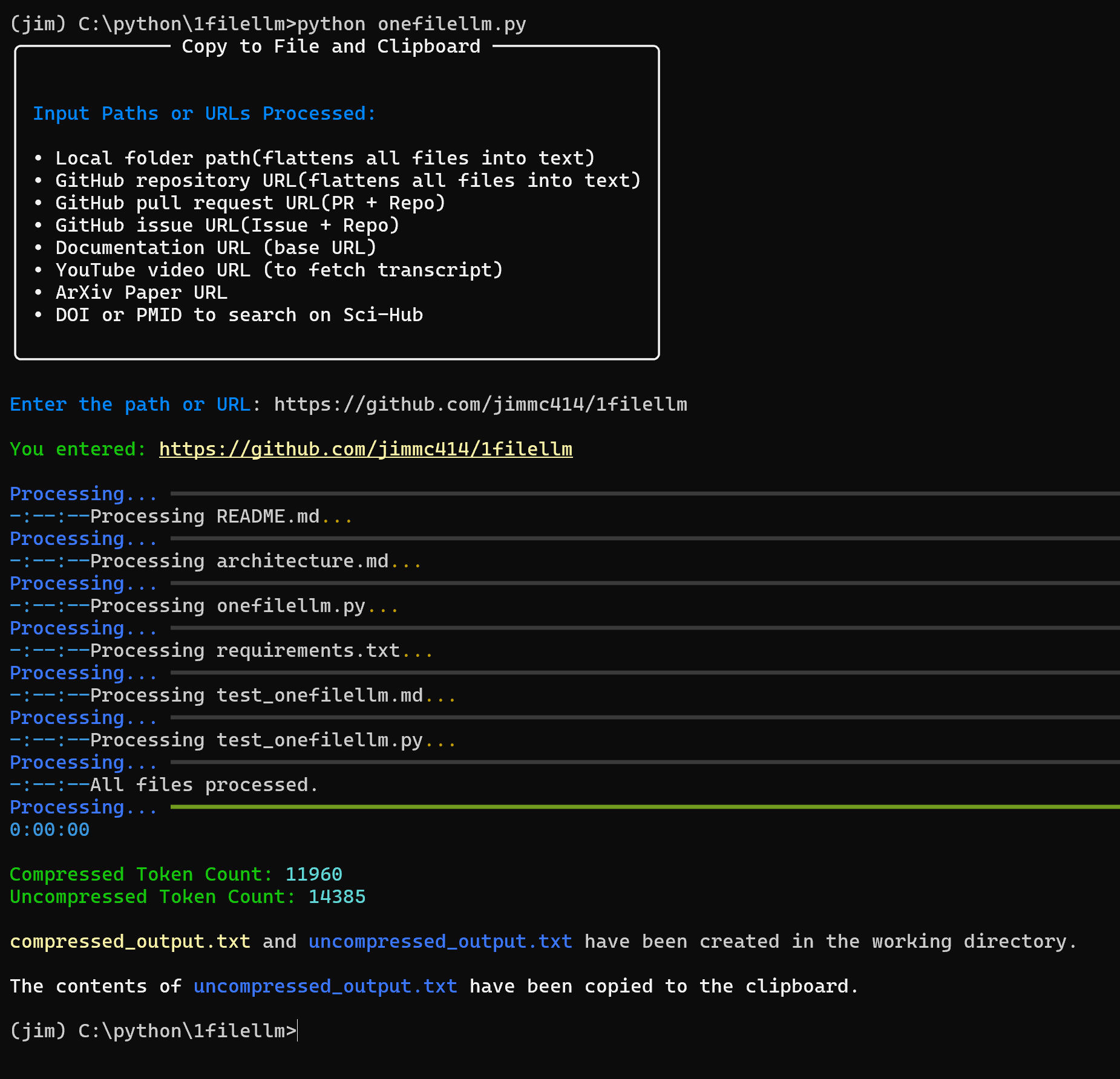
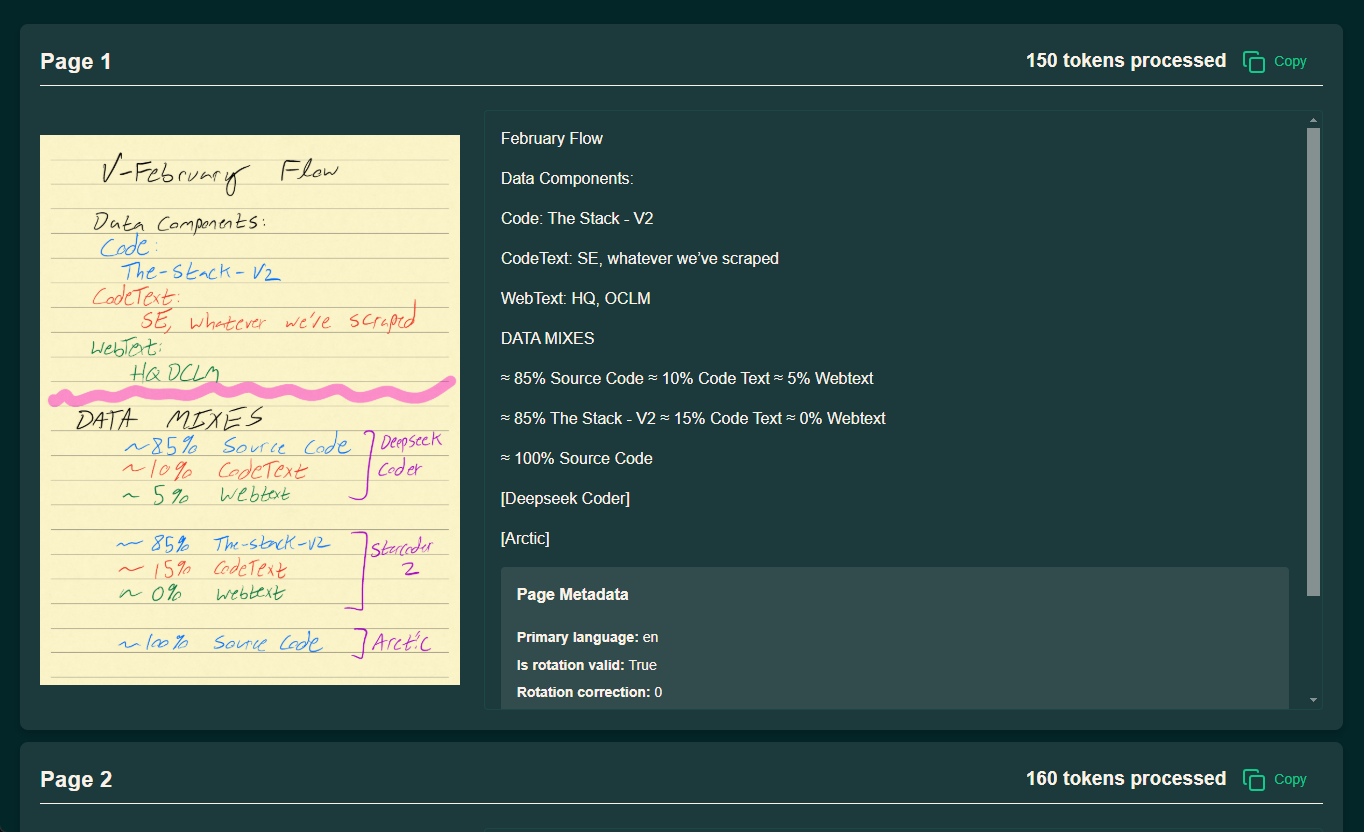
OneFileLLM: 複数のデータソースを単一のテキストファイルに統合包括的な紹介 OneFileLLMは、大規模言語モデル(LLM)に簡単に入力できるように、複数のデータソースを単一のテキストファイルに統合するために設計されたオープンソースのコマンドラインツールです。GitHubリポジトリ、ArXiv論文、YouTube動画トランスクリプション、Web...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング11ヶ月前052.9K
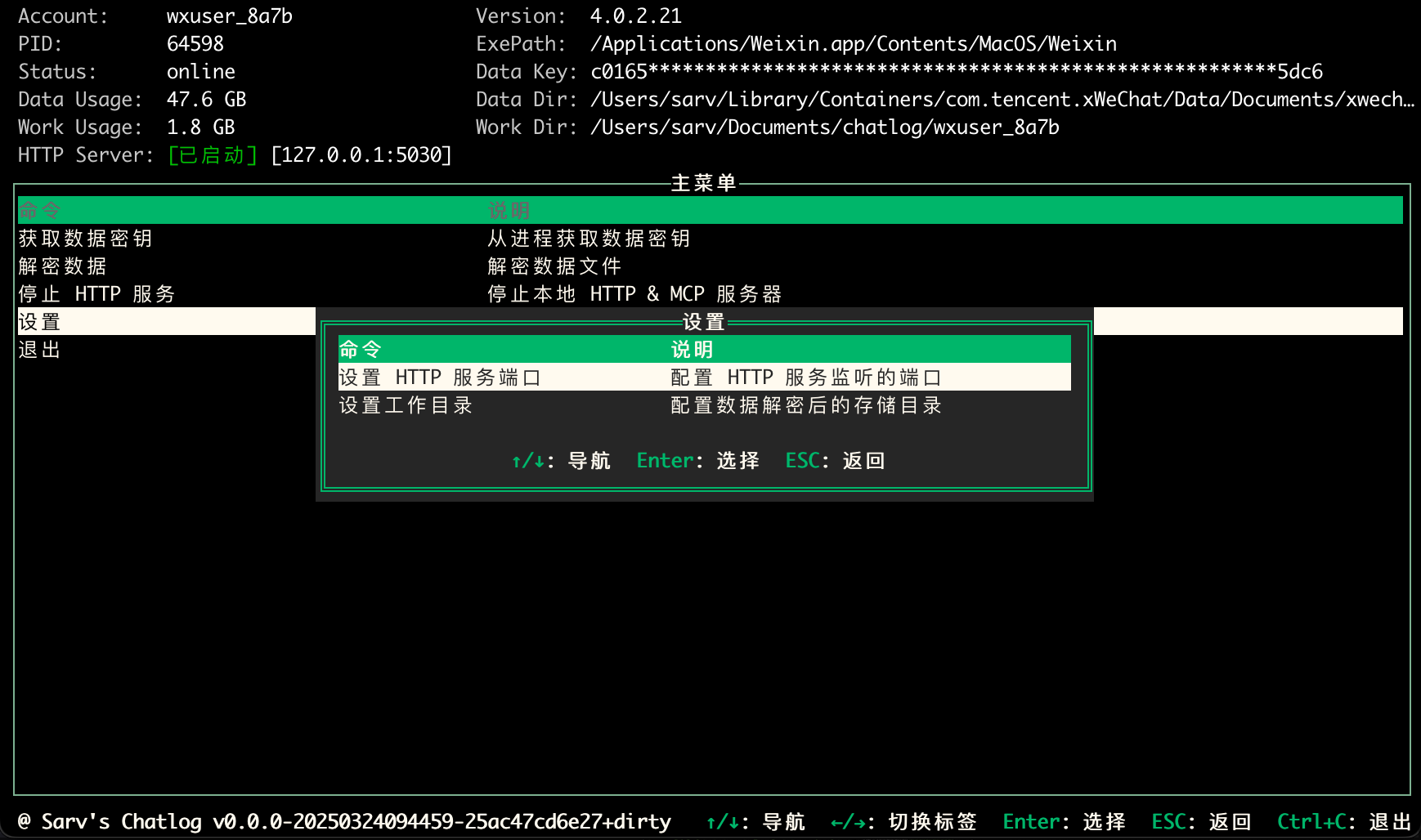
Chatlog: WeChatのチャットログを抽出・照会するオープンソースツール一般的な紹介 チャットログはWeChatのローカルデータベースからチャットログを抽出し、照会することに特化したオープンソースツールです。WeChatバージョン3.xと4.0をサポートし、WindowsとmacOSの両システムをカバーしています。ユーザーは、コマンドライン、ターミナルインターフェース、またはH...最新のAIリソース# AI Java オープンソースプロジェクト# MCPサービス# ドキュメントの抽出とクリーニング12ヶ月前0125.7K
VOP: 複雑な図や数式を抽出するOCRツール包括的な紹介 Versatile OCR Programは、複雑な学術文書や教育文書を扱うために設計されたオープンソースの光学式文字認識(OCR)ツールです。PDF、画像、その他の文書からテキスト、表、数式、図、回路図を抽出し、OCRファイルを生成することができます。最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング12ヶ月前050.1K
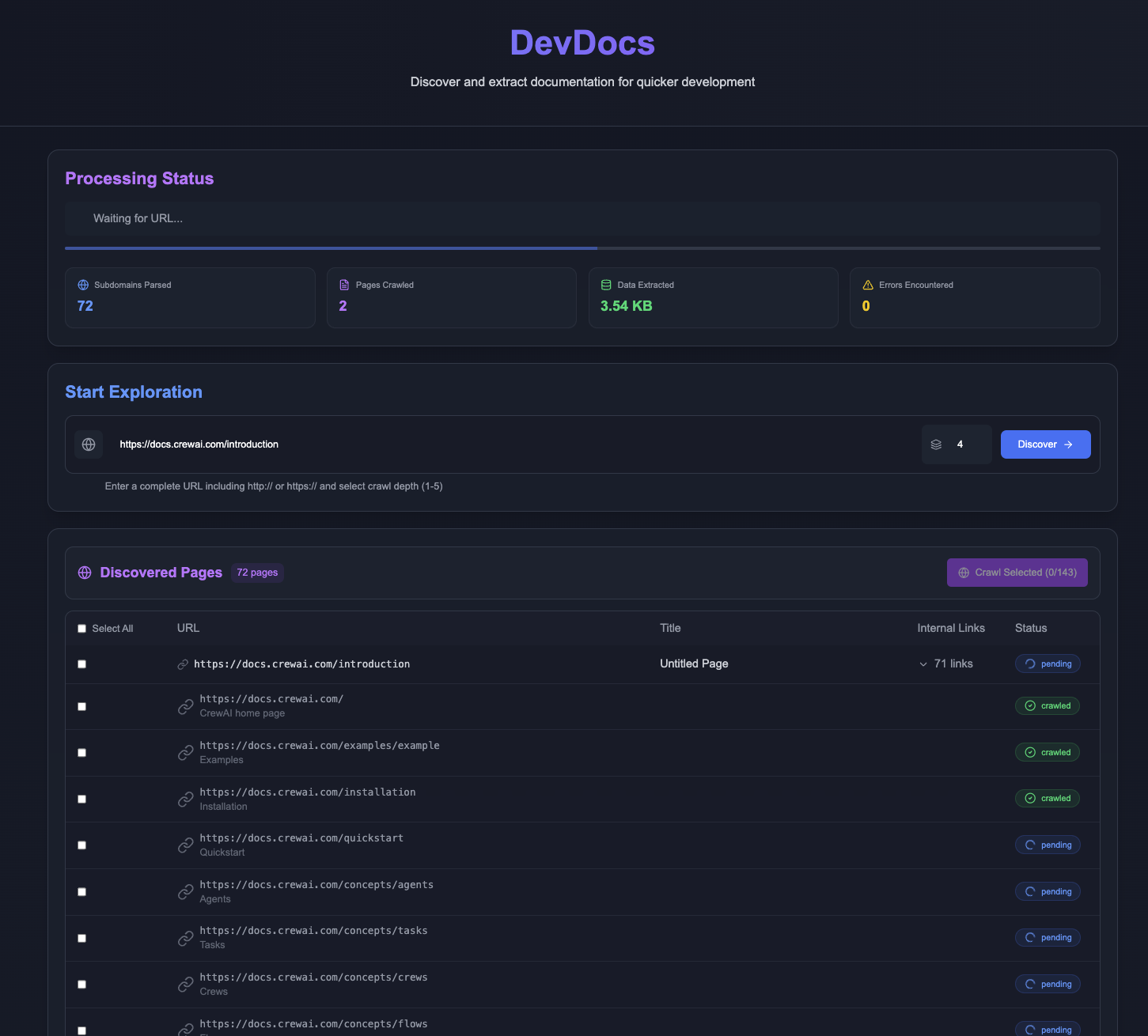
DevDocs:技術文書を素早くクロールして整理するMCPサービス概要 DevDocsは、CyberAGIチームによって開発され、GitHubでホストされている完全に無料のオープンソースツールです。プログラマーやソフトウェア開発者のために設計されたこのツールは、技術文書のURLから始まり、関連するページを自動的にクロールし、簡潔なMa...最新のAIリソース# AI Java オープンソースプロジェクト# MCPサービス# ドキュメントの抽出とクリーニング12ヶ月前055.5K
PDFコンテンツを自動的に解析し、オープンソースサービスのテキストとテーブルを抽出します。総合紹介 PDF文書のレイアウトを自動的に分析し、ページ内のテキスト、タイトル、画像、表、数式、その他の要素を識別し、それらの正しい順序を決定します。このツールはOCR機能をサポートしており、スキャンしたPDFを検索可能なテキストに変換することができます。Docker上で動作し、2つのモデルを提供します。最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング12ヶ月前056.8K
Workers AIに基づいて、無料で複数のファイルをMarkdown形式に変換する概要 serverless-markdown-convertorは、Cloudflare WorkerとWorkers AIをベースとしたフリーでオープンソースのツールで、様々なファイルをMarkdow...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前054K
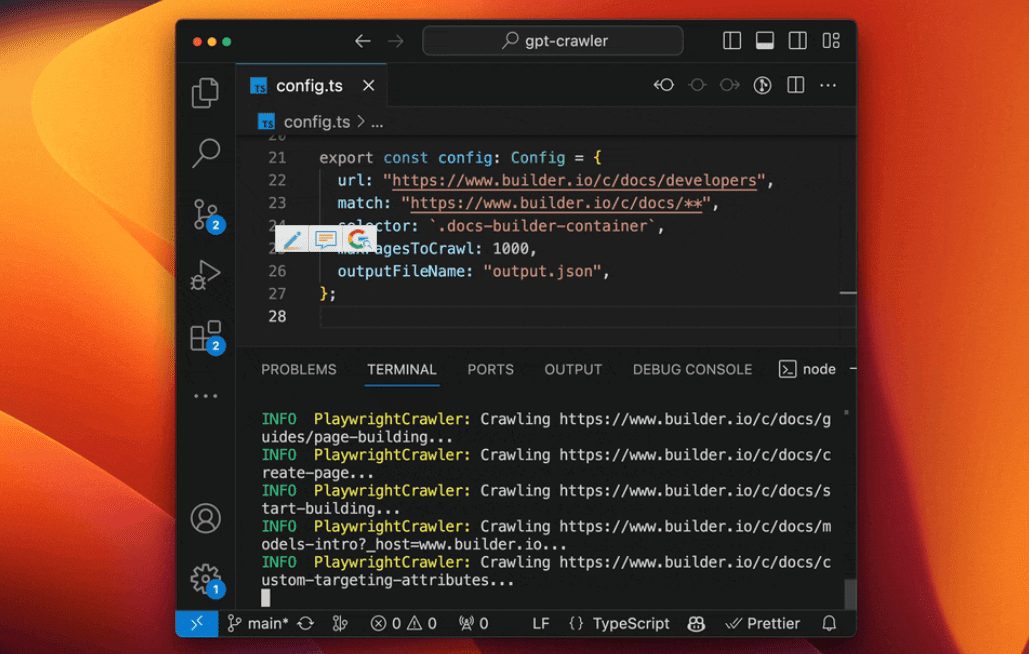
GPT-Crawler: ウェブサイトコンテンツを自動的にクロールして知識ベースドキュメントを生成一般的な紹介 GPT-Crawlerは、BuilderIOチームによって開発され、GitHubでホストされているオープンソースツールです。1つ以上のウェブサイトのURLを入力することでページのコンテンツをクロールし、構造化ナレッジファイル(output.jso...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング10ヶ月前056K
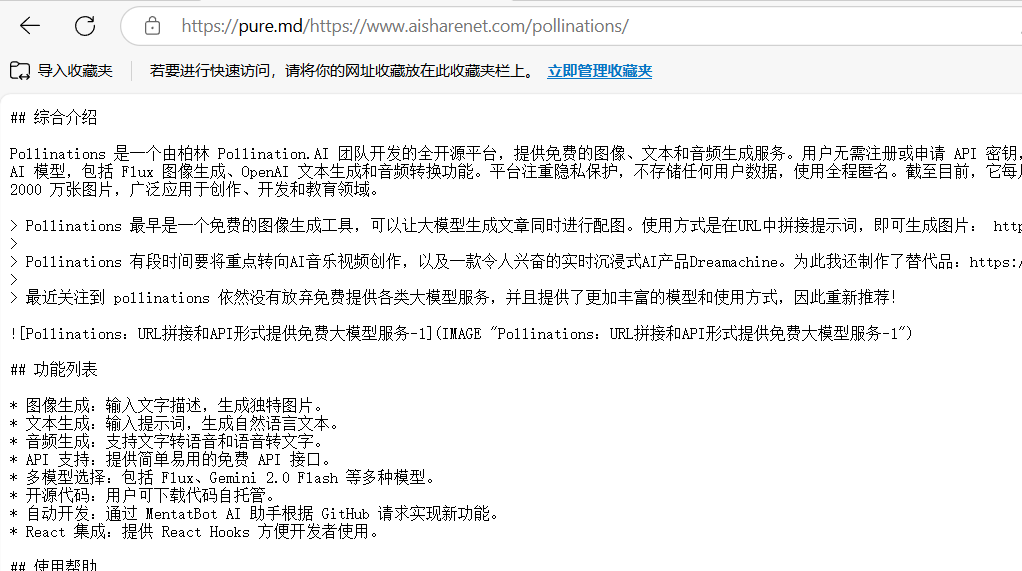
pure.md:URLの前に "pure.md/"を挿入して、きれいなテキストを取り出す。一般的な紹介 pure.mdはAIエージェントや開発者のためのツールで、ウェブコンテンツやファイルを素早くMarkdown形式に変換することに重点を置いています。プロキシサービスによるクローラー対策の制限を回避し、ウェブページのコアデータを抽出し、クリーンなMarkdownを出力します。最新のAIリソース# AIオープンサービス# ドキュメントの抽出とクリーニング1年前061K
Cloudsquid: ドキュメントをアップロードし、構造化データのインテリジェントな抽出のための要件を記述する。概要 Cloudsquidは2023年にドイツのベルリンで設立された企業で、人工知能による文書処理の簡素化に注力している。主力製品はオンラインデータ抽出プラットフォームで、ユーザーはPDF、画像、音声、動画などのドキュメントをアップロードし、抽出が必要であることを伝えるだけで、...最新のAIリソース# ドキュメントの抽出とクリーニング1年前053.6K
PDF Craft: PDFスキャン文書からMarkdownへのオープンソースツール一般的な紹介 PDF Craftは、書籍のPDFをスキャンしてMarkdown形式に変換するために設計されたオープンソースツールです。このツールはoomol-labによって開発され、電子書籍を整理したいユーザのためにGitHubでホストされています。このツールは、以下の方法で動作します。最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング1年前077.7K
Supametas.AI:非構造化データをLLMの高可用性データに抽出する包括的な紹介 Supametas.AIは、ウェブページ、文書、音声、動画などの乱雑なデータを、AIが利用できる構造化データに整理することに特化したデータ処理プラットフォームです。ウェブリンク、API、ローカルファイルなど複数のソースからデータを収集し、JSONとして出力することができます。最新のAIリソース# AIオープンサービス# ドキュメントの抽出とクリーニング1年前053.7K
MarkPDFDown: マルチモーダルモデルに基づくPDFからMarkdownへの変換概要 MarkPDFDownはオープンソースのツールです。Multimodal Big Language Modelを使ってPDFファイルをMarkdown形式に変換します。開発者はGitHubユーザーのjorbenです。このツールの目的はシンプルです:PDFドキュメントを...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前059.2K
SmolDocling:少量で効率的な文書処理のための視覚言語モデル包括的な紹介 SmolDoclingは、ds4sdチームがIBMと共同で開発したビジュアル言語モデル(VLM)で、SmolVLM-256Mをベースに構築され、Hugging Faceプラットフォームでホストされています。サイズは小さく、わずか ...最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング1年前051K
フライング・パドル PP-TableMagic: 複雑なテーブルの構造化情報抽出表認識の目的は、画像中の表を解析し、表の構造やセルの位置を正確に特定し、構造化された表形式(HTMLなど)に変換することである。今日の情報化時代において、大量の重要な表データがまだ構造化されていない状態で存在している(例えば、統計表の写真をスキャンした文書など)。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前064.4K
ミストラルOCR:94.89%総合精度、1000ページ/30秒、わずか1ドル人類の文明の長い歴史の中で、情報の取得と解析の方法が飛躍的に進歩するたびに、社会の進歩に大きく貢献してきた。古代の象形文字から、持ち運び可能なパピルス、その後の印刷機の出現、そして今日のデジタルの波に至るまで、技術革新のたびに人類の知識普及のパラダイムは大きく広がってきた。最新のAIリソース# AIオープンサービス# OCR# ドキュメントの抽出とクリーニング1年前058.7K
Firecrawl MCPサーバー: FirecrawlベースのWebクローラーMCPサービス概要 Firecrawl MCP Serverは、MendableAIによって開発されたオープンソースツールで、モデルコンテキストプロトコル(MCP)プロトコルの実装に基づき、Firecrawl A...最新のAIリソース# AI Java オープンソースプロジェクト# MCPサービス# ドキュメントの抽出とクリーニング1年前070.3K
olmOCR: PDF 文書のテキスト変換、表、数式、手書き内容の認識のサポート概論 olmOCRは、アレン人工知能研究所(AI2)のAllenNLPチームによって開発されたオープンソースツールで、PDFファイルの変換に重点を置いています...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前066.5K
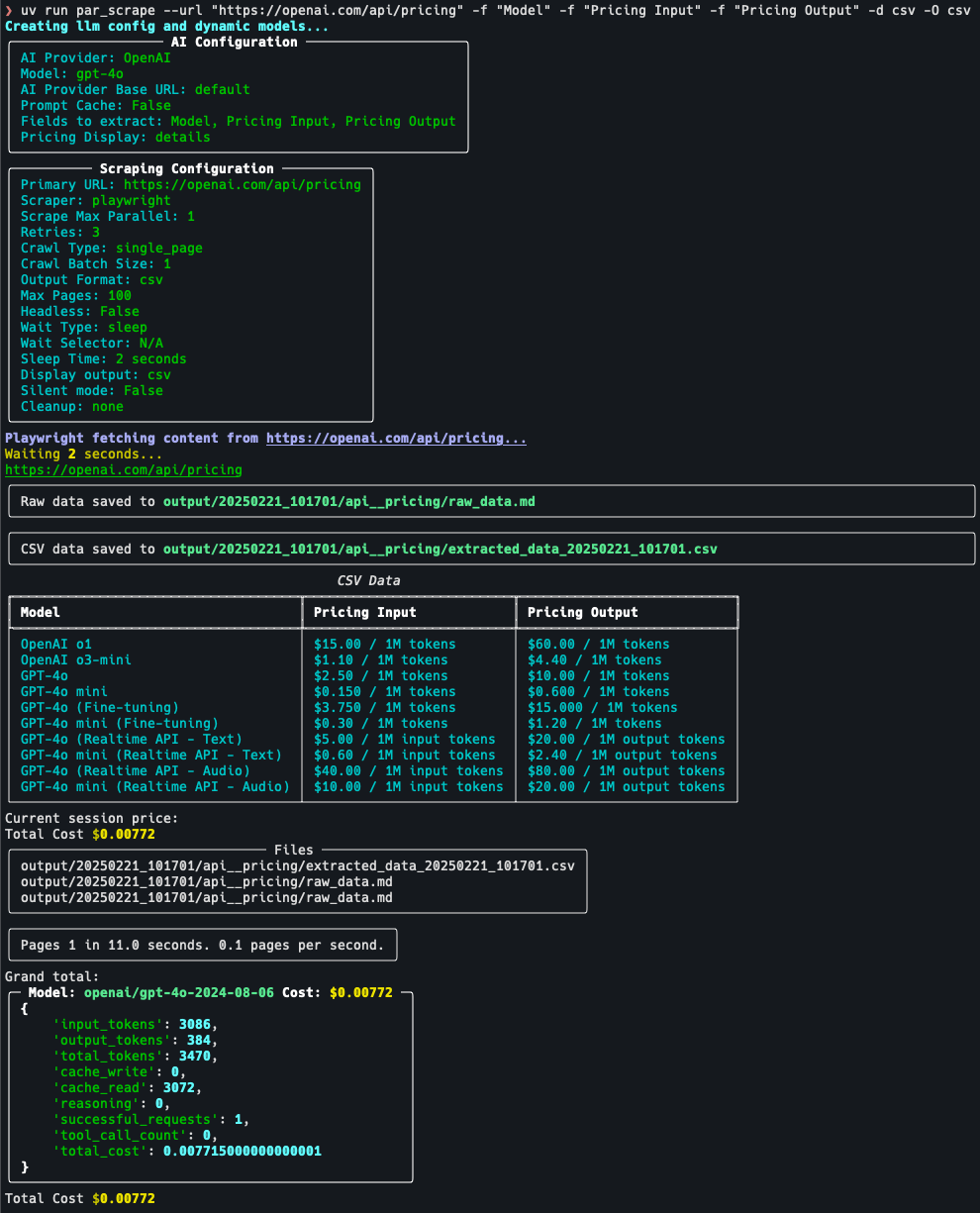
par_scrape: ウェブデータをインテリジェントに抽出するクローラーツール一般的な紹介 par_scrape は Python ベースのオープンソース Web クローラーツールで、開発者の Paul Robello によって GitHub で公開されています。Selenium...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前052.8K
PDF-Extract-Kit:オープンソースツールのPDFコンテンツの複雑な構造を抽出する包括的な紹介 PDF-Extract-KitはOpenDataLabチームによって開発されたオープンソースプロジェクトで、複雑で多様なPDF文書から高品質なコンテンツを効率的に抽出することに重点を置いています。先進的な文書解析技術を統合し、レイアウト検出、数式認識、PDF文書抽出をサポートします。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前0101.9K
Crawl4LLM:LLM事前学習のための効率的なウェブクローリングツール包括的な紹介 Crawl4LLMは清華大学とカーネギーメロン大学によって共同開発されたオープンソースプロジェクトであり、大規模モデル(LLM)の事前学習のためのウェブクローリングの効率最適化に焦点を当てている。高品質なウェブページデータをインテリジェントに選択することで、非効率なクロールを大幅に削減し、本来1...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前055.1K
Markdownify MCP Server: MCPプロトコルに基づき、様々なコンテンツをMarkdownフォーマットに変換します。一般的な紹介 Markdownify MCPサーバーはモデルコンテキストプロトコルに基づいたオープンソースツールで、開発者のZach CaceresによってGitHubでホストされています ...最新のAIリソース# AI Java オープンソースプロジェクト# MCPサービス# ドキュメントの抽出とクリーニング1年前063.4K
CodeWeaver: コード構造とコンテンツから自動的にMarkdownドキュメントを生成します。一般的な紹介 CodeWeaverは、コード・ライブラリを単一の見やすいMarkdownドキュメントに編むために設計されたコマンドライン・ツールです。ディレクトリを再帰的にスキャンし、各ファイルの内容をコードブロックに埋め込むことで、プロジェクトのファイル階層を構造化した表現を生成します。このツールは...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前056.9K
Kreuzberg: あらゆる文書からテキストを抽出するオープンソースツール一般的な紹介 Kreuzbergは、PDFファイルからのテキスト抽出を簡素化するためのライブラリで、シンプルで手間のかからないテキスト抽出ソリューションを提供するように設計されています。このライブラリは、特にRAG(Retrieval-Augmented Generatio...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前059.3K
講師:大規模言語モデルの構造化出力ワークフローを簡素化するPythonライブラリ概要 Instructorは、大規模言語モデル(LLM)からの構造化出力を処理するために設計された人気のあるPythonライブラリです。Pydanticをベースに構築されており、データを管理するためのシンプルで透過的、かつユーザーフレンドリーなAPIを提供します。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前053.4K
zChunk: Llama-70Bに基づく一般的な意味的チャンキング戦略包括的な紹介 zChunkは、ZeroEntropyによって開発された、一般的なセマンティック・チャンキングのソリューションを提供する新しいチャンキング戦略です。このストラテジーはLlama-70Bモデルに基づいており、チャンクの生成を促すことでドキュメントのチャンキングプロセスを最適化し、情報検索を高いレベルで維持することを保証します。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前048.7K
パルス:文書処理とデータ抽出のためのビジネスソリューションPulseは、文書処理とデータ抽出に特化したインテリジェントなプラットフォームで、企業や開発者がさまざまな複雑な文書を効率的に解析・処理できるように設計されています。高度なコンピュータビジョンとマルチモーダル処理技術により、Pulse はテキスト、画像、表、その他多くのデータから正確にデータを抽出することができます。最新のAIリソース# ドキュメントの抽出とクリーニング1年前051.7K
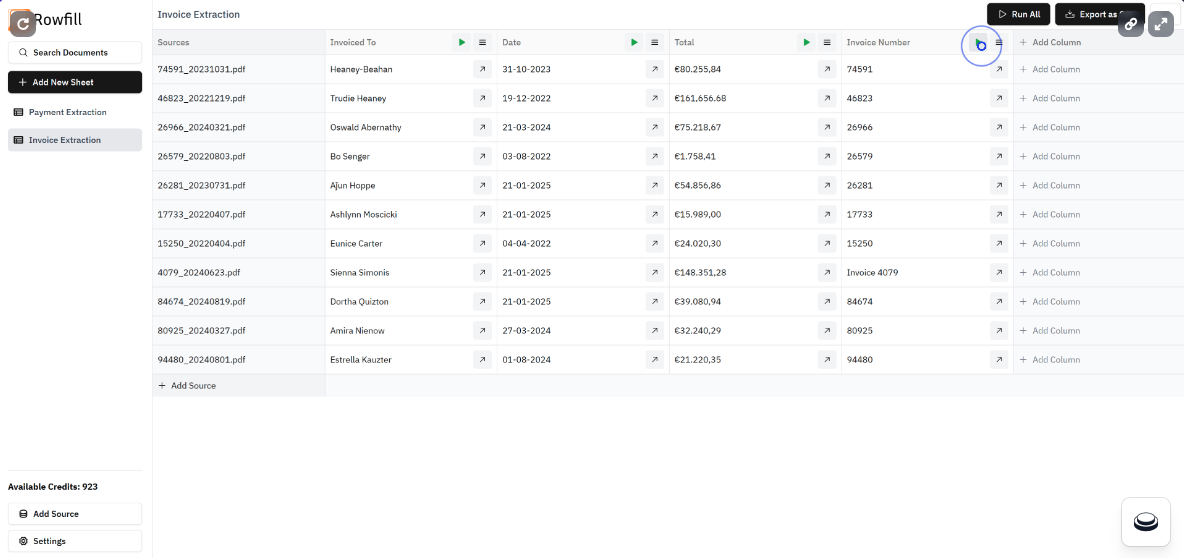
ロウフィル:文書からの構造化情報の一括抽出と自動分析概要 Rowfillは、ナレッジワーカーのために設計されたオープンソースの文書処理プラットフォームです。高度な人工知能技術を使用して、複雑な文書、画像、PDFからデータを抽出、分析、処理します。Rowfillは、Large Language Model(LLM)とOpe...最新のAIリソース# AI Java オープンソースプロジェクト# AIデータ分析# ドキュメントの抽出とクリーニング1年前051.7K
PPTX2MD: PPTXファイルをMarkdownに変換する特別なツール概要 PPTX2MDは、PowerPointのPPTXファイルをMarkdown形式に変換するために設計されたオープンソースツールです。GitHubユーザーのssine氏によって開発されたこのツールは、見出し、リスト、テキストフォーマット(例:太字、斜体、色、スーパー...)を保持することをサポートしています。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前073.5K
Repomix:大規模モデル検索用にコードベースをテキストファイルにパッケージ化概論 Repomix(以前はRepopackとして知られていた)は、コードベース全体を単一のAIフレンドリーなファイルにパッケージ化するために設計されたオープンソースツールです。このツールにより、開発者は自分のコードベースを大規模な言語モデル(ClaudeやChat...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前086.3K
Yek: git リポジトリのテキストファイルを読み込んで、大規模なモデルのために素早くチャンキングする。一般的な紹介 Yekは、リポジトリやディレクトリからテキストファイルを読み込んでチャンキングし、大規模言語モデル(LLM)で使用するためにシリアライズするRustベースの高速ツールです。このツールはデフォルトで .gitignore ルールを使って不要なファイルをスキップし、...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前056.2K
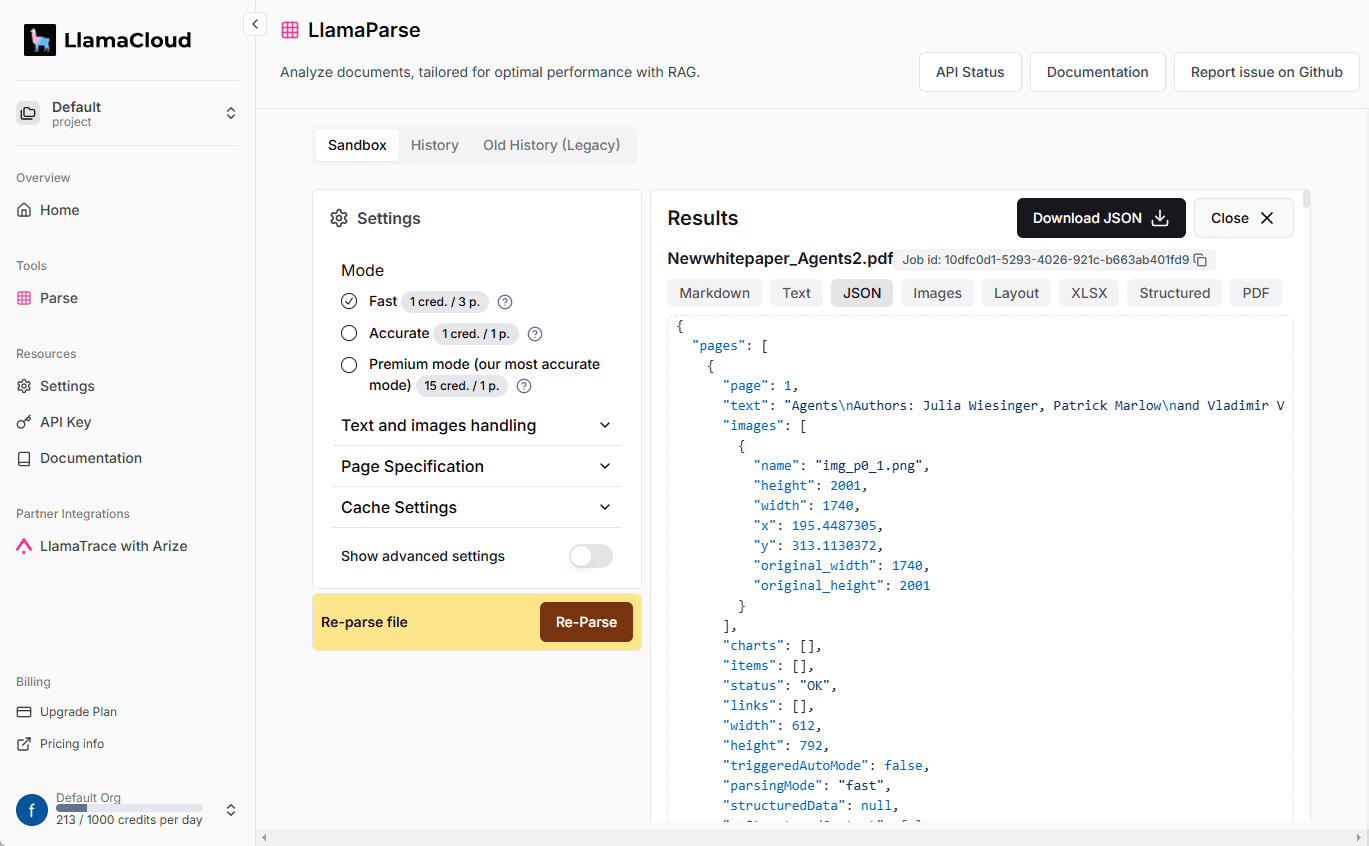
LlamaParse: Llamaindexによる高品質な文書解析とデータ抽出サービス(1日1000ページ無料)。包括的な紹介 LlamaParseは、PDF、PowerPoint、Word文書、スプレッドシートなどの複雑な文書を処理し、構造化データに変換できる強力な文書解析ツールです。最新のAIリソース# AIオープンサービス# ドキュメントの抽出とクリーニング1年前065.7K
UnDatas.IO: さまざまな種類の非構造化データを正確に解析するAPIサービス(有料)包括的な紹介 UnDatas.IOは、非構造化データの解析と処理に特化したプラットフォームです。高度な技術を駆使して、ドキュメントのレイアウトを自動的に認識し、表、画像、数式、テキストを分類して、データ処理プロセスを大幅に簡素化します。このプラットフォームは、データの並べ替えにかかる時間を大幅に節約するだけでなく...最新のAIリソース# AIオープンサービス# ドキュメントの抽出とクリーニング1年前051.2K
Zerox: PDF、DOCX、Markdownへの画像変換、ビジュアルモデル高精度OCR一般的な紹介 Zeroxは、ビジュアルモデルを通してPDF、DOCX、画像やその他のドキュメントをMarkdown形式に変換するために設計されたオープンソースプロジェクトです。このプロジェクトはgetomni-aiチームによって開発され、シンプルで効率的なOCR(光学式文字認識)ソリューションを提供します。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前074K
SemHash: データクリーニング効率を向上させるセマンティックテキスト重複排除の高速実装包括的な紹介 SemHashは、意味的類似性によってデータセットの重複を除去するための軽量で柔軟なツールです。Model2Vecの高速な埋め込み生成と、Vicinityの効率的なANN(近似最近傍)類似検索を組み合わせています。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前067.9K
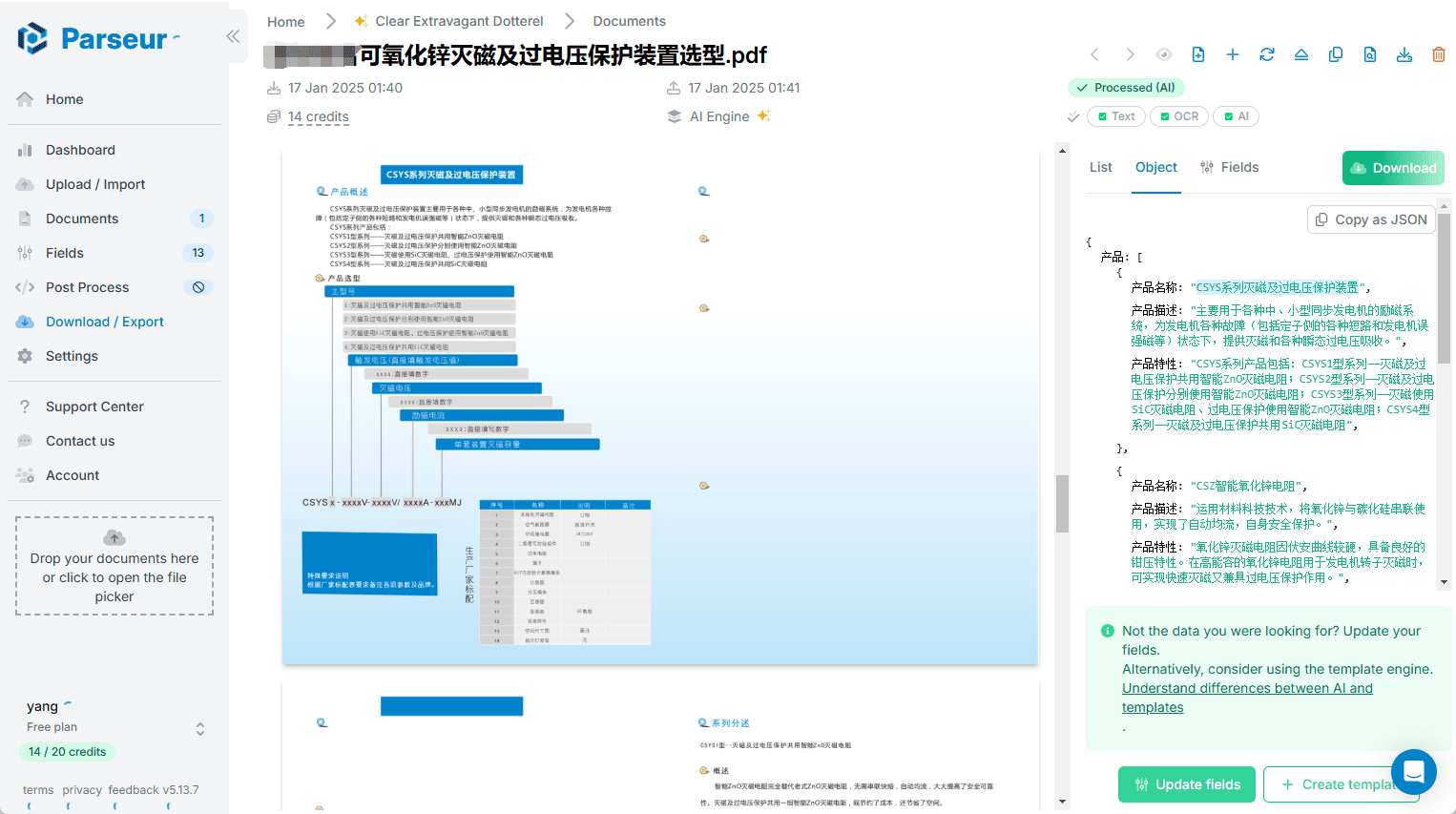
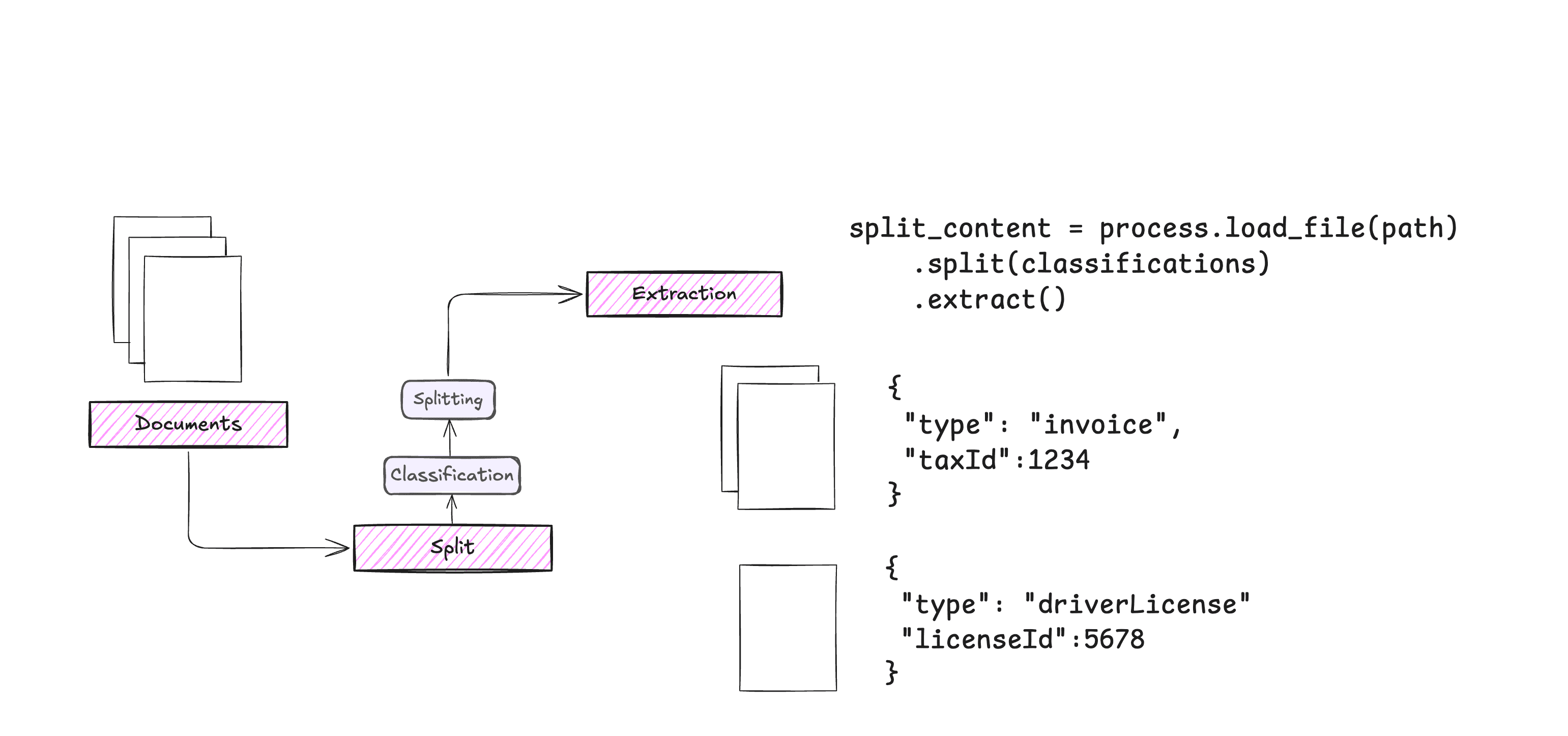
Parseur: 文書データの自動抽出、様々な文書からの構造化テキスト抽出概要 Parseurは、PDF、電子メール、その他のドキュメントからテキストデータを自動的に抽出するために設計された、業界をリードするAIデータ抽出ソフトウェアです。Parseurを使用すると、ユーザーは簡単に非構造化データを構造化データに変換し、様々なアプリケーションに送信することができます...最新のAIリソース# ドキュメントの抽出とクリーニング1年前058.1K
AIファンクション:入力コンテンツを構造化された出力に変換する(API)サービス包括的な紹介 Weco AI Functionsは、ユーザーが迅速にAIファンクションを構築し、展開できるように設計された強力なプラットフォームです。タスクを記述するだけで、ユーザーはA/Bテストや観察モニタリングで構造化された出力パターンを生成できます。このプラットフォームは、ノーコードのプロトタイピングをサポートします。最新のAIリソース# AIオープンサービス# ドキュメントの抽出とクリーニング1年前049.4K
NVインジェスト:複雑なフォーマットのドキュメントを解析し、マルチモーダルデータをメタデータとテキストに抽出する。包括的な紹介 NV Ingest (NVIDIA Ingest)は、何十万もの複雑で厄介な非構造化PDFやその他の企業ドキュメントを解析するために設計された、早期アクセス可能なマイクロサービス群です。これらのドキュメントをメタデータとテキストに変換し、検索に埋め込むことができます...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前062.5K
Trellis: 構造化されていないドキュメントを構造化されたEXCEL形式のデータ、PDFに高速変換(有料)概要 Trellisは、複雑な非構造化データソースを構造化されたSQL形式に変換することに特化したデータプラットフォームです。Trellisは、その強力なAIエンジンを通じて、財務文書、音声通話、電子メールなどの幅広いデータソースを処理し、使用可能なデータに変換することができます。最新のAIリソース# ドキュメントの抽出とクリーニング1年前048.7K
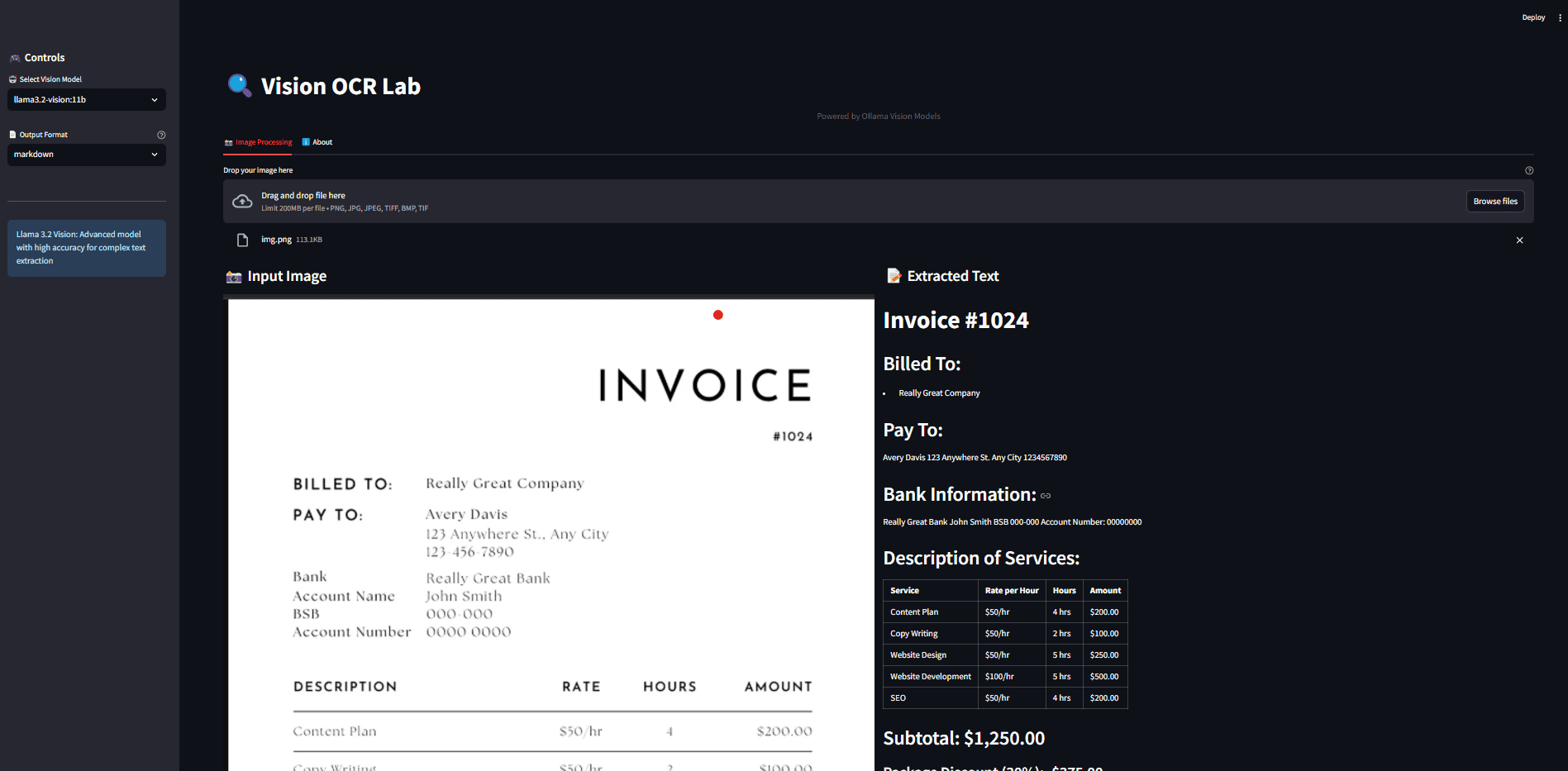
Ollama OCR: Ollamaの視覚モデルを使った画像からのテキスト抽出包括的な紹介 Ollama OCRは、Ollamaプラットフォームが提供する最先端の視覚言語モデルを使用して画像からテキストを抽出する、強力な光学式文字認識(OCR)ツールキットです。このプロジェクトはPythonパッケージとして提供されており、ユーザーフレンドリーなストリー...最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング1年前0101.7K
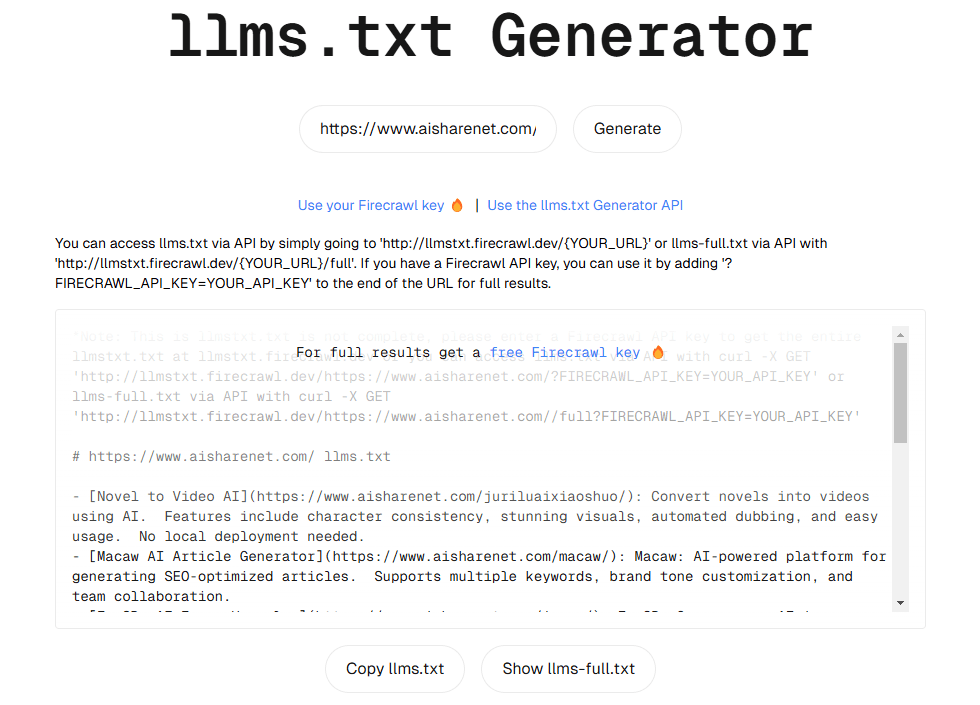
llms.txt Generator: Webサイトのコンテンツを素早くキャプチャし、LLMトレーニング用テキストデータセットを生成します。包括的な紹介 llmstxt-generatorは、大規模言語モデリング(LLM)の訓練と推論のための高品質のテキストデータセットを準備するための専門的なウェブコンテンツ抽出と統合ツールです。このツールはMendable AIによって開発され、@firec...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前052.4K
Doc2X:文書画像式認識・変換ツール、マルチフォーマット変換と高精度翻訳をサポート包括的な紹介 Doc2Xは、強力な文書画像式認識と変換ツールで、効率的でインテリジェントな文書処理ソリューションを提供することを約束します。学術研究論文、教科書、企業文書、財務報告書など、Doc2XはPDFの表と数式を正確に認識することができます。最新のAIリソース# AIオープンサービス# AI翻訳# ドキュメントの抽出とクリーニング1年前085.1K
ExtractThinker: ドキュメントを構造化データに抽出・分類し、ドキュメント処理プロセスを最適化します。包括的な紹介 ExtractThinkerは、大規模言語モデル(LLM)を使用してドキュメントから構造化データを抽出・分類し、シームレスなORMライクなドキュメント処理ワークフローを提供する、柔軟なドキュメントインテリジェンスツールです。LLMを含む様々なドキュメントローダーをサポートしています。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前058.4K
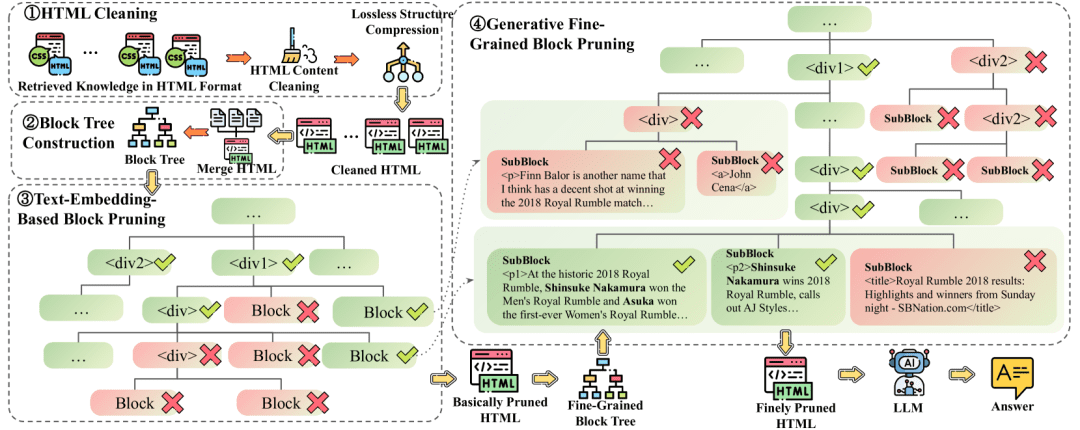
HtmlRAG:効率的なHTML検索拡張生成システムの構築、RAGシステムにおけるHTML文書の検索と処理の最適化包括的な紹介 HtmlRAGは、RAG(Retrieval Augmented Generation)システムにおけるHTML文書の処理を改善することに焦点を当てた、革新的なオープンソースプロジェクトである。このプロジェクトは、RAGシステムでHTMLフォーマットを使用することが、プレーンテキストよりも効率的であると主張する新しいアプローチを提示する。このプロジェクトには、完全な...最新のAIリソース# ドキュメントの抽出とクリーニング# 知識検索とRAGフレームワーク1年前054.7K
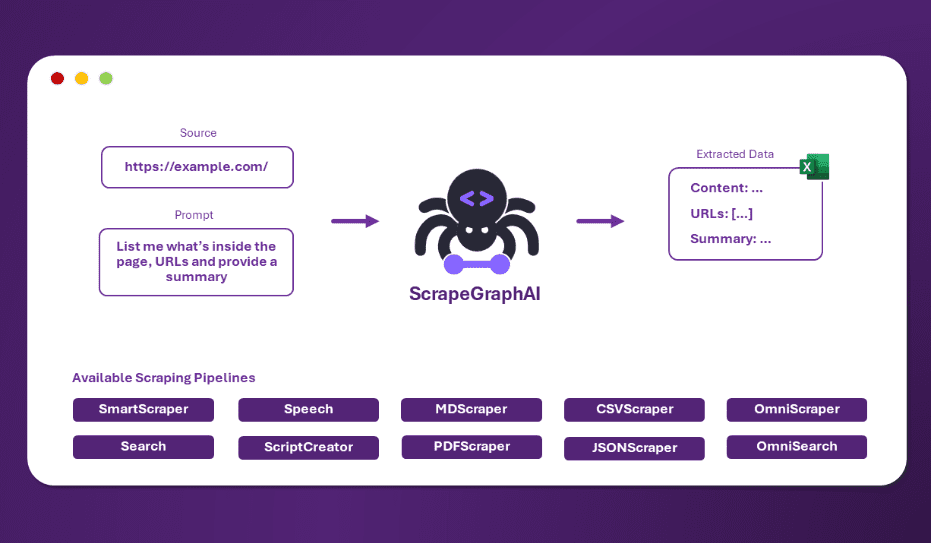
ScrapeGraphAI:ウェブクローリングのための単一のキューワード、ルールを書く必要のないインテリジェントなウェブコンテンツ抽出ツール包括的な紹介 ScrapeGraphAIは革新的なPythonのWebスクレイピングライブラリで、Large Language Modelling (LLM)とDirect Graph Logicを巧みに組み合わせ、Webサイトやローカルドキュメントのスクレイピングパイプラインを作成します。このツールのユニークな点は、完璧なレベルのシンプルさとパワーです。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前056K
Vision Parse: 視覚言語モデルを用いたPDFドキュメントのMarkdownフォーマットへのインテリジェント変換包括的な紹介 Vision Parseは画期的な文書処理ツールで、最先端の視覚言語モデル(Vision Language Models)技術と、PDF文書を高品質のMarkdown形式にインテリジェントに変換する機能を巧みに組み合わせています...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前054.7K
アウトライン: 正規表現、JSON、Pydanticモデルによる構造化テキスト出力の生成概説 Outlinesは、構造化テキスト生成を通じて大規模言語モデル(LLM)のアプリケーションを強化するために、dottxt-aiによって開発されたオープンソースライブラリです。このライブラリは、OpenAIやトランスフォーマーなど、様々なモデルの統合をサポートしています。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前081.6K
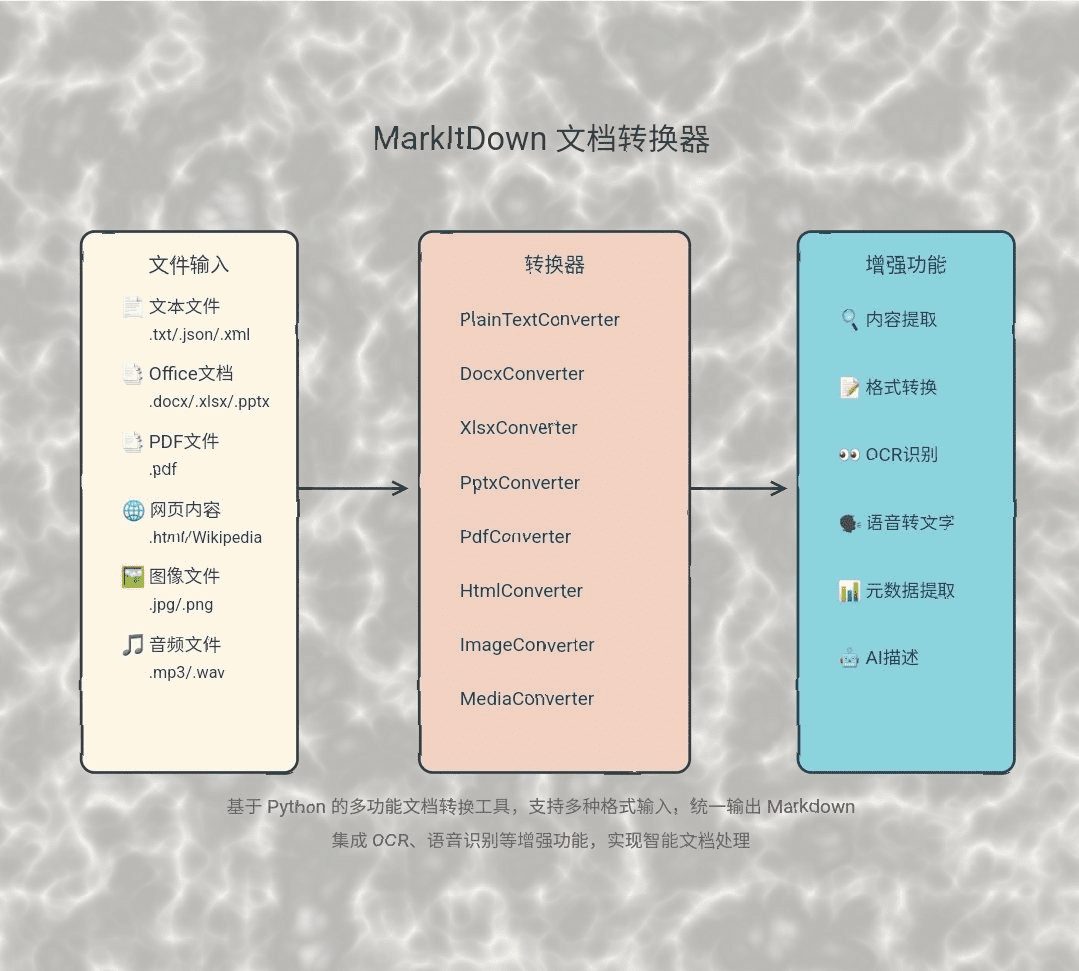
MarkItDown:Microsoftドキュメントインテリジェント変換ツール、様々なファイルをMarkdown形式に変換一般的な紹介 MarkItDownはMicrosoftによって開発されたPythonツールで、様々なファイルやオフィス文書をMarkdown形式に変換するように設計されています。このツールは、PDF、PowerPoint、Word、Excel、ダイアグラム...など、幅広い種類のファイルをサポートしています。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前061.4K
Chunkr: 文書の取り込みにビジュアルモデルを使用し、テキストの段落階層に基づくインテリジェントなチャンキングを行うオールインワンサービス。概要 Chunkrは、PDF、PPTX、DOCX、ExcelファイルをRAG(Retrieval Augmented Generation)やLLM(Large Language Modelling)で使用するのに適したデータに変換するためのセルフホストAPIです。このプロジェクトはLumina...によって開発されました。最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング1年前052.8K
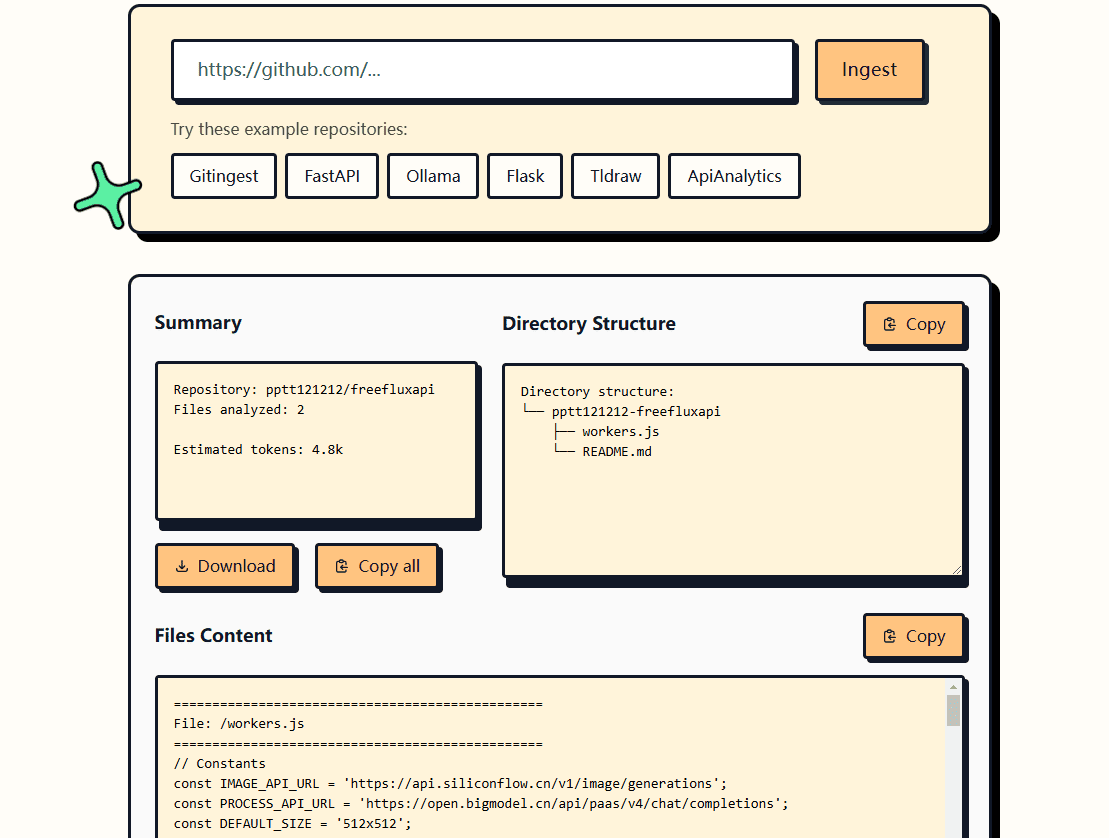
GitIngest: GithubのコードリポジトリをLLMの理解に適したテキストに素早く変換概要 GitIngestは、GitHubのコードリポジトリをLarge Language Model (LLM)のヒントに適したテキストに変換するためのオープンソースツールです。簡単な操作で、あらゆるGitHubリポジトリの内容を抽出し、LLMヒントに適合するように整形することができます。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前078.4K
E2M: 複数のファイル形式をMarkdownに変換し、簡単に統一されたドキュメントフォーマットを実現する概要 E2M (Everything to Markdown)は、様々なファイルフォーマットをMarkdownフォーマットに変換するために設計されたオープンソースのPythonライブラリです。このツールは、doc、docx、epub、html、htm、u...などのフォーマットをサポートしています。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前059.2K
Docling:様々なフォーマットのドキュメントをサポート MarkdownやJSONへの解析とエクスポート PDFサポート OCR包括的な紹介 Doclingは、PDF、DOCX、PPTX、XLSX、画像、HTML、AsciiDocおよびMarkdownを含む幅広い文書形式をサポートする強力な文書解析およびエクスポートツールです。最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング1年前0103.9K
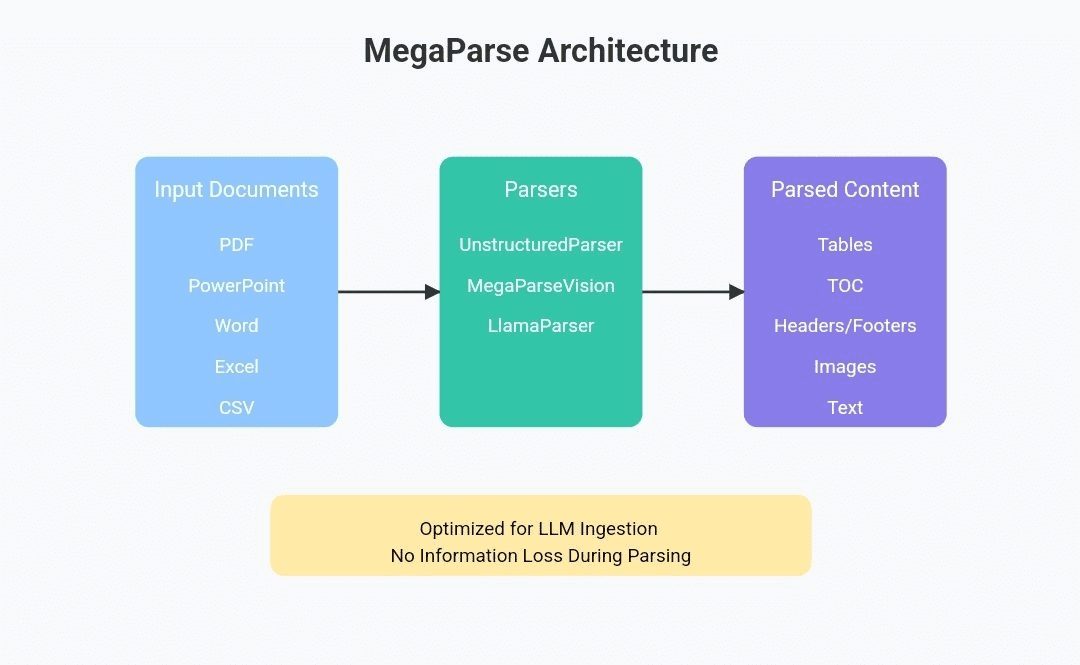
MegaParse:各タイプのドキュメントをLLMで利用可能なデータに解析し、表や写真などドキュメント内のすべての情報をそのまま保存する。概論 MegaParseは、Large Language Model (LLM)のデータ処理を最適化するために設計された、パワフルで多機能な文書解析ツールです。MegaParseは、テキスト、PDF、PowerPointプレゼンテーション、Word文書など、どのような文書を扱う場合でも...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前061K
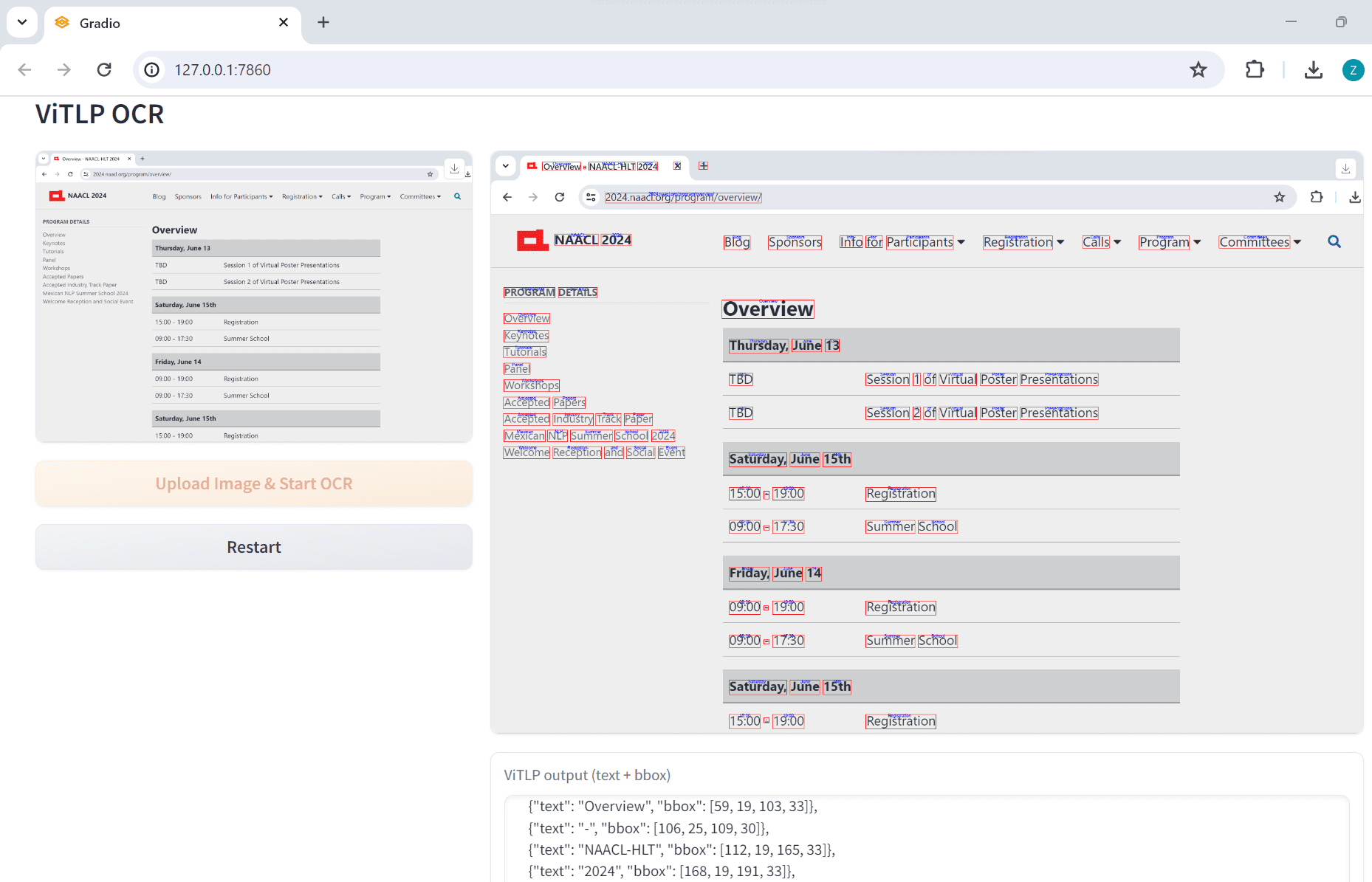
ViTLP: 組版が複雑なPDF文書から構造化データを抽出し、テキストレイアウトのための事前学習済みモデルを視覚的に誘導して生成する包括的な紹介 ViTLP(Visually Guided Generative Text-Layout Pre-training for Document Intelligence)は、ドキュメント・インテリジェンスのための視覚的ガイド付き生成テキストレイアウト事前学習(Visually Guided Generative Text-Layout Pre-training for Document Intelligence)のオープンソースプロジェクトです。最新のAIリソース# OCR# ドキュメントの抽出とクリーニング1年前052.1K
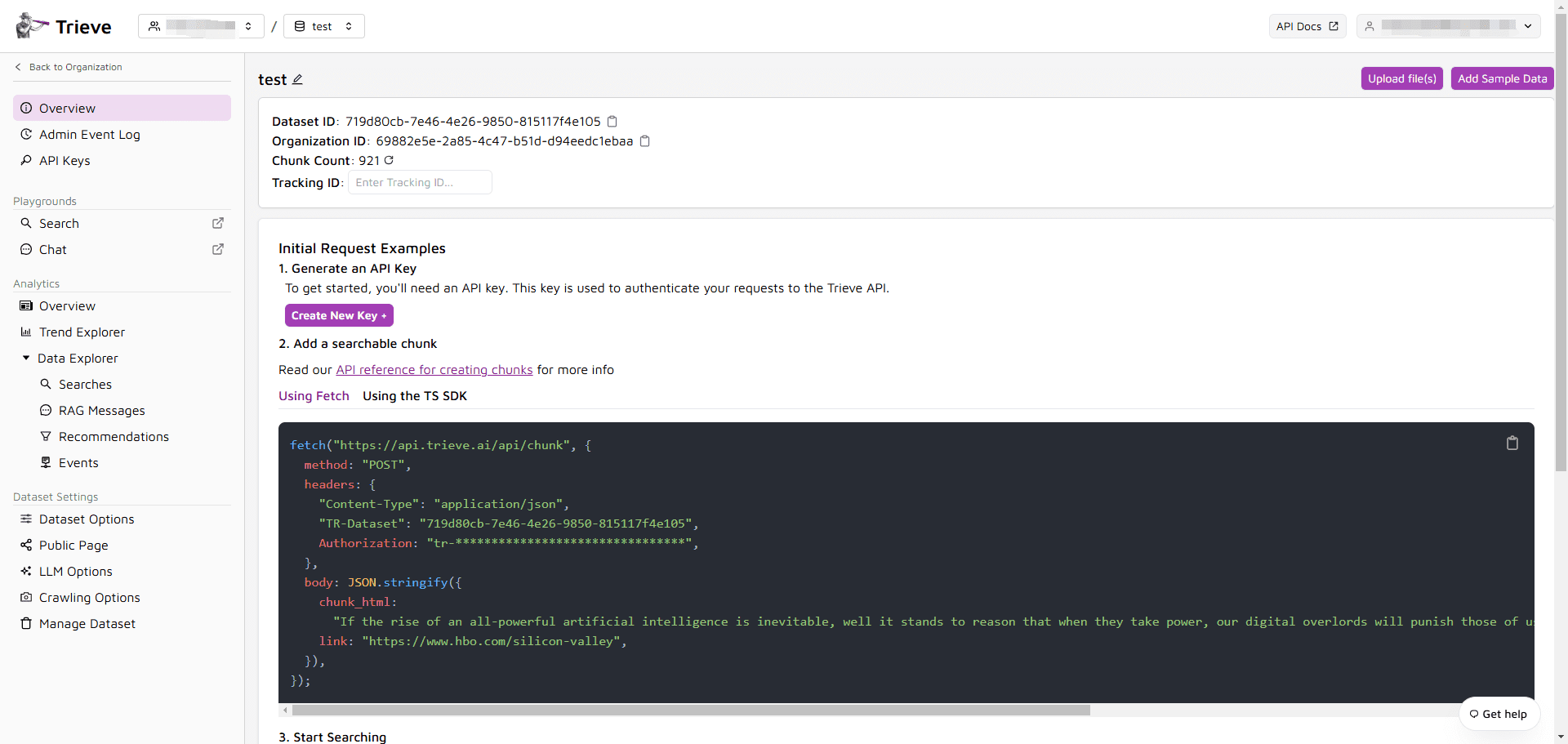
Trieve:検索、レコメンデーション、アナリティクスを提供するフルサービスのRAGクラウドインフラストラクチャ概要 Trieveは、検索、レコメンデーション、RAG(Retrieval Augmented Generation)、分析のために設計された、Devflow, Inc.によって開発された包括的なインフラストラクチャです。プラットフォームはAPI経由で提供され、AWS、GCP、K...最新のAIリソース# AIオープンサービス# ドキュメントの抽出とクリーニング1年前059.3K
pdf2htmlEX: テキストフォーマットを維持したまま、PDFをHTMLにロスレス変換。包括的な紹介 pdf2htmlEXは、PDFファイルをHTML形式に変換するために設計されたオープンソースのツールであり、PDFファイルの内容を分析し、HTML + CSSを使用して正確にその視覚効果を復元することにより、PDF文書は、ブラウザに変換されます。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前059.3K
Maxun:ウェブデータを自動的にクロールし、APIやスプレッドシートに変換するオープンソースのコード不要プラットフォーム包括的な紹介 Maxunはオープンソースのコード不要のウェブデータ抽出プラットフォームで、ウェブデータを自動的にクロールしてAPIやスプレッドシートに変換するロボットを数分で訓練することができます。このプラットフォームは、ページングとスクロールをサポートし、ウェブサイトのレイアウトの変更に適応し、強力なデータクローリングを提供します。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前060.1K
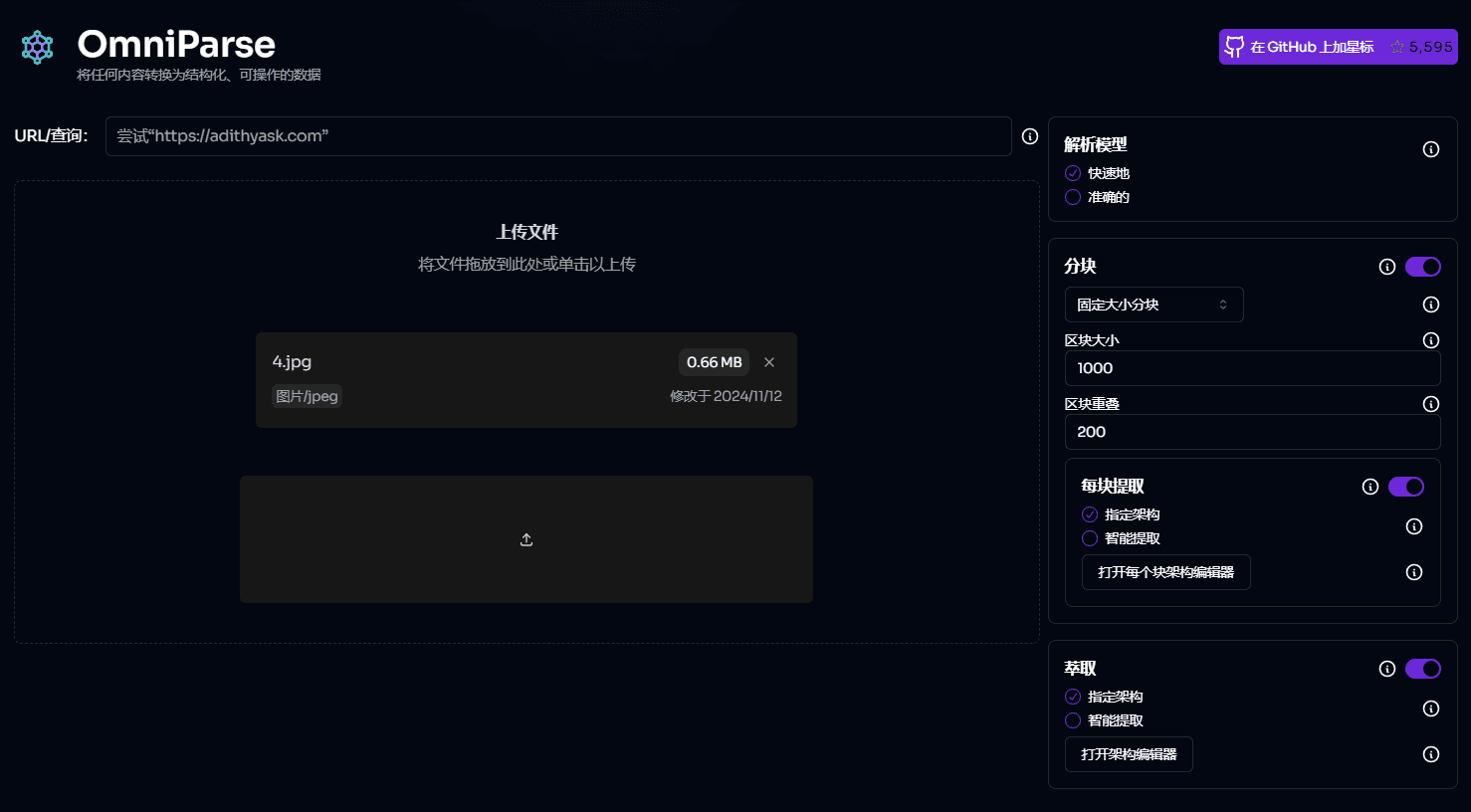
OmniParse: ドキュメント/マルチメディアからあらゆる非構造化データを抽出し、構造化データにパースします。概要 OmniParseは、あらゆる非構造化データを構造化された実用的なデータに変換するために設計された強力なデータ解析および最適化プラットフォームであり、GenAI(Generative Artificial Intelligence)フレームワーク用に最適化されています。ドキュメント、テーブル、画像、ビデオ、オーディオファイル、または...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前051.4K
Parsio: PDF、電子メール、その他のドキュメントから主要な構造化データを自動的に抽出します。概要 ParsioはAIベースの文書および電子メールデータ抽出ツールで、PDFや電子メール、その他の文書から構造化されたデータを自動的に抽出します。このプラットフォームは、強力なPDFパーサーとOCR機能を提供し、...最新のAIリソース# ドキュメントの抽出とクリーニング1年前055.7K
Chonkie: 軽量なRAGテキストチャンキングライブラリ包括的な紹介 Chonkieは軽量で効率的なRAG(Retrieval-Augmented Generation)テキストチャンキングライブラリで、開発者が素早く簡単にテキストをチャンキングできるように設計されています。このライブラリは、... を含む様々なチャンキング手法をサポートしています。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前070.8K
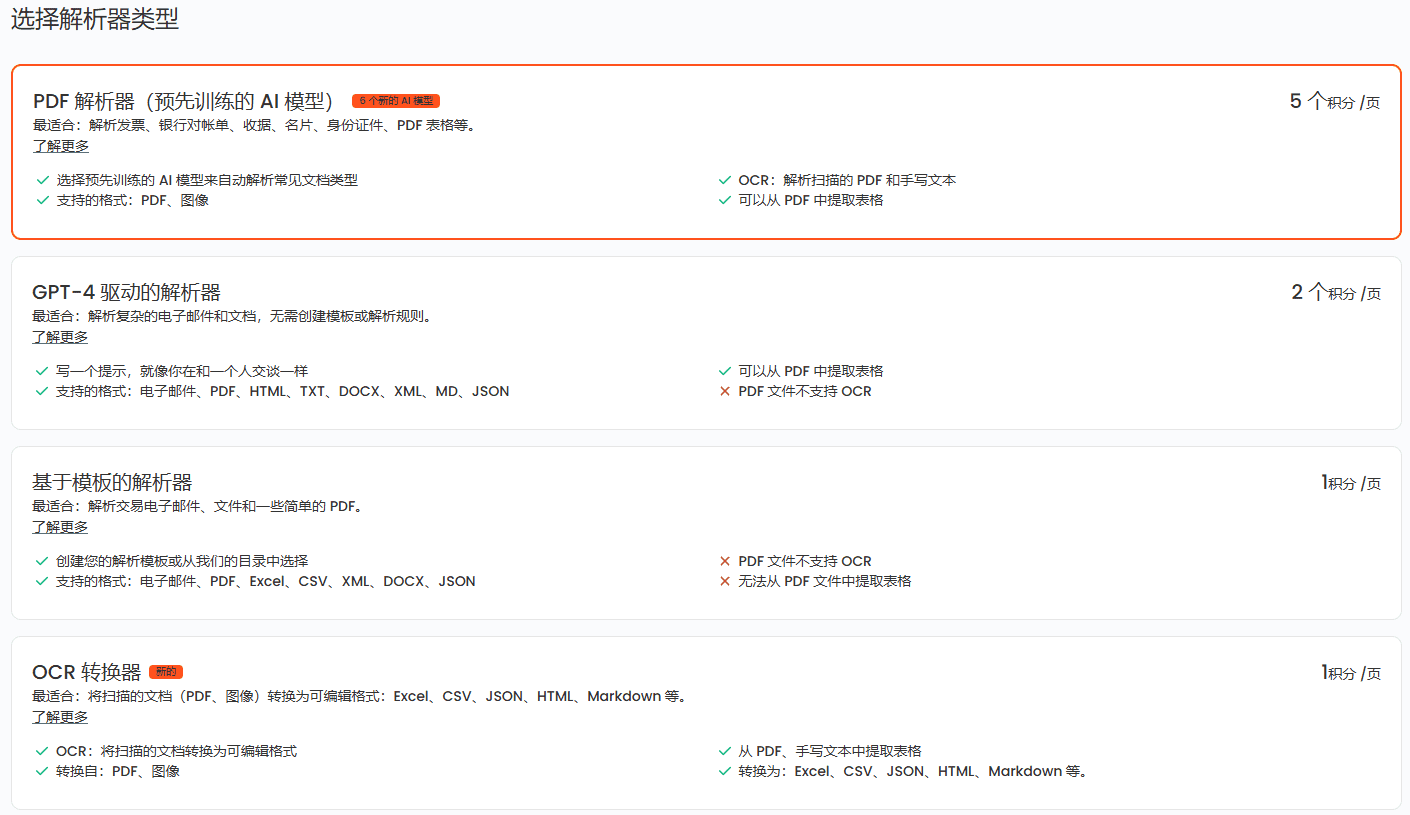
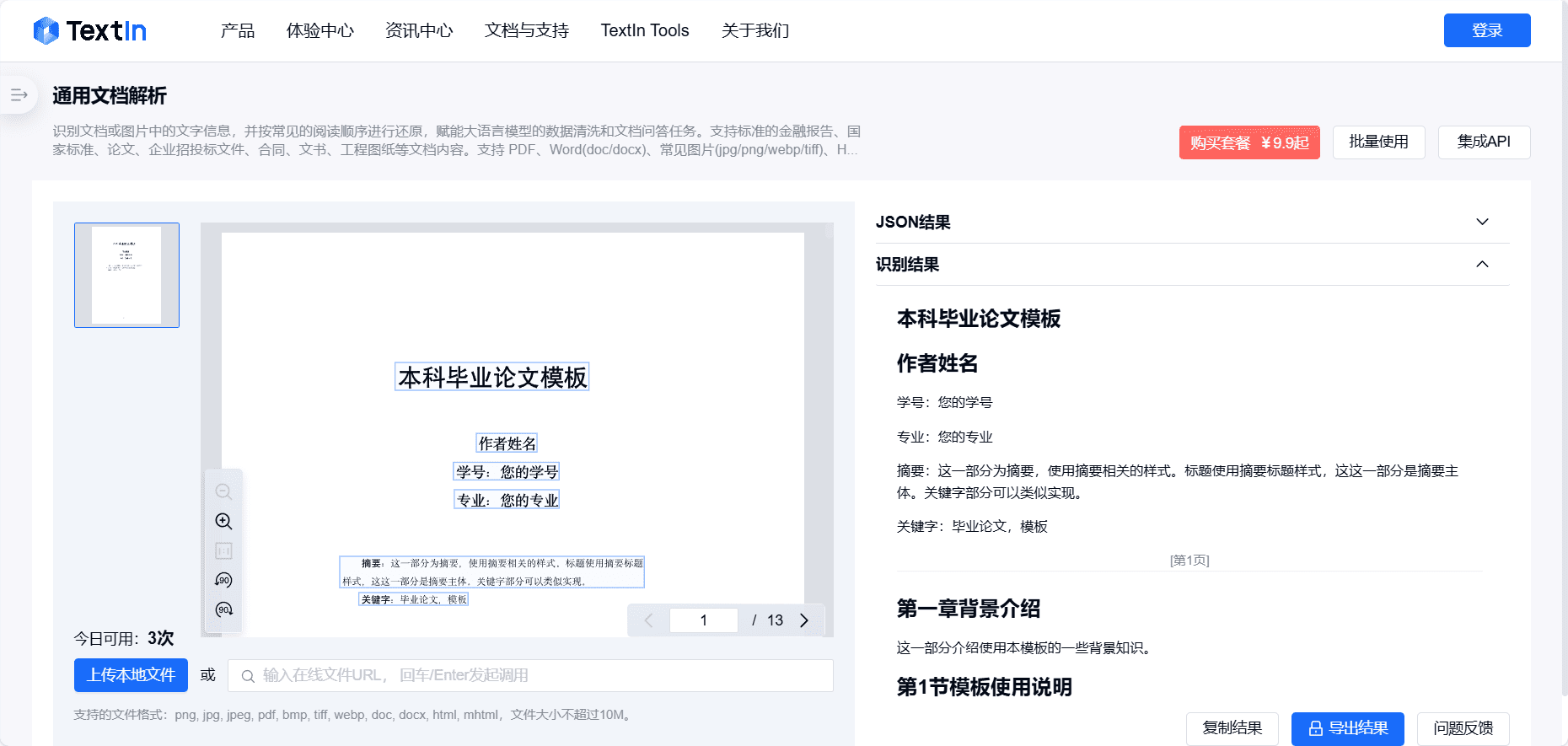
TextIn: ユニバーサルドキュメント変換、PDF to Markdownツール包括的な紹介 TextInは、ユーザーが効率的にPDF文書をMarkdown形式に変換するために設計された専門的なPDF to Markdownツールです。このツールは様々なファイル形式をサポートし、操作が簡単で、変換速度が速く、元のPDF形式と内容を保持します。最新のAIリソース# ドキュメントの抽出とクリーニング1年前052.3K
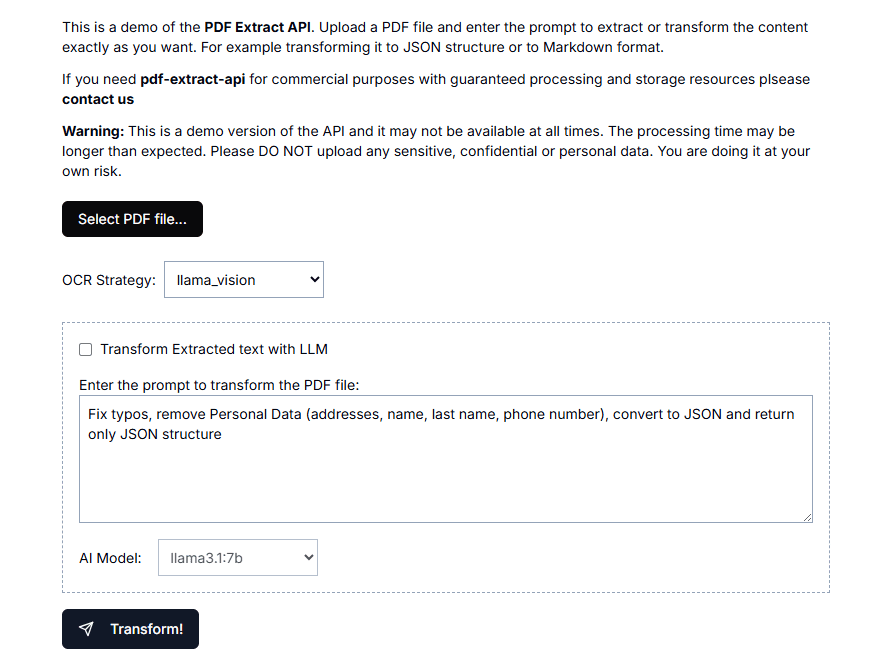
テキスト抽出 API (text-extract-api): テキスト情報の視覚的抽出、匿名化 PDF 抽出ツール包括的な紹介 テキスト抽出API(text-extract-api)は、さまざまな文書形式(PDF、Word、PPTXなど)からコンテンツを抽出し、解析するために設計された強力なツールです。このAPIは、最先端の光学式文字認識(OCR)技術とOl...最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング1年前054.7K
Datalab:専用のOCR認識AIモデル、PDF to Markdown(オープンソース/API)包括的な紹介 Datalabは、OCR、レイアウト分析、PDFからMarkdownへの変換などに焦点を当てた高度なAIモデルを幅広く提供しています。これらのモデルは高性能であるだけでなく、使いやすくオープンソースです。プラットフォーム上のマーカーモデルは、迅速かつ正確に...最新のAIリソース# AIオープンサービス# AI Java オープンソースプロジェクト# OCR1年前062.8K
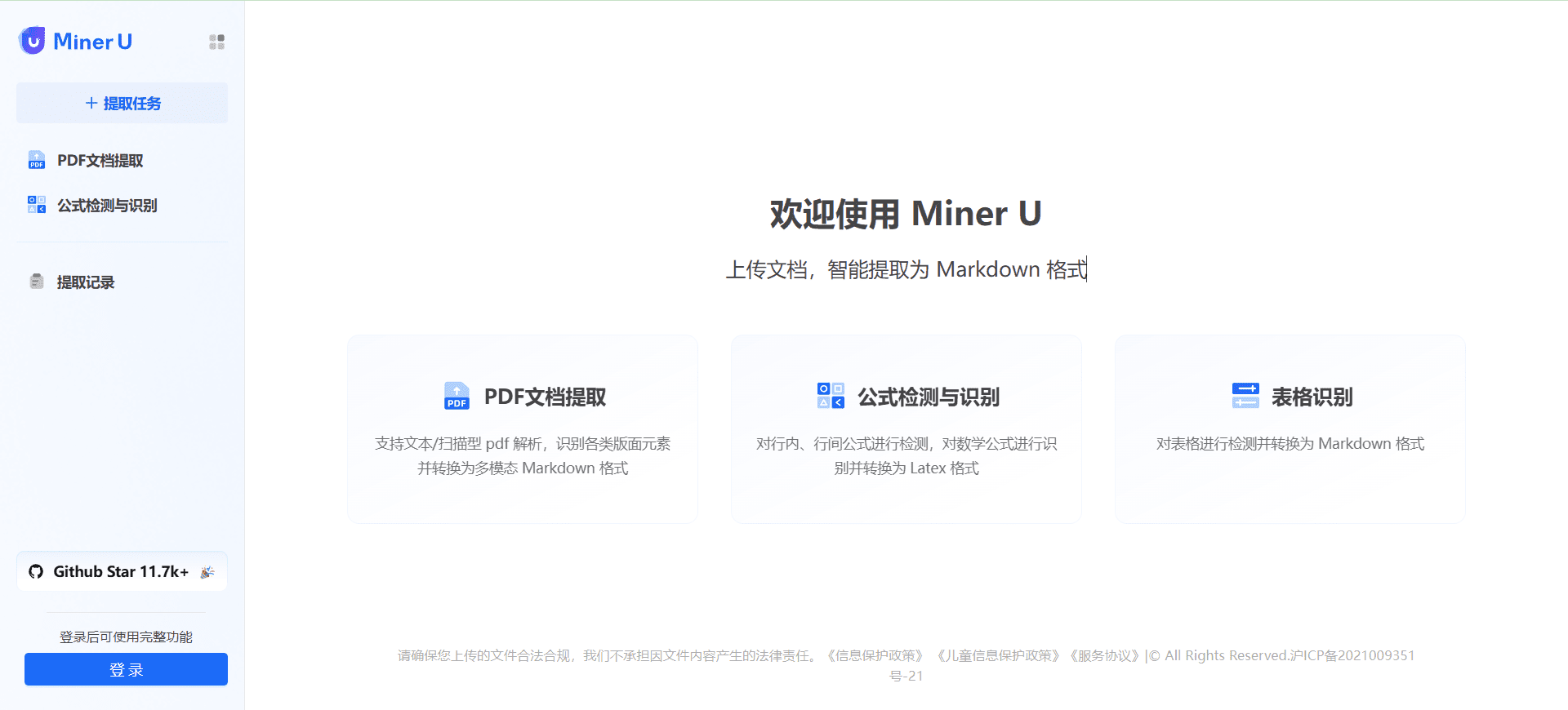
MinerU: PDFドキュメントの抽出とマルチモーダルMarkdownフォーマットへの変換、電子書籍OCRスキャンのサポート包括的な紹介 MinerUは、上海人工知能研究所のOpenDataLabチームによって開発されたオープンソースのデータ抽出ツールで、複雑なPDF文書、ウェブページ、電子ブックからコンテンツを効率的に抽出することに重点を置いている。画像、数式、表、その他の要素を含むマルチモーダルPDFを取り込むことができる。最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング2年前0135K
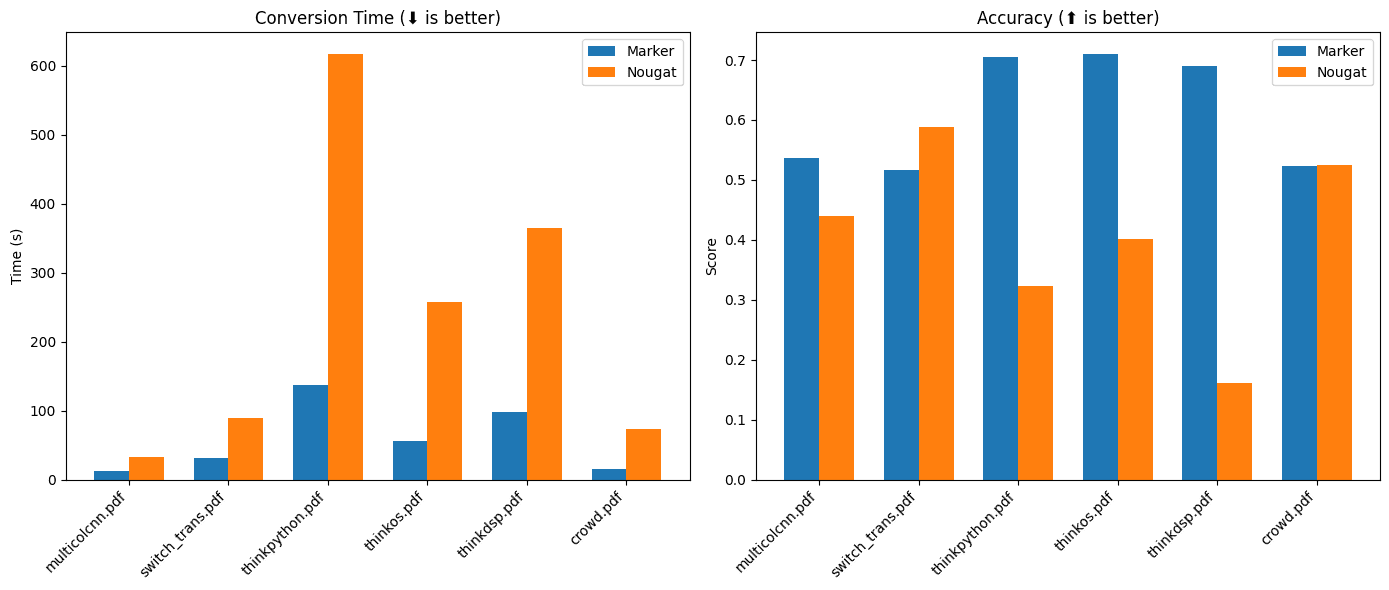
Marker:PDFをMarkdownに素早く変換するオープンソースツール一般的な説明 Markerは、PDFファイルを素早く正確にMarkdown形式に変換するために設計された、ディープラーニングベースの文書処理ツールです。幅広い種類のドキュメントをサポートし、特に書籍や科学論文の変換に最適化されています。Markerはヘッダーを削除することができます...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1年前0121K
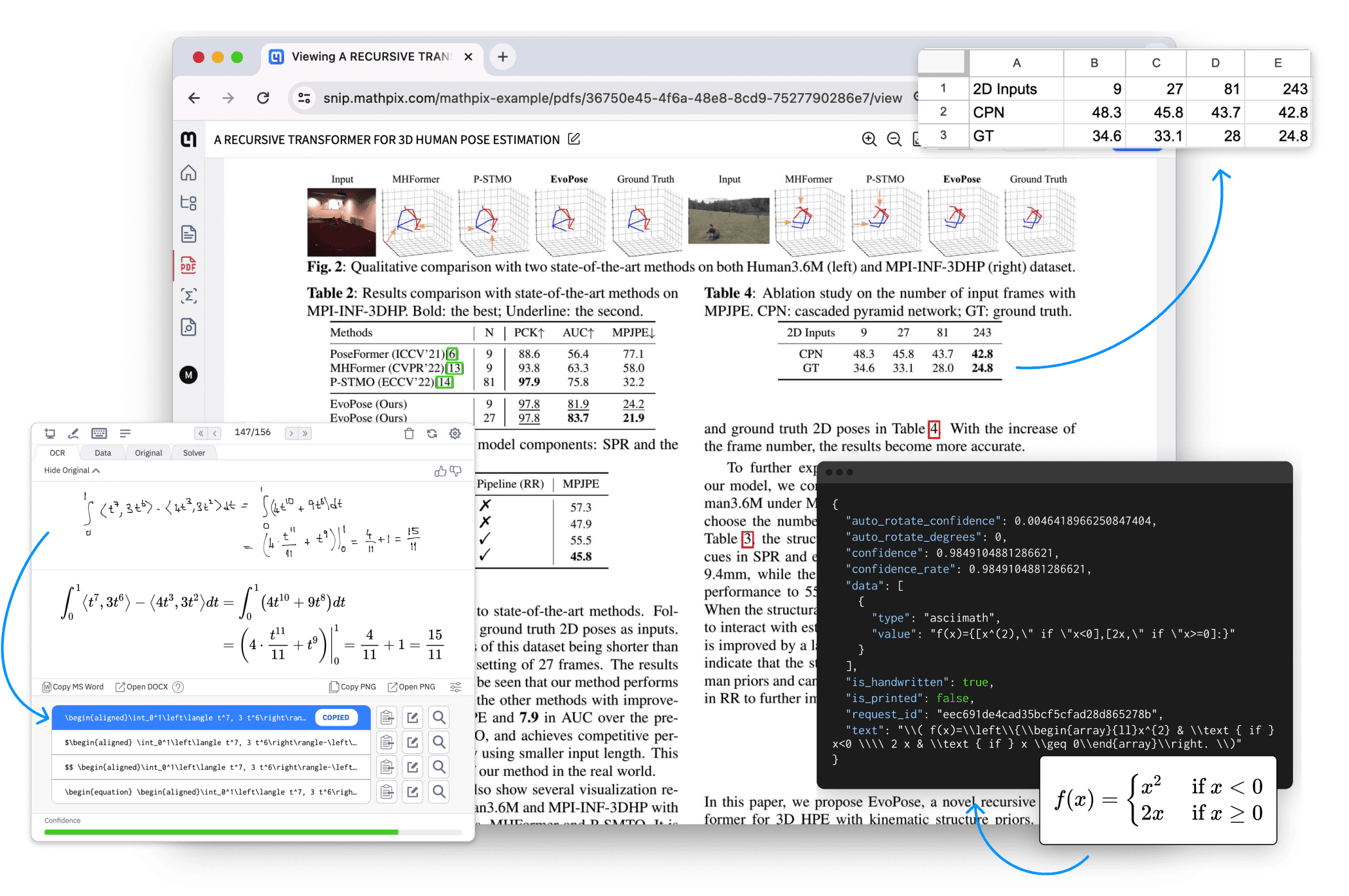
Mathpix:PDFと画像ドキュメントの構造変換ソフトウェア、マルチターミナルをサポート概要 Mathpixは、研究者、開発者、企業向けに設計された、強力なAI駆動型ドキュメント自動化ツールです。Mathpixは、PDFや画像を迅速かつ正確に、検索可能、エクスポート可能、機械可読テキストに変換します。最新のAIリソース# AIオープンサービス# ドキュメントの抽出とクリーニング2年前0103.3K
非構造化:オープンソースの非構造化ドキュメントの前処理、非構造化データ処理ツール包括的な紹介 Unstructured-IOは、画像やPDF、HTML、Word文書などのテキスト文書を処理・前処理するためのオープンソースコンポーネントのセットを提供します。その主な目的は、特に大規模な言語モデル(LL...最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング2年前069.7K
Reader API: ウェブコンテンツ抽出ツール、HTMLからMarkdownへの変換一般的な紹介 Jina AIのReaderプロジェクトは、https://r.jina.ai/转换成适合大型语言模型(Large Languag...)という接頭辞を付加することで、任意のURLを受け取るオープンソースツール(Readerオープンソースアドレス)です。最新のAIリソース# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング2年前0330.3K