
¡Peso pesado! El primer modelo descentralizado de 10B del mundo entrenado, ¡de código abierto en una semana!

Nace el primer modelo paramétrico 10B del mundo entrenado descentralizadamente.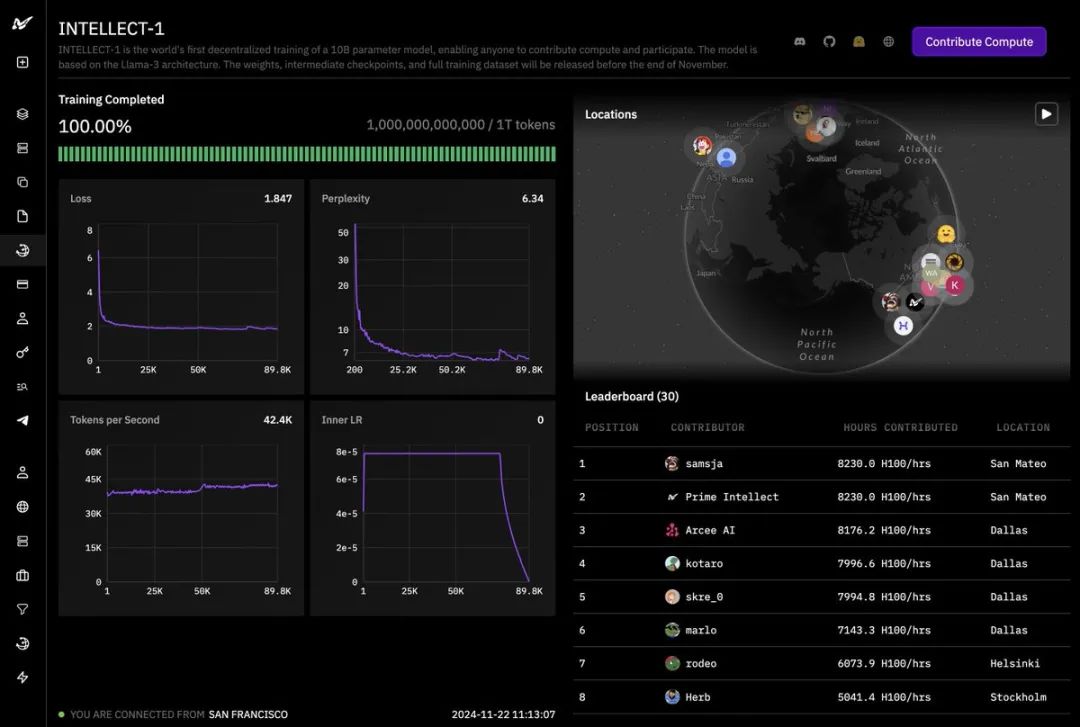 El equipo de Prime Intellect ha anunciado que ha completado un trabajo histórico: una red de entrenamiento descentralizada a través de EE.UU., Europa y Asia ha entrenado con éxito un gran modelo con 10B parámetros. Esto supone un paso revolucionario en el entrenamiento de IA.
El equipo de Prime Intellect ha anunciado que ha completado un trabajo histórico: una red de entrenamiento descentralizada a través de EE.UU., Europa y Asia ha entrenado con éxito un gran modelo con 10B parámetros. Esto supone un paso revolucionario en el entrenamiento de IA.
Como puede verse en el panel de entrenamiento, el proyecto, denominado INTELLECT-1, ha completado el entrenamiento de 1 billón (1T) de fichas.
Tanto las curvas de pérdida como las de perplejidad muestran una deseable tendencia descendente, y el número de tokens generados por segundo se mantiene estable, lo que indica que el proceso de entrenamiento fue muy satisfactorio. El éxito de este proyecto no habría sido posible sin el apoyo de muchos socios.
El éxito de este proyecto no habría sido posible sin el apoyo de muchos socios.
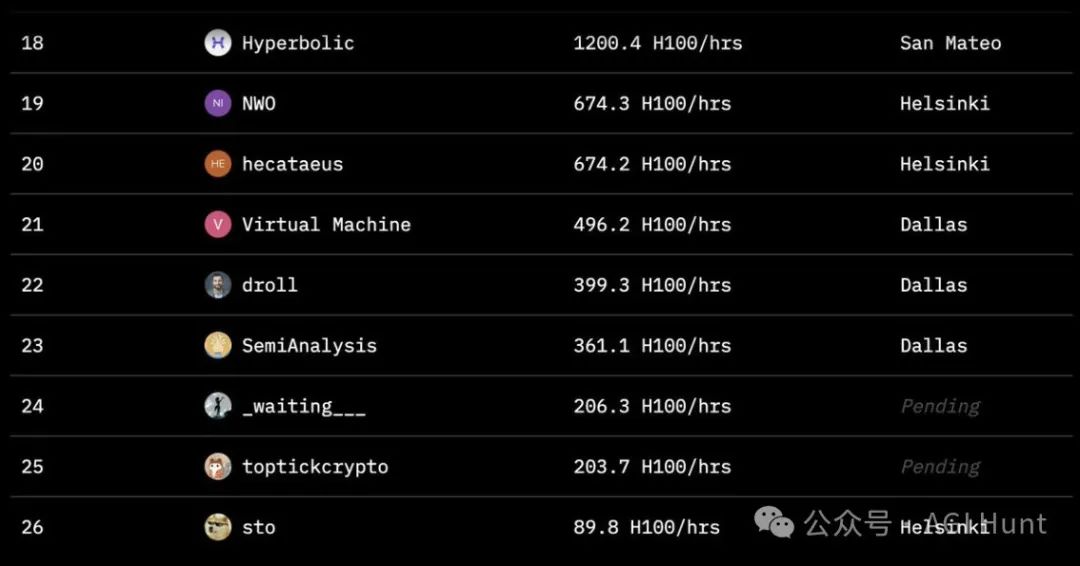
Varias organizaciones, entre ellas Hugging Face, SemiAnalysis, Arcee.ai, Hyperbolic Labs, Olas, Akash, Schelling AI y otras, aportaron valiosos recursos aritméticos al entrenamiento. Este modelo de cooperación sin precedentes demuestra un nuevo tipo de colaboración en IA.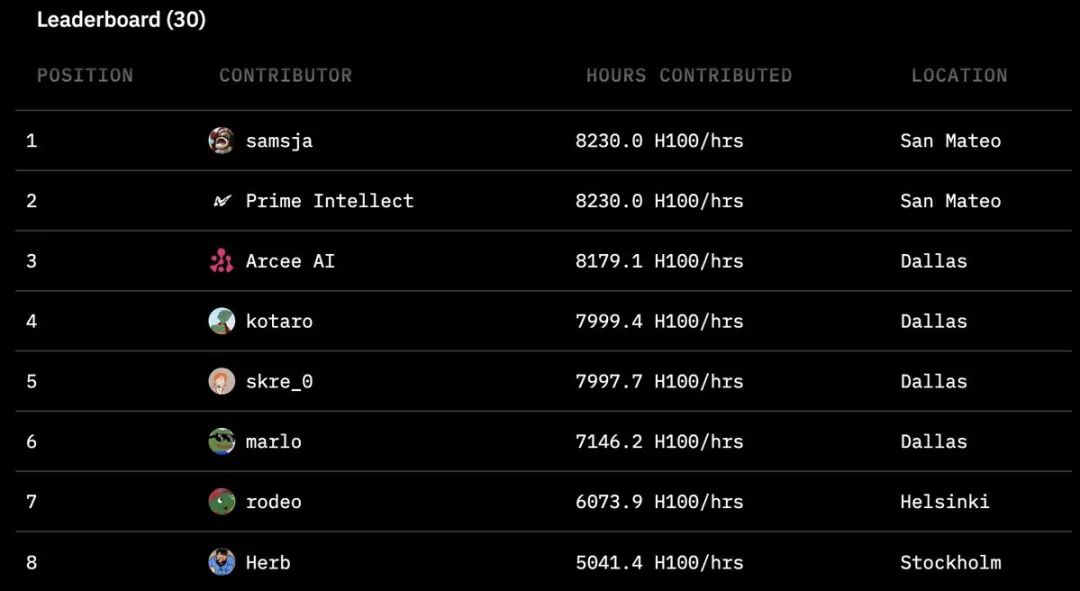 Como puede verse en la tabla de clasificación del proyecto, colaboradores de todo el mundo han aportado una asombrosa cantidad de tiempo de cálculo. El mayor contribuyente alcanzó las 8.230 horas, con participantes repartidos por San Mateo, Dallas, Helsinki y Estocolmo. Este modelo global de colaboración aritmética permite que el entrenamiento de la IA ya no se limite a los centros de datos de un puñado de gigantes tecnológicos.
Como puede verse en la tabla de clasificación del proyecto, colaboradores de todo el mundo han aportado una asombrosa cantidad de tiempo de cálculo. El mayor contribuyente alcanzó las 8.230 horas, con participantes repartidos por San Mateo, Dallas, Helsinki y Estocolmo. Este modelo global de colaboración aritmética permite que el entrenamiento de la IA ya no se limite a los centros de datos de un puñado de gigantes tecnológicos.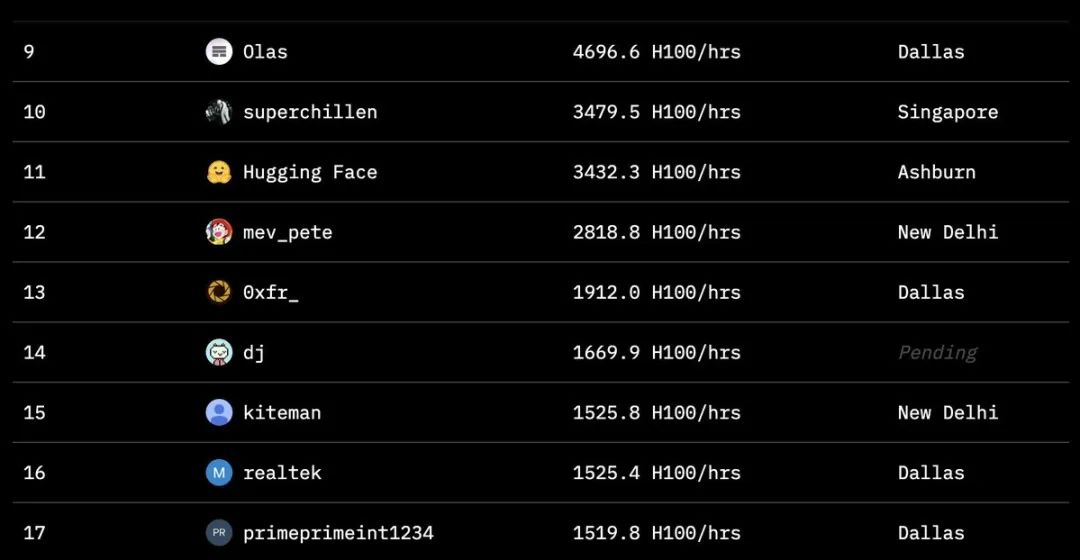
A nivel técnico, la innovación de este proyecto es igualmente impresionante.
El equipo adoptó la técnica de entrenamiento distribuido DiLoCo para hacer frente a los retos del entrenamiento entre regiones. Para hacer frente a los diversos retos de un entorno distribuido, el equipo de investigación también implementó mecanismos de entrenamiento tolerantes a fallos y técnicas de comprobación distribuida asíncrona.
En cuanto a la optimización de la memoria, el equipo optó por actualizar al marco FSDP2, que resolvió con éxito los problemas de asignación de memoria presentes en FSDP1.
Mientras tanto, la eficacia de la formación se mejora significativamente mediante la aplicación de la tecnología de computación paralela tensorial.
Detrás de estas innovaciones tecnológicas hay un sólido equipo de investigación que trabaja en silencio. El director del proyecto agradece especialmente a Tristan Rice y Junjie Wang sus aportaciones en formación tolerante a fallos, y a Chien-Chin Huang e Iris Zhang su trabajo en checkpointing distribuido asíncrono. También se agradece a Yifu Wang sus consejos sobre computación paralela tensorial.
Lo más emocionante es que el equipo ha anunciado que en una semana publicará la versión completa de código abierto, que incluirá el modelo base, los archivos de puntos de control, el modelo post-entrenamiento y el conjunto de datos de entrenamiento. Esto significa que investigadores y desarrolladores de todo el mundo pronto podrán innovar y desarrollar a partir de este modelo.
Ya hay desarrolladores impacientes por empezar a experimentar. Un desarrollador demostró un intento de inferencia del modelo en dos tarjetas gráficas 4090 en la costa oeste de Estados Unidos y en Europa. Aunque la conexión de red entre las dos ubicaciones no era ideal, este experimento demostró la flexibilidad y adaptabilidad del modelo.
El éxito de este proyecto no es sólo un avance tecnológico, sino un hito importante en la democratización de la IA para todos.
Es la prueba de que, gracias a la colaboración mundial, estamos bien situados para superar las limitaciones de la formación tradicional en IA y conseguir que más organizaciones y personas se sumen a la ola de desarrollo de la IA".
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...