_llm은 텍스트 블록의 요약과 제목을 생성하는 데 사용되며, allocation_llm은 제안을 어느 기존 블록에 배치할지 결정하거나 새 블록을 생성하는 역할을 합니다.
- 생성된 텍스트 블록을 저장하는 데 사용되는 청크 사전을 초기화합니다.
- create_new_chunk 함수:
- 이 함수는 입력 매개변수로 chunk_id와 제안을 받습니다.
- 명제를 기반으로 요약_프롬프트_템플릿 및 요약_llm을 사용하여 블록의 제목과 요약이 생성됩니다.
- 을 클릭하고 새 블록을 청크 사전에 저장합니다.
- 추가_제안 함수:
- 이 함수는 또한 chunk_id와 제안을 입력으로 받습니다.
- 청크 사전에서 기존 블록 정보를 검색합니다.
- 현재 블록의 제안서 목록을 업데이트합니다.
- 블록 제목과 요약을 다시 평가하고 업데이트합니다.
- 를 클릭하고 청크 사전에서 해당 블록의 메타데이터를 업데이트합니다.
- 찾기_청크_및_푸시_제안 함수(에이전트 핵심 로직):
- LLM 출력용 블록 ID를 구문 분석하기 위한 ChunkID Pydantic 모델을 정의합니다.
- 현재 제안과 가장 일치하는 기존 블록을 찾거나 새 블록 ID를 반환하도록 LLM에 지시하는 할당_프롬프트를 생성합니다.
- 프롬프트 템플릿과 allocation_llm을 연결하여 allocation_chain을 빌드합니다.
- 기존 블록의 ID와 요약 정보를 저장하는 chunks_summaries 딕셔너리를 구축합니다.
- 청크 사전이 비어 있는 경우(즉, 아직 텍스트 청크가 없는 경우) 새 청크가 바로 만들어집니다.
- allocation_chain을 사용하여 LLM을 호출하여 가장 일치하는 블록의 ID를 가져옵니다.
- LLM에서 반환한 chunk_id가 청크 사전에 없는 경우, 즉 새 텍스트 청크를 만들어야 함을 나타내는 경우 create_new_chunk 함수가 호출됩니다.
- 반환된 chunk_id가 청크 사전에 이미 존재하여 현재 제안이 기존 텍스트 블록에 추가되어야 함을 나타내는 경우 add_proposition 함수를 호출합니다.
- 메인 루프:
- 명제 목록을 반복합니다.
- 각 명제에 대해 find_chunk_and_push_proposition 함수가 호출되고 명제가 적절한 텍스트 블록에 할당됩니다.
- 결과 출력:
- 제목, 초록 및 명제 목록이 포함된 생성된 텍스트 블록의 최종 출력물입니다.
코드 개선 사항:
- 청크 사전이 비어 있을 때 create_new_chunk 함수를 직접 호출하여 잠재적인 오류를 방지함으로써 find_chunk_and_push_proposition 함수를 개선합니다.
- create_new_chunk 함수에서 chunk_id 키-값 쌍이 chunks[chunk_id] 사전에 추가되어 블록 ID를 명시적으로 기록합니다.
- next_chunk_id 생성 로직을 최적화하면 ID 생성 로직의 견고성이 향상되고 다양한 시나리오에서 올바른 ID 생성을 보장할 수 있습니다.
구축 대 구매
에이전트 청킹은 AI 에이전트 워크플로우의 한 부분일 뿐이지만 의미적으로 일관된 텍스트 청크를 생성하는 데 매우 중요합니다. 자체 에이전트 청킹 솔루션을 구축하는 것과 기성 솔루션을 구매하는 것에는 장단점이 있습니다:
셀프 빌드의 장점:
- 높은 수준의 제어 및 사용자 지정: 자체 구축된 솔루션을 통해 사용자는 신속한 설계부터 알고리즘 최적화에 이르기까지 특정 요구 사항에 따라 심층적인 사용자 지정을 할 수 있으며, 이 모든 것이 실제 애플리케이션 시나리오에 완벽하게 맞습니다.
- 정확한 타겟팅: 기업은 고유한 데이터 특성과 애플리케이션 요구 사항에 따라 최적의 성능을 위해 가장 적합한 텍스트 청킹 전략을 맞춤 설정할 수 있습니다.
자체 구축의 단점:
- 높은 엔지니어링 비용: 자체 에이전트 청킹 솔루션을 구축하려면 자연어 처리 기술에 대한 전문 지식과 상당한 개발 시간을 투자해야 하므로 비용이 많이 듭니다.
- LLM 동작의 예측 불가능성: LLM의 동작은 때때로 예측 및 제어가 어렵기 때문에 자체 구축 솔루션에 기술적 어려움이 있습니다.
- 지속적인 유지 관리 오버헤드: 생성 AI 기술은 빠르게 발전하고 있으며, 자체 구축 솔루션은 기술 발전 속도를 따라잡기 위해 유지 관리 및 업데이트에 대한 지속적인 투자가 필요합니다.
- 프로덕션 과제: 프로토타이핑 단계에서 좋은 결과를 얻는 것도 중요하지만, 에이전틱 청킹 솔루션을 99% 이상의 높은 정확도로 실제로 프로덕션에 적용하는 데에는 여전히 상당한 어려움이 있습니다.
요약
에이전트 청킹은 인간의 이해와 판단을 모방하여 의미적으로 일관된 텍스트 청크를 생성함으로써 RAG 시스템의 성능을 크게 향상시키는 강력한 텍스트 청킹 기법입니다. 에이전트 청킹은 기존 텍스트 청킹 방법의 많은 한계를 극복하여 LLM이 보다 정확하고 완전하며 문맥에 맞는 답변을 생성할 수 있게 해줍니다.
이 글에서는 자세한 코드 예시와 단계별 설명을 통해 에이전트 청킹의 작동 원리와 구현에 대한 이해를 돕습니다. 물론 에이전트 청킹을 구현하려면 어느 정도의 기술 투자가 필요하지만, 성능 향상과 애플리케이션 가치는 분명합니다. 에이전틱 청킹은 의심할 여지 없이 대량의 텍스트 데이터를 처리해야 하고 RAG 시스템에 대한 높은 성능 요구 사항이 있는 애플리케이션 시나리오에 효과적인 기술 솔루션입니다.
향후 트렌드: 에이전트 청킹의 향후 방향에는 다음이 포함될 수 있습니다:
- 그래프 데이터베이스와의 긴밀한 통합을 통해 지식 그래프를 구축하고, 그래프 구조 기반 검색 강화 생성(Graph RAG) 기술을 더욱 발전시켜 더 심층적인 지식 마이닝 및 활용을 달성합니다.
- 텍스트 청킹의 정확도와 처리 효율성을 더욱 향상시키기 위해 LLM의 힌트 엔지니어링 및 명령어 설계를 지속적으로 최적화합니다.
- 더 스마트한 텍스트 블록 병합 및 분할 전략을 개발하여 더욱 복잡하고 다양한 문서 구조에 효과적으로 대처하고 에이전트 청킹의 활용성을 개선합니다.
- 지능형 텍스트 요약, 고품질 기계 번역 등 더 광범위한 분야에 에이전트 청킹을 적용하여 적용 범위를 넓히기 위해 적극적으로 연구하고 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...