
일반 소개
Aana SDK는 말라얄람어 "ആന"(코끼리)의 이름을 딴 모비우스랩에서 개발한 오픈 소스 프레임워크입니다. 개발자가 텍스트, 이미지, 오디오, 비디오 등의 데이터 처리를 지원하는 멀티모달 AI 모델을 신속하게 배포하고 관리할 수 있도록 도와주며, Aana SDK는 Ray 분산 컴퓨팅 프레임워크에 기반하여 안정성, 확장성, 효율성을 고려하여 설계되었습니다. 개발자는 이를 사용하여 비디오 트랜스크립션, 이미지 설명 또는 스마트 채팅 도구와 같은 독립형에서 클러스터형 애플리케이션을 쉽게 구축할 수 있습니다.

기능 목록
- 멀티모달 데이터 지원: 텍스트, 이미지, 오디오, 비디오를 동시에 처리할 수 있는 기능입니다.
- 모델 배포 및 확장: 머신 러닝 모델은 단일 머신 또는 클러스터에 배포할 수 있습니다.
- 자동 생성 API: 정의된 엔드포인트를 기반으로 API를 자동으로 생성하고 유효성을 검사합니다.
- 실시간 스트리밍 출력: 실시간 애플리케이션 및 대규모 언어 모델에 대한 스트리밍 결과를 지원합니다.
- 미리 정의된 데이터 유형: 이미지, 동영상 등과 같은 일반적인 데이터 유형을 기본적으로 지원합니다.
- 백그라운드 작업 대기열: 추가 구성 없이 백그라운드에서 엔드포인트 작업이 자동으로 실행됩니다.
- 여러 모델 통합: 위스퍼, vLLM, 허깅 페이스 트랜스포머 등이 지원됩니다.
- 자동 문서 생성: 엔드포인트를 기반으로 애플리케이션 문서를 자동으로 생성합니다.
도움말 사용
설치 프로세스
Aana SDK를 설치하는 방법은 PyPI와 GitHub 두 가지가 있으며, 단계는 다음과 같습니다:
- 환경 준비하기
- Python 3.8 이상이 필요합니다.
- 시스템에 적합한 버전을 선택하여 PyTorch를 수동으로 설치하는 것이 좋습니다(>= 2.1 참조). https://pytorch.org/get-started/locally/). 그렇지 않으면 기본 설치에서 GPU를 최대한 활용하지 못할 수 있습니다.
- GPU를 사용하는 경우 성능 향상을 위해 플래시 어텐션 라이브러리를 설치하는 것이 좋습니다( https://github.com/Dao-AILab/flash-attention).
- PyPI를 통한 설치
- 다음 명령을 실행하여 핵심 종속 요소를 설치합니다:
pip install aana - 전체 기능을 사용하려면 모든 추가 종속성을 설치하세요:
pip install aana[all] - 기타 옵션은 다음과 같습니다.
vllm(언어 모델링),asr(음성 인식),transformers(변환기 모델) 등 필요에 따라 변경할 수 있습니다.
- 다음 명령을 실행하여 핵심 종속 요소를 설치합니다:
- GitHub를 통한 설치
- 복제 창고:
git clone https://github.com/mobiusml/aana_sdk.git cd aana_sdk - 시를 사용하여 설치합니다(시 >= 2.0 권장, https://python-poetry.org/docs/#installation 참조):
poetry install --extras all - 개발 환경에서는 테스트 종속성을 추가할 수 있습니다:
poetry install --extras all --with dev,tests
- 복제 창고:
- 설치 확인
- 가져오기
python -c "import aana; print(aana.__version__)"버전 번호가 반환되면 성공합니다.
- 가져오기
사용 방법
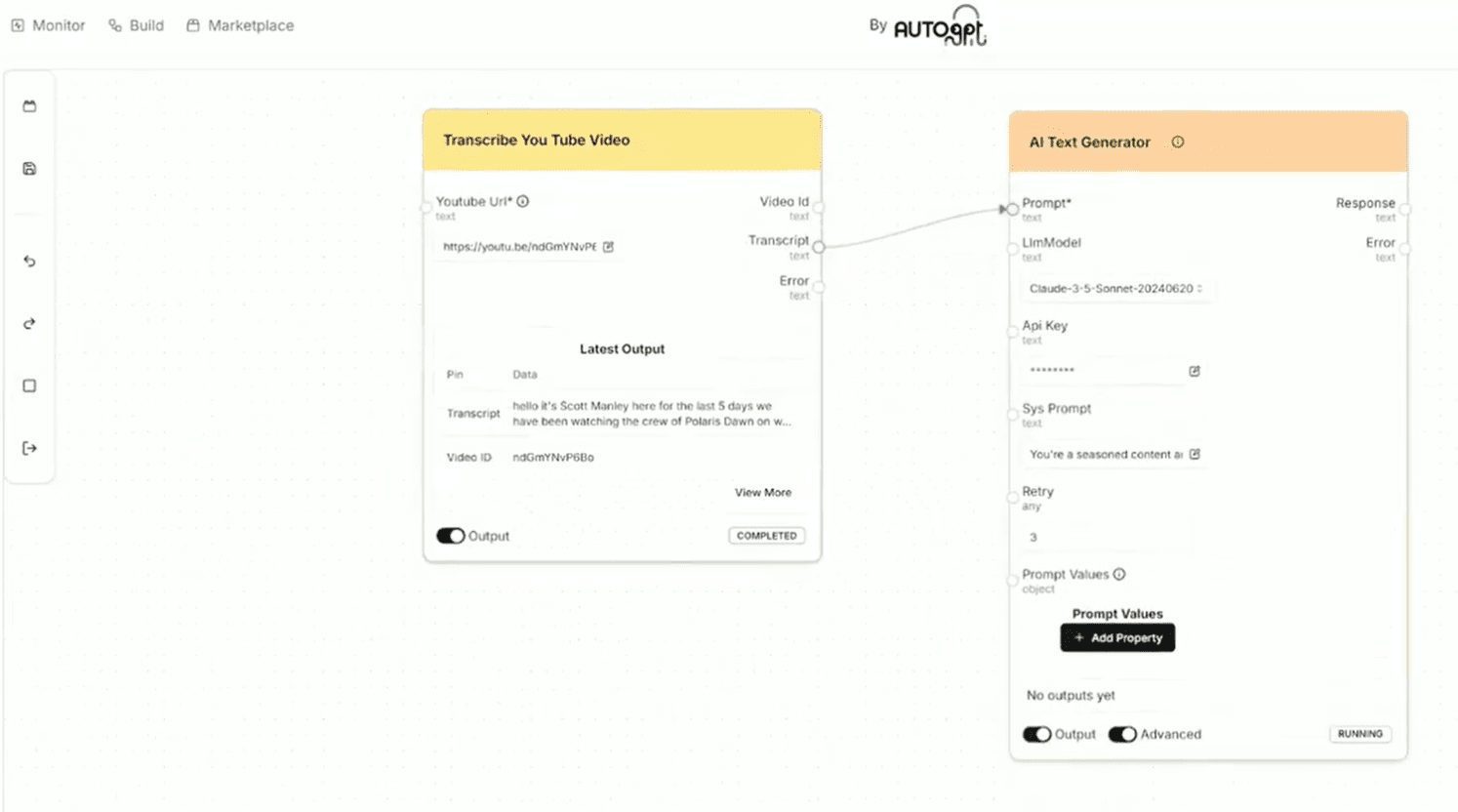
Aana SDK의 핵심은 배포와 엔드포인트입니다. 배포는 모델을 로드하고 엔드포인트는 기능을 정의합니다. 다음은 비디오 트랜스크립션의 예입니다:
- 새 애플리케이션 만들기
- 새 폴더(예
my_app), 생성app.py. - 참조 가능한 템플릿 https://github.com/mobiusml/aana_app_template 빠른 시작.
- 새 폴더(예
- 구성 배포
- 존재
app.py로드 중 Whisper 모델:from aana.sdk import AanaSDK from aana.deployments.whisper_deployment import WhisperDeployment, WhisperConfig, WhisperModelSize, WhisperComputeType app = AanaSDK(name="video_app") app.register_deployment( "whisper", WhisperDeployment.options( num_replicas=1, ray_actor_options={"num_gpus": 0.25}, # 若无GPU可删除此行 user_config=WhisperConfig( model_size=WhisperModelSize.MEDIUM, compute_type=WhisperComputeType.FLOAT16 ).model_dump(mode="json") ) )
- 존재
- 엔드포인트 정의
- 트랜스크립션 엔드포인트를 추가합니다:
from aana.core.models.video import VideoInput @app.aana_endpoint(name="transcribe_video") async def transcribe_video(self, video: VideoInput): audio = await self.download(video.url) # 下载并提取音频 transcription = await self.whisper.transcribe(audio) # 转录 return {"transcription": transcription}
- 트랜스크립션 엔드포인트를 추가합니다:
- 애플리케이션 실행
- 터미널에서 실행됩니다:
python app.py serve - 또는 Aana CLI를 사용하세요:
aana deploy app:app --host 127.0.0.1 --port 8000 - 애플리케이션이 시작되면 기본 주소는
http://127.0.0.1:8000.
- 터미널에서 실행됩니다:
- 테스트 기능
- cURL을 사용하여 요청을 보냅니다:
curl -X POST http://127.0.0.1:8000/transcribe_video -F body='{"url":"https://www.youtube.com/watch?v=VhJFyyukAzA"}' - 또는 Swagger UI(
http://127.0.0.1:8000/docs) 테스트.
- cURL을 사용하여 요청을 보냅니다:
주요 기능 작동
- 멀티모달 처리
음성 트랜스크립션 외에도 이미지 모델(예: Blip2)을 통합하여 설명을 생성할 수 있습니다:captions = await self.blip2.generate_captions(video.frames)
- 스트리밍 출력
예를 들어 실시간 결과 반환을 지원합니다:@app.aana_endpoint(name="chat", streaming=True) async def chat(self, question: str): async for chunk in self.llm.generate_stream(question): yield chunk - 클러스터 확장
레이 클러스터로 배포하려면, 레이 클러스터의app.connect()클러스터 주소를 지정하기만 하면 됩니다.
추가 도구
- 레이 대시보드실행 후 액세스
http://127.0.0.1:8265를 클릭하고 클러스터 상태 및 로그를 확인합니다. - 도커 배포https://mobiusml.github.io/aana_sdk/pages/docker/ 참조.
애플리케이션 시나리오
- 비디오 콘텐츠 데이터 정렬
교육용 동영상에 자막과 요약을 생성하여 쉽게 보관하고 검색할 수 있습니다. - 지능형 질문 및 답변 시스템(Q&A)
사용자가 동영상을 업로드한 다음 질문을 하면 시스템이 오디오 및 동영상 콘텐츠를 기반으로 답변합니다. - 엔터프라이즈 데이터 분석
회의 녹화 및 비디오에서 주요 정보를 추출하여 보고서를 생성하세요.
QA
- GPU가 필요하신가요?
필수는 아니며 CPU로도 실행할 수 있지만 GPU(40GB RAM 권장)를 사용하면 효율성이 크게 향상됩니다. - 설치 오류는 어떻게 처리하나요?
파이썬 버전과 종속성이 일치하는지 확인하려면--log-level DEBUG자세한 로그 보기. - 어떤 언어 모델이 지원되나요?
트랜스포머를 통해 더 많은 허깅 페이스 모델 통합을 위한 내장형 vLLM, 위스퍼 등이 제공됩니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...