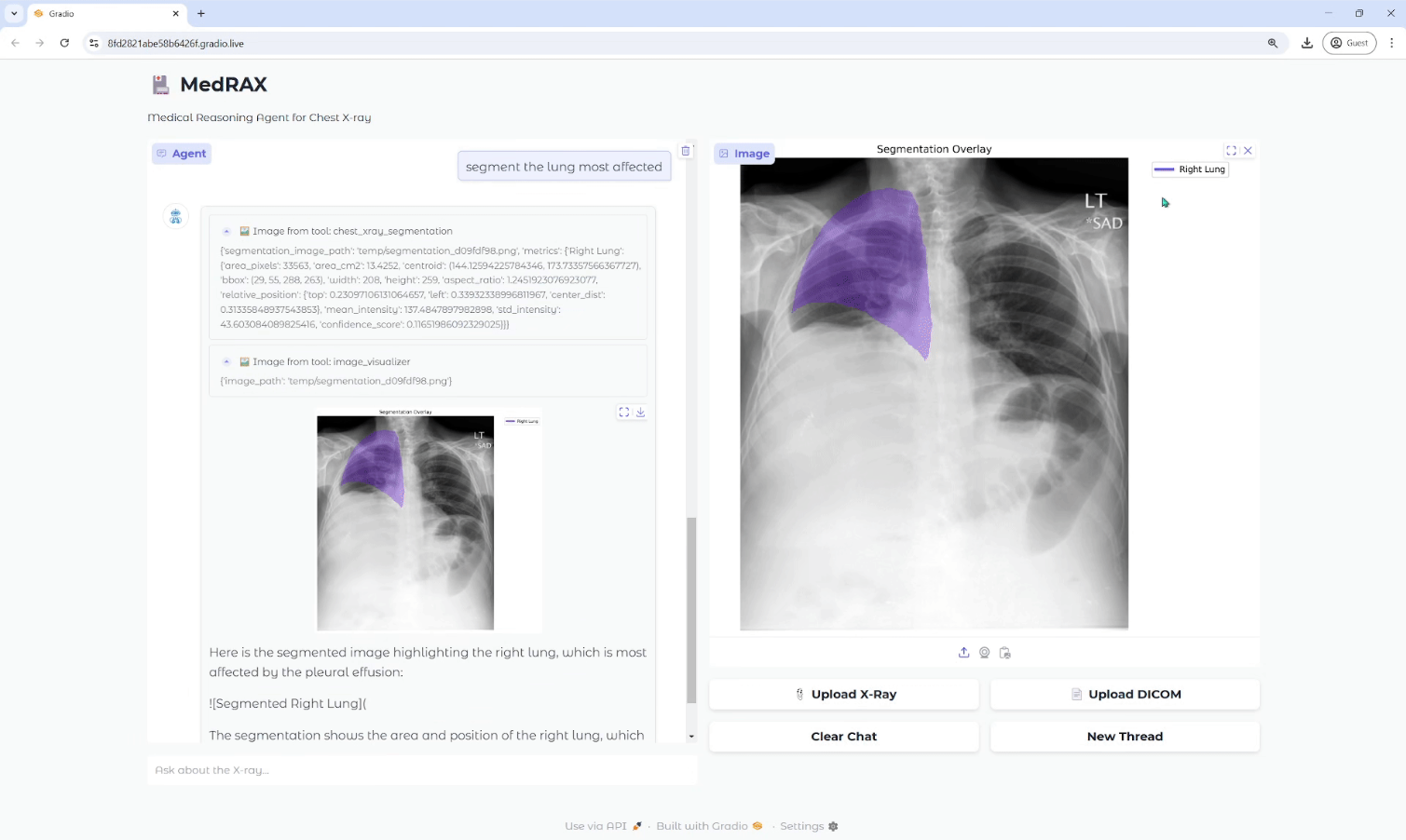
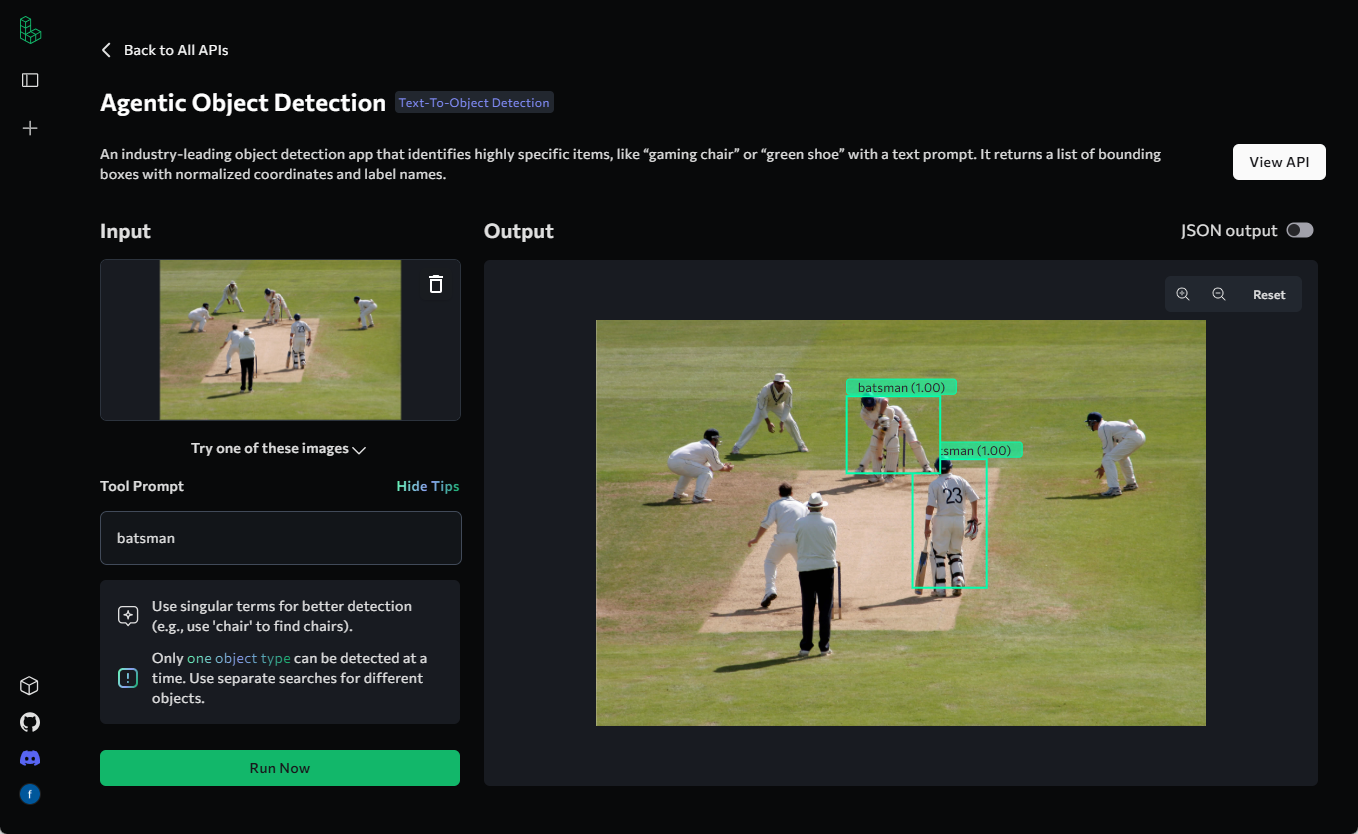
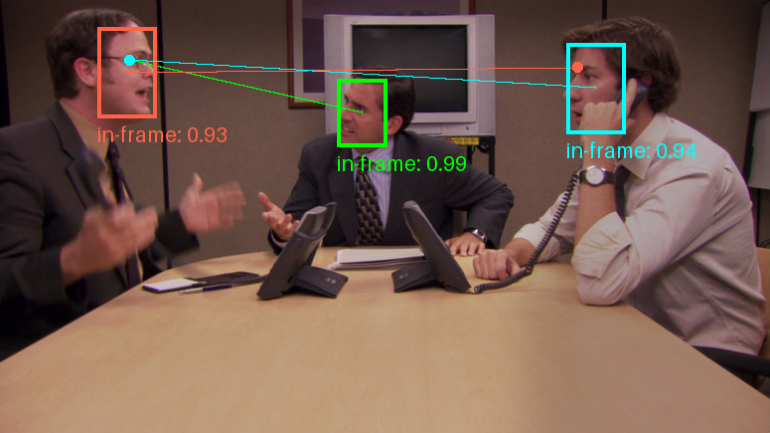
Trackers: biblioteca de herramientas de código abierto para el seguimiento de objetos en vídeo
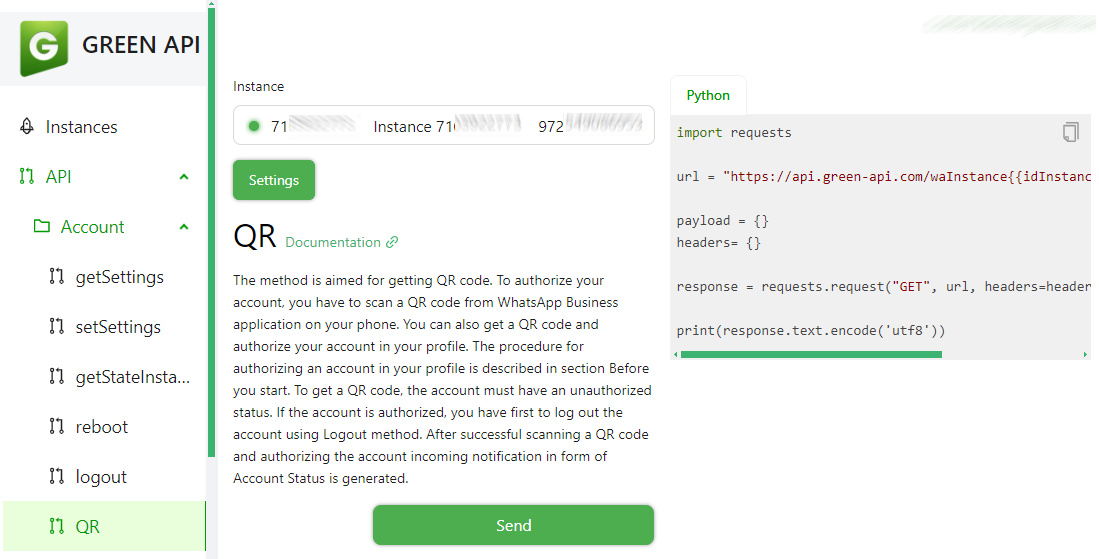
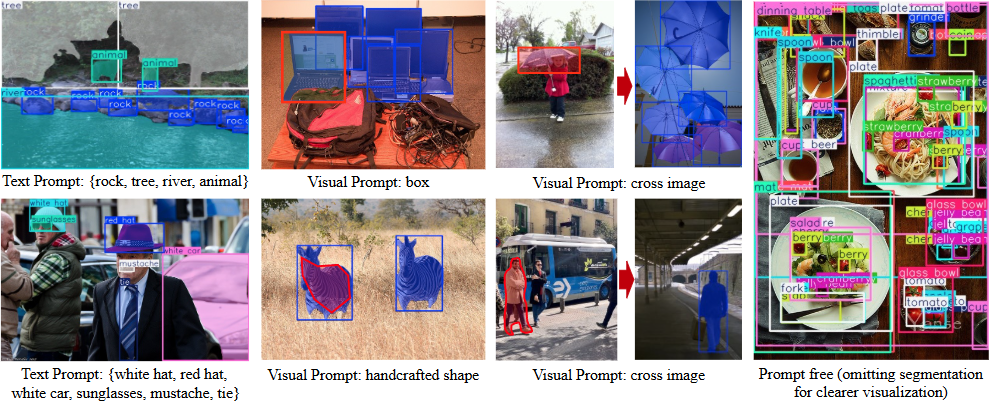
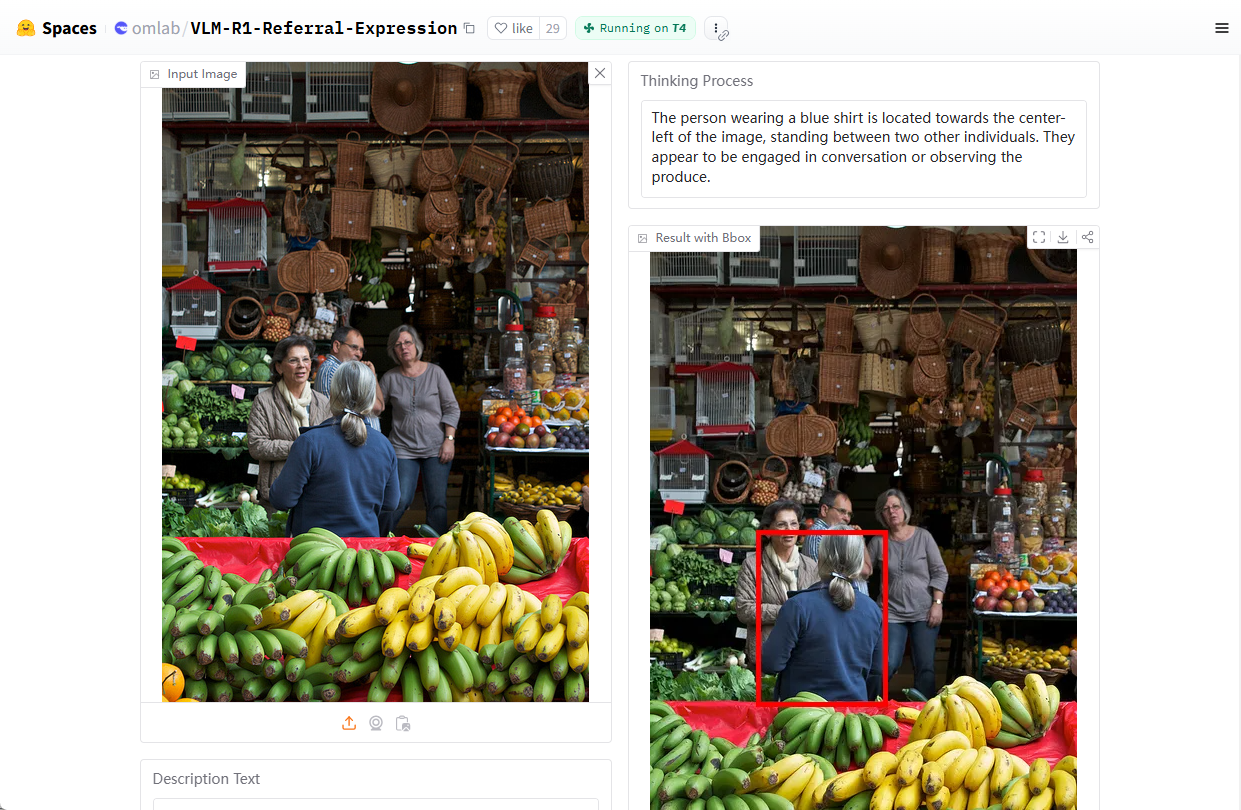
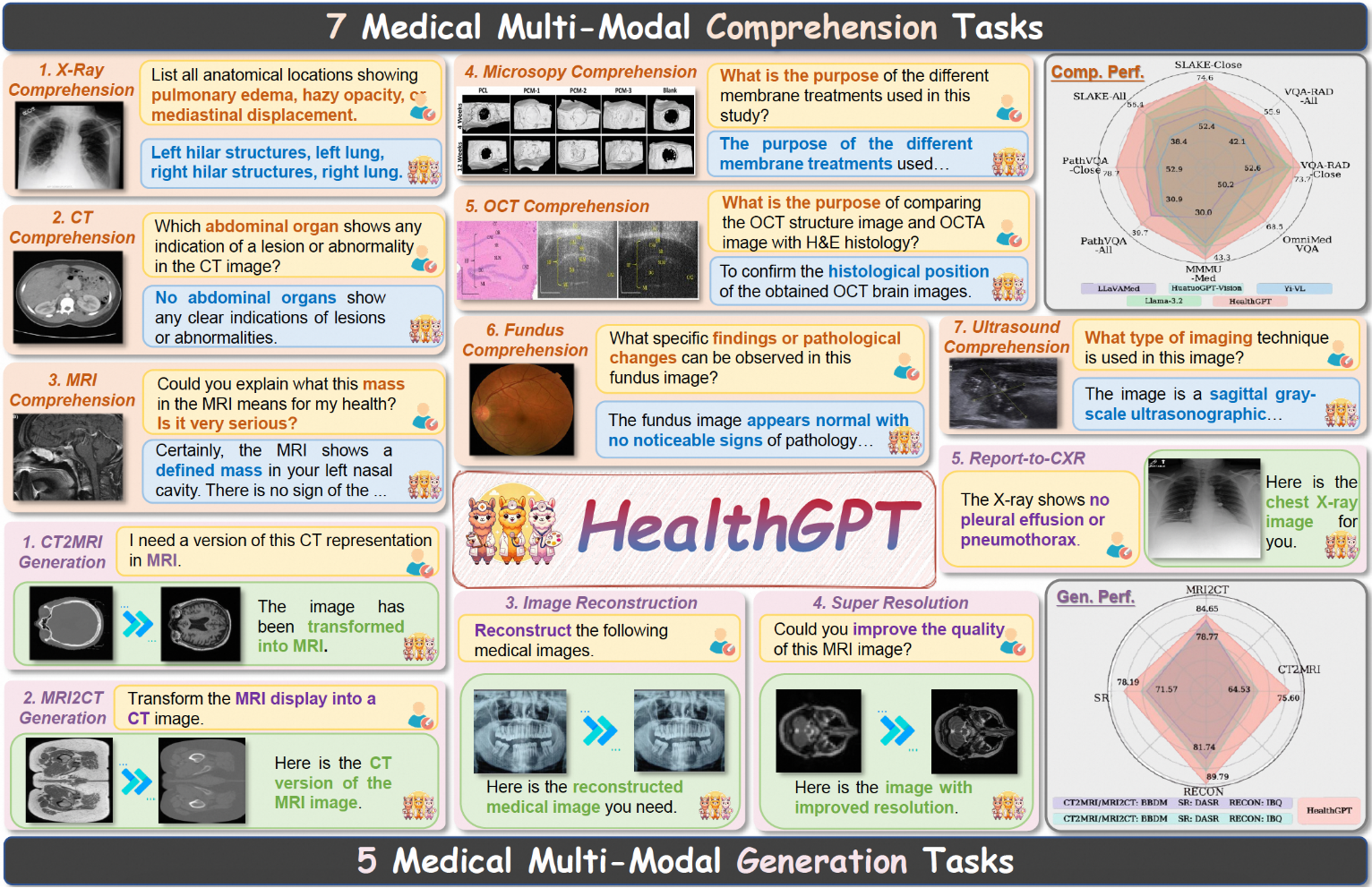
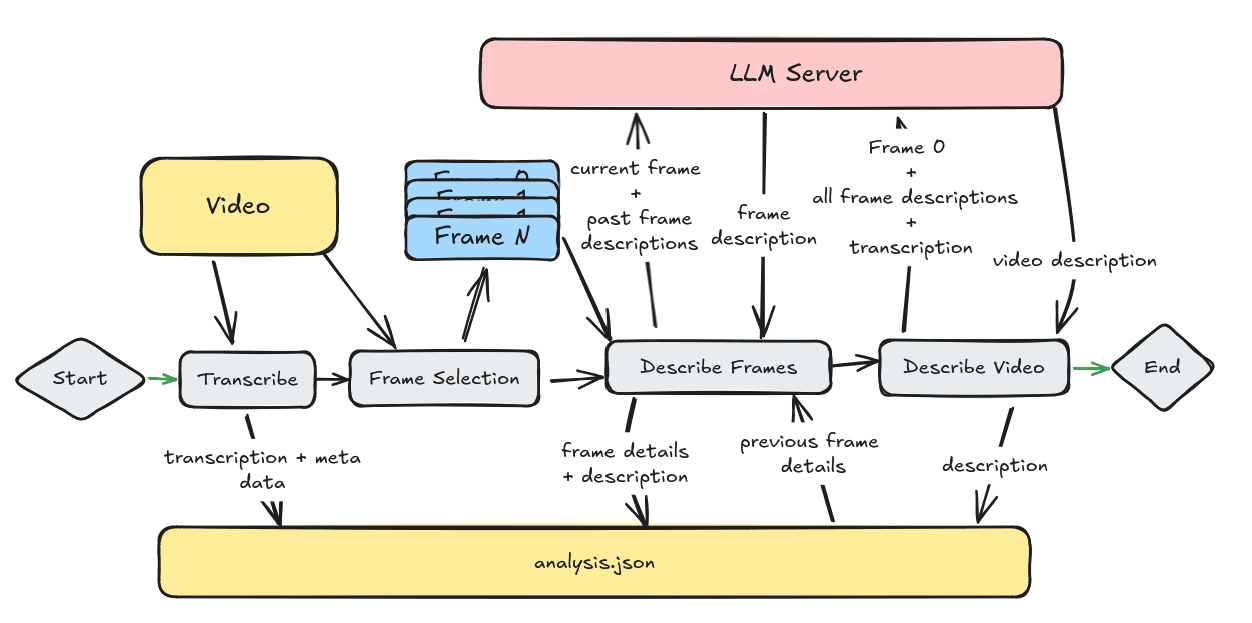
Introducción general Trackers es una biblioteca de herramientas Python de código abierto centrada en el seguimiento multiobjeto en vídeo. Integra varios algoritmos de seguimiento líderes, como SORT y DeepSORT, y permite a los usuarios combinar diferentes modelos de detección de objetos (como YOLO...