LightLLM:大規模言語モデルの推論と処理のための効率的な軽量フレームワーク

はじめに
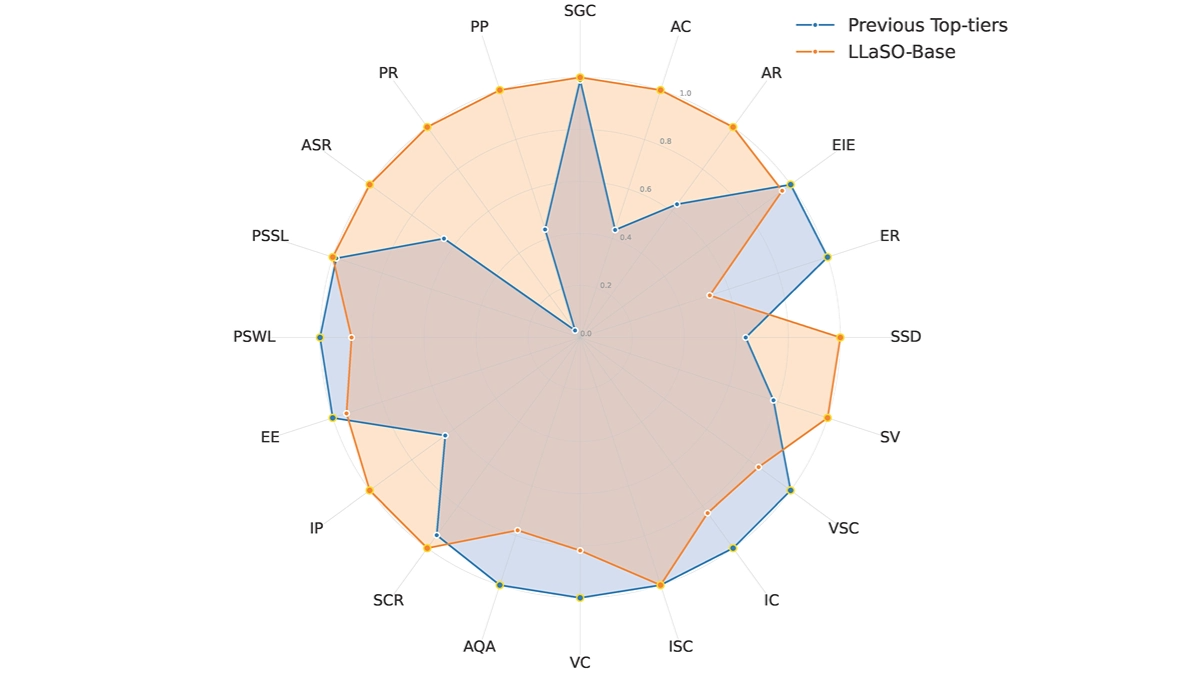
ライトLLM lightLLMは、PythonベースのLarge Language Model(LLM)推論・サービスフレームワークで、軽量設計、スケーリングの容易さ、効率的なパフォーマンスで知られています。このフレームワークは、FasterTransformer、TGI、vLLM、FlashAttentionなど、さまざまな有名なオープンソース実装を活用しています。lightLLMは、非同期コラボレーション、動的バッチ処理、テンソル並列処理などの技術により、GPUの利用率と推論速度を劇的に向上させ、さまざまなモデルやアプリケーションシナリオに対応します。

機能一覧
- 非同期コラボレーション:GPUの利用率を向上させるために、非同期の単語分割、モデル推論、分割解除操作をサポートします。
- フィラーレス・アテンション:複数のモデルに対するフィラーレス・アテンション操作をサポートし、長さの差が大きいリクエストに対応する。
- 動的バッチ処理:リクエストの動的バッチスケジューリングをサポート。
- FlashAttention:FlashAttentionで速度を向上し、GPUメモリのフットプリントを削減します。
- テンソル並列:テンソル並列を使用して複数のGPUで推論を高速化。
- トークン KVキャッシュにトークン・ベースのメモリ管理メカニズムを実装し、メモリの無駄をゼロにした。
- 高性能ルーター:トークン・アテンションと連携し、システムのスループットを最適化。
- Int8KVキャッシュ:トークンの容量をほぼ2倍に増加。
- 複数のモデルをサポート:BLOOM、LLaMA、StarCoder、ChatGLM2など。
ヘルプの使用
設置プロセス
- Dockerを使用してLightLLMをインストールします:
docker pull modeltc/lightllm
docker run -it --rm modeltc/lightllm
- 依存関係をインストールします:
pip install -r requirements.txt
使用方法
- LightLLM サービスを開始します:
python -m lightllm.server
- クエリーモデル(コンソールの例):
python -m lightllm.client --model llama --text "你好,世界!"
- クエリーモデル(Pythonの例):
from lightllm import Client
client = Client(model="llama")
response = client.query("你好,世界!")
print(response)
主な機能
- 非同期コラボレーションLightLLMは、セグメンテーション、モデル推論、セグメンテーション解除の各操作を非同期で実行することで、GPUの使用率を大幅に向上させます。ユーザーはサービスを開始するだけで、システムがこれらの処理を自動的に処理します。
- 注意力不足長さの差が大きいリクエストを処理する場合、LightLLM はパディングなしのアテンション操作をサポートし、効率的な処理を保証します。ユーザーによる追加設定は不要で、システムは自動的に最適化されます。
- ダイナミック・バッチ処理LightLLMはダイナミックバッチスケジューリングをサポートしており、ユーザーは設定ファイルを通じてバッチパラメータを設定することができます。
- フラッシュ・アテンションFlashAttention技術を統合することで、LightLLMは推論速度を向上させ、GPUメモリフットプリントを削減します。ユーザーは設定ファイルでこの機能を有効にすることができます。
- テンソル並列LightLLMは複数GPUでのテンソル並列をサポートしており、ユーザーは設定ファイルでGPUの数と並列パラメーターを設定すれば、システムが自動的にタスクを割り当てます。
- トークン・アテンションLightLLMはKVキャッシュにトークンベースのメモリ管理メカニズムを実装し、メモリの無駄をゼロにします。ユーザーによる追加設定は不要で、システムが自動的にメモリを管理します。
- 高性能ルーターLightLLMの高性能ルーターは、トークン・アテンションと連携してシステムのスループットを最適化します。ユーザーが設定ファイルでルーティング・パラメーターを設定すると、システムが自動的にルーティング・ポリシーを最適化します。
- Int8KVキャッシュLightLLM は Int8KV キャッシュをサポートし、トークンの容量をほぼ 2 倍に増やします。ユーザーが設定ファイルでこの機能を有効にすると、システムが自動的にキャッシュ戦略を調整します。
対応モデル
LightLLMは様々なモデルをサポートしています:
- ブルーム
- LLaMA
- スターコーダー
- チャットGLM2
- インターンLM
- クウェン-VL
- ラバ
- 厩務員
- ミニCPM
- ファイ3
- CohereForAI
- ディープシーク-V2
ユーザーは必要に応じて適切なモデルを選択し、コンフィギュレーション・ファイルで設定することができる。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません