
Vannaのローカル展開:効率的なText2SQL変換を簡単に

Vannaは、自然言語をSQLクエリ文に変換する、高く評価されているText2SQLオープンソース・フレームワークだ。この記事では、Vannaをローカルにデプロイし、MySQLデータベースや ディープシーク モデルは、ツールをすぐに使い始められるように構成され、テストされています。すべての操作は、手順が明確で実行可能であることを保証するために、実際のテストに基づいています。
Python環境セットアップ
Vannaを実行するには、まず安定したPython環境が必要です。ここでは、Miniconda3を例に、Vannaを設定するためのステップバイステップのガイドを示します。
Miniconda3のインストール
- インストールパッケージをダウンロードする:
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh - インストールスクリプトを実行する:
sh Miniconda3-latest-Linux-x86_64.sh - 環境変数を設定する:
vim /etc/profileファイルに追加する:
export PATH="/data/apps/miniconda3/bin:$PATH"設定を保存して更新する:
source /etc/profile - アンインストールが必要な場合は、インストールディレクトリを削除すればよい:
rm -rf /data/apps/miniconda3/
仮想環境の構築
- Python 3.10の環境を作る:
conda create -n test python=3.10 - 環境を有効化する(新しい端末または再起動後に有効にする必要があります):
conda activate test - その他の一般的なコマンド:
- 出口環境:
conda deactivate - 環境情報を見る
conda info --env
- 出口環境:
上記のステップを完了すると、Vannaのデプロイの土台となるスタンドアロンのPython仮想環境が出来上がる。
Vannaの展開と設定
Python環境の準備ができたので、Vannaのコア設定に移ろう。以下の操作は公式ドキュメント(https://vanna.ai/docs/)を参照し、MySQLデータベースを例にしています。
データベース接続の設定
まず、MySQLアカウント、パスワード、ポートでデータベースに正しくログインできることを確認します。正常な接続をテストした後、Vanna公式ドキュメントのMySQL設定ページを開いてください(左のメニューバーでMySQLを選択してください)。ページには、以下のようなサンプル接続コードが表示されます:
データベース情報に基づいて、コード内のパラメータ(ホスト、ユーザー、パスワードなど)を調整し、Vannaがスムーズに接続できるようにします。
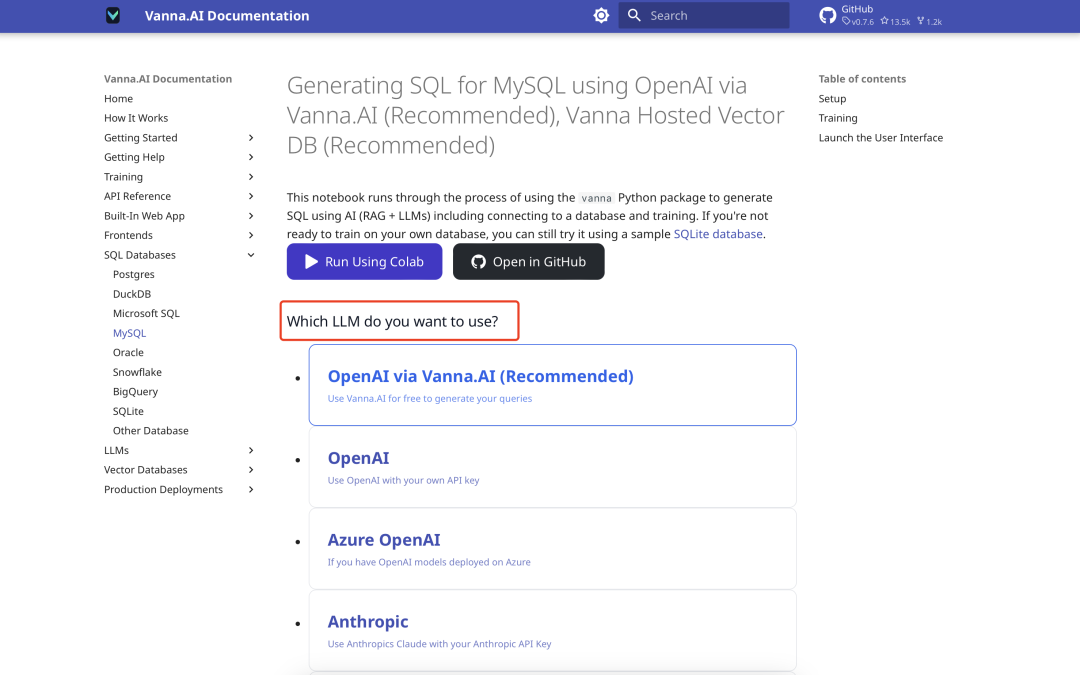
言語モデルの選択
Vannaは様々なLarge Language Models(LLM)をサポートしている。公式ページでは、例えば次のようにモデルの選択を促します。 オーラマ またはAPIコールを使用します。ここでは、シリコンベースのフローに対するDeepseekモデルを例として示す。
- オッラマの経験定量化されたDeepseek-7bモデルの導入が試みられたが、結果は芳しくなかった。
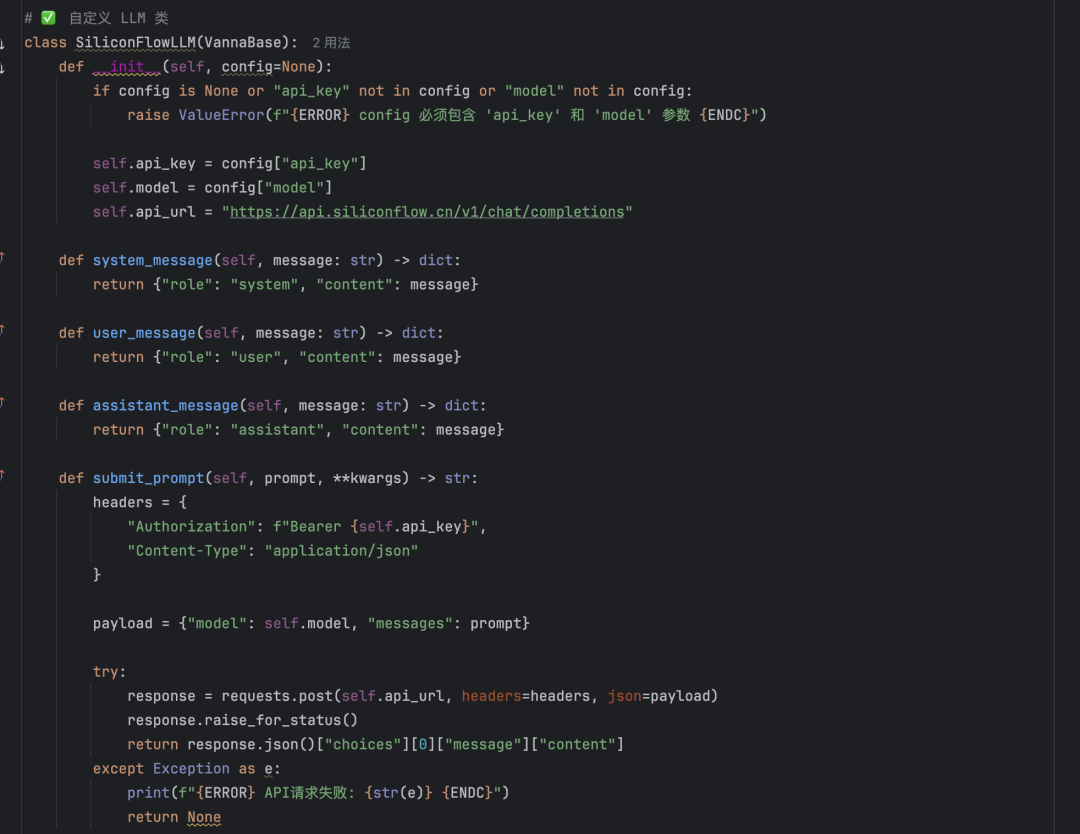
- ディープシークAPIin silico フローを介した Deepseek モデルの呼び出しの方が、より優れた性能を発揮します。ただし、公式にサポートされていないモデルを使用するには、カスタム LLM クラスが必要です。Vannaオープンソースプロジェクトの ミストラル 実装 (mistral.py) を使用して、Deepseek に適合するクラスを作成します。
設定画面は以下の通り:
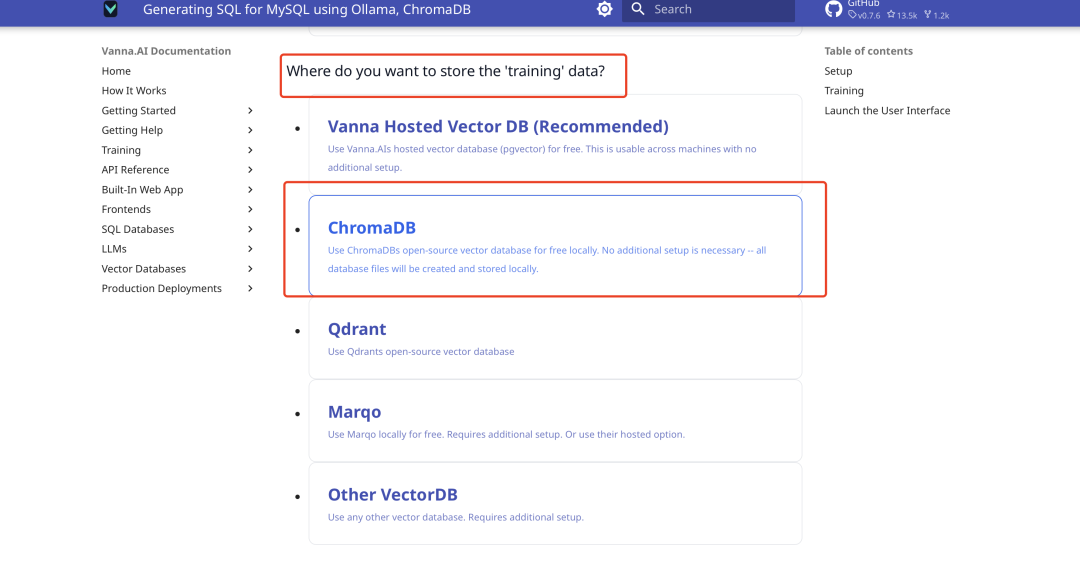
ベクター・データベースのセットアップ
VannaはデフォルトでChromaDBを小さなベクターデータベースとして統合しており、追加のインストールは必要ありません。公式ドキュメントは、以下のように、あなたの選択に従ってコードを生成します:
依存関係のインストールとコードの準備
- アクティブ化された仮想環境にVannaとその依存関係をインストールする:
pip install vanna - を作成する。
.pyファイルを作成し、そこに公式生成コードをコピーします。以下は、MySQLとDeepseekを適合させるためのサンプルコードスニペットです(実際の状況に応じてパラメータを調整する必要があります):from vanna.remote import VannaDefault vn = VannaDefault(model='deepseek', api_key='your_api_key') vn.connect_to_mysql(host='localhost', dbname='test_db', user='root', password='your_password', port=3306)
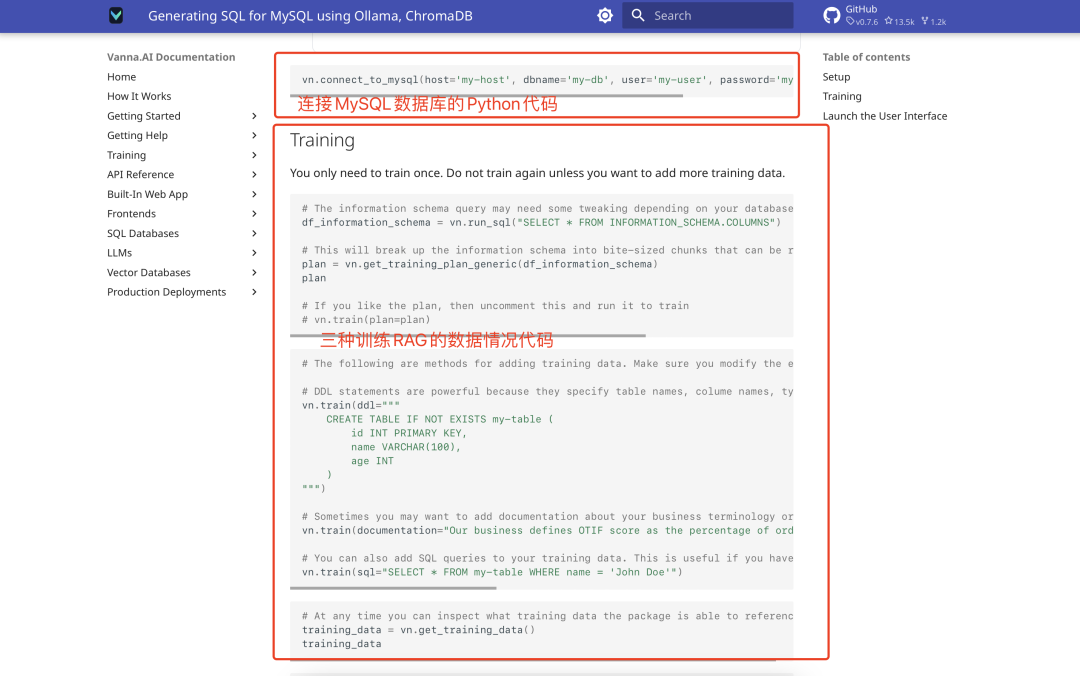
データトレーニング
VannaはSQLステートメント、製品ドキュメント、データベーステーブル構造記述の3種類のトレーニングデータをサポートしています。ここでは、テーブル構造の説明を使用することをお勧めします。トレーニングの手順は以下の通りです:
- テーブル構造データ(DDLファイルなど)を準備する。
- 公式に提供されたトレーニングコードを使用する:
vn.train(ddl="CREATE TABLE employees (id INT, name VARCHAR(255), salary INT)") - トレーニングのプロセスを以下に示す:
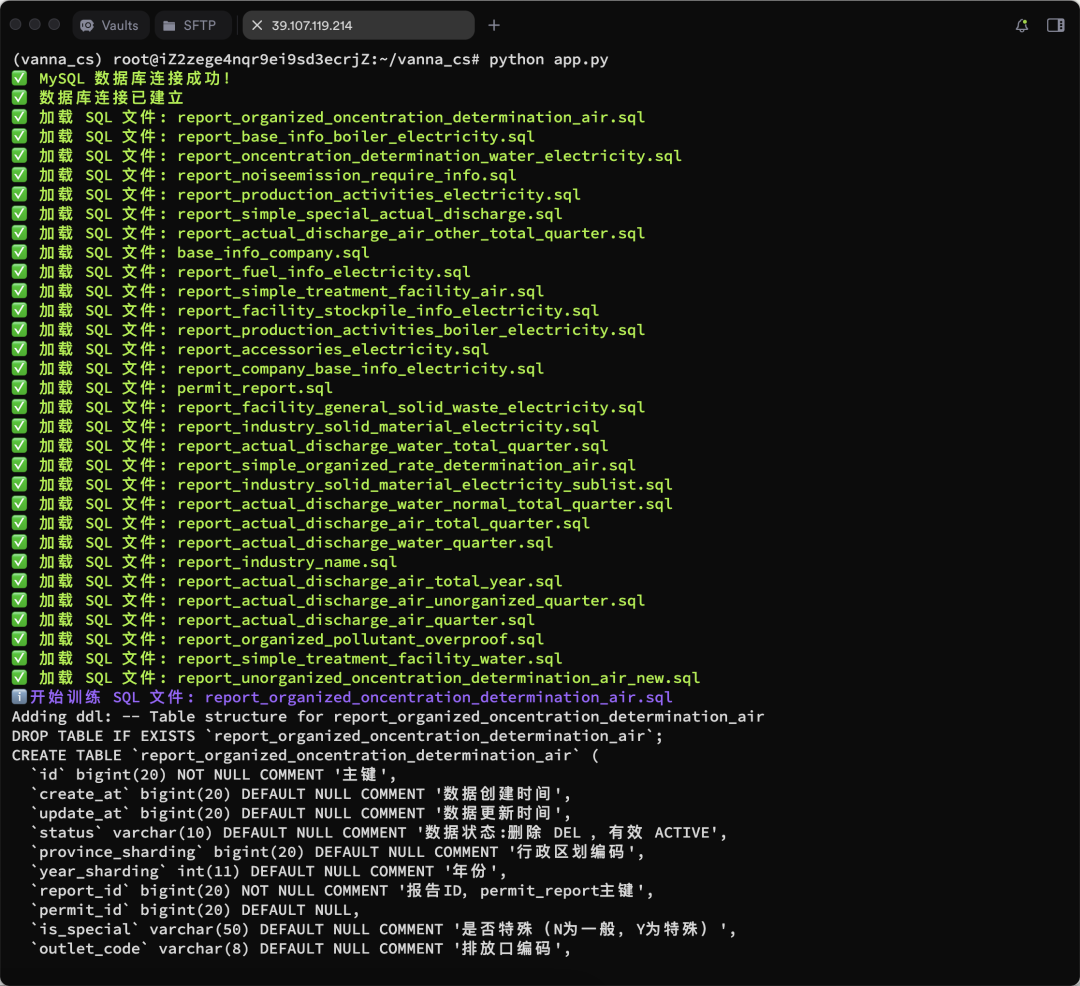
より多くのトレーニング結果が示されている:
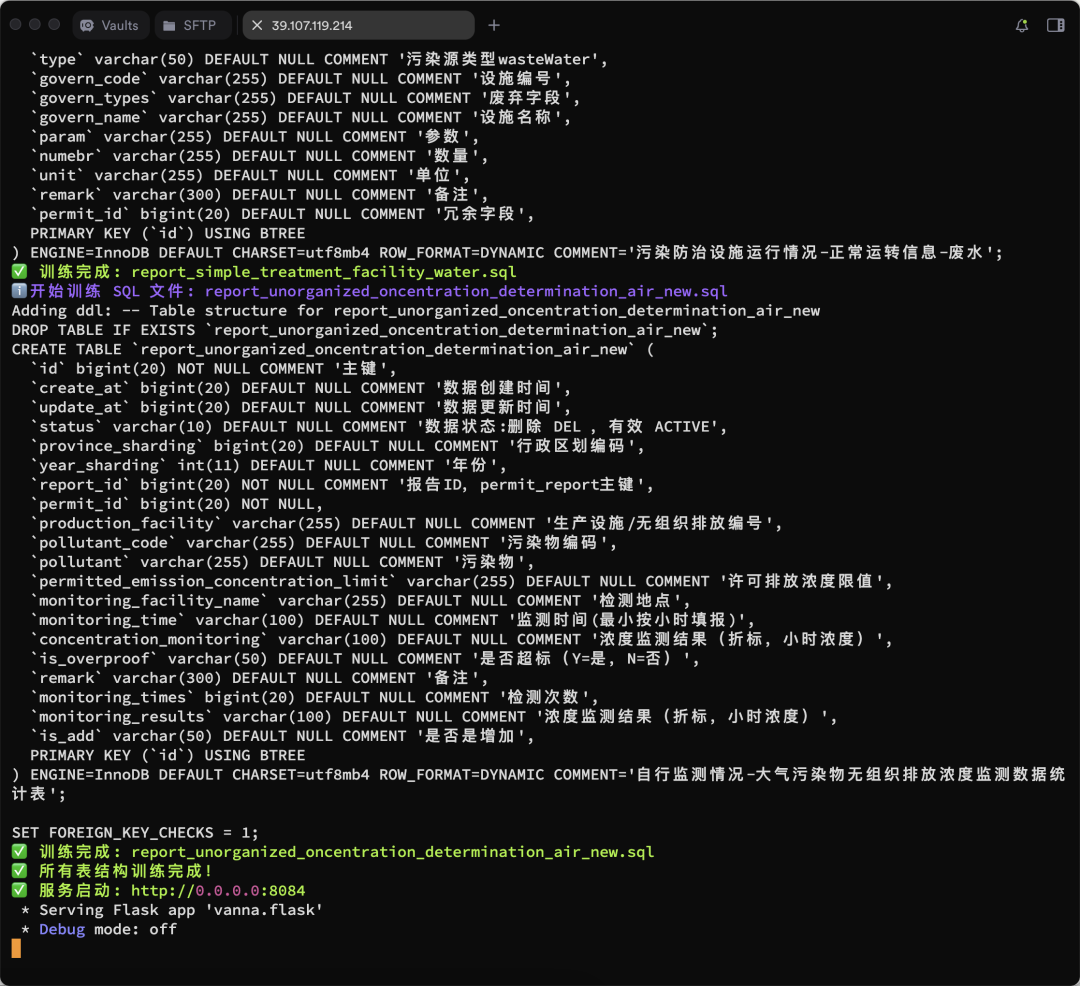
ウェブインターフェースの実行
トレーニングが完了したら、以下のFlask APIコードを実行してVannaのWeb UIを起動します:
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()
ローカルアドレスへのアクセス(通常は http://127.0.0.1:5000)、インターフェイスからSQLクエリーを実行できる。
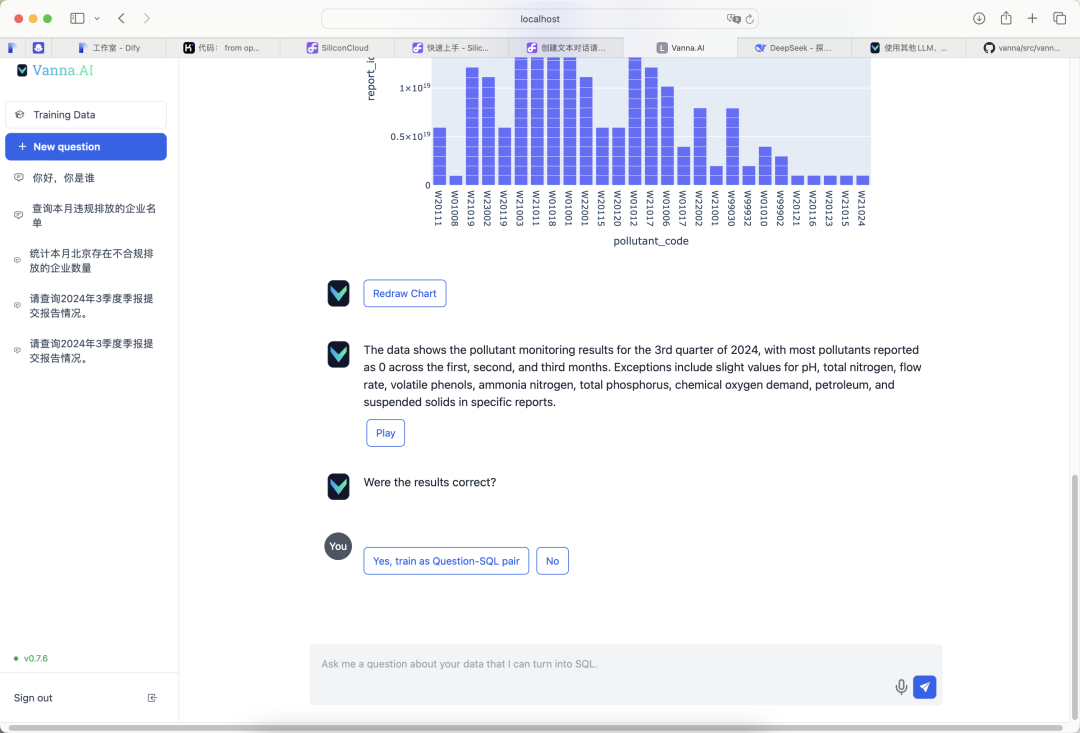
問い合わせ効果表示
配備後、VannaのQ&A機能は満足のいくものでした。以下は実際のテスト結果です:
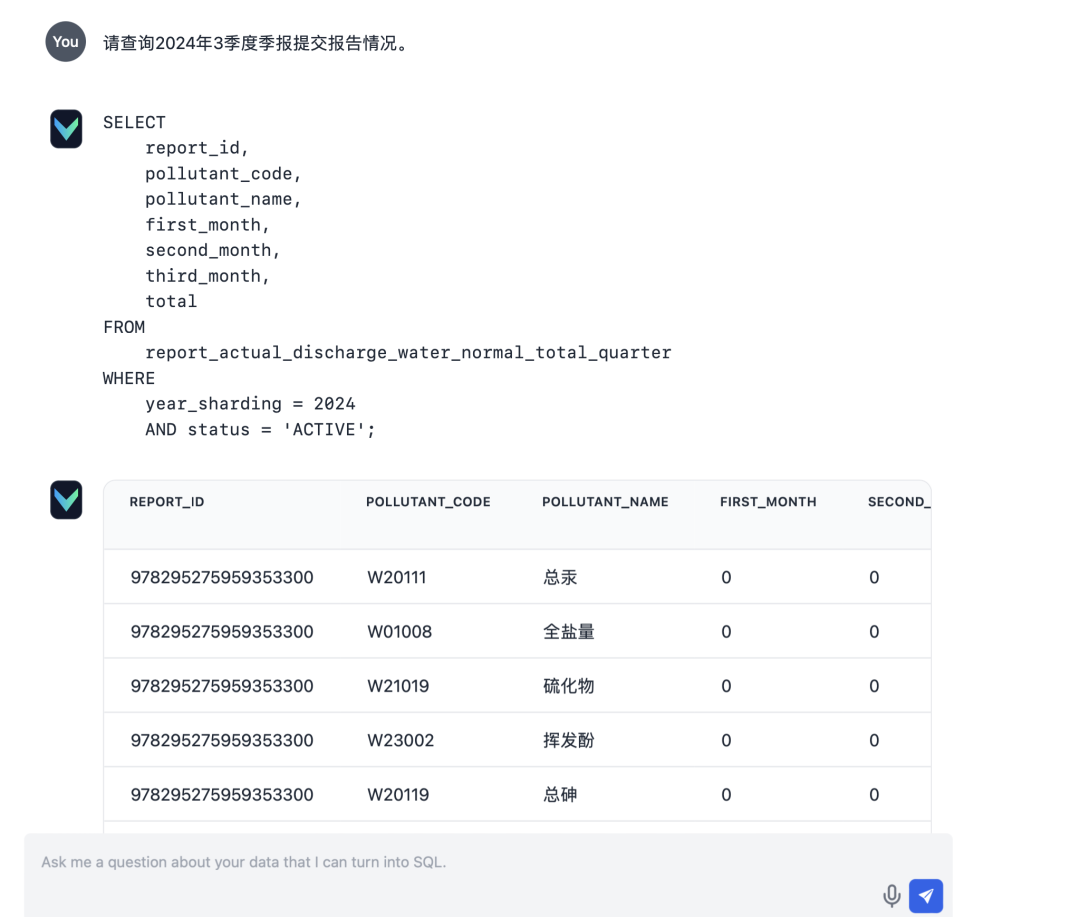
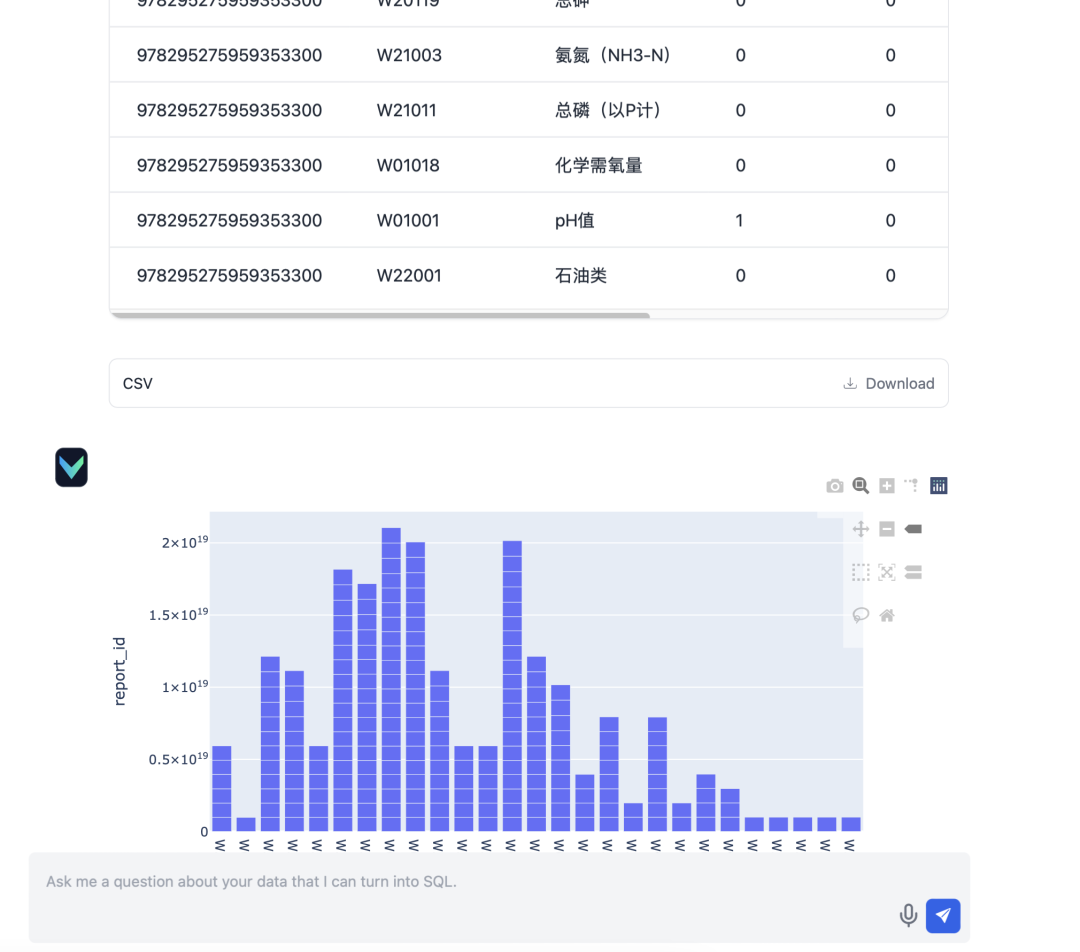
- インプット:"2024年3月期の四半期報告書の提出状況についてお問い合わせください。"

- 入力:"統計数"
- 入力:"汚染物質統計"
まとめと提言
これらのステップに従うことで、Vannaをローカルに展開し、MySQLおよびDeepseekモデルと組み合わせて効率的なText2SQL機能を実装することができます。他のツールと比較して、Vannaは使いやすさと有効性において明らかな利点があります。初心者は、テーブル構造を使用してデータを学習することを優先し、実際のニーズに応じて言語モデルの構成を調整することをお勧めします。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません