
Qwen3-Omni - Modelo de IA omnimodal presentado por Ali Tongyi
Últimos recursos sobre IAPublicado hace 6 meses Círculo de intercambio de inteligencia artificial 38.2K 00

Qué es Qwen3-Omni
Qwen3-Omni es un modelo de IA totalmente modal presentado por el equipo de Ali Tongyi, capaz de manejar múltiples tipos de datos como texto, imagen, audio y vídeo, que admite la interacción con texto en 119 idiomas, con baja latencia y características altamente controlables. Gracias a su innovador diseño arquitectónico y su sólido rendimiento, Qwen3-Omni supera a varios modelos conocidos en pruebas de referencia de audio y audio-vídeo. El modelo admite la personalización y la invocación de herramientas, y puede utilizarse ampliamente en la creación de contenidos, la atención al cliente inteligente, la educación, la asistencia médica y otros campos, aportando a los usuarios una experiencia de interacción multimodal eficiente e inteligente.
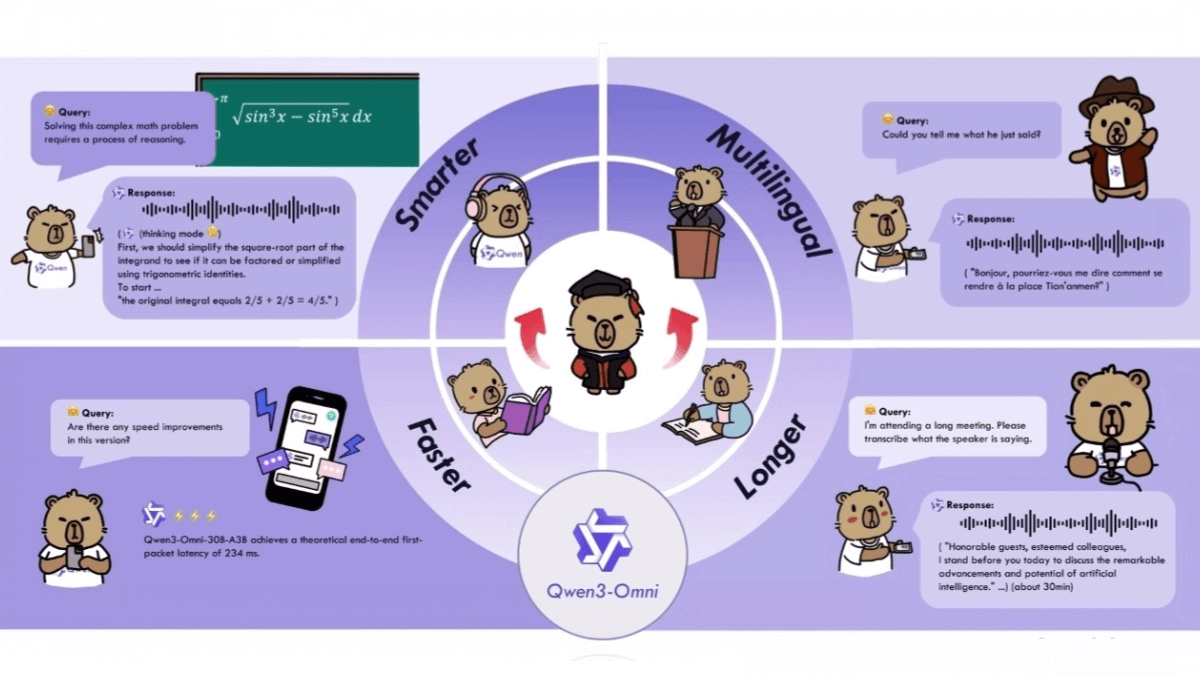
Características funcionales de Qwen3-Omni
- interacción totalmente modalEl modelo puede manejar sin problemas datos multimodales, como texto, imagen, audio y vídeo, y lograr un procesamiento de fusión multimodal, como la generación del contenido de imagen o audio correspondiente basado en texto, o la comprensión de la información en imágenes y audio, y la salida de descripciones de texto.
- Alto rendimientoQwen3-Omni ha obtenido excelentes resultados en una amplia gama de pruebas comparativas de audio y vídeo, superando a modelos muy conocidos.
- Soporte multilingüe: Admite la interacción textual en varios idiomas, puede, comprender y generar contenido textual en varios idiomas, satisface las necesidades de usuarios de distintos idiomas y dispone de sólidas capacidades lingüísticas globalizadas.
- respuesta rápida: La baja latencia del diálogo de audio de extremo a extremo del modelo permite procesar y responder rápidamente al audio entrante, proporcionando una experiencia interactiva en tiempo real.
- Procesamiento de audio de larga duración: El modelo admite hasta 30 minutos de comprensión de audio y puede manejar contenidos de audio más largos sin degradación del rendimiento ni incapacidad de procesamiento.
- PersonalizaciónLos usuarios pueden personalizar las indicaciones del sistema y otras palabras del modelo según sus propias necesidades, y modificar el estilo de respuesta, el personaje, etc., para que el modelo se adapte mejor a los distintos escenarios de uso y a las preferencias de los usuarios.
- Capacidad de mecanizadoEl modelo dispone de una potente función de invocación de herramientas incorporada, que puede integrarse eficazmente con herramientas o servicios externos para conseguir funciones y aplicaciones más complejas, ampliando el ámbito de aplicación y la utilidad del modelo.
Rendimiento de Qwen3-Omni
- Evaluación exhaustiva del rendimientoEl Qwen3-Omni demuestra una excelente capacidad de procesamiento multimodal. En tareas unimodales, el rendimiento es comparable al de la familia de modelos unimodales Qwen del mismo tamaño, con una ventaja significativa en tareas de audio.
- 36 puntos de referencia audio/vídeoQwen3-Omni alcanza el mejor rendimiento en el espacio de código abierto en 32 pruebas y el mejor del sector (SOTA) en 22 pruebas, superando a potentes modelos de código cerrado como Gemini-2.5-Pro, Seed-ASR, GPT-4o-Transcribe, etc.
Principales ventajas de Qwen3-Omni
- Verdadera capacidad modal completaQwen3-Omni es un macromodelo nativo multimodal que puede procesar simultáneamente datos multimodales como texto, imagen, audio y vídeo con un excelente rendimiento en todas las modalidades sin reducir la capacidad de procesamiento de una sola modalidad debido a la fusión multimodal.
- Potente rendimiento y eficienciaQwen3-Omni supera a muchos modelos conocidos en una serie de pruebas comparativas de audio y vídeo, demostrando un rendimiento sobresaliente. El modelo presenta una baja latencia -tan baja como 211 ms para conversaciones de audio y 507 ms para conversaciones de vídeo- y responde rápidamente a las entradas del usuario para ofrecer una experiencia interactiva fluida.
- Soporte en varios idiomasEl modelo admite 119 lenguas de texto y múltiples lenguas de comprensión y generación del habla, lo que le permite satisfacer las necesidades de usuarios de distintas lenguas en todo el mundo y tiene un gran potencial de aplicación internacional.
- Altamente personalizable y flexibleLos usuarios pueden personalizar el modelo según sus propias necesidades, como modificar el estilo de respuesta, el personaje, etc., y ajustar el comportamiento del modelo mediante palabras de aviso del sistema, etc., para que el modelo pueda adaptarse mejor a los distintos escenarios de aplicación y preferencias de los usuarios.
- Código abierto y diseño arquitectónico innovadorQwen3-Omni se basa en la innovadora arquitectura Thinker-Talker y la tecnología multicodebook, etc., para mejorar el rendimiento y la eficiencia del modelo y ofrecer a los desarrolladores más margen para la innovación. La naturaleza de código abierto del modelo facilita a los desarrolladores la investigación y el desarrollo de aplicaciones, lo que impulsa un mayor desarrollo de la tecnología.
¿Cuál es la página web oficial de Qwen3-Omni?
- Página web del proyecto:: https://qwen.ai/blog?id=65f766fc2dcba7905c1cb69cc4cab90e94126bf4&from=research.latest-advancements-list
- Repositorio GitHub:: https://github.com/QwenLM/Qwen3-Omni
- Biblioteca de modelos HuggingFace:: https://huggingface.co/collections/Qwen/qwen3-omni-68d100a86cd0906843ceccbe
- Documentos técnicos:: https://github.com/QwenLM/Qwen3-Omni/blob/main/assets/Qwen3_Omni.pdf
Personas para las que Qwen3-Omni es adecuado
- creador de contenidos: El modelo genera material creativo de texto, imagen, audio y vídeo de alta calidad, lo que proporciona a los creadores inspiración y una mayor eficacia.
- Equipo corporativo y de atención al clienteEl modelo, con funciones de interacción de texto y voz en varios idiomas, puede responder con rapidez y precisión a las preguntas de los clientes, lo que mejora la eficacia del servicio de atención al cliente y la experiencia del usuario.
- Educadores y estudiantesEl modelo puede generar materiales didácticos personalizados, ayudar a los profesores a diseñar contenidos didácticos que respondan a las distintas necesidades de aprendizaje y mejorar la eficacia de la enseñanza y el aprendizaje.
- Profesionales de la industria médicaEl modelo puede procesar datos multimodales, como imágenes médicas y grabaciones de voz, para ayudar a los médicos a diagnosticar y formular planes de tratamiento, y mejorar la eficiencia del trabajo médico.
- Profesionales de la industria del entretenimiento y multimedia: Los modelos pueden componer música, generar guiones de vídeo, diseñar argumentos de juegos, etc., lo que proporciona un rico material creativo para el entretenimiento y la creación de contenidos multimedia.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...