r1-reasoning-rag:収集した情報からの再帰的推論に基づくRAGの新しいアイデア

最近、素晴らしいオープンソースプロジェクトを発見した。 ラグ という考えがある。 DeepSeek-R1 の組み合わせの推理力 Agentic Workflow RAG検索に適用
プロジェクト住所
https://github.com/deansaco/r1-reasoning-rag.git
プロジェクトは以下の組み合わせで実施される。 DeepSeek-R1そしてTavily 歌で応える LangGraphを利用したAI主導の動的情報検索・回答メカニズムを実装している。 deepseek な r1 複雑な質問に完全に答えるために、知識ベースから積極的に情報を取り出し、取捨選択し、合成する推論。
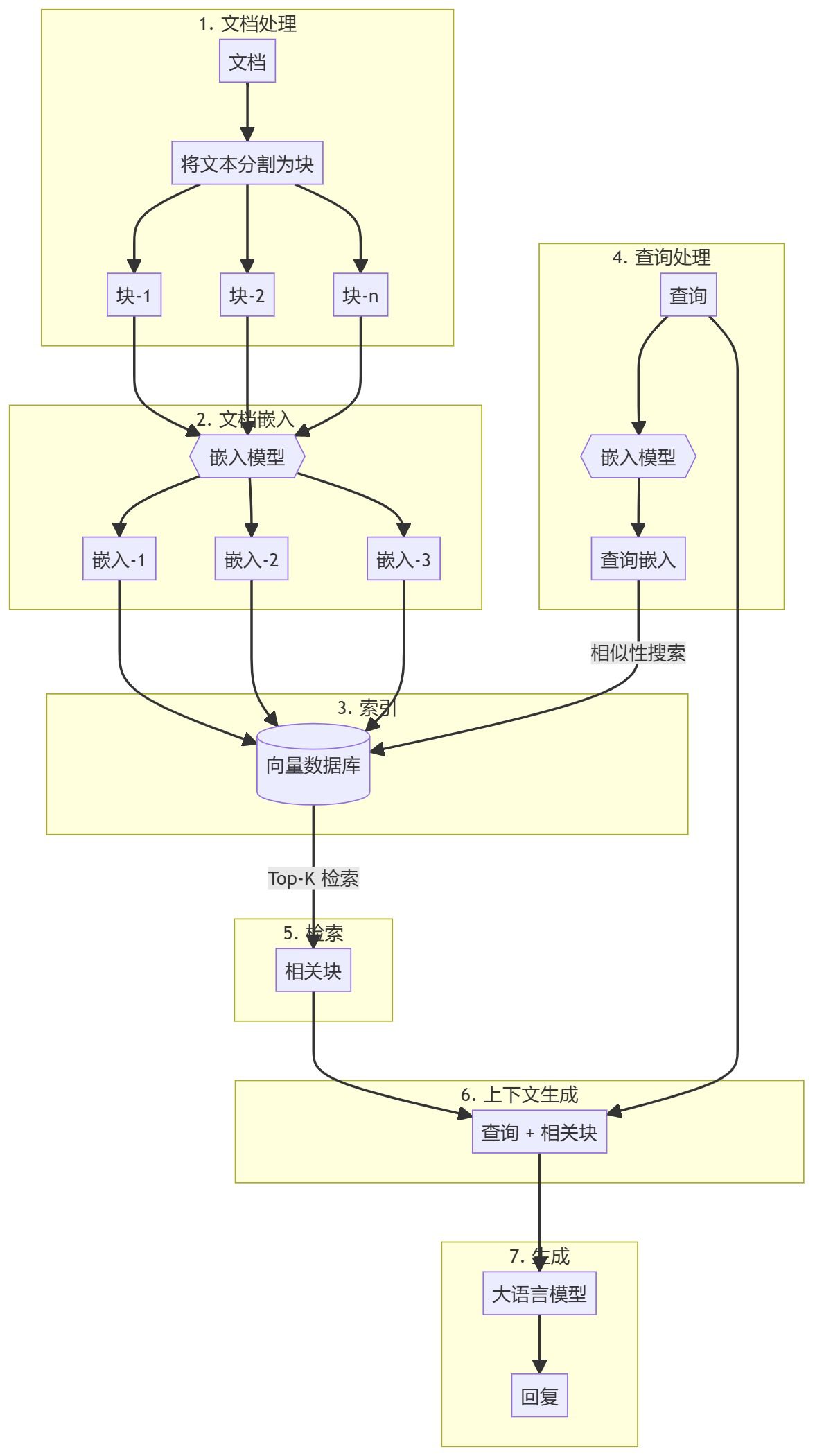
新旧RAG比較
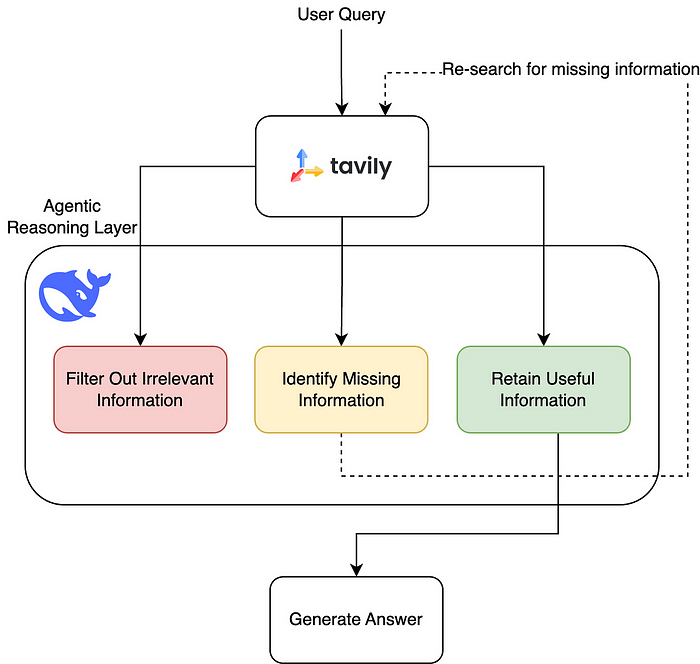
従来のRAG(Retrieval Augmented Generation)は少々硬直的で、通常、検索が処理された後、類似検索によっていくつかのコンテンツが発見され、一致度に応じて並び替えられ、信頼できそうな情報の断片が大規模言語モデル(LLM)に渡され、答えが生成される。しかし、これは特に並べ替えモデルの質に依存しており、モデルが強力でなければ、重要な情報を見逃したり、間違ったものをLLMに渡したりしやすく、結果として得られる答えは信頼できるものにならない。
現在。 LangGraph チームはそのプロセスに大きなアップグレードを施した。 DeepSeek-R1 AIの強力な推論能力により、従来の動かないフィルタリング方法は、状況に応じて調整できる、より柔軟で動的なプロセスに変化した。彼らはこれを「エージェント検索」と呼んでいる。AIは不足している情報を積極的に見つけるだけでなく、情報を探す過程で自らの戦略を継続的に最適化し、一種の循環的最適化効果を形成することで、LLMに引き渡されるコンテンツがより正確なものになる。
この改良は、モデル内部から拡張テスト時間推論の概念をRAG検索に実際に適用し、検索の精度と効率を大幅に改善します。この新しいアプローチは、RAG検索技術に取り組んでいる人々にとって、間違いなく調べる価値のあるものである!
コア技術とハイライト
DeepSeek-R1 推論
更新済み DeepSeek-R1 は強力な推論モデルである
- 情報内容の深い思考による分析
- 既存コンテンツの評価
- 検索結果の精度を向上させるため、推論を何度も繰り返し、不足しているコンテンツを特定する。
Tavilyインスタント情報検索
Tavily インスタント情報検索を提供し、モデルの知識の範囲を拡大するために、過去に大きなモデルを最新の情報にすることができます。
- 静的データだけに頼るのではなく、欠落した情報を洗い出す動的検索。
LangGraph 再帰的検索 (RR)
を通して Agentic AI これは、検索と推論を複数回繰り返した後に、大規模なモデルが閉ループ学習を形成できるようにするためのメカニズムで、次のような一般的なプロセスを持つ:
- 最初のステップは、問題についての情報を探すことである。
- 第二段階は、その情報が質問に答えるのに十分かどうかを分析することである。
- ステップ3 情報が不十分な場合は、さらに問い合わせを行う
- ステップ4 関連性のないコンテンツをフィルタリングし、有効な情報だけを残す
そのような 递归式 検索メカニズムは、大規模なモデルがクエリー結果を継続的に最適化し、フィルタリングされた情報をより完全で正確なものにすることを保証する。
ソースコード解析
ソースコードから見ると、シンプルな3つのファイルだ:agentそしてllmそしてprompts
代理店
このセクションの核となる考え方は以下の通りである。 create_workflow この関数
 このように定義している。
このように定義している。 workflow のノードは add_conditional_edges 定義の一部は条件付きエッジであり、処理の全体的な考え方は、冒頭で見たグラフの再帰的ロジックである。
不慣れな場合 LangGraph そうすれば、情報をチェックすることができる。LangGraph この構造体は、ノードとエッジを持つグラフデータ構造であり、エッジは条件付きである。
各検索の後、大きなモデルによって選別され、無用な情報は除外され(Filter Out Irrelevant Information)、有用な情報は保持され(Retain Useful Information)、欠落した情報については(Identify Missing Information)、再び検索される。このプロセスは、目的の答えが見つかるまで繰り返される。
プロンプト
ここで定義される主な合図は2つある。VALIDATE_RETRIEVAL このテンプレートは、検索された情報が与えられた質問に答えられるかどうかを検証するために使用されます。このテンプレートには2つの入力変数があります: retrieved_contextとquestionです。このテンプレートの主な目的は、提供されたテキストブロックに基づいて、質問に答えられる情報が含まれているかどうかを判断するJSON形式のレスポンスを生成することです。 
ANSWER_QUESTION提供されたテキストブロックに基づいて質問に答えるよう、質問応答エージェントに指示するために使用されます。このテンプレートは、retrieved_contextとquestionという2つの入力変数を持ちます。このテンプレートの主な目的は、与えられたコンテキスト情報に基づいて、直接的で簡潔な回答を提供することです。

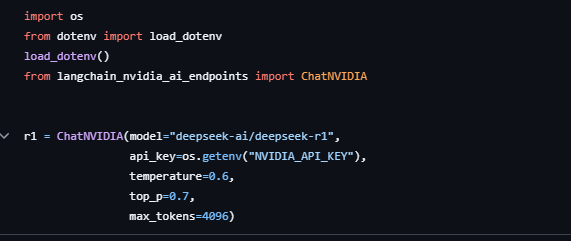
llm
ここでは r1 モデリング
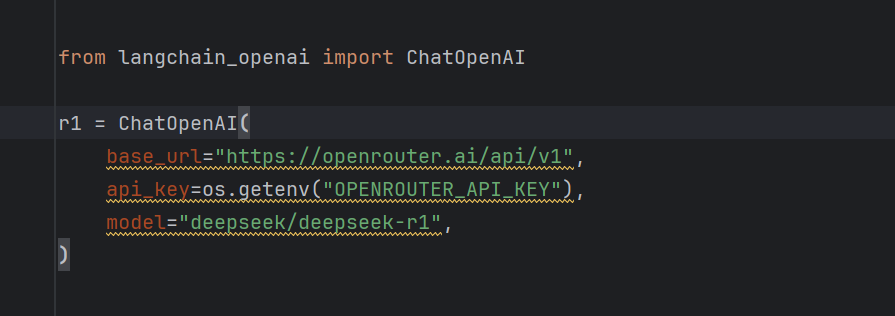
他のベンダーが提供するモデルに変更することも可能です。 openrouter 無料 r1 モデリング
試験効果
プロジェクト内のスクリプトを使用しない別のスクリプトをここに書きました。 《哪吒2》中哪吒的师傅的师傅是谁
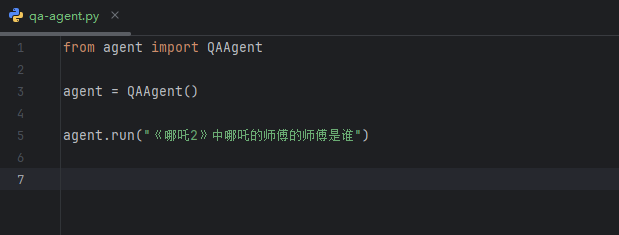
まず、情報を検索するために検索を呼び出し、それから

そして、分析を開始し、次のようになる。 哪吒的师父是太乙真人 これは有効な情報だが、同時に欠けている情報も見つかった。 太義の師匠(つまり哪吒の師匠)の具体的な身元や名前。

そして、不足している情報を探し、戻ってきた情報を分析し、検証し続ける。
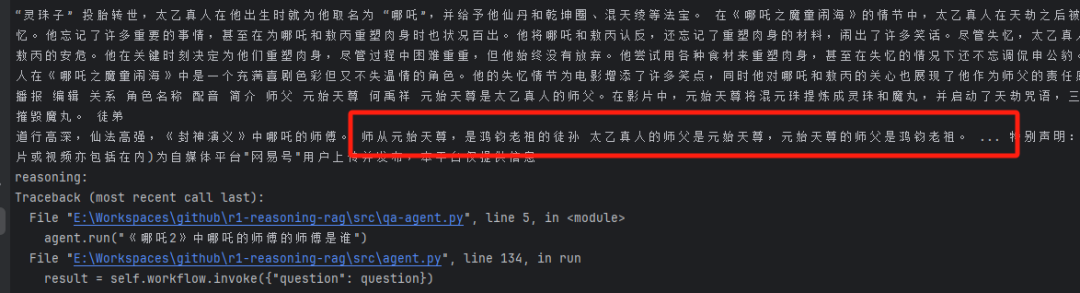
私の方ではネットワークがダウンしていたため、後でエラーが報告されたが、上の画像からわかるように、この重要な情報を見つけることができるはずだった。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません