
RAG avancé : architecture, technologie, applications et perspectives de développement
La génération augmentée par récupération (RAG) est devenue un cadre important dans le domaine de l'IA, améliorant considérablement la précision et la pertinence des grands modèles de langage (LLM) lors de la génération de réponses à l'aide de sources de connaissances externes. D'après Les banques de données Les données montrent que 60% des applications LLM dans l'entreprise utilisent Retrieval Augmented Generation (RAG), 30% utilisant un processus à plusieurs étapes. RAG a reçu beaucoup d'attention parce qu'il génère des réponses qui sont presque aussi bonnes que celles qui s'appuient uniquement sur l'affinement du modèle. Amélioration de la précision du 43%Il montre que la RAG un grand potentiel d'amélioration de la qualité et de la fiabilité du contenu généré par l'IA.
Cependant, les approches traditionnelles des RAG sont toujours confrontées à un certain nombre de défis pour répondre à des requêtes complexes, comprendre des contextes nuancés et traiter de multiples types de données. Ces limitations ont alimenté la création de RAG avancés visant à améliorer les capacités de l'IA en matière de recherche et de génération d'informations. Notamment.nombre d'entreprises Le RAG a été intégré dans environ 60%, ce qui démontre son importance et son efficacité dans les applications pratiques.
L'introduction des RAG multimodaux et des graphes de connaissances constitue l'une des principales avancées dans ce domaine. Les RAG multimodaux étendent la capacité des RAG à traiter non seulement du texte, mais aussi un large éventail de données, y compris des images, des sons et des vidéos. Cela permet aux systèmes d'IA d'être plus complets et d'avoir une meilleure compréhension du contexte lorsqu'ils interagissent avec les utilisateurs. Les graphes de connaissances, quant à eux, améliorent la cohérence et la précision du processus de recherche d'informations et du contenu généré grâce à une représentation structurée des connaissances.Microsoft Research suggère que le GraphRAG requis Jeton Le nombre est réduit de 26% à 97% par rapport aux autres méthodes, ce qui témoigne d'une plus grande efficacité et d'un coût de calcul réduit.
Ces avancées dans la technologie RAG ont permis des gains de performance significatifs dans de nombreux benchmarks et applications du monde réel. A titre d'exemple.carte des connaissances a atteint une précision de 86,31% dans le test RobustQA, ce qui dépasse largement les autres méthodes RAG. En outre, le test RobustQA a permis d'obtenir une précision de 86,31%.Sequeda et Allemang Plusieurs études de suivi ont montré que la combinaison d'ontologies réduisait le taux d'erreur 20%. Les entreprises ont également largement bénéficié de ces avancées, lesLinkedIn a fait état d'une réduction de 28,61 TP3T du temps de résolution de l'assistance à la clientèle grâce à l'approche RAG plus Knowledge Graph.
Dans cet article, nous nous pencherons sur l'évolution des RAG avancés, en explorant la complexité des RAG multimodaux et des RAG à base de graphes de connaissances, ainsi que leur efficacité à améliorer la recherche et la production d'informations basées sur l'IA. Nous discuterons également du potentiel de ces innovations à être appliquées dans différentes industries et des défis rencontrés dans la promotion et l'application de ces technologies.
- [Qu'est-ce que la génération augmentée par récupération (RAG) et pourquoi est-elle importante pour la modélisation des langues étendues (LLM) ?]
- [Types d'architecture RAG]
- [De la RAG de base à la RAG avancée : comment surmonter les limitations et améliorer les capacités].
- [Composants et processus avancés du système RAG dans l'entreprise].
- [Technologie RAG avancée]
- [Applications avancées des RAG et études de cas]
- [Comment construire des outils de dialogue à l'aide de RAG avancés ?]
- [Comment construire une application RAG avancée ?]
- [L'essor des graphes de connaissances dans les RAG avancés].
- [RAG avancé : génération améliorée d'horizons étendus grâce à la recherche multimodale].
- [Comment ZBrain, la plateforme de collaboration GenAI de LeewayHertz, se distingue des systèmes RAG avancés].
Advanced RAG : Architecture, Technology, Applications and Development Perspectives PDF Download :
RAG avancé : architecture, technologie, applications et perspectives de développement
Qu'est-ce que la génération augmentée par récupération (RAG) et pourquoi est-elle importante pour la modélisation des langues étendues (LLM) ?
Les grands modèles de langage (LLM) sont devenus essentiels aux applications de l'intelligence artificielle, qui s'appuient sur leur puissance pour tout ce qui concerne les assistants virtuels et les outils d'analyse de données sophistiqués. Cependant, malgré leurs capacités, ces modèles ont des limites lorsqu'il s'agit de fournir des informations actualisées et précises. C'est là que la Génération Augmentée de Récupération (RAG) apporte un complément puissant aux LLM.
Qu'est-ce que la Génération Augmentée de Récupération (GAR) ?
Retrieval Augmented Generation (RAG) est une technique avancée qui améliore les capacités de génération des grands modèles de langage (LLM) en intégrant des sources de connaissances externes.Les LLM sont formés sur de grands ensembles de données, avec des milliards de paramètres, et sont capables d'effectuer un large éventail de tâches telles que la réponse à des questions, la traduction linguistique et l'achèvement de textes.RAG va encore plus loin en se référant à des bases de connaissances faisant autorité et spécifiques à un domaine pour améliorer la pertinence, la précision et l'utilité du contenu généré sans qu'il soit nécessaire de former à nouveau le modèle. Les RAG vont plus loin en référençant des bases de connaissances faisant autorité et spécifiques à un domaine afin d'améliorer la pertinence, la précision et l'utilité du contenu généré sans qu'il soit nécessaire de réentraîner le modèle. Cette approche rentable et efficace est idéale pour les entreprises qui cherchent à optimiser leurs systèmes d'IA.
Comment RAG (Retrieval Augmented Generation) peut-il aider la modélisation des langues (LLM) à résoudre le problème principal ?
Les grands modèles de langage (LLM) jouent un rôle clé dans le développement de chatbots intelligents et d'autres applications de traitement du langage naturel (NLP). Grâce à un entraînement intensif, ils tentent de fournir des réponses précises dans divers contextes. Toutefois, les LLM présentent eux-mêmes certaines lacunes et sont confrontés à de nombreux défis :
- message d'erreurLes réponses inexactes peuvent être générées lorsque les connaissances en matière de LLM sont insuffisantes.
- informations obsolètesLes données d'apprentissage sont statiques, de sorte que les réponses générées par le modèle peuvent être obsolètes.
- source non autoriséeLes réponses générées peuvent parfois provenir de sources peu fiables, ce qui nuit à la crédibilité.
- confusion terminologiqueLes sources d'information : L'utilisation incohérente d'une même terminologie par différentes sources de données peut facilement conduire à des malentendus.
RAG aborde ces questions en fournissant au LLM une source de données externe faisant autorité pour améliorer la précision et la nature en temps réel des réponses du modèle. Les points suivants expliquent pourquoi le RAG est si important pour le développement du LLM :
- Améliorer la précision et la pertinenceRAG extrait les informations les plus récentes et les plus pertinentes de sources faisant autorité afin de garantir que les réponses du modèle sont plus précises et plus pertinentes par rapport au contexte actuel, étant donné que les données d'apprentissage sont statiques.
- Dépasser les limites des données statiquesLe RAG permet au LLM d'accéder aux données les plus récentes, ce qui permet de maintenir l'information à jour et pertinente.
- Renforcer la confiance des utilisateursLe RAG renforce la transparence et la confiance des utilisateurs en permettant au LLM de citer des sources et de fournir des informations vérifiables.
- réduction des coûtsLe RAG offre une alternative plus rentable au réentraînement du LLM avec de nouvelles données, offrant une alternative rentable au réentraînement de l'ensemble du modèle à l'aide de sources de données externes, ce qui rend les techniques d'IA avancées plus largement disponibles.
- Un contrôle et une flexibilité accrus pour les développeursLe RAG offre aux développeurs une plus grande liberté pour spécifier avec souplesse les sources de connaissances, s'adapter rapidement aux changements d'exigences et assurer un traitement approprié des informations sensibles afin de soutenir un large éventail d'applications et d'améliorer l'efficacité des systèmes d'intelligence artificielle.
- Fournir des réponses personnaliséesAlors que les LLM traditionnels ont tendance à donner des réponses trop générales, RAG combine les LLM avec les bases de données internes de l'organisation, les informations sur les produits et les manuels d'utilisation pour fournir des réponses plus spécifiques et plus pertinentes, améliorant ainsi considérablement l'expérience de l'assistance et de l'interaction avec les clients.
RAG (Retrieval Augmented Generation) permet à LLM de générer des réponses plus précises, en temps réel et contextualisées en intégrant des bases de connaissances externes. Ceci est vital pour les organisations qui s'appuient sur l'IA, du service client à l'analyse de données, RAG améliore non seulement l'efficacité mais aussi la confiance des utilisateurs dans les systèmes d'IA.
Types d'architecture RAG
La génération augmentée par récupération (RAG) représente une avancée majeure dans la technologie de l'IA, en combinant des modèles de langage avec des systèmes de récupération de connaissances externes. Cette approche hybride améliore la capacité de l'IA à générer des réponses en obtenant des informations détaillées et pertinentes à partir de vastes sources de données externes. Comprendre les différents types d'architectures RAG nous aide à mieux tirer parti de leurs avantages en fonction de nos besoins spécifiques. Voici un aperçu détaillé des trois principales architectures RAG :
1. le RAG naïf
Naive RAG est la méthode de génération d'amélioration de la recherche la plus basique. Son principe est simple : le système extrait des éléments d'information pertinents de la base de connaissances en fonction de la requête de l'utilisateur, puis utilise ces éléments d'information comme contexte pour générer la réponse par le biais de la modélisation linguistique.
Caractéristiques :
- mécanisme de récupérationLa méthode de recherche simple est utilisée pour extraire des blocs de documents pertinents à partir d'un index préétabli, généralement par le biais d'une correspondance de mots-clés ou d'une similarité sémantique de base.
- l'intégration contextuelleLes documents récupérés sont fusionnés avec la requête de l'utilisateur et introduits dans le modèle linguistique pour générer une réponse. Cette fusion fournit un contexte plus riche au modèle pour générer des réponses plus pertinentes.
- flux de traitementLe système suit un processus fixe : extraire, scinder, générer. Le modèle ne modifie pas les informations extraites, mais les utilise directement pour générer des réponses.
2. le RAG avancé
Le RAG avancé est basé sur le RAG naïf et utilise des techniques plus avancées pour améliorer la précision de la recherche et la pertinence contextuelle. Il surmonte certaines des limites de Naive RAG en combinant des mécanismes avancés pour mieux traiter et utiliser les informations contextuelles.
Caractéristiques :
- Extraction amélioréeAméliorer la qualité et la pertinence des informations extraites en utilisant des stratégies de recherche avancées telles que l'expansion de la requête (ajout de termes pertinents à la requête initiale) et la recherche itérative (optimisation des documents en plusieurs étapes).
- Optimisation du contexteLe modèle linguistique est plus précis et plus contextuel lorsque l'on se concentre sur les éléments les plus pertinents du contexte grâce à des techniques telles que le mécanisme d'attention.
- stratégie d'optimisationLes stratégies d'optimisation telles que l'évaluation de la pertinence et l'amélioration du contexte sont utilisées pour garantir que le modèle capture les informations les plus pertinentes et de meilleure qualité pour générer des réponses.
3. le RAG modulaire
Le RAG modulaire est l'architecture RAG la plus souple et la plus personnalisable. Elle décompose le processus d'extraction et de génération en modules distincts, ce qui permet de l'optimiser et de le remplacer en fonction des besoins d'applications spécifiques.
Caractéristiques :
- Conception modulaireDécomposer le processus RAG en différents modules tels que l'expansion de la requête, la recherche, le réordonnancement et la génération. Chaque module peut être optimisé indépendamment et remplacé à la demande.
- Personnalisation flexibleElle permet un degré élevé de personnalisation, les développeurs pouvant essayer différentes configurations et techniques à chaque étape pour trouver la meilleure solution. La méthodologie fournit des solutions personnalisées pour une variété de scénarios d'application.
- Intégration et adaptationL'architecture est capable d'intégrer des fonctionnalités supplémentaires telles qu'un module de mémoire (pour enregistrer les interactions passées) ou un module de recherche (pour extraire des données de moteurs de recherche ou de graphes de connaissances). Cette adaptabilité permet au système RAG d'être adapté de manière flexible pour répondre à des besoins spécifiques.
Il est essentiel de comprendre ces types et ces caractéristiques pour sélectionner et mettre en œuvre l'architecture RAG la plus appropriée.
Du RAG de base au RAG avancé : dépasser les limites et améliorer les capacités
La génération augmentée par récupération (RAG) est utilisée dans le cadre de l'analyse de l'information. Traitement du langage naturel (NLP) Il est devenu une méthode très efficace pour combiner la recherche d'informations et la génération de textes afin de produire des résultats plus précis et contextualisés. Cependant, avec l'évolution de la technologie, les premiers systèmes RAG "de base" ont révélé certaines faiblesses, ce qui a conduit à l'émergence de versions plus avancées. L'évolution du RAG de base vers le RAG avancé signifie que nous surmontons progressivement ces défauts et que nous améliorons considérablement les capacités globales du système RAG.
Limites du RAG de base

Le cadre RAG sous-jacent est une première tentative de combiner la recherche et la génération pour le NLP. Bien que cette approche soit innovante, elle se heurte encore à certaines limites :
- Méthodes de recherche simplesLa plupart des systèmes RAG de base s'appuient sur une simple correspondance de mots-clés, une approche qui rend difficile la compréhension des nuances et du contexte de la requête et qui permet donc de récupérer des informations insuffisamment ou partiellement pertinentes.
- Difficulté à comprendre le contexteIl est difficile pour ces systèmes de comprendre correctement le contexte d'une requête d'utilisateur. Par exemple, le système RAG sous-jacent peut extraire des documents contenant les mots-clés d'une requête, mais ne parvient pas à saisir la véritable intention ou le contexte de l'utilisateur, ce qui l'empêche de répondre précisément à ses besoins.
- Capacité limitée à traiter des requêtes complexesLes systèmes RAG de base sont peu performants lorsqu'ils sont confrontés à des requêtes complexes ou à plusieurs étapes. Leurs limites en matière de compréhension du contexte et de recherche précise les empêchent de traiter efficacement les problèmes complexes.
- Base de connaissances statiqueLe système RAG sous-jacent repose sur une base de connaissances statique et ne dispose pas d'un mécanisme de mise à jour dynamique ; les informations peuvent devenir obsolètes au fil du temps, ce qui affecte la précision et la pertinence de la réponse.
- Absence d'optimisation itérativeLe RAG sous-jacent ne dispose pas d'un mécanisme d'optimisation basé sur le retour d'information, ne peut pas améliorer ses performances par un apprentissage itératif et stagne au fil du temps.
Passage au niveau avancé du RAG
Avec l'évolution de la technologie, des solutions plus sophistiquées sont devenues disponibles pour remédier aux lacunes des systèmes RAG de base. Les systèmes RAG avancés permettent de relever ces défis de plusieurs manières :
- Algorithmes de recherche plus complexesLes systèmes RAG avancés utilisent des techniques sophistiquées telles que la recherche sémantique et la compréhension du contexte, qui peuvent aller au-delà de la correspondance des mots clés pour comprendre le sens réel d'une requête, améliorant ainsi la pertinence des résultats obtenus.
- Intégration contextuelle amélioréeCes systèmes intègrent des pondérations de contexte et de pertinence pour intégrer les résultats de la recherche afin de s'assurer que non seulement les informations sont exactes, mais qu'elles sont également adaptées au contexte et qu'elles répondent mieux à la requête et à l'intention de l'utilisateur.
- Optimisation itérative et mécanismes de rétroaction: :
Le système Advanced RAG utilise un processus d'optimisation itératif qui améliore continuellement la précision et la pertinence au fil du temps en intégrant les commentaires des utilisateurs. - Mise à jour dynamique des connaissances: :
Le système avancé RAG est capable d'actualiser dynamiquement la base de connaissances, d'introduire en permanence les informations les plus récentes et de garantir que le système reflète toujours les dernières tendances et évolutions. - Compréhension complexe du contexte: :
S'appuyant sur des techniques NLP plus avancées, les systèmes RAG avancés ont une compréhension plus approfondie de la requête et du contexte, et sont capables d'analyser les nuances sémantiques, les indices contextuels et l'intention de l'utilisateur afin de générer des réponses plus cohérentes et plus pertinentes.
Améliorations du système RAG avancé sur les composants
L'évolution du RAG de base vers le RAG avancé signifie que le système apporte des améliorations significatives dans chacun des quatre composants clés : le stockage, la récupération, l'amélioration et la génération.
- stockLes systèmes RAG avancés rendent la recherche d'informations plus efficace en stockant les données par le biais d'une indexation sémantique, organisée en fonction de la signification des données plutôt que de simples mots-clés.
- récupérer (données)La recherche sémantique et la recherche contextuelle étant améliorées, le système ne se contente pas de trouver des données pertinentes, mais comprend également l'intention et le contexte de l'utilisateur.
- renforcerLe module d'amélioration du système Advanced RAG génère des réponses plus personnalisées et plus précises grâce à un mécanisme d'apprentissage et d'adaptation dynamique qui est optimisé en permanence en fonction des interactions avec l'utilisateur.
- générantLe module Génération utilise une compréhension contextuelle sophistiquée et une optimisation itérative pour permettre la génération de réponses plus cohérentes et contextuelles.
L'évolution des RAG de base vers les RAG avancés constitue un bond en avant significatif. En utilisant des techniques de recherche sophistiquées, une meilleure intégration contextuelle et des mécanismes d'apprentissage dynamique, les systèmes de RAG avancés fournissent une approche plus précise et contextuelle de la recherche et de la génération d'informations. Cette avancée améliore la qualité des interactions avec l'IA et jette les bases d'une communication plus raffinée et plus efficace.
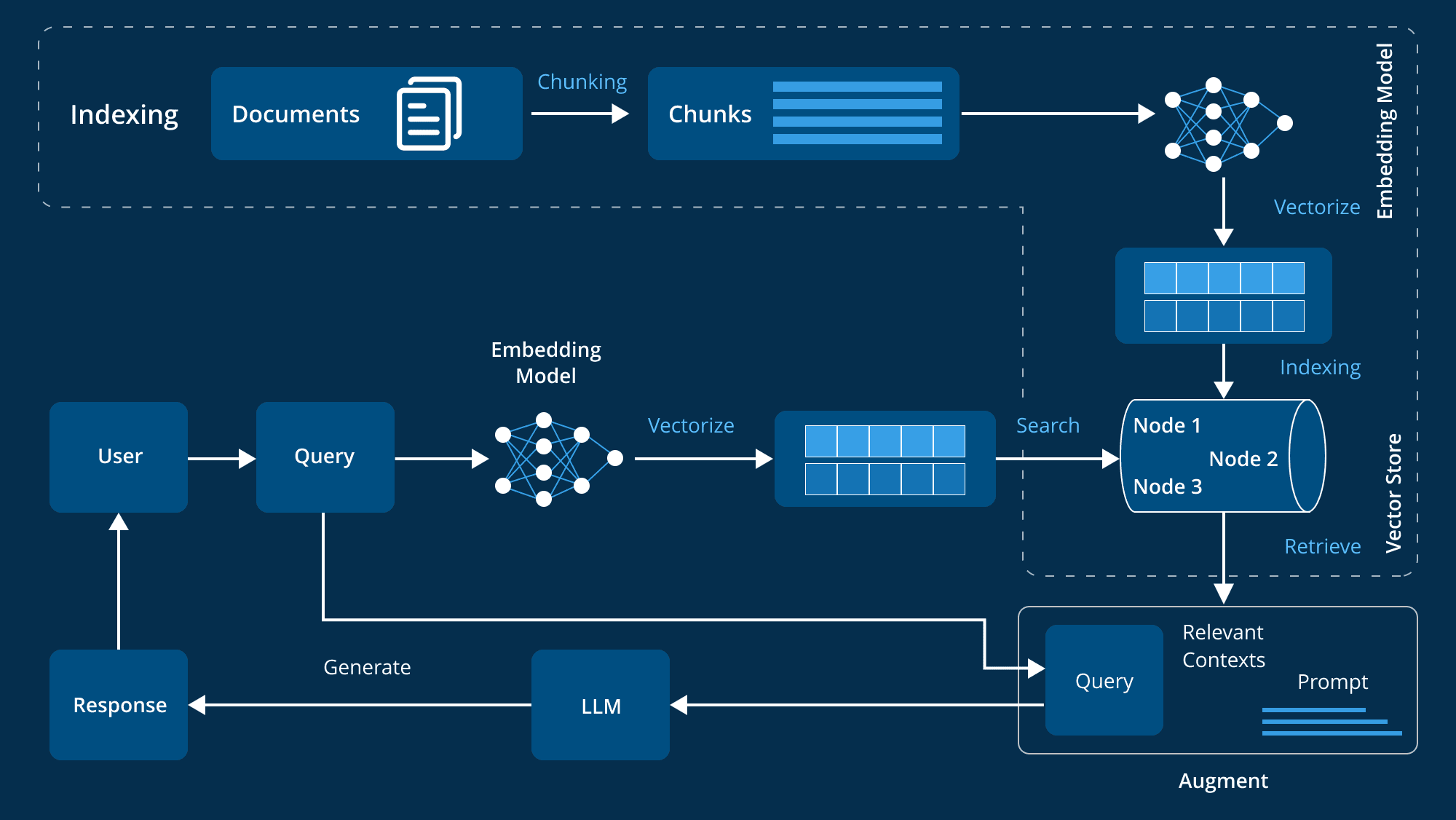
Composants et flux de travail d'un système RAG avancé au niveau de l'entreprise
Dans le domaine des applications d'entreprise, il existe un besoin croissant de systèmes capables d'extraire et de générer intelligemment des informations pertinentes. Les systèmes RAG (Retrieval Augmented Generation) sont apparus comme des solutions puissantes qui combinent la précision de la recherche d'informations avec la puissance générative des grands modèles de langage (LLM). Cependant, pour construire un système RAG avancé qui réponde aux besoins complexes d'une organisation, son architecture doit être soigneusement conçue.
Composants de l'architecture de base
Un système avancé de Génération d'Augmentation de la Récupération (RAG) nécessite de multiples composants de base qui fonctionnent ensemble pour assurer l'efficacité et l'efficience du système. Ces composants couvrent la gestion des données, le traitement des entrées des utilisateurs, la recherche et la production d'informations, ainsi que l'amélioration continue des performances du système. Voici une description détaillée de ces composants clés :
- Préparation et gestion des données
La base d'un système RAG avancé est la préparation et la gestion des données, ce qui implique un certain nombre d'éléments clés :
- Découpage des données et vectorisation : Les données sont décomposées en morceaux plus faciles à gérer et converties en représentations vectorielles, ce qui est essentiel pour améliorer l'efficacité et la précision de la recherche.
- Génération de métadonnées et de résumés : La création de métadonnées et de résumés permet une référence rapide et réduit le temps de recherche.
- Nettoyage des données : Il est essentiel de s'assurer que les données sont propres, organisées et exemptes de bruit pour garantir l'exactitude des informations extraites.
- Traite les formats de données complexes : La capacité du système à gérer des formats de données complexes garantit une utilisation efficace des différents types de données de l'organisation.
- Gestion de la configuration des utilisateurs : La personnalisation est importante dans un environnement d'entreprise, et en gérant les configurations des utilisateurs, les réponses peuvent être adaptées aux besoins individuels, optimisant ainsi l'expérience de l'utilisateur.
- Traitement des données de l'utilisateur
Le module de traitement des données de l'utilisateur joue un rôle essentiel en veillant à ce que le système puisse traiter les demandes de manière efficace :
- Authentification de l'utilisateur : La sécurité des systèmes d'entreprise est très importante et les mécanismes d'authentification garantissent que seuls les utilisateurs autorisés peuvent utiliser le système RAG.
- Optimiseur de requêtes : La structure de la requête de l'utilisateur peut ne pas convenir à la recherche et l'optimiseur optimise la requête pour améliorer la pertinence et la précision de la recherche.
- Mécanismes de protection des entrées : Les mécanismes de protection protègent le système contre les intrants étrangers ou malveillants, garantissant ainsi la fiabilité du processus de recherche.
- Utilisation de l'historique des conversations : En se référant aux dialogues précédents, le système est mieux à même de comprendre et de répondre à la requête actuelle, en générant des réponses plus précises et contextualisées.
- système de recherche d'informations
Le système de recherche d'informations est au cœur de l'architecture RAG et est chargé de récupérer les informations les plus pertinentes à partir d'un index de données prétraitées :
- Indexation des données : Une technologie d'indexation efficace garantit une recherche rapide et précise des informations, et des méthodes d'indexation avancées permettent de traiter de grandes quantités de données d'entreprise.
- Réglage des hyperparamètres : Les paramètres du modèle de recherche sont ajustés pour optimiser ses performances et garantir la récupération des résultats les plus pertinents.
- Réorganisation des résultats : Après la recherche, le système réorganise les résultats pour s'assurer que les informations les plus pertinentes sont affichées en premier, ce qui améliore la qualité des réponses.
- Intégrer l'optimisation : En ajustant les vecteurs d'intégration, le système est en mesure de mieux faire correspondre la requête avec les données pertinentes, améliorant ainsi la précision de la recherche.
- Problèmes hypothétiques liés à la technologie HyDE : La génération de paires de questions et de réponses hypothétiques à l'aide de la technologie HyDE (Hypothetical Document Embedding) permet de mieux gérer la recherche d'informations lorsque la requête et le document sont asymétriques.
- Production et traitement de l'information
Lorsque des informations pertinentes sont recherchées, le système doit produire une réponse cohérente et adaptée au contexte :
- Génération de réponses : À l'aide de grands modèles linguistiques (LLM) avancés, le module synthétise les informations recherchées en une réponse complète et précise.
- Protection de la production et audit : Afin de s'assurer que les réponses générées répondent aux spécifications, le système utilise diverses règles pour les examiner.
- Mise en cache des données : Les données ou les réponses fréquemment consultées sont mises en cache, ce qui réduit le temps de recherche et améliore l'efficacité du système.
- Génération de la personnalisation : Le système personnalise le contenu généré en fonction des besoins et de la configuration de l'utilisateur afin de garantir la pertinence et l'exactitude de la réponse.
- Retour d'information et optimisation du système
Les systèmes RAG avancés devraient être capables d'auto-apprentissage et d'amélioration, et les mécanismes de retour d'information sont essentiels pour une optimisation continue :
- Commentaires des utilisateurs : En recueillant et en analysant les commentaires des utilisateurs, le système peut identifier les domaines à améliorer et évoluer pour mieux répondre aux besoins des utilisateurs.
- Optimisation des données : Sur la base des commentaires des utilisateurs et des nouvelles découvertes, les données du système sont continuellement optimisées pour garantir la qualité et la pertinence de l'information.
- Produire des évaluations de la qualité : Le système évalue régulièrement la qualité du contenu généré en vue d'une optimisation continue.
- Surveillance du système : Contrôler en permanence les performances du système pour s'assurer qu'il fonctionne efficacement et qu'il peut répondre aux changements de la demande ou des modèles de données.
Intégration aux systèmes d'entreprise
Pour qu'un système RAG avancé fonctionne au mieux dans un environnement organisationnel, une intégration transparente avec les systèmes existants est essentielle :
- Intégration des systèmes CRM et ERP : L'interfaçage des systèmes RAG avancés avec les systèmes de gestion de la relation client (CRM) et de planification des ressources de l'entreprise (ERP) permet un accès efficace aux données clés de l'entreprise et leur utilisation, améliorant ainsi la capacité à générer des réponses précises et adaptées au contexte.
- API et architecture microservices : L'utilisation d'API flexibles et d'une architecture microservices permet au système RAG d'être facilement intégré dans les logiciels d'entreprise existants, ce qui permet des mises à niveau et des extensions modulaires.
Sécurité et conformité
La sécurité et la conformité sont particulièrement importantes en raison de la sensibilité des données de l'entreprise :
- Protocoles de sécurité des données : Un cryptage solide des données et des mesures de traitement sécurisé des données sont utilisés pour protéger les informations sensibles et garantir la conformité avec les réglementations sur la protection des données telles que le GDPR.
- Contrôle d'accès et authentification : Mettre en œuvre des mécanismes sécurisés d'authentification des utilisateurs et de contrôle d'accès basé sur les rôles afin de garantir que seul le personnel autorisé peut accéder au système ou le modifier.
Évolutivité et optimisation des performances
Les systèmes RAG de classe entreprise doivent être évolutifs et capables de maintenir de bonnes performances sous des charges élevées :
- Architecture native dans le nuage (Cloud Native Architecture) : L'utilisation d'une architecture "cloud-native" offre la flexibilité de faire évoluer les ressources à la demande, en garantissant une haute disponibilité du système et l'optimisation des performances.
- Équilibrage des charges et gestion des ressources : Des stratégies efficaces d'équilibrage de la charge et de gestion des ressources aident le système à gérer de grands volumes de demandes d'utilisateurs et de données tout en maintenant des performances optimales.
Analyse et rapports
Les systèmes RAG avancés devraient également disposer de solides capacités d'analyse et d'établissement de rapports :
- Contrôle des performances : La surveillance en temps réel des performances du système, des interactions avec les utilisateurs et de la santé du système grâce à l'intégration d'outils d'analyse avancés est essentielle pour maintenir l'efficacité du système.
- Intégration de l'intelligence économique : L'intégration avec des outils de veille stratégique peut fournir des informations précieuses pour faciliter la prise de décision et conduire la stratégie de l'entreprise.
Les systèmes RAG avancés au niveau de l'entreprise représentent une combinaison de technologies d'IA de pointe, de mécanismes robustes de traitement des données, d'infrastructures sécurisées et évolutives, et de capacités d'intégration transparentes. En combinant ces éléments, les organisations sont en mesure de construire des systèmes de GCR capables de récupérer et de générer des informations de manière efficace, tout en faisant partie intégrante du système technologique de l'entreprise. Ces systèmes n'apportent pas seulement une valeur commerciale significative, mais améliorent également les processus de prise de décision et renforcent l'efficacité opérationnelle globale.
Technologie avancée RAG
Les systèmes avancés de récupération et de génération augmentée (RAG) englobent une série d'outils technologiques conçus pour améliorer l'efficacité et la précision à tous les stades du traitement. Ces systèmes RAG avancés sont capables de mieux gérer les données et de fournir des réponses plus précises et contextualisées en appliquant des technologies avancées à différents stades du processus, depuis l'indexation et la transformation des requêtes jusqu'à la récupération et la génération. Voici quelques-unes des techniques avancées utilisées pour optimiser chaque étape du processus RAG :
1. l'index
L'indexation est un processus clé qui améliore la précision et l'efficacité des systèmes de grands modèles linguistiques (LLM). L'indexation est plus qu'un simple stockage de données ; elle implique l'organisation systématique et l'optimisation des données pour garantir que l'information est facile à accéder et à comprendre, tout en conservant un contexte important. Une indexation efficace permet de retrouver les données avec précision et efficacité, ce qui permet aux gestionnaires de l'apprentissage tout au long de la vie de fournir des réponses pertinentes et précises. Parmi les techniques utilisées dans le processus d'indexation, on peut citer
Technique 1 : Optimisation des blocs de texte grâce à l'optimisation des blocs
L'objectif de l'optimisation des blocs est d'ajuster la taille et la structure des blocs de texte de manière à ce qu'ils ne soient ni trop grands ni trop petits, tout en conservant le contexte, ce qui permet d'améliorer la recherche.
Technique 2 : Conversion du texte en vecteurs à l'aide de modèles d'intégration avancés
Après avoir créé des blocs de texte, l'étape suivante consiste à convertir ces blocs en représentations vectorielles. Ce processus transforme le texte en vecteurs numériques qui capturent sa signification sémantique. Des modèles tels que BGE-large ou la famille d'intégration E5 sont efficaces pour représenter les nuances du texte. Ces représentations vectorielles sont cruciales pour la recherche ultérieure et l'appariement sémantique.
Technique 3 : Amélioration de la concordance sémantique par l'intégration d'un réglage fin
L'objectif du réglage fin de l'intégration est d'améliorer la compréhension sémantique des données indexées par le modèle d'intégration, et donc d'améliorer la précision de la correspondance entre les informations extraites et la requête de l'utilisateur.
Technique 4 : Améliorer l'efficacité de la recherche grâce à des représentations multiples
Les techniques de multi-représentation convertissent les documents en unités de recherche légères, telles que les résumés, afin d'accélérer le processus de recherche et d'améliorer la précision lorsque l'on travaille avec des documents volumineux.
Technique 5 : Utilisation d'index hiérarchiques pour organiser les données
L'indexation hiérarchique améliore la recherche en structurant les données en plusieurs niveaux, du plus détaillé au plus général, grâce à des modèles tels que RAPTOR, qui fournissent des informations contextuelles à la fois larges et précises.
Technique 6 : Amélioration de la recherche de données grâce à l'ajout de métadonnées
Les techniques d'ajout de métadonnées ajoutent des informations supplémentaires à chaque bloc de données afin d'améliorer les capacités d'analyse et de classification, ce qui rend la recherche de données plus systématique et contextuelle.
2. conversion des requêtes
La transformation des requêtes vise à optimiser la saisie de l'utilisateur et à améliorer la qualité de la recherche d'informations. En utilisant les LLM, le processus de transformation est capable de rendre les requêtes complexes ou ambiguës plus claires et plus spécifiques, améliorant ainsi l'efficacité et la précision globales de la recherche.
Technique 1 : Utilisation de HyDE (Hypothetical Document Embedding) pour améliorer la clarté des requêtes
HyDE améliore la pertinence et la précision de la recherche d'informations en générant des données d'hypothèse pour renforcer la similarité sémantique entre les questions et le contenu de référence.
Technique 2 : Simplifier les requêtes complexes avec des requêtes en plusieurs étapes
Les requêtes en plusieurs étapes décomposent les questions complexes en sous-questions plus simples, récupèrent les réponses à chaque sous-question séparément et regroupent les résultats pour fournir une réponse plus précise et plus complète.
Technique 3 : Améliorer le contexte à l'aide d'indices de retour en arrière
La technique du backtracking hinting génère une requête générale plus large à partir de la requête originale complexe, de sorte que le contexte aide à fournir une base pour la requête spécifique, améliorant ainsi la réponse finale en combinant les résultats de la requête originale et de la requête plus large.
Technique 4 : Amélioration de la récupération grâce à la réécriture de la requête
La technique de réécriture des requêtes utilise le LLM pour reformuler la requête initiale afin d'améliorer la recherche. LangChain et LlamaIndex utilisent tous deux cette technique, LlamaIndex fournissant une implémentation particulièrement puissante qui améliore considérablement la recherche.
3. l'acheminement des requêtes
Le rôle de l'acheminement des requêtes est d'optimiser le processus de recherche en envoyant la requête à la source de données la plus appropriée en fonction des caractéristiques de la requête, en veillant à ce que chaque requête soit traitée par le composant du système le plus approprié.
Technique 1 : Routage logique
Le routage logique optimise la recherche en analysant la structure de la requête pour sélectionner la source de données ou l'index le plus approprié. Cette approche garantit que la requête est traitée par la source de données la mieux à même de fournir une réponse précise.
Technologie 2 : Routage sémantique
Le routage sémantique dirige la requête vers la source de données ou l'index approprié en analysant la signification sémantique de la requête. Il améliore la précision de la recherche en comprenant le contexte et la signification de la requête, en particulier pour les questions complexes ou nuancées.
4. les techniques de pré-recherche et d'indexation des données
L'optimisation avant extraction améliore la qualité et la possibilité d'extraction des informations dans un index de données ou une base de connaissances. Les méthodes d'optimisation spécifiques varient en fonction de la nature, de la source et de la taille des données. Par exemple, l'augmentation de la densité de l'information peut générer des réponses plus précises avec moins de jetons, améliorant ainsi l'expérience de l'utilisateur et réduisant les coûts. Toutefois, les méthodes d'optimisation qui fonctionnent pour un système peuvent ne pas fonctionner pour d'autres. Les grands modèles de langage (LLM) fournissent des outils permettant de tester et d'ajuster ces optimisations, ce qui permet d'adopter des approches personnalisées pour améliorer la recherche dans différents domaines et applications.
Technique 1 : Utilisation de LLM pour augmenter la densité de l'information
Une étape fondamentale dans l'optimisation d'un système RAG consiste à améliorer la qualité des données avant qu'elles ne soient indexées. En utilisant les LLM pour le nettoyage, l'étiquetage et le résumé des données, la densité d'information peut être augmentée, ce qui permet d'obtenir des résultats plus précis et plus efficaces dans le traitement des données.
Technique 2 : Recherche d'index hiérarchique
Les recherches par indexation hiérarchique simplifient le processus de recherche en créant des résumés de documents comme première couche de filtres. Cette approche multicouche garantit que seules les données les plus pertinentes sont prises en compte au stade de la recherche, ce qui améliore l'efficacité et la précision de la recherche.
Technique 3 : Améliorer la symétrie de la recherche grâce à des paires hypothétiques de questions-réponses
Pour remédier à l'asymétrie entre les requêtes et les documents, cette technique utilise des LLM pour générer des paires hypothétiques de questions-réponses à partir de documents. En intégrant ces paires de questions-réponses dans la recherche, le système peut mieux répondre à la requête de l'utilisateur, améliorant ainsi la similarité sémantique et réduisant les erreurs de recherche.
Technique 4 : Déduplication avec LLMs
Les informations en double peuvent être à la fois bénéfiques et préjudiciables à un système RAG. L'utilisation de LLM pour dédupliquer des blocs de données optimise l'indexation des données, réduit le bruit et augmente la probabilité de générer des réponses exactes.
Technique 5 : Tester et optimiser les stratégies de découpage en morceaux
Une stratégie de découpage efficace est essentielle pour la récupération. En effectuant des tests A/B avec différentes tailles de morceaux et différents taux de chevauchement, il est possible de trouver l'équilibre optimal pour un cas d'utilisation particulier. Cela permet de conserver un contexte suffisant sans disperser ou diluer les informations pertinentes.
Technique 6 : Utilisation d'un index à fenêtre coulissante
L'indexation par fenêtre coulissante garantit que les informations contextuelles importantes ne sont pas perdues entre les segments par le chevauchement des blocs de données au cours du processus d'indexation. Cette approche maintient la continuité des données et améliore la pertinence et la précision des informations recherchées.
Technique 7 : Augmenter la granularité des données
L'amélioration de la granularité des données est principalement obtenue en appliquant des techniques de nettoyage des données afin de supprimer les informations non pertinentes et de ne conserver dans l'index que le contenu le plus précis et le plus récent. Cela améliore la qualité de la recherche et garantit que seules les informations pertinentes sont prises en compte.
Technique 8 : Ajout de métadonnées
L'ajout de métadonnées, telles que la date, l'objet ou la section, peut améliorer la précision de la recherche, ce qui permet au système de se concentrer plus efficacement sur les données les plus pertinentes et d'améliorer la recherche dans son ensemble.
Technique 9 : Optimisation de la structure de l'index
L'optimisation de la structure d'indexation implique le redimensionnement des morceaux et l'utilisation de stratégies d'indexation multiples, telles que l'extraction par fenêtre de phrase, afin d'améliorer la manière dont les données sont stockées et extraites. En intégrant des phrases individuelles tout en maintenant une fenêtre contextuelle, cette approche permet une extraction plus riche et plus précise sur le plan contextuel pendant l'inférence.
5. les techniques de récupération
Dans la phase d'extraction, le système recueille les informations nécessaires pour répondre à la requête de l'utilisateur. Une technologie de recherche avancée garantit que le contenu récupéré est à la fois complet et contextuel, ce qui constitue une base solide pour les étapes de traitement ultérieures.
Technique 1 : Optimisation des requêtes de recherche avec les LLM
Les LLM optimisent la requête de l'utilisateur pour qu'elle corresponde mieux aux exigences du système de recherche, qu'il s'agisse d'une recherche simple ou d'une requête de dialogue complexe. Cette optimisation garantit que le processus de recherche est plus ciblé et plus efficace.
Technique 2 : Correction de l'asymétrie requête-document avec HyDE
En générant des documents de réponse hypothétiques, la technique HyDE améliore la similarité sémantique dans la recherche et résout l'asymétrie entre les requêtes courtes et les documents longs.
TECHNIQUE 3 : Mise en œuvre du routage des requêtes ou des modèles de décision RAG
Dans les systèmes utilisant des sources de données multiples, l'acheminement des requêtes optimise l'efficacité de la recherche en orientant les recherches vers la base de données appropriée. Le modèle de décision RAG optimise encore ce processus en déterminant quand une recherche est nécessaire pour économiser des ressources lorsque le modèle de langage étendu peut répondre de manière indépendante.
Technique 4 : Exploration en profondeur avec des chercheurs récursifs
Un chercheur récursif effectue d'autres requêtes sur la base du résultat précédent et convient pour explorer en profondeur des données pertinentes afin d'obtenir des informations détaillées ou complètes.
Technique 5 : Optimiser la sélection des sources de données à l'aide d'extracteurs d'itinéraires
Le Routing Retriever utilise le LLM pour sélectionner dynamiquement la source de données ou l'outil d'interrogation le plus approprié afin d'améliorer l'efficacité du processus de recherche en fonction du contexte de l'interrogation.
Technique 6 : Génération automatique de requêtes à l'aide d'un "auto-retriever".
L'Auto-Retriever utilise le LLM pour générer automatiquement des filtres de métadonnées ou des instructions d'interrogation, ce qui simplifie le processus d'interrogation de la base de données et optimise la recherche d'informations.
Technique 7 : Combinaison des résultats à l'aide d'un chercheur de fusion
Le Fusion Retriever combine les résultats de plusieurs requêtes et index pour fournir une vue complète et non redondante de l'information, garantissant ainsi une recherche exhaustive.
Technique 8 : Agrégation de contextes de données à l'aide de chercheurs de fusion automatique
L'Auto Merge Retriever combine plusieurs segments de données en un seul contexte unifié, améliorant ainsi la pertinence et l'exhaustivité des informations en intégrant des contextes plus restreints.
Technique 9 : Affiner le modèle d'intégration
En affinant le modèle d'intégration pour le rendre plus spécifique au domaine, on améliore la capacité à traiter la terminologie spécialisée. Cette approche améliore la pertinence et la précision des informations recherchées en alignant plus étroitement le contenu spécifique au domaine.
Technique 10 : Mise en œuvre de l'intégration dynamique
Les embeddings dynamiques vont au-delà des représentations statiques en adaptant les vecteurs de mots au contexte, ce qui permet une compréhension plus nuancée de la langue. Cette approche, telle que le modèle embeddings-ada-02 d'OpenAI, capture les significations contextuelles de manière plus précise et fournit donc des résultats de recherche plus exacts.
Technique 11 : Utilisation de la recherche hybride
La recherche hybride combine la recherche vectorielle et la correspondance traditionnelle des mots-clés, permettant à la fois la similarité sémantique et la reconnaissance précise des termes. Cette approche est particulièrement efficace dans les scénarios où une reconnaissance précise des termes est nécessaire, ce qui garantit une recherche complète et précise.
6. les techniques de post-récupération
Une fois que le contenu pertinent a été acquis, la phase de post-récupération se concentre sur la manière de rassembler ce contenu de manière efficace. Cette étape consiste à fournir des informations contextuelles précises et concises au modèle linguistique étendu (LLM), en veillant à ce que le système dispose de tous les détails nécessaires pour générer des réponses cohérentes et précises. La qualité de cette intégration détermine directement la pertinence et la clarté du résultat final.
Technique 1 : Optimiser les résultats de recherche en les réorganisant
Après l'extraction, le modèle de réorganisation réorganise les résultats de la recherche pour placer les documents les plus pertinents plus près de la requête, améliorant ainsi la qualité des informations fournies au mécanisme d'apprentissage tout au long de la vie et, par conséquent, la génération de la réponse finale. Le réarrangement ne réduit pas seulement le nombre de documents à fournir au mécanisme d'apprentissage tout au long de la vie, mais agit également comme un filtre pour améliorer la précision du traitement linguistique.
Technique 2 : Optimisation des résultats de recherche par compression avec des indices contextuels
Le LLM peut filtrer et compresser les informations récupérées avant de générer l'invite finale. La compression permet au LLM de se concentrer davantage sur les informations critiques en réduisant les informations de fond redondantes et en supprimant les bruits parasites. Cette optimisation améliore la qualité de la réponse, en la concentrant sur les détails importants. Des cadres comme LLMLingua améliorent encore ce processus en supprimant les jetons superflus, ce qui rend les messages-guides plus concis et plus efficaces.
Technique 3 : Notation et filtrage des documents récupérés en corrigeant les erreurs de grammaire et d'orthographe
Avant que le contenu ne soit introduit dans le LLM, les documents doivent être sélectionnés et filtrés afin d'éliminer les documents non pertinents ou moins précis. Cette technique garantit que seules des informations pertinentes et de haute qualité sont utilisées, améliorant ainsi la précision et la fiabilité de la réponse. Le RAG correctif utilise un modèle tel que T5-Large pour évaluer la pertinence des documents récupérés et filtre ceux qui sont inférieurs à un seuil prédéfini, ce qui garantit que seules les informations utiles sont prises en compte dans la génération de la réponse finale.
7. les technologies génératives
Au cours de la phase de génération, les informations extraites sont évaluées et réorganisées afin d'identifier le contenu le plus important. À ce stade, la technologie avancée consiste à sélectionner les détails clés qui augmentent la pertinence et la fiabilité de la réponse. Ce processus garantit que le contenu généré ne répond pas seulement à la requête, mais qu'il est également étayé par les données extraites de manière significative.
Technique 1 : Réduire le bruit grâce à des conseils sur la chaîne de pensée
Les messages-guides de la chaîne de pensée aident le LLM à gérer les informations d'arrière-plan bruyantes ou non pertinentes, augmentant ainsi la probabilité de générer une réponse précise même s'il y a des interférences dans les données.
TECHNIQUE 2 : Auto-réflexion sur le système par le biais de l'auto-RAG
La méthode Self-RAG consiste à apprendre au modèle à utiliser des jetons de réflexion pendant la génération afin qu'il puisse évaluer et améliorer ses propres résultats en temps réel, en choisissant la meilleure réponse sur la base de la véracité et de la qualité.
Technique 3 : Ignorer les arrière-plans superflus grâce à un réglage fin
Le système RAG a été spécialement affiné pour améliorer la capacité du LLM à ignorer les éléments extérieurs, garantissant ainsi que seules les informations pertinentes influencent la réponse finale.
Technique 4 : Amélioration de la robustesse du LLM face à des contextes non pertinents grâce au raisonnement en langage naturel
L'intégration de modèles d'inférence du langage naturel permet de filtrer les informations contextuelles non pertinentes en comparant le contexte récupéré avec la réponse générée, garantissant ainsi que seules les informations pertinentes influencent le résultat final.
Technique 5 : Contrôle de l'extraction des données avec FLARE
FLARE (Flexible Language Modelling Adaptation for Retrieval Enhancement) est une approche basée sur l'ingénierie des indices qui garantit que le LLM ne récupère les données que lorsque cela est nécessaire. Il adapte continuellement la requête et vérifie les mots-clés à faible probabilité qui déclenchent la récupération de documents pertinents afin d'améliorer la précision de la réponse.
Technique 6 : Amélioration de la qualité des réponses avec ITER-RETGEN
ITER-RETGEN (Iterative Retrieval-Generation) améliore la qualité des réponses en exécutant de manière itérative le processus de génération. Chaque itération utilise le résultat précédent comme contexte pour récupérer des informations plus pertinentes, améliorant ainsi continuellement la qualité et la pertinence de la réponse finale.
Technique 7 : Clarifier les questions à l'aide de l'arbre de clarification (ToC)
ToC génère récursivement des questions spécifiques pour clarifier les ambiguïtés de la requête initiale. Cette approche affine le processus de questions-réponses en évaluant et en affinant en permanence la question initiale, ce qui permet d'obtenir une réponse finale plus détaillée et plus précise.
8. évaluation
Dans les technologies avancées de récupération et de génération augmentée (RAG), le processus d'évaluation est essentiel pour garantir que les informations récupérées et synthétisées sont à la fois exactes et pertinentes par rapport à la requête de l'utilisateur. Le processus d'évaluation se compose de deux éléments clés : les scores de qualité et les capacités requises.
L'évaluation de la qualité se concentre sur la mesure de l'exactitude et de la pertinence du contenu :
- Contexte Pertinence. Évaluer l'applicabilité des informations extraites ou générées dans le contexte spécifique de la requête. S'assurer que la réponse est exacte et adaptée aux besoins de l'utilisateur.
- Fidélité de la réponse. Vérifier que les réponses générées reflètent fidèlement les données extraites et n'introduisent pas d'erreurs ou d'informations trompeuses. Cela est essentiel pour maintenir la fiabilité des résultats du système.
- Pertinence de la réponse. Évaluer si la réponse générée répond directement et efficacement à la requête de l'utilisateur, en s'assurant que la réponse est à la fois utile et cohérente avec l'essentiel de la question.
Les capacités requises sont celles que le système doit posséder pour fournir des résultats de haute qualité :
- Résistance au bruit. Mesurer la capacité du système à filtrer les données parasites ou bruyantes pour s'assurer que ces perturbations n'affectent pas la qualité de la réponse finale.
- Rejet négatif. Tester l'efficacité du système dans l'identification et l'exclusion des informations erronées ou non pertinentes de la contamination du résultat généré.
- Intégration de l'information. Évaluer la capacité du système à intégrer plusieurs éléments d'information pertinents dans une réponse cohérente et complète qui donne à l'utilisateur une réponse complète.
- Robustesse contrefactuelle. Vérifier les performances du système dans le cadre de scénarios hypothétiques ou contrefactuels afin de s'assurer que les réponses restent précises et fiables même lorsqu'il s'agit de questions spéculatives.
Ensemble, ces éléments d'évaluation garantissent que le système Advanced RAG fournit une réponse à la fois précise et pertinente, solide, fiable et adaptée aux besoins spécifiques de l'utilisateur.
Technologies supplémentaires
Moteur de chat : amélioration des capacités de dialogue dans le système RAG
L'intégration d'un moteur de chat dans un système avancé de génération augmentée de recherche (RAG) améliore la capacité du système à traiter les questions de suivi et à maintenir le contexte du dialogue, comme le fait la technologie traditionnelle des chatbots. Différentes mises en œuvre offrent différents niveaux de complexité :
- Moteur de chat contextuel : Cette approche sous-jacente guide la réponse du modèle de langage large (LLM) en récupérant le contexte pertinent pour la requête de l'utilisateur, y compris les discussions précédentes. Le dialogue est ainsi cohérent et adapté au contexte.
- Concentration et modes contextuels : Il s'agit d'une approche plus avancée qui condense les journaux de discussion et les derniers messages de chaque interaction en une requête optimisée. Cette requête affinée prend en compte le contexte pertinent et le combine avec le message original de l'utilisateur afin de fournir au LLM une réponse plus précise et contextualisée.
Ces mises en œuvre contribuent à améliorer la cohérence et la pertinence du dialogue dans le système RAG et offrent différents niveaux de complexité en fonction des besoins.
Citations de références : s'assurer que les sources sont exactes
Il est important de garantir l'exactitude des références, en particulier lorsque plusieurs sources contribuent aux réponses générées. Cela peut se faire de plusieurs manières :
- Étiquetage direct de la source : La configuration d'une tâche dans une invite de modèle linguistique (LLM) exige que la source soit directement étiquetée dans la réponse générée. Cette approche permet à la source originale d'être clairement étiquetée.
- Technique de correspondance floue : Les techniques de correspondance floue, telles que celles utilisées par LlamaIndex, sont employées pour aligner des parties du contenu généré avec des blocs de texte dans l'index source. La correspondance floue améliore la précision du contenu et garantit qu'il reflète les informations de la source.
En appliquant ces stratégies, la précision et la fiabilité des citations de référence peuvent être considérablement améliorées, ce qui garantit que les réponses générées sont à la fois crédibles et bien étayées.
Agents de la Génération Augmentée de Récupération (RAG)
Les agents jouent un rôle important dans l'amélioration des performances des systèmes RAG (Retrieval Augmented Generation) en fournissant des outils et des fonctionnalités supplémentaires au Large Language Model (LLM) afin d'étendre sa portée. Introduits à l'origine par le biais de l'API LLM, ces agents permettent aux LLM de tirer parti de fonctions de code externes, d'API et même d'autres LLM pour améliorer leur fonctionnalité.
Une application importante des agents est la recherche multi-documents. Par exemple, les assistants récents de l'OpenAI démontrent des avancées dans ce concept. Ces assistants augmentent les LLM traditionnels en intégrant des fonctionnalités telles que des journaux de discussion, des magasins de connaissances, des interfaces de téléchargement de documents et des API d'appels de fonctions qui convertissent le langage naturel en commandes exploitables.
L'utilisation d'agents s'étend également à la gestion de documents multiples, où chaque document est traité par un agent dédié, comme les résumés et les quiz. Un agent central de haut niveau supervise ces agents spécifiques aux documents, achemine les requêtes et consolide les réponses. Cette configuration permet d'effectuer des comparaisons et des analyses complexes entre plusieurs documents, démontrant ainsi des techniques avancées de RAG.
Réponse à Synthesizer : élaborer la réponse finale
La dernière étape du processus RAG consiste à synthétiser le contexte récupéré et la requête initiale de l'utilisateur en une réponse. Outre la combinaison directe du contexte avec la requête et son traitement par le LLM, des approches plus raffinées sont possibles :
- Optimisation itérative : Le fait de diviser le contexte récupéré en plusieurs parties permet d'optimiser la réponse grâce à de multiples interactions avec le LLM.
- Résumé contextuel : La compression d'un grand nombre d'éléments contextuels pour les faire tenir dans les questions du programme LLM garantit que les réponses restent ciblées et pertinentes.
- Génération de réponses multiples : Générer des réponses multiples à partir de différents segments du contexte, puis intégrer ces réponses dans une réponse unifiée.
Ces techniques améliorent la qualité et la précision des réponses du système RAG, démontrant le potentiel des méthodes avancées dans la synthèse des réponses.
L'adoption de ces technologies RAG avancées peut améliorer considérablement les performances et la fiabilité du système. En optimisant le processus à chaque étape, du prétraitement des données à la génération de réponses, les entreprises peuvent créer des applications d'IA plus précises, plus efficaces et plus puissantes.
Applications et cas avancés de RAG
Les systèmes RAG (Retrieval Augmented Generation) sont utilisés dans un large éventail de domaines pour améliorer l'analyse des données, la prise de décision et l'interaction avec l'utilisateur grâce à leurs puissantes capacités de traitement et de génération de données. De l'étude de marché à l'assistance à la clientèle en passant par la création de contenu, les systèmes RAG avancés ont démontré des avantages significatifs dans un certain nombre de domaines. Les applications spécifiques de ces systèmes dans différents domaines sont décrites ci-dessous :
1. Étude de marché et analyse concurrentielle
- intégration des donnéesLe système RAG est capable d'intégrer et d'analyser des données provenant de diverses sources telles que les médias sociaux, les articles de presse et les rapports de l'industrie.
- Identification des tendancesEn traitant de grandes quantités de données, le système RAG est capable d'identifier les tendances émergentes sur le marché et les changements dans le comportement des consommateurs.
- Aperçu des concurrentsLe système fournit des stratégies concurrentielles détaillées et des analyses de performance pour aider les entreprises à s'auto-évaluer et à s'étalonner.
- des informations exploitablesLes entreprises peuvent utiliser ces rapports pour la planification stratégique et la prise de décision.
2. Soutien et interaction avec les clients
- Des réponses adaptées au contexteLe système RAG extrait les informations pertinentes de la base de connaissances afin de fournir des réponses précises et contextualisées aux clients.
- Réduire la charge de travailL'automatisation des problèmes courants soulage l'équipe d'assistance manuelle, ce qui lui permet de traiter des problèmes plus complexes.
- Service personnaliséLe système personnalise les réponses et les interactions pour répondre aux besoins individuels en analysant l'historique et les préférences du client.
- Améliorer l'expérience interactiveLes services d'assistance de haute qualité améliorent la satisfaction des clients et renforcent les relations avec eux.
3. Conformité réglementaire et gestion des risques
- Analyse réglementaireLe système RAG analyse et interprète les documents juridiques et les orientations réglementaires afin de garantir la conformité.
- l'identification des risquesLe système identifie rapidement les risques potentiels de conformité en comparant les politiques internes avec les réglementations externes.
- Recommandations de conformitéLes entreprises ont besoin de conseils pratiques pour combler les lacunes en matière de conformité et réduire les risques juridiques.
- Des rapports efficacesLes rapports de conformité : Générer des rapports et des résumés de conformité faciles à auditer et à inspecter.
4. Développement de produits et innovation
- Analyse du retour d'information des clientsLe système RAG : Le système RAG analyse les commentaires des clients afin d'identifier les problèmes communs et les points douloureux.
- Aperçu du marchéLes activités de recherche et de développement : Suivre les tendances émergentes et les besoins des clients pour orienter le développement des produits.
- Propositions innovantesLes services d'assistance technique et les services d'aide à la gestion des ressources humaines sont des services d'assistance technique et d'aide à la gestion des ressources humaines.
- positionnement concurrentielLes objectifs sont les suivants : aider les entreprises à développer des produits qui répondent aux besoins du marché et qui se distinguent de la concurrence.
5. Analyse et prévisions financières
- intégration des donnéesLe système RAG intègre des données financières, des conditions de marché et des indicateurs économiques pour une analyse complète.
- Analyse des tendancesLes objectifs sont les suivants : identifier les modèles et les tendances des marchés financiers afin de faciliter les prévisions et les décisions d'investissement.
- conseil en investissementLes services de conseil en investissement : fournir des conseils pratiques sur les opportunités d'investissement et les facteurs de risque.
- planification stratégiqueLes services d'appui à la prise de décision financière stratégique grâce à des prévisions précises et à des recommandations fondées sur des données.
6. Recherche sémantique et recherche d'information efficace
- compréhension du contexteLe système RAG effectue une recherche sémantique en comprenant le contexte et la signification des requêtes de l'utilisateur.
- Résultats pertinents: : Améliorer l'efficacité de la recherche en extrayant les informations les plus pertinentes et les plus précises à partir de grandes quantités de données.
- gagner du temps: Optimiser le processus de recherche de données et réduire le temps consacré à la recherche d'informations.
- Améliorer la précisionLe système de recherche par mot-clé : Il fournit des résultats de recherche plus précis que les méthodes traditionnelles de recherche par mot-clé.
7. Améliorer la création de contenu
- Intégration des tendancesLe système RAG utilise les données les plus récentes pour s'assurer que le contenu généré est conforme aux tendances actuelles du marché et aux intérêts du public.
- Génération automatique de contenuLes avantages de cette solution : générer automatiquement des idées de contenu et des ébauches en fonction des thèmes et des publics ciblés.
- Renforcer la participationLes services d'information et de communication : Générer un contenu plus attrayant et plus pertinent afin d'améliorer l'interaction avec les utilisateurs.
- mise à jour en temps utileLe contenu de l'information doit refléter les derniers événements et développements du marché et rester d'actualité.
8. résumé du texte
- Points fortsLe système RAG permet de résumer efficacement de longs documents, en distillant les points clés et les conclusions importantes.
- gagner du tempsLes rapports sont rédigés en anglais et en français, ce qui permet d'économiser du temps de lecture grâce aux résumés concis des rapports destinés aux cadres et aux dirigeants très occupés.
- se concentrer surLes messages clés : mettre en évidence les messages clés pour aider les décideurs à saisir rapidement les points essentiels.
- Efficacité accrue dans la prise de décisionLe but est de fournir des informations pertinentes d'une manière facile à comprendre afin d'améliorer l'efficacité de la prise de décision.
9. Système avancé de questions-réponses
- Des réponses précisesLe système RAG extrait des données d'un large éventail de sources d'information pour générer des réponses précises à des questions complexes.
- Amélioration de l'accès: : Améliorer l'accès à l'information dans divers domaines, tels que les soins de santé ou la finance.
- sensible au contexteLes réponses : fournir des réponses ciblées basées sur les besoins et les questions spécifiques de l'utilisateur.
- Questions complexes: Traiter des questions complexes en intégrant de multiples sources d'information.
10. Agents de dialogue et chatbots
- informations contextuellesLe système RAG améliore l'interaction entre les chatbots et les assistants virtuels en fournissant des informations contextuelles pertinentes.
- Améliorer la précisionLes réponses des agents de dialogue doivent être précises et informatives.
- l'assistance aux utilisateurs: : Améliorer l'expérience de l'assistance à l'utilisateur en fournissant une interface de dialogue intelligente et réactive.
- Nature interactive: : Récupérer des données pertinentes en temps réel pour rendre les interactions plus naturelles et plus attrayantes.
11. recherche d'informations
- Recherche avancéeAméliorer la précision des moteurs de recherche grâce aux capacités de recherche et de génération de RAG.
- Génération de fragments d'informationLes services d'aide à la décision : Générer des extraits d'information efficaces pour améliorer l'expérience de l'utilisateur.
- Résultats de recherche améliorés: : Enrichir les résultats de recherche avec des réponses générées par le système RAG afin d'améliorer la résolution des requêtes.
- moteur de connaissancesLes données de l'entreprise : utiliser les données de l'entreprise pour répondre à des questions internes, telles que les politiques de ressources humaines ou les questions de conformité, afin de faciliter l'accès à l'information.
12. Recommandations personnalisées
- Analyse des données relatives aux clientsLes produits : générer des recommandations de produits personnalisées en analysant les achats antérieurs et les avis des clients.
- Améliorer l'expérience d'achat: : Améliorer l'expérience d'achat des utilisateurs en leur recommandant des produits en fonction de leurs préférences personnelles.
- augmenter les recettesLes services d'assistance technique : recommander des produits pertinents en fonction du comportement des clients afin d'augmenter les ventes.
- l'adéquation au marché: : Adapter le contenu recommandé aux tendances actuelles du marché pour répondre à l'évolution des besoins des clients.
13. achèvement du texte
- complément contextuel: Le système RAG complète des parties du texte de manière appropriée au contexte.
- accroître l'efficacité: : Fournir des compléments précis pour simplifier des tâches telles que la rédaction de courriels ou de codes.
- Améliorer la productivitéLes avantages : réduire le temps nécessaire à la réalisation des tâches d'écriture et de codage et augmenter la productivité.
- Maintenir la cohérenceLes compléments textuels doivent être cohérents avec le contenu et le ton existants.
14. l'analyse des données
- Intégration complète des donnéesLe système RAG intègre des données provenant de bases de données internes, de rapports de marché et de sources externes afin de fournir une vue d'ensemble et une analyse approfondie.
- prévisions précisesLes prévisions : améliorer la précision des prévisions en analysant les données les plus récentes, les tendances et les informations historiques.
- Insight DiscoveryLes tâches suivantes sont à accomplir: : analyser des ensembles de données complets afin d'identifier et d'évaluer de nouvelles opportunités et de fournir des informations précieuses pour la croissance et l'amélioration.
- Recommandations fondées sur des données: : Fournir des recommandations fondées sur des données en analysant des ensembles de données complets afin de soutenir la prise de décision stratégique et d'améliorer la qualité générale de la prise de décision.
15. tâche de traduction
- recherche d'une traduction: : Récupérer des traductions pertinentes dans des bases de données pour faciliter les tâches de traduction.
- Génération de contexte: : Générer des traductions cohérentes basées sur le contexte et en référence au corpus récupéré.
- Améliorer la précision: Utilisation de données provenant de sources multiples pour améliorer la précision des traductions.
- accroître l'efficacitéLa traduction : Rationaliser le processus de traduction grâce à l'automatisation et à la génération en fonction du contexte.
16. Analyse du retour d'information des clients
- analyse complèteLes compétences en matière de gestion des ressources humaines sont les suivantes: : analyser le retour d'information provenant de différentes sources afin d'acquérir une compréhension globale de l'opinion et des problèmes des clients.
- perspicacitéLes services d'aide à la décision : Fournir des informations détaillées qui révèlent les thèmes récurrents et les points douloureux des clients.
- intégration des donnéesLes résultats de l'analyse des données de la base de données interne, des médias sociaux et des évaluations sont intégrés pour une analyse complète.
- Prise de décision informativeLes services de l'entreprise : : Prendre des décisions plus rapides et plus intelligentes en se basant sur les commentaires des clients afin d'améliorer les produits et les services.
Ces applications illustrent le large éventail de possibilités offertes par les systèmes RAG avancés et démontrent leur capacité à améliorer l'efficacité, la précision et la compréhension. Qu'il s'agisse d'améliorer l'assistance à la clientèle, de renforcer les études de marché ou de rationaliser l'analyse des données, les systèmes RAG avancés fournissent des solutions inestimables qui favorisent la prise de décisions stratégiques et l'excellence opérationnelle.
Construire des outils de dialogue avec un RAG avancé
Les outils d'IA de dialogue jouent un rôle essentiel dans les interactions modernes avec les utilisateurs, en fournissant un retour d'information vivant et rapide sur une variété de plates-formes. Nous pouvons porter les capacités de ces outils à un tout autre niveau en intégrant un système avancé de génération augmentée de recherche (RAG), qui combine une recherche d'informations puissante avec des techniques de génération avancées pour garantir que les dialogues sont à la fois informatifs et qu'ils maintiennent un flux de communication naturel. Lorsqu'il est intégré à un outil d'IA de dialogue, le système RAG peut fournir aux utilisateurs des réponses précises et riches en contexte tout en maintenant une cadence de dialogue naturelle. Cette section explore la manière dont RAG peut être utilisé pour construire des outils de dialogue avancés, en soulignant les éléments clés sur lesquels il faut se concentrer lors de la construction de ces systèmes et comment les rendre efficaces et pratiques dans des applications du monde réel.
Conception du processus de dialogue
Au cœur de tout outil de dialogue se trouve le flux de dialogue, c'est-à-dire les étapes par lesquelles le système traite les données de l'utilisateur et génère des réponses. Pour les outils avancés basés sur les RAG, la conception du flux de dialogue doit être soigneusement planifiée afin de tirer pleinement parti des capacités d'extraction du système RAG et de la génération de modèles linguistiques. Ce flux se compose généralement de plusieurs étapes clés :
Évaluation et recadrage des problèmes: :
- Le système évalue d'abord la question posée par l'utilisateur et détermine si elle doit être reformatée pour fournir le contexte nécessaire à une réponse précise. Si la question est trop vague ou manque de détails essentiels, le système peut la reformater en une requête autonome, en veillant à ce que toutes les informations nécessaires soient incluses.
Contrôle de pertinence et routage: :
- Une fois la question correctement formatée, le système recherche les données pertinentes dans le magasin de vecteurs (une base de données contenant des informations indexées). Si des informations pertinentes sont trouvées, la question est transmise à l'application RAG, qui récupère les informations nécessaires pour générer une réponse.
- S'il n'y a pas d'informations pertinentes dans la mémoire vectorielle, le système doit décider s'il continue avec la réponse générée par le modèle linguistique seul, ou s'il demande au système RAG de déclarer qu'une réponse satisfaisante ne peut pas être fournie.
Générer une réponse: :
- En fonction des décisions prises à l'étape précédente, le système utilise les données extraites pour générer des réponses détaillées ou s'appuie sur la connaissance du modèle linguistique et l'historique du dialogue pour répondre à l'utilisateur. Cette approche garantit que l'outil est capable de traiter des problèmes du monde réel tout en s'adaptant à des dialogues plus décontractés et ouverts.
Optimiser les processus de dialogue en utilisant des mécanismes de prise de décision
Un aspect important de la construction d'outils de dialogue RAG avancés est la mise en œuvre de mécanismes de prise de décision qui contrôlent le flux du dialogue. Ces mécanismes aident le système à décider intelligemment quand il doit récupérer des informations, quand il doit s'appuyer sur des capacités génératives et quand il doit informer l'utilisateur qu'aucune donnée pertinente n'est disponible. Grâce à ces décisions, l'outil peut devenir plus flexible et s'adapter à divers scénarios de dialogue.
- Point de décision 1 : Réinventer ou continuer ?
Le système décide d'abord si la question de l'utilisateur peut être traitée telle quelle ou si elle doit être remodelée. Cette étape permet de s'assurer que le système comprend l'intention de l'utilisateur et qu'il dispose de tout le contexte nécessaire pour permettre une recherche ou une génération efficace avant de générer une réponse. - Point de décision 2 : Récupérer ou générer ?
Dans le cas où un remodelage est nécessaire, le système détermine s'il existe des informations pertinentes dans la base de données vectorielles. Si des données pertinentes sont trouvées, le système utilisera le RAG pour la recherche et la génération de réponses. Dans le cas contraire, le système doit décider s'il doit s'appuyer uniquement sur le modèle linguistique pour générer la réponse. - Point de décision 3 : Informer ou interagir ?
Si ni le magasin de vecteurs ni le modèle linguistique ne peuvent fournir une réponse satisfaisante, le système informe l'utilisateur qu'aucune information pertinente n'est disponible, ce qui préserve la transparence et la crédibilité du dialogue.
Comment concevoir des messages-guides efficaces pour les RAG conversationnels ?
Les messages-guides jouent un rôle clé dans l'orientation du comportement conversationnel des modèles linguistiques. Pour concevoir des messages-guides efficaces, il faut bien comprendre les informations contextuelles, les objectifs de l'interaction, ainsi que le style et le ton souhaités. Exemple :
- informations généralesLes informations contextuelles : fournir des informations contextuelles pertinentes pour s'assurer que le modèle linguistique saisit le contexte nécessaire lors de la création ou de l'adaptation des questions.
- Conseils pour la réalisation d'objectifsLes participants sont invités à préciser l'objectif de chaque invite, par exemple pour ajuster la question, décider d'un processus de recherche ou générer une réponse.
- Style et tonLes modèles de langue sont des outils qui permettent de spécifier le style (par exemple, formel, décontracté) et le ton (par exemple, informatif, empathique) souhaités pour s'assurer que le résultat du modèle de langue répond aux attentes de l'expérience de l'utilisateur.
La création d'outils de dialogue utilisant des techniques avancées de RAG nécessite une stratégie intégrée qui combine les forces de la recherche et de la génération. En concevant soigneusement les flux de dialogue, en mettant en œuvre des mécanismes de prise de décision intelligents et en développant des messages-guides efficaces, les développeurs peuvent créer des outils d'IA qui fournissent à la fois des réponses précises et riches en contexte, ainsi que des interactions naturelles et significatives avec les utilisateurs.
Comment créer des applications RAG avancées ?
C'est une bonne chose de commencer par construire une application de base de Génération Augmentée de Récupération (RAG), mais pour réaliser tout le potentiel de RAG dans des scénarios plus complexes, vous devez aller au-delà des principes de base. Cette section décrit comment construire une application RAG avancée qui améliore le processus d'extraction, la précision des réponses et met en œuvre des techniques avancées telles que la réécriture des requêtes et l'extraction en plusieurs étapes.
Avant de plonger dans les techniques avancées, examinons brièvement la fonctionnalité de base d'une application RAG, qui combine les capacités d'un modèle linguistique (LLM) avec une base de connaissances externe pour répondre aux questions des utilisateurs. Ce processus se compose généralement de deux phases :
- récupérer (données)L'application recherche des extraits de texte dans des bases de données vectorielles ou d'autres bases de connaissances qui correspondent à la requête de l'utilisateur.
- lireLe texte récupéré est transmis au mécanisme d'apprentissage tout au long de la vie pour générer une réponse basée sur ces contextes.
Cette approche "recherche et lecture" fournit au LLM les informations de base nécessaires pour fournir des réponses plus précises aux questions nécessitant des connaissances spécialisées.
Les étapes pour construire une application RAG avancée sont les suivantes :
Étape 1 : Utiliser des techniques avancées pour améliorer la recherche
L'étape de l'extraction est essentielle pour la qualité de la réponse finale. Dans une application RAG de base, le processus d'extraction est relativement simple, mais dans une application RAG avancée, vous pouvez utiliser les améliorations suivantes :
1. recherche en plusieurs étapes
Les recherches en plusieurs étapes permettent de cibler les contextes les plus pertinents en affinant la recherche en plusieurs étapes. Elle comprend généralement
- Recherche initiale élargieLes recherches : Commencez par une recherche élargie d'un ensemble de documents potentiellement pertinents.
- Affiner votre rechercheUne recherche plus précise basée sur des résultats préliminaires, réduite aux segments les plus pertinents.
Cette méthode améliore la précision des informations extraites, ce qui permet d'obtenir des réponses plus précises.
2. réécriture des requêtes
La réécriture des requêtes convertit la requête d'un utilisateur dans un format plus susceptible de produire des résultats pertinents lors d'une recherche. Cela peut se faire de plusieurs manières :
- réécriture de l'échantillon zéroLes requêtes sont réécrites sans exemples concrets, en s'appuyant sur la compréhension linguistique du modèle.
- Moins de réécriture d'échantillonsLes exemples sont fournis pour aider les modèles à réécrire des requêtes similaires afin d'améliorer la précision.
- Réécrivains sur mesureLes résultats de l'étude sont les suivants : affiner le modèle dédié à la réécriture des requêtes afin de mieux traiter les requêtes spécifiques à un domaine.
Ces requêtes réécrites correspondent mieux à la langue et à la structure des documents de la base de connaissances, ce qui améliore la précision de la recherche.
3. décomposition des sous-requêtes
Pour les requêtes complexes impliquant plusieurs questions ou aspects, la décomposition de la requête en plusieurs sous-requêtes peut améliorer la recherche. Chaque sous-requête se concentre sur un aspect particulier de la question initiale, de sorte que le système peut récupérer le contexte pertinent pour chaque partie et intégrer les réponses.
Étape 2 : Améliorer la génération de réponses
Après avoir amélioré le processus de recherche, l'étape suivante consiste à optimiser la manière dont le Big Language Model génère des réponses :
1. conseils pour le backtracking
Lorsque l'on est confronté à des questions complexes ou à plusieurs niveaux, il peut être utile de générer des requêtes supplémentaires plus larges. Ces indices de "repli" peuvent aider à récupérer un plus large éventail d'informations contextuelles, permettant ainsi au Big Language Model de générer des réponses plus complètes.
2. l'intégration de documents hypothétiques (HyDE)
HyDE est une technique de pointe qui capture l'intention d'une requête en générant des documents hypothétiques basés sur la requête de l'utilisateur, puis en utilisant ces documents pour trouver des documents réels correspondants dans une base de connaissances. Cette approche est particulièrement adaptée lorsque la requête n'est pas sémantiquement similaire au contexte pertinent.
Étape 3 : Intégrer les boucles de rétroaction
Afin d'améliorer en permanence les performances des applications RAG, il est important d'intégrer des boucles de rétroaction dans le système :
1. le retour d'information des utilisateurs
Intégrer un mécanisme permettant aux utilisateurs d'évaluer la pertinence et la précision des réponses. Ce retour d'information peut être utilisé pour ajuster le processus de recherche et de génération.
2. l'amélioration de l'apprentissage
Grâce aux techniques d'apprentissage par renforcement, les modèles sont formés sur la base du retour d'information des utilisateurs et d'autres paramètres de performance. Cela permet au système d'apprendre de ses erreurs et d'améliorer la précision et la pertinence au fil du temps.
Étape 4 : Extension et optimisation
Au fur et à mesure que les applications RAG progressent, la mise à l'échelle et l'optimisation des performances deviennent de plus en plus importantes :
1. la recherche distribuée
Pour faire face aux bases de connaissances à grande échelle, des systèmes de recherche distribués sont mis en œuvre, qui peuvent traiter les tâches de recherche en parallèle sur plusieurs nœuds, réduisant ainsi le temps de latence et augmentant la vitesse de traitement.
2. stratégie de mise en cache
La mise en œuvre d'une stratégie de mise en cache pour stocker les blocs de contexte fréquemment consultés réduit la nécessité d'une recherche répétitive et accélère les temps de réponse.
3. optimisation du modèle
Optimiser les grands modèles linguistiques et les autres modèles utilisés dans l'application afin de réduire la charge de calcul tout en maintenant la précision. Des techniques telles que la distillation et la quantification des modèles sont très utiles à cet égard.
La création d'une application RAG avancée nécessite une compréhension approfondie des mécanismes de recherche et des modèles de génération, ainsi que la capacité de mettre en œuvre et d'optimiser des technologies complexes. En suivant les étapes décrites ci-dessus, vous pouvez créer un système de RAG avancé qui dépasse les attentes des utilisateurs et fournit des réponses de haute qualité et contextuellement précises pour une variété de scénarios d'application.
La montée en puissance des graphes de connaissance dans les RAG avancés
Le rôle des graphes de connaissances dans les systèmes avancés de génération d'augmentation de la recherche (RAG) est devenu particulièrement important, car les organisations s'appuient de plus en plus sur l'IA pour des tâches complexes basées sur des données.Selon Gartner. Le Knowledge Graph est l'une des technologies de pointe qui promet de perturber plusieurs marchés à l'avenir.Technologies émergentes affectant les radars a noté que les graphes de connaissances sont des outils de soutien essentiels pour les applications avancées de l'IA, et qu'ils constituent la base de la gestion des données, des capacités de raisonnement et de la fiabilité des résultats de l'IA. Cela a conduit à l'utilisation généralisée des graphes de connaissances dans divers secteurs tels que les soins de santé, la finance et le commerce de détail.
Qu'est-ce que le Knowledge Graph ?
Un graphe de connaissances est une représentation structurée de l'information dans laquelle les entités (nœuds) et les relations entre elles (arêtes) sont explicitement définies. Ces entités peuvent être des objets concrets (tels que des personnes et des lieux) ou des concepts abstraits. Les relations entre les entités permettent de construire un réseau de connaissances qui rend la recherche de données, le raisonnement et l'inférence plus cognitifs pour l'homme. Plus qu'un simple stockage de données, le graphe de connaissances capture les relations riches et nuancées au sein d'un domaine, ce qui en fait un outil puissant dans les applications d'intelligence artificielle.
Amélioration et planification des requêtes à l'aide de graphes de connaissances
L'amélioration des requêtes est une solution au problème des questions peu claires dans le système RAG. L'objectif est d'ajouter le contexte nécessaire à une requête pour s'assurer que même les questions vagues peuvent être interprétées avec précision. Par exemple, dans le domaine financier, des questions telles que "Quels sont les défis actuels liés à la mise en œuvre de la réglementation financière ? Les questions telles que "Quels sont les défis actuels dans la mise en œuvre de la réglementation financière ?" peuvent être améliorées pour inclure des entités spécifiques telles que "conformité AML" ou "processus KYC" afin de concentrer le processus de recherche sur les informations les plus pertinentes.
Dans le domaine juridique, des questions telles que "Quels sont les risques associés aux contrats ?" peuvent être complétées par l'ajout de types de contrats spécifiques, tels que "contrat de travail" ou "contrat de service", sur la base du contexte fourni par le graphe de connaissances.
La planification des requêtes, quant à elle, décompose les requêtes complexes en parties gérables en générant des sous-questions. Cela permet au système RAG de récupérer et d'intégrer les informations les plus pertinentes pour fournir une réponse complète. Par exemple, pour répondre à la question "Quel est l'impact des nouvelles normes d'information financière sur l'entreprise ?" le système pourrait d'abord extraire des données sur les différentes normes d'information, les calendriers de mise en œuvre et les impacts historiques sur les différents domaines.
Dans le domaine médical, une question telle que "Quelles sont les dernières avancées en matière de dispositifs médicaux ? peut être décomposée en sous-questions qui explorent les avancées dans des domaines spécifiques, tels que les "dispositifs implantables", les "dispositifs de diagnostic" ou les "outils chirurgicaux", ce qui permet au système d'obtenir des informations détaillées et pertinentes à partir de chaque sous-catégorie. Le système obtient ainsi des informations détaillées et pertinentes de chaque sous-catégorie.
Grâce à l'amélioration et à la planification des requêtes, le Knowledge Graph permet d'optimiser et de structurer les requêtes afin d'améliorer la précision et la pertinence de la recherche d'informations, ce qui permet d'obtenir des réponses plus précises et plus utiles dans des domaines complexes tels que la finance, le droit et les soins de santé.
Le rôle des graphes de connaissances dans les GCR
Dans les systèmes de génération assistée par récupération (RAG), les graphes de connaissances améliorent le processus de récupération et de génération en fournissant des données structurées et riches en contexte. Les systèmes RAG traditionnels s'appuient sur des textes non structurés et des bases de données vectorielles, ce qui peut entraîner une recherche d'informations inexacte ou incomplète. En intégrant les graphes de connaissances, les systèmes RAG sont capables de.. :
- Amélioration de la compréhension des requêtes : Les graphes de connaissances aident le système à mieux comprendre le contexte et les relations d'une requête et donc à extraire des données pertinentes avec plus de précision.
- Génération de réponses améliorées : Les données structurées fournies par le Knowledge Graph peuvent générer des réponses plus cohérentes et plus pertinentes sur le plan contextuel, réduisant ainsi le risque d'erreurs de l'IA.
- Mise en œuvre d'un raisonnement complexe : Les graphes de connaissances prennent en charge le raisonnement multi-sauts, où le système peut déduire de nouvelles connaissances ou relier des informations disparates en parcourant de multiples relations.
Principaux éléments du graphe de connaissances
Le graphe de connaissances se compose des principaux éléments suivants :
- Nœuds : Représente diverses entités ou concepts dans le domaine de la connaissance, tels que des personnes, des lieux ou des choses.
- Côté : Décrire la relation entre les nœuds, en montrant comment ces entités sont interconnectées.
- Attributs : Informations supplémentaires ou métadonnées associées aux nœuds et aux arêtes qui fournissent plus de contexte ou de détails.
- Triade : Les éléments de base d'un graphe de connaissances, contenant un sujet, un prédicat et un objet (par exemple, "Einstein" [sujet] "découverte" [prédicat] "relativité" [objet ), ces triplets constituent le cadre de base pour la description des relations entre les entités.
Graphique de connaissances - Méthodologie RAG
La méthodologie KG-RAG comprend trois étapes principales :
- KG Construction : Cette étape consiste à transformer des données textuelles non structurées en un graphe de connaissances structuré, en veillant à ce que les données soient organisées et pertinentes.
- Récupéré : À l'aide d'un nouvel algorithme de recherche appelé "chaîne d'exploration" (CoE), le système effectue la recherche de données dans le graphe de connaissances.
- Génération de réponses : Enfin, les informations récupérées sont utilisées pour générer des réponses cohérentes et contextualisées, en combinant les données structurées du graphe de connaissances avec les capacités d'un grand modèle linguistique.
Cette méthodologie met en évidence le rôle important des connaissances structurées dans l'amélioration du processus de recherche et de génération des systèmes RAG.
Avantages des graphes de connaissances dans les RAG
L'intégration du graphe de connaissances dans le système RAG présente plusieurs avantages significatifs :
- Représentation structurée des connaissances : Les graphes de connaissances organisent l'information de manière à refléter les relations complexes entre les entités, ce qui rend la recherche et l'utilisation des données plus efficaces.
- Compréhension du contexte : Les graphes de connaissances fournissent des informations contextuelles plus riches en saisissant les relations entre les entités, ce qui permet au système RAG de générer des réponses plus pertinentes et plus cohérentes.
- Compétences en matière de raisonnement : La cartographie des connaissances aide le système à déduire de nouvelles connaissances en analysant les relations entre les entités afin de générer des réponses plus complètes et plus précises.
- Intégration des connaissances : Les graphiques de connaissances peuvent intégrer des informations provenant de différentes sources afin de fournir une vue plus complète des données et d'aider à prendre de meilleures décisions.
- Interprétabilité et transparence : La nature structurée du graphe de connaissances rend le cheminement du raisonnement clair et compréhensible, facilite l'explication du processus de formation des conclusions et améliore la crédibilité du système.
Intégration de KG dans LLM-RAG
L'utilisation de graphes de connaissances en conjonction avec de grands modèles de langage (LLM) dans les systèmes RAG améliore la représentation globale des connaissances et les capacités de raisonnement. Cette combinaison permet une fusion dynamique des connaissances, garantissant que les informations restent à jour et pertinentes au moment de l'inférence, générant ainsi des réponses plus précises et plus perspicaces.Les LLM peuvent utiliser des données structurées et non structurées pour fournir des résultats de meilleure qualité.
Utilisation des graphes de connaissances dans les questionnaires sur la chaîne de pensée
La cartographie des connaissances gagne du terrain dans les questionnaires sur la chaîne de pensée, en particulier lorsqu'elle est utilisée en conjonction avec la modélisation du langage étendu (LLM). Cette approche consiste à décomposer les questions complexes en sous-questions, à récupérer les informations pertinentes et à les synthétiser pour former une réponse finale. Les graphes de connaissances fournissent des informations structurées dans ce processus, améliorant ainsi le pouvoir de raisonnement du LLM.
Par exemple, un agent LLM peut d'abord utiliser le graphe de connaissances pour identifier les entités pertinentes dans une requête, puis obtenir davantage d'informations à partir de différentes sources, et enfin générer une réponse complète qui reflète les connaissances interconnectées dans le graphe.
Applications pratiques des graphes de connaissance
Dans le passé, les graphes de connaissances étaient principalement utilisés dans des domaines à forte intensité de données, tels que l'analyse de données massives et les systèmes de recherche d'entreprise, où leur rôle consistait à maintenir la cohérence et l'uniformité entre différents silos de données. Cependant, avec le développement de systèmes RAG basés sur de grands modèles de langage, les graphes de connaissances ont trouvé de nouveaux scénarios d'application. Ils servent désormais de complément structuré aux grands modèles linguistiques probabilistes, contribuant à réduire les fausses informations, à fournir plus de contexte et à agir comme un mécanisme de mémoire et de personnalisation dans les systèmes d'intelligence artificielle.
Présentation de GraphRAG
GraphRAG est une méthodologie de recherche de pointe qui combine les graphes de connaissance et les bases de données vectorielles dans une architecture RAG (Retrieval Augmented Generation). Ce modèle hybride exploite les forces des deux systèmes pour fournir des solutions d'IA plus précises, plus contextuelles et plus faciles à comprendre.Gartner a déclaré L'importance croissante des graphes de connaissances dans l'amélioration de la stratégie des produits et la création de nouveaux scénarios d'application de l'IA.
Les caractéristiques de GraphRAG sont les suivantes
- Plus grande précision : En combinant des données structurées et non structurées, GraphRAG est en mesure de fournir des réponses plus précises et plus complètes.
- Évolutivité : Cette approche simplifie le développement et la maintenance des applications RAG et permet une meilleure évolutivité.
- Interprétabilité : GraphRAG fournit des chemins d'inférence clairs qui améliorent la transparence du système, rendant les résultats de l'IA plus faciles à comprendre et plus fiables.
Avantages de GraphRAG
GraphRAG présente plusieurs avantages significatifs par rapport aux méthodes RAG traditionnelles :
- Des réponses de meilleure qualité : L'intégration du Knowledge Graph a permis d'améliorer la précision et la pertinence des réponses générées par l'IA, avec des benchmarks récents montrant une amélioration de la précision d'un facteur trois.
- Le rapport coût-efficacité : GraphRAG est plus rentable, nécessite moins de ressources informatiques et de données d'entraînement, et constitue une option intéressante pour les organisations qui cherchent à optimiser leurs investissements dans l'IA.
- Meilleure évolutivité : Cette approche prend en charge les applications d'IA à grande échelle, permettant aux organisations de traiter facilement des requêtes plus complexes et des ensembles de données plus importants.
- Amélioration de l'interprétabilité : L'approche structurée de GraphRAG fournit des chemins d'inférence plus clairs, rendant le processus de prise de décision de l'IA plus transparent et plus facile à déboguer.
- Révéler les connexions cachées : Les graphes de connaissances peuvent révéler des relations qui passent inaperçues dans les grands ensembles de données, ce qui permet d'obtenir des informations plus approfondies et d'améliorer la qualité du processus de prise de décision.
Architectures communes de GraphRAG
Plusieurs architectures GraphRAG apparaissent comme des moyens d'intégrer efficacement les graphes de connaissances dans les systèmes RAG :
- Graphes de connaissances avec regroupement sémantique : Cette architecture améliore la pertinence et la précision de la recherche de données en regroupant les informations pertinentes avant de générer des réponses.
- Intégration des graphes de connaissances dans les bases de données vectorielles : Cette architecture combine les deux systèmes pour fournir un contexte plus riche au modèle linguistique plus large, ce qui permet de générer des réponses plus complètes et adaptées au contexte.
- Système de questions-réponses amélioré par un graphe de connaissances : Dans cette architecture, le graphe de connaissances ajoute des informations factuelles aux réponses générées par le grand modèle linguistique après la recherche vectorielle, afin de garantir l'exactitude et l'exhaustivité des réponses.
- Recherche hybride améliorée par les graphes : Cette approche combine les recherches vectorielles, les recherches par mot-clé et les requêtes spécifiques aux graphes pour fournir un système de recherche puissant et flexible qui améliore la capacité des grands modèles de langage à générer des réponses pertinentes.
Modèles émergents pour GraphRAG
Au fur et à mesure de l'évolution de GraphRAG, plusieurs modèles émergent :
- Amélioration de l'enquête : Optimiser et améliorer les requêtes à l'aide de graphes de connaissances pour s'assurer que les informations les plus pertinentes sont récupérées.
- Amélioration de la réponse : Améliorer la précision et l'exhaustivité des réponses générées par le Big Language Model en ajoutant des faits pertinents.
- Contrôle des réponses : Utiliser les graphes de connaissances pour vérifier l'exactitude du contenu généré par l'IA et réduire le risque d'informations incorrectes ou fausses.
Ces modèles montrent comment GraphRAG modifie la façon dont les systèmes d'intelligence artificielle traitent les requêtes complexes et génèrent des réponses.
Applications de GraphRAG
- Recherche juridique : La capacité de GraphRAG à naviguer dans un réseau complexe de lois, de jurisprudences et d'études de cas offre aux professionnels du droit un outil puissant pour découvrir des informations juridiques pertinentes et des liens potentiels.
- Soins de santé Dans le domaine des soins de santé, GraphRAG aide à comprendre les relations complexes entre les connaissances médicales, les antécédents du patient et les options thérapeutiques afin d'améliorer la précision du diagnostic et la planification personnalisée du traitement.
- Analyse financière : GraphRAG aide à analyser les réseaux financiers complexes et les dépendances, en fournissant des informations sur les tendances du marché, la gestion des risques et les stratégies d'investissement en utilisant les données interconnectées du graphe de connaissances.
- Analyse des réseaux sociaux : GraphRAG permet d'explorer des structures et des interactions sociales complexes, aidant les chercheurs et les analystes à comprendre les modèles de relations et d'influence dans les réseaux sociaux.
- Gestion des connaissances : GraphRAG améliore la base de connaissances de l'entreprise en capturant et en exploitant les relations et les hiérarchies au sein des organisations, en améliorant les processus de prise de décision et en encourageant l'innovation au sein de l'entreprise.
Au fur et à mesure que l'IA progresse, il devient de plus en plus important d'incorporer des graphes de connaissances dans les systèmes de génération d'augmentation de la recherche. L'émergence de GraphRAG démontre les avantages de la combinaison des graphes de connaissances avec les méthodes vectorielles traditionnelles, offrant une approche plus complète et plus efficace de la recherche d'informations et de la génération de réponses.
RAG avancé : Élargir les horizons grâce à la génération améliorée et à la recherche multimodale
Les progrès de l'intelligence artificielle se sont accompagnés de percées qui continuent à repousser les limites de la compréhension et de la génération des machines. Alors que les systèmes traditionnels de Génération Augmentée de Récupération (GAR) se concentraient principalement sur les données textuelles, l'émergence de la GAR multimodale marque un saut technologique important. Cette technologie innovante permet à l'intelligence artificielle de traiter et d'intégrer de multiples formes de données, telles que le texte, les images, le son et la vidéo, afin de générer des résultats riches en contenu et contextualisés. En exploitant les données multimodales, ces systèmes d'IA avancés deviennent plus flexibles, plus sensibles au contexte et capables de fournir des informations plus approfondies et des réponses plus précises. Cette section explore les concepts fondamentaux, les mécanismes opérationnels et les applications potentielles de la RAG multimodale, en soulignant son importance pour la prochaine génération d'interactions d'IA.
Comprendre le RAG multimodal
Le RAG multimodal est une extension avancée du cadre RAG classique qui combine les mécanismes de recherche avec l'IA générative pour de multiples types de données. Alors que les systèmes RAG traditionnels obtiennent des informations en interrogeant des bases de données textuelles, la RAG multimodale étend cette capacité en intégrant du texte, des images, de l'audio et de la vidéo dans le processus de recherche et de génération. Cette extension permet aux modèles d'IA de tirer parti d'un plus large éventail d'entrées pour générer des résultats plus complets et plus nuancés.
Comment fonctionne le GCR multimodal ?
Le flux de travail d'un RAG multimodal consiste à encoder différents types de données dans un format structuré, généralement des vecteurs, afin que le modèle d'IA puisse les traiter. Ces vecteurs sont stockés dans un espace d'intégration partagé qui contient des données provenant de différentes modalités. Lorsqu'une requête est formulée, le modèle extrait les informations pertinentes de ces modalités, ce qui permet de fournir une réponse plus riche et plus précise. Par exemple, pour une requête concernant un événement historique, le système peut récupérer des descriptions textuelles, des images pertinentes, des clips audio de commentaires d'experts et des séquences vidéo qui, ensemble, forment une réponse plus détaillée et plus informative.
Méthodes de mise en œuvre des RAG multimodaux
Un certain nombre d'approches peuvent être adoptées pour réaliser un RAG multimodal, chacune présentant des avantages et des défis particuliers :
- Un modèle multimodal unique :
Cette approche utilise un modèle unifié qui est formé pour encoder différents types de données (texte, images, audio, etc.) dans un espace vectoriel commun. Le modèle peut ensuite extraire et générer des données de manière transparente à travers ces types de données. Bien que cette approche simplifie le processus en utilisant un modèle unique, elle nécessite une formation complexe pour garantir l'encodage et l'extraction précis des données multimodales. - Modale de base basée sur le texte :
Dans cette approche, les données non textuelles sont converties en descriptions textuelles avant d'être encodées et stockées. Cette approche tire parti des modèles textuels les plus récents. Cependant, il peut y avoir une perte d'informations au cours du processus de conversion, car les nuances de l'image ou de l'audio peuvent ne pas être entièrement représentées dans le texte. - Encodeurs multiples :
Cette approche utilise différents modèles pour coder différents types de données, chacun étant traité par son propre modèle spécialisé. Le processus de recherche intégrera ces résultats. Si cette approche permet un codage plus spécialisé et une extraction plus précise des données, elle accroît la complexité du système et nécessite une gestion minutieuse des multiples modèles et de leurs interactions.
Architecture d'un RAG multimodal
L'architecture du RAG multimodal s'appuie sur les fondements des RAG traditionnels tout en intégrant la complexité du traitement de plusieurs types de données. L'architecture de base comprend les éléments clés suivants :
- Codeurs modaux spécifiques :
Chaque modalité de données, comme le texte, l'image ou le son, est traitée par un encodeur spécialisé. Ces encodeurs convertissent les données brutes en un espace d'intégration uniforme, ce qui permet de comparer et d'extraire toutes les modalités de manière standardisée. - Espace intégré partagé :
Un élément clé du RAG multimodal est l'espace d'intégration partagé, qui stocke les vecteurs codés provenant de différentes modalités. Cet espace permet d'effectuer des comparaisons intermodales et des recherches, ce qui permet au modèle de reconnaître les informations pertinentes dans différents types de données. - Retriever :
Le composant Retriever est chargé d'interroger l'espace d'intégration partagé pour trouver les points de données les plus pertinents dans les différentes modalités. Il peut extraire des informations sur la base de divers critères tels que la pertinence par rapport à la requête d'entrée ou la similarité avec d'autres points de données dans l'espace. - Générateur :
Une fois les informations pertinentes récupérées, le générateur intègre ces données dans la réponse du modèle d'IA. Le générateur est généralement un modèle de langage complexe capable d'intégrer des informations provenant de modalités multiples dans un résultat cohérent et précis sur le plan contextuel. - Mécanismes d'intégration :
Le mécanisme de fusion est chargé de combiner les données multimodales récupérées en une représentation unifiée à l'usage du générateur. Ce processus peut impliquer la sélection des modalités les plus pertinentes ou la synthèse d'informations provenant de différentes sources pour créer une réponse complète.
Plusieurs stratégies clés doivent être employées pour gérer les informations des différentes modalités dans un système RAG :
- Uniformément intégré dans l'espace :
Le codage de tous les types de données dans un espace d'intégration commun permet au système d'effectuer efficacement des opérations de recherche multimodale. En même temps, cet espace d'intégration fournit une base pour l'intégration et l'alignement des données provenant de différentes sources. - Mécanismes d'attention intermodale :
L'utilisation d'un mécanisme d'attention multimodale permet au modèle de se concentrer sur les informations les plus pertinentes des données extraites, quelle que soit la modalité dont elles proviennent. Cela permet d'équilibrer l'importance de chaque type de données dans la réponse finale. - Post-traitement spécifique à la modalité :
Une fois l'extraction terminée, un post-traitement spécifique des données pour chaque modalité peut être nécessaire, comme le redimensionnement des images ou la normalisation de l'audio, afin de garantir que les données sont optimisées pour l'intégration et la génération.
RAG multimodal dans les Chatbots
Les RAG multimodaux améliorent considérablement les capacités des chatbots, leur permettant de fournir des expériences interactives plus riches et plus contextualisées. Les chatbots traditionnels s'appuient principalement sur le texte, ce qui limite leur capacité à répondre à des informations visuelles ou sonores. Les RAG multimodaux permettent aux chatbots de capturer et d'intégrer des informations provenant d'images, de vidéos et de clips audio afin d'offrir à l'utilisateur une expérience plus complète et plus intéressante.
Par exemple, en utilisant les RAG multimodaux Chatbot de support client Des vidéos d'instruction, des images de produits ou des guides audio peuvent être affichés en réponse à la demande d'un utilisateur, ce qui permet d'apporter une aide plus interactive et plus pratique. Ceci est particulièrement important dans des domaines tels que la vente au détail, les soins de santé et l'éducation, où la communication doit souvent être soutenue par de multiples formes d'information.
Développement des applications multimodales du système RAG
L'introduction de la fonctionnalité multimodale ouvre de nouvelles perspectives dans un grand nombre de secteurs :
- Soins de santé
Les RAG multimodaux peuvent combiner des dossiers médicaux textuels, des images radiologiques, des résultats de laboratoire et des descriptions audio des patients afin d'améliorer la précision et l'exhaustivité des systèmes de diagnostic. - Finances :
Dans les services financiers, le RAG multimodal est capable de traiter et d'analyser des documents complexes contenant des tableaux, des graphiques et des textes explicatifs afin d'améliorer le processus de prise de décision. - Éducation :
Les plates-formes éducatives peuvent utiliser les RAG multimodales pour mélanger texte, conférences vidéo, illustrations et simulations interactives dans un récit pédagogique complet, offrant ainsi une expérience d'apprentissage plus riche.
La RAG multimodale est une avancée technologique importante qui a le potentiel de changer la façon dont les systèmes d'intelligence artificielle interagissent avec les utilisateurs et leur répondent. En intégrant plusieurs types de données dans le processus d'extraction et de génération, les systèmes de RAG multimodale sont en mesure de fournir des résultats plus riches, plus précis et contextualisés, ce qui ouvre de nouvelles possibilités dans toute une série de secteurs d'activité. Au fur et à mesure que la technologie évolue, on s'attend à ce que ses applications se développent pour améliorer encore la capacité de l'IA à traiter des informations multimodales complexes.
Comment la plateforme de coordination GenAI de LeewayHertz, ZBrain, se distingue des systèmes RAG avancés.
Curieux de connaître les RAG avancés, les RAG multimodaux et les graphes de connaissances ? Imaginez que vous puissiez combiner ces puissantes fonctionnalités dans une plateforme unique qui vous permette de créer facilement des applications d'IA avancées. C'est ZBrain.
ZBrainDéveloppé par LeewayHertz, ZBrain est une plateforme d'orchestration complète conçue pour simplifier et accélérer le développement et la mise à l'échelle de solutions d'IA de classe entreprise. Grâce à son environnement convivial à code bas, ZBrain permet aux organisations de créer, de déployer et de mettre à l'échelle rapidement des applications d'IA générative (GenAI) personnalisées avec un effort de codage réduit. La plateforme révolutionne le processus de développement de l'IA en entreprise en permettant aux organisations d'exploiter leurs propres données pour créer des applications d'IA hautement personnalisées et précises. En tant que centre de contrôle central, ZBrain s'intègre de manière transparente aux piles technologiques existantes afin d'améliorer l'efficacité du développement d'applications GenAI. Les applications construites sur ZBrain excellent dans les tâches de traitement du langage naturel (NLP) telles que la génération de rapports, la traduction, l'analyse de données, la classification et le résumé de textes. En exploitant les données privées et contextuelles, ZBrain garantit que les réponses sont hautement pertinentes et personnalisées pour répondre aux besoins spécifiques de l'entreprise.
Comment s'interfacer avec les systèmes avancés de génération d'augmentation de la recherche (RAG) ?
- Intégration de diverses sources de données : ZBrain intègre une variété de sources de données, y compris des flux privés, publics et en temps réel dans tous les formats de données (structurés, semi-structurés et non structurés) afin d'améliorer la précision et la pertinence des réponses de l'IA.
- Optimisation au niveau des blocs : La plateforme garantit que des résultats précis et adaptés sont générés en décomposant l'information en morceaux gérables et en appliquant les stratégies de recherche les plus efficaces.
- Découverte automatique de stratégies de recherche : Les algorithmes avancés de ZBrain identifient et appliquent automatiquement des stratégies de recherche optimales, réduisant ainsi les actions manuelles basées sur les données et le contexte et améliorant la précision de la récupération des données.
- Mesures de protection et contrôle des hallucinations : ZBrain est équipé de protections et de contrôles fantômes qui empêchent la production d'informations inexactes ou trompeuses, garantissant ainsi une grande précision et une grande fiabilité.
capacité multimodale
- Gère plusieurs formats de données. ZBrain excelle dans le traitement de multiples formats de données tels que le texte, les images, la vidéo et l'audio, fournissant ainsi une réponse complète et détaillée.
- Intégration et analyse des différents types de données. La plateforme est capable d'intégrer et d'analyser différents types de données afin de fournir des informations plus riches et des réponses pertinentes.
- Amélioration du traitement des requêtes. ZBrain gère et récupère efficacement les informations provenant de multiples modalités de données, améliorant ainsi la précision et la compréhension des problèmes complexes.
carte des connaissances
- Cadre de données structurées. ZBrain organise les données en un réseau structuré qui améliore la précision de la recherche et fournit des informations plus approfondies en reliant des concepts connexes.
- Des données plus approfondies. La nature interconnectée du Knowledge Graph permet à ZBrain de fournir des réponses nuancées et contextuelles qui conduisent à des informations plus riches et plus significatives.
- Capacités étendues en matière de données. ZBrain permet d'étendre les données au niveau du bloc ou du fichier, de mettre à jour les méta-informations et de générer des ontologies afin d'améliorer la représentation, l'organisation et la recherche des données.
Avantages de l'utilisation de ZBrain pour le développement de solutions d'IA d'entreprise
ZBrain offre de nombreux avantages pour le développement de solutions d'IA d'entreprise, notamment
- évolutivité
ZBrain facilite la mise à l'échelle des solutions d'IA pour gérer des volumes de données et des scénarios d'utilisation croissants sans compromettre les performances. - Une intégration efficace
La plateforme s'intègre facilement aux piles technologiques existantes, ce qui réduit les délais et les coûts de déploiement et accélère l'adoption de l'IA. - personnalisation
ZBrain soutient le développement d'applications d'IA hautement personnalisées qui répondent aux besoins spécifiques des entreprises et s'alignent sur les objectifs organisationnels. - Efficacité des ressources
Sa nature "low-code" réduit le besoin d'un grand nombre de développeurs et convient aux organisations dotées d'équipes techniques réduites. - Des solutions complètes
Du développement au déploiement, ZBrain couvre l'ensemble du cycle de vie d'une application d'IA, ce qui en fait une solution complète. - Déploiement neutre dans le nuage
ZBrain est neutre vis-à-vis du cloud, ce qui permet de déployer des applications sur une variété de plateformes cloud, offrant ainsi la flexibilité nécessaire pour s'adapter aux différents besoins organisationnels et aux préférences en matière d'infrastructure.
Le système RAG avancé de ZBrain, la prise en charge multimodale et l'intégration robuste des graphes de connaissances en font une plateforme puissante qui permet d'améliorer la précision, l'efficacité et la compréhension dans un large éventail d'applications.
note de bas de page
Les progrès réalisés dans le domaine de la génération assistée par récupération (RAG) ont considérablement accru ses capacités, lui permettant de surmonter les limites précédentes et d'ouvrir de nouvelles perspectives en matière de récupération et de génération d'informations basées sur l'IA. Grâce à l'utilisation de mécanismes de recherche sophistiqués, la RAG avancée peut accéder à de grandes quantités de données afin de garantir que les réponses générées sont à la fois exactes et pertinentes sur le plan contextuel. Cette avancée ouvre la voie à des applications d'IA plus dynamiques et interactives, faisant des RAG un outil important dans des domaines tels que le service à la clientèle, la recherche, la gestion des connaissances et la création de contenu. L'application de ces technologies avancées de RAG offre aux organisations la possibilité d'améliorer l'expérience de l'utilisateur, de rationaliser les processus et de résoudre des problèmes complexes avec plus de précision et d'efficacité.
L'introduction de la RAG multimodale et de la RAG de graphe de connaissances améliore encore les capacités de ce cadre, ce qui en favorise l'adoption à grande échelle dans tous les secteurs d'activité. Le RAG multimodal combine des données textuelles, visuelles et autres, ce qui permet au modèle de langage étendu (LLM) de générer des réponses plus complètes et contextuelles qui améliorent l'expérience de l'utilisateur et fournissent des informations plus riches et plus nuancées. Le Knowledge Graph RAG utilise des structures de données interconnectées pour récupérer et générer un contenu sémantiquement riche, ce qui améliore considérablement la précision et la profondeur de l'information. Ces avancées dans la technologie RAG annoncent une nouvelle vague d'innovation en matière d'IA, offrant des solutions plus intelligentes et plus souples aux défis complexes de la recherche d'informations.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...