UIGEN-T1-Qwen-7b: HTML および CSS UI コンポーネント生成のための特殊モデル

はじめに
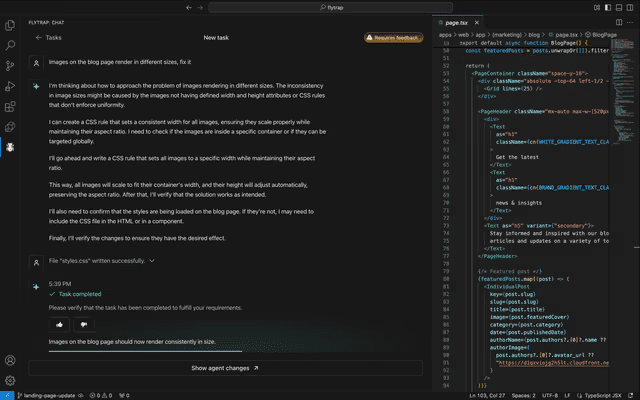
UIGEN-T1は70億パラメータを持つ。 変圧器 このモデルは、Qwen2.5-Coder-7B-Instruct をベースに微調整され、推論ベースの UI 生成用に設計されています。洗練された思考の連鎖アプローチを使用して、強力なHTMLとCSSベースのUIコンポーネントを生成します。現在のところ、ダッシュボード、ランディングページ、登録フォームなどの基本的なアプリケーションに限定されています。このモデルは、設計原則に関する推論によってHTMLとCSSのレイアウトを生成します。強力な連鎖思考の推論プロセスを持っていますが、現在のところ、テキストベースのUI要素と、より単純なフロントエンド・アプリケーションに限定されています。このモデルはダッシュボード、ランディングページ、登録フォームに優れていますが、高度なインタラクティブ性(JavaScriptを多用する機能など)には欠けています。


機能一覧
- UIジェネレーションユーザーインターフェイスを構築するためのHTMLとCSSコードを生成する能力。
- チェーン思考連鎖思考的アプローチでデザイン原則を推論し、UIレイアウトを生成します。
- 適用シナリオダッシュボード、ランディングページ、登録フォームなどの基本的なアプリケーションに最適です。
- コード生成生成されたコードはよく構造化されており、効果的だ。
ヘルプの使用
UIGEN-T1は、キュー・ワードに基づいてユーザー・インターフェース(UI)のHTMLとCSSコードを生成することができる。以下は、このモデルを使用するための基本的な手順と注意点である:
1.環境を整える
あなたの環境が以下の要件を満たしていることを確認してください:
- ソフトウェア少なくとも12GBのVRAMを推奨します。
- ハードウェア::
- トランスフォーマーライブラリー(ハグ顔)
- パイトーチ
2.依存関係のインストール
pip install transformers
pip install torch
3.基本推論コード
基本的な推論には以下のコードを使用する:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "smirki/UIGEN-T1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to("cuda")
prompt = """<|im_start|>user
Make a dark-themed dashboard for an oil rig.<|im_end|>
<|im_start|>assistant
<|im_start|>think
"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=12012, do_sample=True, temperature=0.7) #max tokens has to be greater than 12k
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
4.コードの解釈
- モデルローディング::
model_name = "smirki/UIGEN-T1"モデル名を指定します。tokenizer = AutoTokenizer.from_pretrained(model_name)学習済みの曖昧性解消器をロードする。model = AutoModelForCausalLM.from_pretrained(model_name).to("cuda")モデルをロードし、CUDAデバイス(利用可能な場合)に移動します。
- キュー・ワードの準備::
promptユーザーの指示を含むプロンプトワード。例えば、石油掘削施設のダッシュボードをダークなテーマで作成します。
- モデル化された推論::
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")キューワードをPyTorchテンソルに変換し、CUDAデバイスに移動する。outputs = model.generate(**inputs, max_new_tokens=12012, do_sample=True, temperature=0.7)出力を生成する。max_new_tokens生成されるトークンの最大数を設定し、12012より大きくなければならない。do_sample生成されるコンテンツの多様性を高めるためにサンプリングを可能にする。temperature値を小さくすると、出力はより決定論的になる。
- 出力デコード::
print(tokenizer.decode(outputs, skip_special_tokens=True))生成されたトークンをテキストにデコードし、結果を表示します。
5.使用テクニック
- キュー・ワード・エンジニアリング::
- よりよい推論をするためには、入力プロンプトの最後に "answer "を加える必要があるかもしれない。
- 例
Make a dark-themed dashboard for an oil rig. answer
- マニュアル後処理::
- 生成されたUIコードは、改良のために手作業による後処理が必要になる場合がある。
- 微調整::
- このモデルは、特定のフロントエンド・フレームワーク(React、Vueなど)向けにさらに微調整することができる。
6.制限事項
- 複雑なフロントエンド・アプリケーションには不向きこのモデルは、JavaScriptのインタラクションを多用する複雑なフロントエンド・アプリケーションには当てはまらない。
- 限られたデザインの多様性このモデルは基本的なフロントエンドのレイアウトを好むため、クリエイティブで高度なUIレイアウトを生成することはできません。
- 出土品一部の出力には書式アーチファクトが含まれる場合があります。
7.適用可能なシナリオ
- インストルメントパネルデータ表示画面を素早く生成
- ランディングページシンプルな1ページのアプリケーションを作成します。
- 登録フォームユーザー登録画面を作成します。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません