
450 pour former un "o1-preview" ? Le modèle d'inférence 32B Sky-T1 de l'UC Berkeley est en libre accès et la communauté de l'IA s'en émeut.
Un prix de 450 dollars ne semble pas énorme à première vue. Mais que se passerait-il si c'était le coût total de la formation d'un modèle d'inférence 32B ?
Oui, à l'approche de 2025, les modèles d'inférence sont de plus en plus faciles à développer et leur coût diminue rapidement pour atteindre des niveaux inimaginables auparavant.
Récemment, NovaSky, une équipe de recherche du Sky Computing Lab de l'université de Californie à Berkeley, a publié Sky-T1-32B-Preview. Il est intéressant de noter que, selon l'équipe, "Sky-T1-32B-Preview coûte moins de 450 dollars pour être entraîné, ce qui suggère qu'il est possible de reproduire économiquement et efficacement des capacités de raisonnement de haut niveau".

- Page d'accueil du projet : https://novasky-ai.github.io/posts/sky-t1/
- Adresse de la source ouverte : https://huggingface.co/NovaSky-AI/Sky-T1-32B-Preview
Selon les informations officielles, ce modèle d'inférence correspond à une version antérieure de l'OpenAI o1 dans plusieurs points de référence clés.

Le fait est que Sky-T1 semble être le premier modèle d'inférence véritablement open-source, puisque l'équipe a publié l'ensemble des données d'entraînement ainsi que le code d'entraînement nécessaire pour que tout le monde puisse le reproduire à partir de zéro.
Les gens se sont exclamés : "Quelle incroyable contribution en termes de données, de code et de poids des modèles".
Il n'y a pas si longtemps, le prix de l'entraînement d'un modèle aux performances équivalentes se chiffrait souvent en millions de dollars. Les données d'entraînement synthétiques ou générées par d'autres modèles ont permis de réduire considérablement les coûts.
Auparavant, une entreprise spécialisée dans l'IA, Writer, avait mis sur le marché le Palmyra X 004, qui a été entraîné presque entièrement à partir de données synthétiques et dont le développement n'a coûté que 700 000 dollars.
Imaginez que ce programme soit exécuté sur le supercalculateur Nvidia Project Digits AI, qui coûte 3 000 dollars (ce qui n'est pas cher pour un supercalculateur) et qui peut exécuter des modèles comportant jusqu'à 200 milliards de paramètres. Dans un avenir proche, les modèles comportant moins de 1 000 milliards de paramètres seront exécutés localement par des particuliers.
L'évolution de la technologie des grands modèles en 2025 s'accélère, et c'est un sentiment très fort.
Vue d'ensemble du modèle
Le raisonnement o1 et Gémeaux 2.0 Des modèles tels que la pensée éclair ont permis de résoudre des tâches complexes et de réaliser d'autres progrès en générant de longues chaînes de pensée internes. Cependant, les détails techniques et les poids des modèles ne sont pas disponibles, ce qui constitue un obstacle à l'engagement de la communauté universitaire et de la communauté open source.
À cette fin, des résultats notables ont été obtenus dans le domaine des mathématiques pour l'entraînement de modèles d'inférence à pondération ouverte, tels que Still-2 et Journey. Entre-temps, l'équipe NovaSky de l'université de Californie, à Berkeley, a exploré diverses techniques pour développer les capacités d'inférence des modèles de base et des modèles accordés par commande.
Dans ce travail, Sky-T1-32B-Preview, l'équipe a obtenu des performances d'inférence compétitives non seulement sur le plan mathématique, mais aussi sur le plan du codage du même modèle.

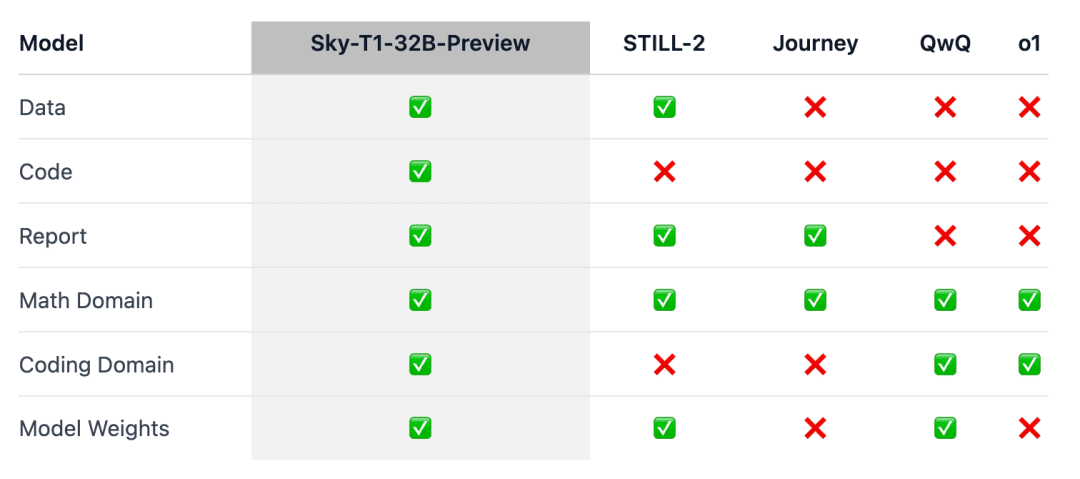
Pour s'assurer que ce travail "profite à l'ensemble de la communauté", l'équipe a ouvert tous les détails (par exemple, les données, le code, les poids des modèles) afin que la communauté puisse facilement le reproduire et l'améliorer :
- Infrastructure : construction de données, formation et évaluation de modèles dans un référentiel unique ;
- Données : 17K données utilisées pour former Sky-T1-32B-Preview ;
- Détails techniques : rapports techniques et journaux wandb ;
- Poids du modèle : 32B Poids du modèle.
Détails techniques
Processus de collecte des données
Pour générer les données d'entraînement, l'équipe a utilisé QwQ-32B-Preview, un modèle open-source doté de capacités d'inférence comparables à o1-preview. L'équipe a organisé le mélange de données de manière à couvrir les différents domaines dans lesquels l'inférence était nécessaire et a utilisé une procédure d'échantillonnage par rejet pour améliorer la qualité des données.
Ensuite, inspirée par Still-2, l'équipe a réécrit la trace QwQ en une version structurée utilisant GPT-4o-mini pour améliorer la qualité des données et simplifier l'analyse.
Ils ont constaté que la simplicité de l'analyse syntaxique était particulièrement bénéfique pour les modèles d'inférence. Ils sont formés pour répondre dans un format spécifique et les résultats sont souvent difficiles à analyser. Par exemple, sur l'ensemble de données APPs, sans reformatage, l'équipe ne pouvait que supposer que le code était écrit dans le dernier bloc de code, et QwQ ne pouvait atteindre qu'une précision d'environ 25%. Cependant, il arrive que le code soit écrit au milieu, et après le reformatage, la précision augmente pour atteindre plus de 90%.
Rejeter l'échantillon. En fonction de la solution fournie avec l'ensemble de données, si l'échantillon QwQ est incorrect, l'équipe le rejette. Pour les problèmes mathématiques, l'équipe effectue une correspondance exacte avec la solution de vérité terrain. Pour les problèmes de codage, l'équipe effectue les tests unitaires fournis dans l'ensemble de données. Les données finales de l'équipe se composent de 5 000 données codées provenant d'APPs et de TACO, et de 10 000 données mathématiques provenant du sous-ensemble Olympiades des ensembles de données AIME, MATH et NuminaMATH. En outre, l'équipe a conservé 1 000 données sur les sciences et les énigmes provenant de STILL-2.
train
L'équipe a utilisé les données d'entraînement pour affiner Qwen2.5-32B-Instruct, un modèle open-source dépourvu de capacités d'inférence. Le modèle a été entraîné en utilisant 3 époques, un taux d'apprentissage de 1e-5 et une taille de lot de 96. L'entraînement du modèle a été réalisé en 19 heures sur 8 H100 à l'aide d'un déchargement DeepSpeed Zero-3 (prix d'environ 450 $ selon Lambda Cloud). L'équipe a utilisé Llama-Factory pour la formation.
Résultats de l'évaluation
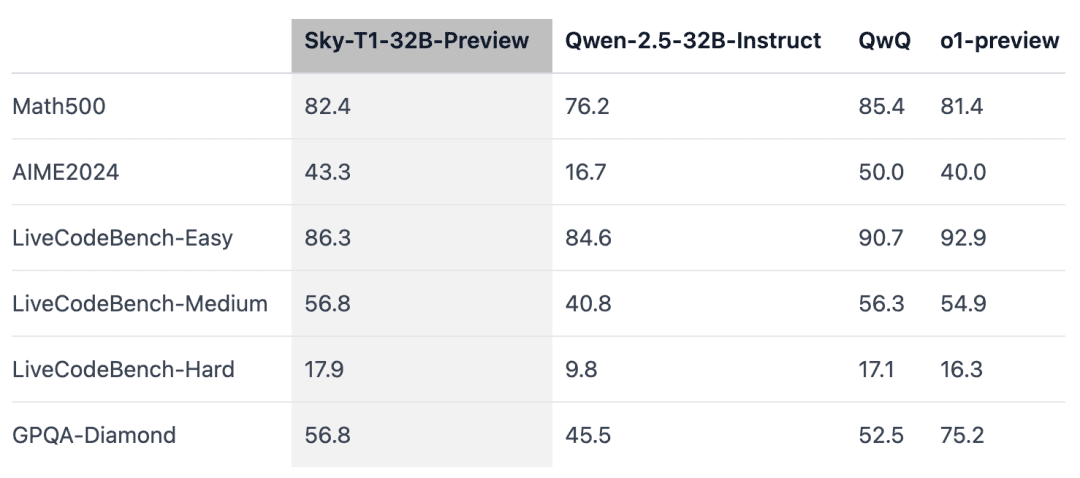
Sky-T1 a surpassé une version antérieure de o1 sur MATH500, un défi mathématique de niveau "compétition", et a également battu une version préliminaire de o1 sur un ensemble de puzzles de LiveCodeBench, une évaluation de codage. Toutefois, Sky-T1 n'est pas aussi performant que la version préliminaire de o1 sur GPQA-Diamond, qui contient des problèmes liés à la physique, à la biologie et à la chimie que les titulaires d'un doctorat doivent connaître.
Cependant, la version GA de o1 d'OpenAI est plus puissante que la version preview de o1, et OpenAI prévoit de publier un modèle d'inférence plus performant, o3, dans les semaines à venir.
De nouvelles découvertes qui méritent l'attention
La taille du modèle est importante.L'équipe a d'abord essayé de s'entraîner sur des modèles plus petits (7B et 14B), mais n'a observé que peu d'améliorations. Par exemple, l'entraînement de Qwen2.5-14B-Coder-Instruct sur l'ensemble de données APPs a montré une légère amélioration des performances sur LiveCodeBench, de 42,6% à 46,3%.Toutefois, en examinant manuellement la sortie des modèles plus petits (ceux de moins de 32B), l'équipe a constaté qu'ils généraient souvent du contenu dupliqué, ce qui limite leur efficacité. ce qui limitait leur efficacité.
Le mélange des données est important.L'équipe a d'abord entraîné le modèle 32B en utilisant 3-4K problèmes de mathématiques provenant de l'ensemble de données Numina (fourni par STILL-2), et la précision d'AIME24 s'est considérablement améliorée, passant de 16,7% à 43,3%. Cependant, lorsque les données de programmation générées par l'ensemble de données APPs ont été incorporées dans le processus d'entraînement, la précision d'AIME24 a chuté à 36,7%. Il est possible que cette baisse soit due aux différentes méthodes d'inférence requises pour les tâches de mathématiques et de programmation.
Le raisonnement de programmation implique généralement des étapes logiques supplémentaires telles que la simulation des entrées de test ou l'exécution interne du code généré, alors que le raisonnement pour les problèmes mathématiques tend à être plus simple et plus structuré.Pour remédier à ces différences, l'équipe a enrichi les données d'entraînement avec des problèmes mathématiques difficiles provenant de l'ensemble de données NuminaMath et des tâches de programmation complexes provenant de l'ensemble de données TACO. Ce mélange équilibré de données a permis au modèle d'exceller dans les deux domaines, en obtenant une précision de 43,3% sur AIME24 tout en améliorant ses capacités de programmation.
Dans le même temps, certains chercheurs ont exprimé leur scepticisme :


Qu'en pensez-vous ? N'hésitez pas à en discuter dans la section des commentaires.
Lien de référence : https://www.reddit.com/r/LocalLLaMA/comments/1hys13h/new_model_from_httpsnovaskyaigithubio/
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...