DeepSeek-OCR - DeepSeekオープンソース光学式文字認識モデル

DeepSeek-OCRとは何ですか?
DeepSeek-OCRは ディープシーク このチームのオープンソースの高度な光学式文字認識(OCR)モデルは、「文脈光学圧縮」技術を使ってテキストを画像に変換する。 トークン 効率的な長文テキスト処理のための圧縮と復号が可能です。技術的な特徴としては、高い圧縮率(10倍圧縮時で最大97%の精度)、視覚と言語の共同理解、多構造・多フォーマットのサポート(JPG、PNG、PDFなど、多言語認識)、エンドツーエンドのVLMアーキテクチャなどが挙げられます。長文テキスト、複雑な文書、多言語展開など、幅広いアプリケーションシナリオに対応します。長文、複雑な文書、多言語対応、ローカライズ展開など、幅広いアプリケーションシナリオに対応。高い効率性(A100-40Gグラフィックカード1枚で1日20万ページ以上の学習データ生成をサポート)、低遅延性(モバイルデバイスで毎秒15フレームのリアルタイム認識、待ち時間は100ミリ秒以下)、高い適応性(複雑なシナリオで最大98.7%の認識精度)など、性能面で大きな利点があります。開発者の便宜のため、オープンソースコードとモデルウェイトが公開されている。
DeepSeek-OCRの特徴
- コンテクスチュアル光圧縮テキストを画像に変換し、ビジュアルトークンで圧縮・復号化することで、10倍圧縮で最大97%の精度で効率的な長文テキスト処理を実現します。
- 視覚と言語の共同理解画像の視覚情報と言語モデルの理解力を組み合わせることで、テキストの意味やレイアウト構造を正確に把握する。
- マルチストラクチャー、マルチフォーマット対応幅広い画像形式(JPG、PNG、PDF)をサポートし、多言語認識も可能で、手書き、混合テキスト、図表とテキストが混在した文書にも対応できる。
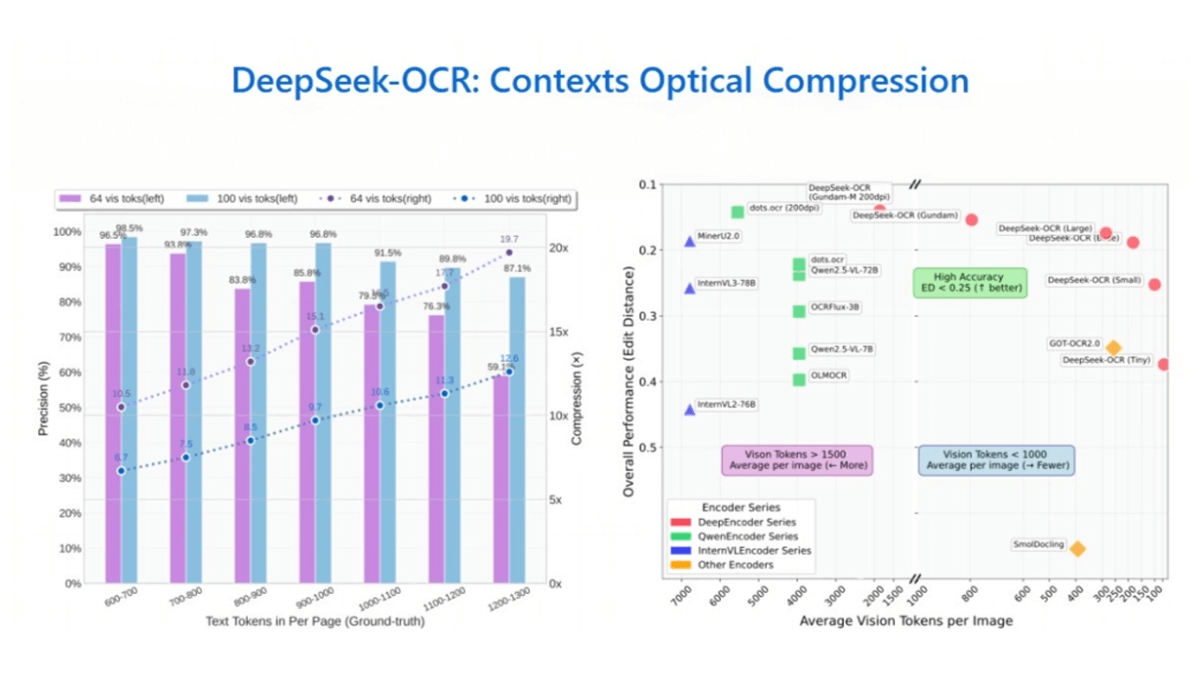
- 高圧縮比と高精度10倍圧縮の場合、OCR精度は97%に達します。圧縮率を20倍にしても、モデル精度は60%程度を維持できます。
- エンド・ツー・エンドVLMアーキテクチャDeepEncoderエンコーダーとDeepSeek3B-MoEデコーダーが使用され、エンコーダーは画像特徴の抽出、トークン化、視覚表現の圧縮を担当し、デコーダーは画像トークンとキューに基づいて必要な結果を生成する。
- 幅広いアプリケーション・シナリオTP3Tの最新バージョンの特徴は以下の通り:数千語の文書を1つの図に「シュート」することができ、97%の正確な削減を10分の1以下のコストで達成し、大規模な言語モデルにおける長いコンテキストの問題に対する効率的なソリューションを提供する;表や財務諸表のテキスト、チャート、図の情報を認識することができ、化学分子式、数式、幾何学的図形も読み取ることができる、中国語や英語を含む100以上の言語をサポートし、機密文書をサードパーティのクラウド・サービスに送信することを回避するローカル・デプロイメントをサポートする。
- 性能面での大きな利点A100-40Gグラフィックスカード1枚で、1日あたり20万ページ以上の大規模言語モデル/視覚言語モデル学習データ生成をサポート。モバイルデバイス上で、100ミリ秒以下のレイテンシで毎秒15フレームのリアルタイム認識が可能。マルチスケール動的特徴フュージョンモジュールとコンテキストアウェアデコーダにより、複雑なシーンにおけるモデルの認識精度は98.7%に達し、業界平均を6.4ポイント上回る。業界平均より6.4ポイント高い。
DeepSeek-OCRの主な利点
- 効率的なコンテクスト光圧縮テキストを画像化し、ビジュアルトークンを用いて圧縮・復号化することで、高い精度を維持しながら高い圧縮率を実現し、10倍圧縮で最大97%、20倍圧縮で約60%の精度を実現し、長文処理の問題を効果的に解決している。
- 視覚と言語の深い融合画像に含まれる視覚情報(位置、レイアウト、図形、表の境界など)と言語モデルの理解力を組み合わせることで、テキストの内容を認識するだけでなく、意味やレイアウト構造も正確に把握し、複雑な文書の処理を強化します。
- 幅広いフォーマットと言語サポート幅広い画像フォーマット(JPG、PNG、PDF)と100以上の言語をサポートし、手書き、混合テキスト、図表とテキストが混在した文書も扱えるので、幅広いシーンに対応できる。
- パワフルなパフォーマンスA100-40Gグラフィックスカード1枚で、1日あたり20万ページ以上の大規模言語モデル学習データ生成、モバイルデバイスでの毎秒15フレームのリアルタイム認識、100ミリ秒未満の待ち時間、複雑なシーンでの業界平均を大幅に上回る最大98.71 TP3Tの認識精度をサポートすることができます。
- 柔軟な展開サードパーティのクラウドサービスに機密文書を送信することを避け、データセキュリティを保護し、展開環境に対するさまざまなユーザーのニーズを満たすために、ローカライズされた展開をサポートします。
DeepSeek-OCRの公式サイトを教えてください。
- GitHubリポジトリ:: https://github.com/deepseek-ai/DeepSeek-OCR
- HuggingFaceモデルライブラリ:: https://huggingface.co/deepseek-ai/DeepSeek-OCR
- 技術論文:: https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
DeepSeek-OCRは誰のためのものですか?
- ビジネスユーザー効率的な長文処理と複雑な文書認識機能により、作業効率の向上と人件費の削減を実現します。
- (研究者DeepSeek-OCRの多言語サポートと正確な認識能力は、多言語文書、図表、数式などの複雑なコンテンツを扱う必要があることが多い学術研究に役立ちます。
- 教育者手書き認識機能とマルチフォーマット対応機能により、教育現場のニーズに応えます。
- 開発者オープンソース・コードとモデル・ウエイトは、開発者が自身のプロジェクトに統合し、カスタマイズされたOCRアプリケーションを開発し、アプリケーション・シナリオを拡張することを容易にします。
- 個人ユーザーDeepSeek-OCRは、文書内容の抽出、ノートの整理、外国語資料の翻訳など、個人のオフィスや学習効率を向上させるための便利で効率的なソリューションです。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません