
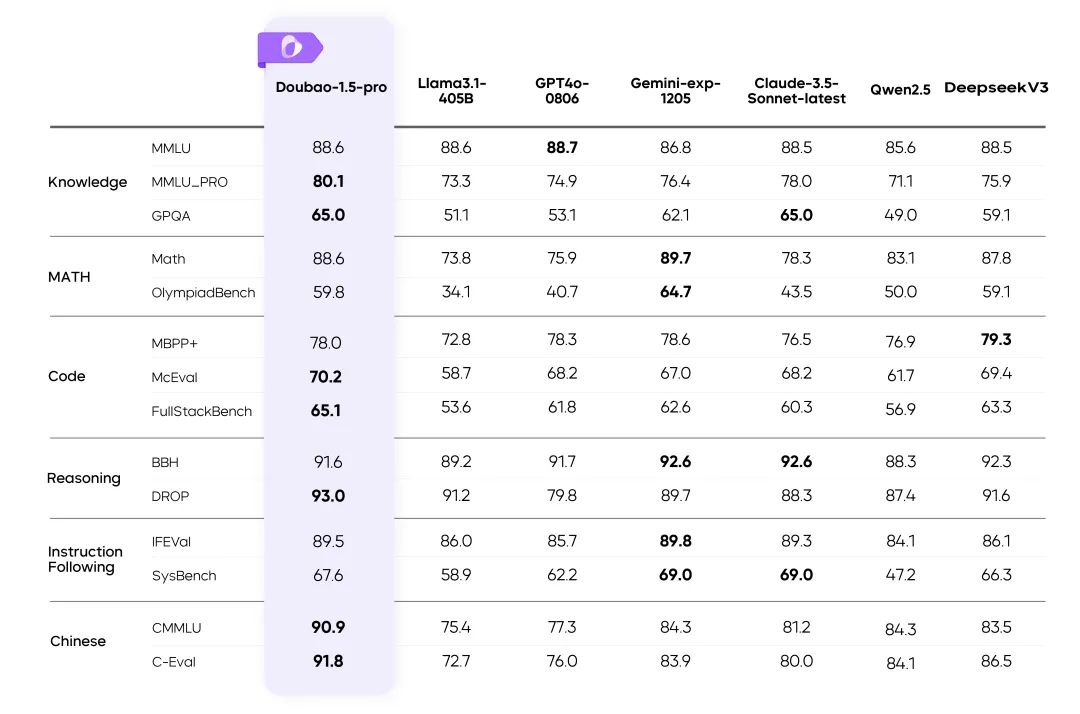
BrowseComp:OpenAI、AIネットワークの情報検索能力を評価する新しいベンチマークを発表

最近、OpenAIは ブラウズコンプ は、インターネットをナビゲートするAIエージェントの能力を評価するために設計された新しいベンチマークテストです。このベンチマークは、科学的発見からポップカルチャーまで幅広い領域をカバーする1,266の質問で構成されており、エージェントには、見つけにくく情報が絡み合った答えを探すために、オープンなウェブ環境を持続的にナビゲートすることが要求される。

図 1:OpenAI Deep Research の初期バージョンの、異なるブラウジング努力下での BrowseComp パフォーマンス。テスト時の計算量が増加するにつれて、精度はスムーズに向上する。
既存のベンチマークは "飽和状態 "にあり、BrowseCompはそのために開発された。
現在、SimpleQAのようないくつかの一般的なベンチマークは、孤立した単純な事実を検索するモデルの能力に焦点を当てている。ブラウジングツールを備えたGPT-4oのような高度なモデルの場合、そのようなタスクは単純すぎて性能の飽和に近づいています。つまり、SimpleQAのようなベンチマークは、発見するために深いネットワーク探索を必要とするような、より複雑な情報を扱う場合、モデルの真の能力を区別する上で、もはや効果的ではないということです。
このギャップを埋めるために、OpenAIはBrowseComp(「ブラウズ競争」の意)を開発した。このベンチマークは、1,266の難問で構成され、見つけるのが難しく、情報ポイントが絡み合っており、回答するために何十、何百ものウェブサイトを訪問する必要があるような質問を見つけるAIエージェントの能力を評価するように設計されています。チームはベンチマークをOpenAIの simple evals GitHubリポジトリを提供する。研究論文.
ブラウズコンプのデザインコンセプト
BrowseCompはもともと、既存のベンチマークテストのギャップを埋めるために設計されました。情報検索能力を評価するためのベンチマークは過去にも数多く存在したが、そのほとんどは既存の言語モデルで簡単に解決できる比較的単純な質問に基づいており、BrowseCompは答えを見つけるために詳細な検索と創造的な推論を必要とする複雑な質問に焦点を当てている。
以下はBrowseCompのサンプルです:
- 質問例11990年から1994年の間に、ブラジルの審判団と対戦したサッカーチームのうち、イエローカードが4枚(各チーム2枚ずつ)出され、そのうち3枚は後半に出された。
- 参考回答アイルランド対ルーマニア
- 質問例 2:時折第四の壁を破って視聴者と交流し、ユーモアで知られ、1960年代から1980年代にかけて放送されたテレビ番組で、エピソード数が50以下の架空の人物を挙げてください。
- 参考回答プラスチックマン
- 質問例 3筆頭著者がダートマス大学の学部卒、第4著者がペンシルバニア大学の学部卒で、2018年から2023年の間にEMNLPカンファレンスで発表された科学論文のタイトルを教えてください。
- 参考回答:: パン作りの基礎:パンの科学
BrowseComp独自の機能
- 挑戦的: BrowseCompの問題は、既存のモデルが短時間では解けないように注意深くデザインされています。問題を作成する際には、人間のトレーナーが何度も検証を行い、問題の難易度を確認しています。以下は、問題の難易度を評価するために使用される基準の一部です:
- 既存のモデルでは解決できないトレーナーは、GPT-4o(ブラウジングの有無にかかわらず)、OpenAI o1、および以前のバージョンのディープリサーチモデルが、これらの問題に対処できていないことを検証するよう求められました。
- 検索結果に表示されない:: 訓練生は、5つの簡単なグーグル検索を行い、その答えが検索結果の最初の数ページにないことをチェックするよう求められた。
- 人間は10分では解決できない。トレーナーには、他の人が10分以内に解けないような難しい問題を作ってもらいました。問題の中には、2人目のトレーナーが答えを見つけようとするものもあります。40%以上解かれた問題を作成したトレーナーには、問題を修正するよう求めました。

図2:BrowseCompにおけるトピックの分布。のヒントにより、BrowseCompにおけるトピックの分布が改善されている。 チャットGPT モデルは各質問のテーマを事後的に分類した。 - 検証が容易質問内容の難易度にもかかわらず、解答は通常短く明確で、参照解答によって容易に検証可能である。この設計により、ベンチマークは不公平になることなく、チャレンジングなものとなっている。
- 色どり:: BrowseCompの問題は、テレビ・映画、科学技術、芸術、歴史、スポーツ、音楽、ビデオゲーム、地理、政治など幅広い分野をカバーしています。この多様性により、テストは総合的なものとなっています。
モデル性能評価
ブラウズコンプのテストでは、既存のモデルの性能はまちまちであることが示されている:
- GPT-4o 歌で応える GPT-4.5 ブラウズ機能なしでは、精度はゼロに近い。ブラウズ機能を有効にした場合でも、GPT-4oの精度は0.6%から1.9%にしか向上していない。これは、ブラウズ機能だけでは複雑な問題を解決するには不十分であることを示している。
- オープンAI o1 このモデルはブラウズ機能を持たないが、強力な推論能力により9.91 TP3Tの精度を達成しており、これは内部知識推論によっていくつかの答えが得られることを示唆している。
- OpenAIディープリサーチ このモデルは、自律的にネットワークを検索し、複数のソースからの情報を評価・合成し、検索戦略を適応させることで、他の方法では解決できない問題に取り組むことができる。
詳細分析
1.校正エラー
ディープリサーチのモデルは、精度という点では良い結果を出していますが、キャリブレーション誤差が大きくなっています。これは、モデルが自信を持って不正解を与えるときに、モデル自身の不確実性の正確な評価が欠けていることを意味します。この現象は、ブラウズ機能を持つモデルで特に顕著であり、ウェブツールへのアクセスが不正解に対するモデルの自信を増大させる可能性を示唆しています。

図3:人間がBrowseCompの問題を解くのにかかった時間、またはあきらめた時間を示すヒストグラム。トレーナーは少なくとも2時間以上問題を解こうとした後でなければあきらめることは許されない。
2.コンピューティング・リソースの影響
テスト結果は、テスト中に計算リソースを増やすと、モデルの性能が徐々に向上することを示している。このことは、BrowseCompの問題にはかなりの量の検索と推論の労力が必要であり、計算資源を増やすことでモデルの性能が大幅に向上することを示唆している。

図 4: 並列サンプリングと信頼度ベースの投票を使用した場合の Deep Research の BrowseComp パフォーマンス。計算量を増やすことで、Best-of-N のモデル性能がさらに向上する。
3.アグリゲーション戦略
モデルの性能は、複数回の試行と異なる集計戦略(多数決、加重投票、ベストチョイスなど)15%~25%を使用することでさらに向上させることができます。ベストチョイス戦略の性能が最も高く、ディープリサーチモデルが正解を特定する精度が高いことを示しています。
評決を下す
BrowseCompのリリースは、AIエージェントの評価に新たな次元を提供する。これはモデルの情報検索能力をテストするだけでなく、複雑な問題に対する粘り強さや創造性も検証する。BrowseCompにおける既存モデルの性能はまだ改善する必要があるが、このベンチマークテストのリリースがAI分野の研究を前進させることは間違いない。
今後、より多くのモデルが採用され、技術が進歩するにつれて、ブラウズコンプのAIエージェントの性能は向上し続け、最終的には、より信頼性が高く、信用できるAIエージェントになることが期待されます。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません