DeepSeekハンズオン:3つのステップによる知識グラフの構築 - 単一抽出、複数パートの融合、トピック生成

質問だ: ナレッジグラフは重要だ。DeepSeek言語モデルが話題だが、ナレッジグラフを素早く構築するのに使えるのか?試してみたい。 ディープシーク 情報を抽出し、知識を統合し、何もないところからグラフを作成する能力がどの程度あるのか、実物を見てみよう。
方法: 私は、DeepSeekの知識グラフ構築能力をテストするために3つの実験を行った:
- 単一記事のビルドマッピング: DeepSeekに記事を与え、情報を正確に取得してグラフを作成できるかどうかを確認する。
- 複数記事のフュージョンマッピング DeepSeekに複数の記事を与えて、既存のグラフに新しい知識を追加できるかどうかを確認する。
- テーマ・ジェネレーション・マッピング: DeepSeekに、記事ではなくアトラスのトピックを伝え、DeepSeek自身がアトラスを作成できるかどうかを確認してください。
結果 実験は、DeepSeekが知識グラフをうまく構築し融合することを証明しているが、まだ改善の余地がある。
以下は実験の正確な手順と結果だが、より簡単な言葉で明らかにしよう。
I. 1つの記事から知識を抽出してマップを作る
目的 記事から知識を抽出し、ナレッジグラフを構築するDeepSeekの能力をテスト。
プロセス NebulaGraph グラフ・データベースに関する記事を見つけ、DeepSeek に記事を読ませて重要な情報を抽出し、NebulaGraph データベース・コード (nGQL) を生成してナレッジ・グラフを作成させました。
指示する: 「ナレッジグラフの作成を手伝ってもらえませんか?記事を渡すから、重要な情報を抽出して、nGQLコードでナレッジグラフを構築してくれ。"
オペレーション 記事の内容をコピーしてDeepSeekに直接貼り付けます。
DeepSeek が生成した nGQL コード:
# Schema 定义(TAG 类型)
CREATE TAG IF NOT EXISTS product (
name STRING,
description STRING
);
CREATE TAG IF NOT EXISTS company (
name STRING
);
CREATE TAG IF NOT EXISTS feature (
name STRING
);
CREATE TAG IF NOT EXISTS tool (
name STRING
);
CREATE TAG IF NOT EXISTS scenario (
name STRING
);
CREATE TAG IF NOT EXISTS language (
name STRING
);
CREATE TAG IF NOT EXISTS auth_service (
name STRING
);
CREATE TAG IF NOT EXISTS ecosystem (
name STRING
);
# Schema 定义(EDGE 类型)
CREATE EDGE IF NOT EXISTS has_feature ();
CREATE EDGE IF NOT EXISTS used_by ();
CREATE EDGE IF NOT EXISTS provides_tool ();
CREATE EDGE IF NOT EXISTS supports_language ();
CREATE EDGE IF NOT EXISTS applicable_scenario ();
CREATE EDGE IF NOT EXISTS compatible_with ();
CREATE EDGE IF NOT EXISTS supports_auth ();
CREATE EDGE IF NOT EXISTS integrates_with ();
# 数据插入 - 核心产品
INSERT VERTEX product(name, description) VALUES
"NebulaGraph": ("NebulaGraph", "开源的分布式图数据库,支持千亿点万亿边数据集");
# 数据插入 - 产品特性
INSERT VERTEX feature(name) VALUES
"high_performance": ("高性能"),
"open_source": ("开源"),
"scalability": ("易扩展"),
"flexible_modeling": ("灵活数据建模"),
"read_write_balance": ("读写平衡"),
"compatibility": ("查询语言兼容性");
/* ... 此处省略 n多数据 ... */
結果 DeepSeekのコードは問題なく、構文も正しく、複数のデータを1つのステートメントにまとめるという点で効率的です。このコードを NebulaGraph に入力して実行すると、グラフは次のようになります:
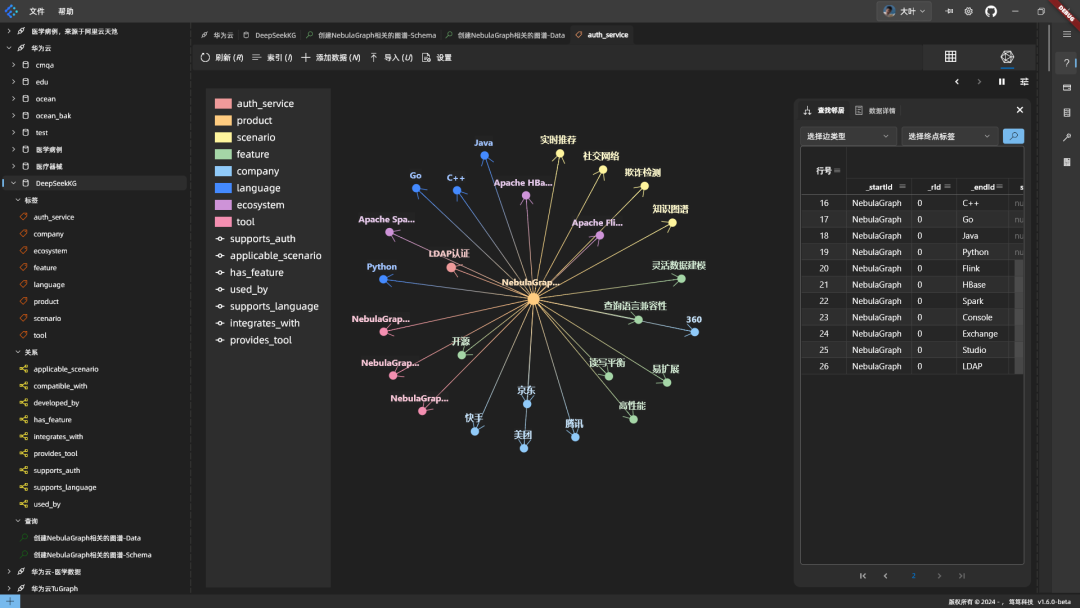
グラフはNebulaGraphを中心に関連情報を表示する。
II.複数の記事にまたがる知識の統合
目的 既存のグラフを拡張するために、複数の記事から知識を融合するDeepSeekの能力をテスト。
プロセス まず1つの記事でグラフを構築し、次に(百度の百科事典から)NebulaGraphに関するより多くの記事をDeepSeekに与えて、新しい知識を既存のグラフにマージする。
指示する: 「次の記事マッピングを現在のテーブル構造になじませてみてください。テーブル構造を変更するにはALTERコマンドを使用する。"
オペレーション NebulaGraphと360百科事典のエントリの抄録は、それぞれDeepSeekに提供された。
DeepSeekが生成したnGQLコード(NebulaGraphのエントリ):
# 结构变更 1:为 product 标签增加版本和时间属性
ALTER TAG product ADD (
license STRING,
current_version STRING,
release_date STRING,
last_updated STRING
);
# 结构变更 2:新增开发关系类型
CREATE EDGE IF NOT EXISTS developed_by();
# 数据更新 - 补充产品属性
INSERT VERTEX product(name, description, license, current_version, release_date, last_updated)
VALUES
"NebulaGraph": ("NebulaGraph", "分布式图数据库", "Apache 2.0", "v3.3.0", "2019-05-15", "2022-11-14");
# 新增开发公司(复用 company 标签)
INSERT VERTEX company(name)
VALUES
"Yueshu": ("杭州悦数科技有限公司");
# 新增特性(复用 feature 标签)
INSERT VERTEX feature(name)
VALUES
"acl_mechanism": ("ACL 机制"),
"linear_scaling": ("线性扩容"),
"data_recovery": ("数据恢复"),
"htap": ("HTAP 混合负载"),
"nGQL_language": ("nGQL 查询语言");
# 关系建立(复用已有关系类型)
INSERT EDGE has_feature()
VALUES
"NebulaGraph"->"acl_mechanism":(),
"NebulaGraph"->"linear_scaling":(),
"NebulaGraph"->"data_recovery":(),
"NebulaGraph"->"htap":(),
"NebulaGraph"->"nGQL_language":();
# 新增开发关系
INSERT EDGE developed_by()
VALUES
"NebulaGraph"->"Yueshu":();
DeepSeek が生成した nGQL コード (360 ワード):
# 结构变更 1:为 company 标签增加创始人、成立时间和收入属性
ALTER TAG company ADD (founder STRING, founded_date STRING, revenue DOUBLE);
# 结构变更 2:新增事件类型 TAG
CREATE TAG IF NOT EXISTS event (
type STRING,
date STRING,
amount DOUBLE,
details STRING
);
# 数据更新:补充 360 公司信息
INSERT VERTEX company(name, founder, founded_date, revenue)
VALUES
"360": ("奇虎360", "周鸿祎", "2005-09", 116.15);
# 数据插入:产品生态(复用 product 标签)
INSERT VERTEX product(name)
VALUES
"360_Security_Guard": ("360安全卫士"),
"360_Browser": ("360安全浏览器"),
"360_Cloud": ("360安全云");
# 数据插入:重大事件(使用新增 event 标签)
INSERT VERTEX event(type, date, amount, details)
VALUES
"acquisition_360.com": ("域名收购", "2015-02-04", 1700.0, "1.1亿人民币收购 360.com"),
"privatization": ("私有化", "2015-12", 9300.0, "93 亿美元私有化交易");
# 关系建立:复用 developed_by 边连接产品
結果 DeepSeek は、新しい項目に基づいてテーブル構造を変更できます ( 製品 歌で応える 会社 テーブル+フィールド)と新しいリレーションシップ・タイプを追加した。これは ALTER コマンドでテーブル構造を変更することができる。 ちょっとした問題は、コメントで --nGQLが認識されない場合は、手動で変更してください。 # ライン上。
コードは実行のためにデータベースに入れられ、融合されたマッピングが機能する:
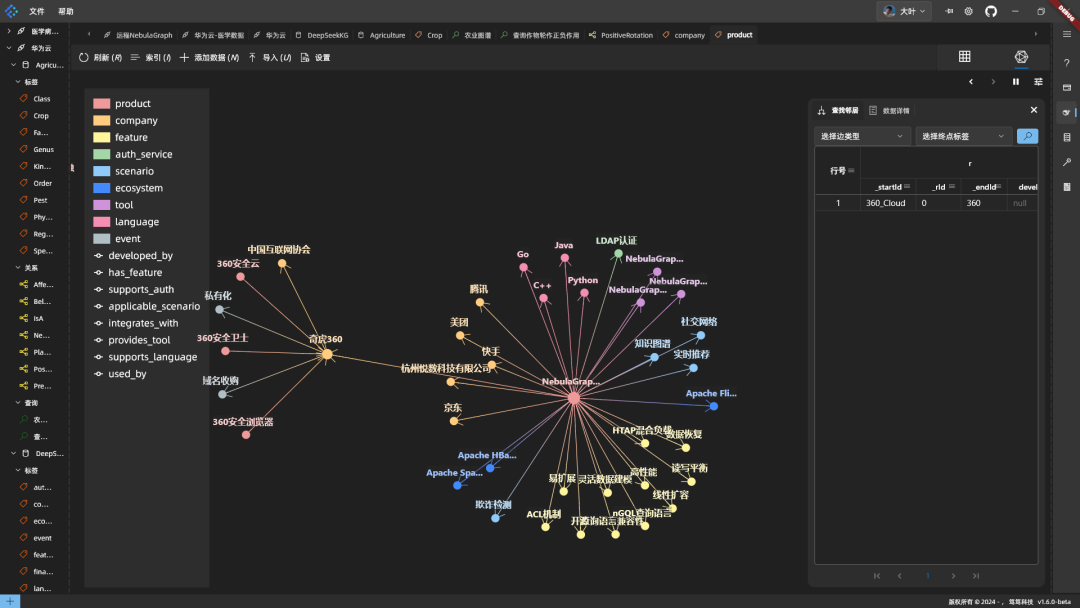
概要 DeepSeekはグラフの構築や知識の融合に適している。しかし、サーバーは時々遅く、NebulaGraphはスキーマを非同期で変更するため、反映されるまでに時間がかかる。
III.テーマの創出:何もないところからの農業地図作成
目的 記事のないトピックに基づいてナレッジグラフを生成するDeepSeekの機能をテスト。
プロセス 新しいダイアログを作成し、DeepSeekに「農業」のトピックに関するマッピングコードを直接生成させます。記事は指定されず、「自由参加」です。
指示する: "農業ナレッジグラフを構築したい。NebulaGraphデータベースを使用し、nGQLスクリプトを生成する。テーブル名は大きなこぶ、属性名は小さなこぶ、スキーマ名は衝突を避けるため``でラップ。少なくとも3000ノードを生成する。"
DeepSeek によって生成された nGQL コード (部分):
# ======================================= #
# 创建图空间
# ======================================= #
CREATE SPACE `Agriculture` (vid_type = FIXED_STRING(32));
USE `Agriculture`;
# ======================================= #
# 定义标签 Schema(大驼峰命名)
# ======================================= #
CREATE TAG IF NOT EXISTS `Crop` (
`cropId` int,
`cropName` string,
`growthPeriod` int,
`suitableTemp` string,
`yieldPerMu` float
);
# ======================================= #
# 此处省略好多脚本
# ======================================= #
問題点と改善点
- ノード数の制限: 3000ノードで始めたが、DeepSeekは拒否し、CSVコードをインポートするためにPythonを与えた。私はPythonを使いたくなかったので、ノード数を減らした。
- 注釈の問題が再び浮上する: コードのコメントは次のとおりである。 --疑問が再び指摘された。
改善指示: 「コメントには#を使い、Pythonコードは使わない。50ノード分のngqlスクリプトをください。"
フォローアップの対話と指示: マップを改良するために、私はDeepSeekと対話を続け、データの追加、関連付けの強化、分類(門、目、科、属、種)によるマップの整理、さらに輪作データの作成を依頼した。
例えば、私の指示:
- "データリンク強化のための補足データ"
- 「これらの分類(系統、目、科、属、種)のアトラスを作る。
- 「禁忌作物を特定し、既存作物のローテーションに作物を加える。
- "マッピングされた作物組織データを組み合わせて、以前のフォーマットでnGQLスクリプトを与える"
実験的な間奏曲: ディープシーク、一度だけ インサート 文はnGQLではサポートされていないCypher構文を使用しており、指摘を受けて変更した。
指示する: "この挿入文はnGQL構文ではありません。 DDLが先でDMLが後になるように変更してください。"
最終データ量: 数回の対話の後、データ量が表示される:

マッピング効果: ランダムなノードをいくつか展開して見る:
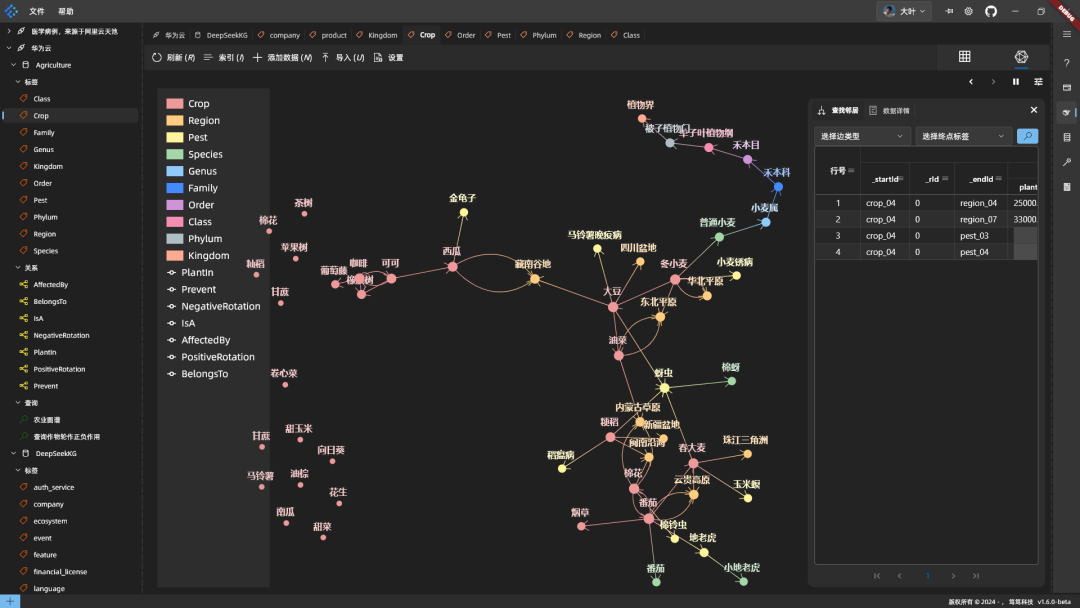
回転種の収量を高める組み合わせの例: 不定植による収量増加の組み合わせ効果:
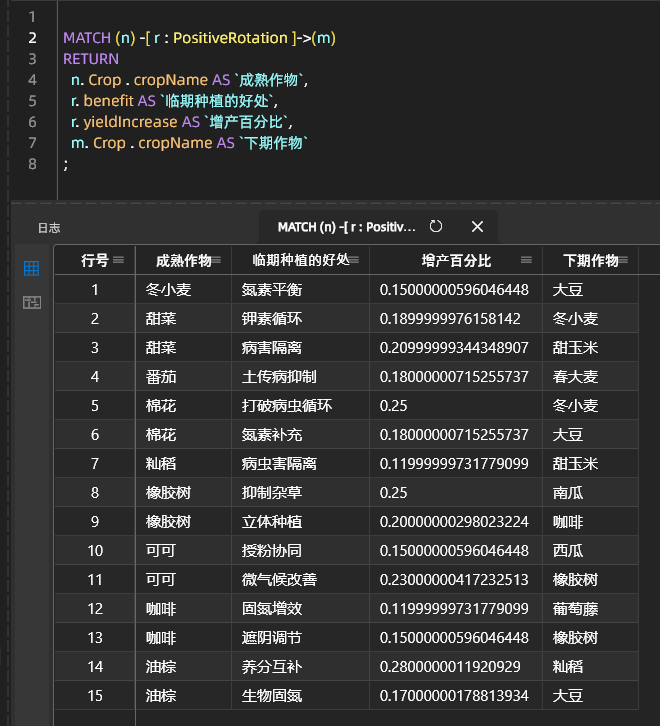
要約
結論 DeepSeekは知識グラフの構築と融合に優れており、実験でもその能力が実証されている:
- 情報の抽出は迅速かつ正確: DeepSeekは、テキストから重要な情報を素早く抽出し、準拠したnGQLスクリプトを生成し、エンティティ、関係、イベントを認識する強力な言語理解力を備えています。
- 知識を統合する能力が高い: DeepSeekは、複数の記事からの知識をうまく融合し、新しい記事に基づいてグラフを拡張・更新し、グラフの完全性と正確性を保証します。
- 何もないところから地図を作ることができる: トピック別にチャートを生成できる記事はない。生成プロセスにはいくつかの構文の不具合があるが、調整によって合格点のスクリプトが生成される。
- 細部を最適化する必要がある: DeepSeek によって生成されたスクリプトに、不正なコメントなどの構文の問題が発生することがあります。大量のノードを生成する場合、サーバの応答が遅くなることがあります。実際に使用する際は、これらの問題に注意する必要があります。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません