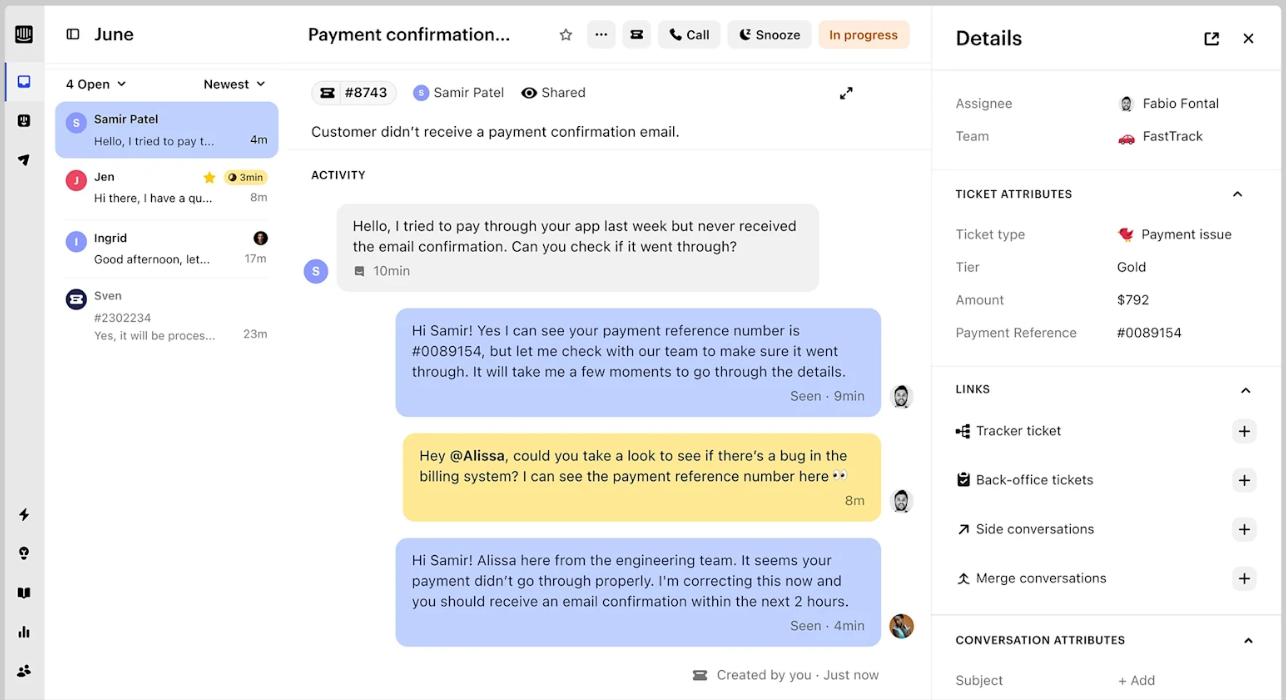
R1-Onevision: un modelo de lenguaje visual de código abierto para el razonamiento multimodal
Últimos recursos sobre IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 54.7K 00

Introducción general
R1-Onevision es un gran modelo de lenguaje multimodal de código abierto desarrollado por el equipo Fancy-MLLM, centrado en la combinación profunda de visión y lenguaje, capaz de procesar entradas multimodales como imágenes y texto, y de destacar en los campos del razonamiento visual, la comprensión de imágenes y la resolución de problemas matemáticos. Basado en Qwen2.5-VL Gracias a la optimización del modelo, R1-Onevision supera a modelos comparables como Qwen2.5-VL-7B en varias pruebas e incluso desafía las capacidades de GPT-4V. El proyecto está alojado en GitHub y proporciona pesos de modelos, conjuntos de datos y código adecuados para desarrolladores, investigadores para exploración académica o aplicaciones prácticas.2025 Desde su lanzamiento el 24 de febrero, ha recibido mucha atención y ha obtenido especialmente buenos resultados en tareas de razonamiento visual.

Lista de funciones
- inferencia multimodal: Soporte para tareas de razonamiento complejas que combinan imágenes y texto, como la resolución de problemas matemáticos y el análisis de problemas científicos.
- comprensión gráficaCapacidad para analizar el contenido de una imagen y generar una descripción detallada o responder a las preguntas pertinentes.
- Soporte de conjuntos de datos: Proporciona conjuntos de datos de R1-Onevision que contienen datos multidominio como escenas naturales, OCR, gráficos, etc.
- formación de modelosAdmite el ajuste fino supervisado de modelos completos (SFT) mediante el marco de trabajo de código abierto LLama-Factory.
- Evaluación del alto rendimientoDemuestra mejor razonamiento que tus compañeros en pruebas como Mathvision, Mathverse, etc.
- recurso de código abierto: Proporcionar modelos de pesos y códigos para facilitar el desarrollo secundario o la investigación.
Utilizar la ayuda
Proceso de instalación
R1-Onevision es un proyecto de código abierto basado en GitHub que requiere una cierta base de programación y configuración del entorno para ejecutarse. A continuación se ofrece una guía detallada de instalación y uso:
1. Preparación medioambiental
- sistema operativoSe recomienda Linux (por ejemplo, Ubuntu) o Windows (con WSL).
- requisitos de hardwareGPU NVIDIA : Se recomienda una GPU NVIDIA (con al menos 16 GB de memoria de vídeo, como A100 o RTX 3090) para soportar la inferencia y el entrenamiento del modelo.
- dependiente del software::
- Python 3.8 o posterior.
- PyTorch (recomendamos instalar la versión para GPU, consulte el sitio web de PyTorch).
- Git (para clonar repositorios de código).
2. Clonación de almacenes
Abra un terminal y ejecute el siguiente comando para obtener el código del proyecto R1-Onevision:
git clone https://github.com/Fancy-MLLM/R1-Onevision.git
cd R1-Onevision
3. Instalación de dependencias
El proyecto depende de varias bibliotecas de Python, que pueden instalarse con los siguientes comandos:
pip install -r requirements.txt
Si necesitas acelerar el razonamiento, te recomendamos instalar Flash Attention:
pip install flash-attn --no-build-isolation
4. Descarga de las ponderaciones de los modelos
R1-Onevision proporciona modelos preentrenados que pueden descargarse de Hugging Face:
- Visite la página del modelo Hugging Face.
- Descargue el archivo del modelo (por ejemplo
R1-Onevision-7B) y extráigalo al directorio del proyecto bajo la carpetamodels(debe crearse manualmente).
5. Entorno de configuración
Asegúrese de que CUDA está correctamente instalado y es compatible con PyTorch, lo que puede comprobarse ejecutando el siguiente código:
import torch
print(torch.cuda.is_available()) # 输出 True 表示 GPU 可用
Utilización
Razonamiento básico: análisis de imágenes y textos
R1-Onevision permite ejecutar tareas de inferencia mediante scripts de Python. A continuación se muestra un ejemplo de carga de un modelo y procesamiento de imágenes y texto:
- Redacción de guiones de razonamiento::
Cree un archivo en el directorio raíz del proyecto (por ejemploinfer.py), introduzca el siguiente código:
from transformers import AutoProcessor, Qwen2_5_VLForConditionalGeneration
import torch
from qwen_vl_utils import process_vision_info
# 加载模型和处理器
MODEL_ID = "models/R1-Onevision-7B" # 替换为模型实际路径
processor = AutoProcessor.from_pretrained(MODEL_ID, trust_remote_code=True)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
MODEL_ID, trust_remote_code=True, torch_dtype=torch.bfloat16
).to("cuda").eval()
# 输入图像和文本
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "path/to/your/image.jpg"}, # 替换为本地图像路径
{"type": "text", "text": "请描述这张图片的内容并回答:图中有几个人?"}
]
}
]
# 处理输入
inputs = processor(messages, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=512)
response = processor.decode(outputs[0], skip_special_tokens=True)
print(response)
- Ejecución de scripts::
python infer.py
El script mostrará una descripción de la imagen y una respuesta. Por ejemplo, si hay dos personas en la imagen, el modelo podría devolver: "La imagen muestra una escena de un parque con dos personas sentadas en un banco".
Artículo: Razonamiento matemático
R1-Onevisión destaca en el razonamiento matemático visual. Suponiendo una imagen que contiene un problema matemático (por ejemplo, "2x + 3 = 7, halla x"), se pueden seguir los siguientes pasos:
- modificaciones
messagesEl texto en dice: "Por favor, responde a la pregunta de matemáticas de esta imagen e indica los cálculos". - Ejecute el script y el modelo devolverá resultados similares a los siguientes:
图片中的题目是:2x + 3 = 7
解题过程:
1. 两边同时减去 3:2x + 3 - 3 = 7 - 3
2. 简化得:2x = 4
3. 两边同时除以 2:2x / 2 = 4 / 2
4. 得出:x = 2
最终答案:x = 2
Uso del conjunto de datos
R1-Onevision proporciona conjuntos de datos específicos que pueden utilizarse para afinar o probar el modelo:
- Descargar el conjunto de datos: Página del conjunto de datos Cara de abrazo.
- Los datos contienen pares de imagen y texto que pueden utilizarse directamente para el entrenamiento o la validación después de desempaquetarlos.
Ajuste de modelos
Si se requiere un modelo personalizado, se puede realizar un ajuste fino supervisado utilizando la LLama-Factory:
- Instalar LLama-Factory:
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -r requirements.txt
- Configure los parámetros de entrenamiento (consulte la documentación del proyecto) y ejecútelo:
python train.py --model_name models/R1-Onevision-7B --dataset path/to/dataset
Resumen del proceso operativo
- análisis de imágenesPrepara la ruta de la imagen, escribe el script y ejecútalo para obtener el resultado.
- razonamiento matemáticoSube una foto del tema, introduce una pregunta y consulta la respuesta detallada.
- Desarrollo a medidaDescarga el conjunto de datos y el modelo y ajusta los parámetros para el entrenamiento.
Ten en cuenta el uso de memoria de la GPU, se recomiendan al menos 16 GB de memoria de vídeo para garantizar un funcionamiento fluido.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...