LongBench v2: Evaluación de textos largos +o1?


Evaluación de grandes modelos de "comprensión y razonamiento profundos" en el mundo real, textos largos y tareas múltiples
En los últimos años, se ha avanzado mucho en el estudio de los grandes modelos lingüísticos para textos largos, habiéndose ampliado la longitud de la ventana contextual de los modelos desde los 8k iniciales hasta 128k o incluso 1M de tokens. sin embargo, sigue planteándose una pregunta clave: ¿comprenden realmente estos modelos los textos largos que tratan? En otras palabras, ¿son capaces de comprender, aprender y razonar en profundidad a partir de la información de los textos largos?
Para responder a esta pregunta e impulsar el avance de los modelos de texto largo para la comprensión y el razonamiento en profundidad, un equipo de investigadores de la Universidad de Tsinghua y Smart Spectrum han lanzado LongBench v2, una prueba de referencia diseñada para evaluar las capacidades de comprensión y razonamiento en profundidad de los LLM en la multitarea de texto largo en el mundo real.
Creemos que LongBench v2 avanzará en la exploración de cómo escalar la computación en tiempo de inferencia (por ejemplo, el modelo o1) puede ayudar a resolver problemas de comprensión profunda e inferencia en escenarios de textos largos.
especificidades
LongBench v2 presenta varias características significativas con respecto a los puntos de referencia existentes para la comprensión de textos largos:
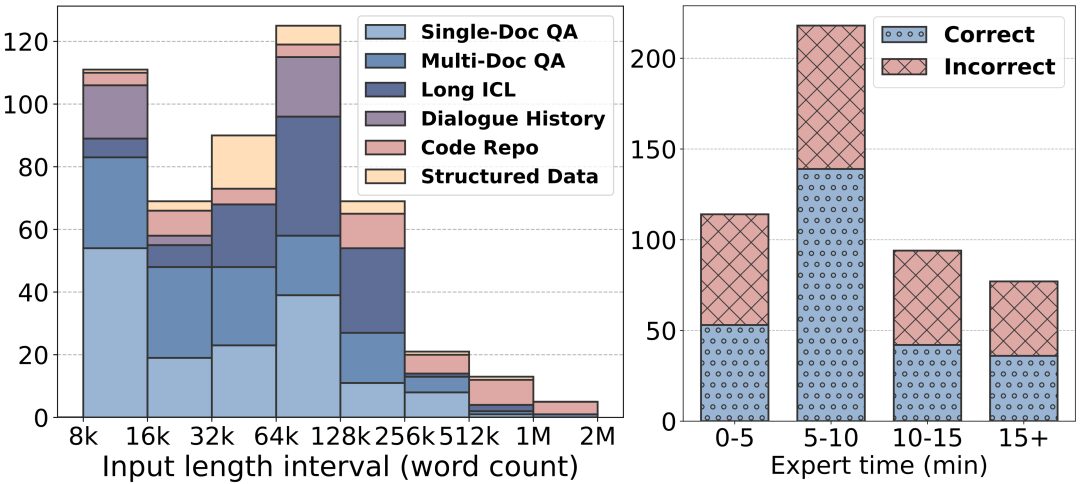
Textos de mayor longitud: la longitud de los textos de LongBench v2 oscila entre 8.000 y 2.000 palabras, y la mayor parte del texto tiene menos de 128.000 palabras.
Mayor dificultad: LongBench v2 contiene 503 desafiantes preguntas tipo test de cuatro opciones, preguntas que incluso los expertos humanos que utilizan la herramienta de búsqueda en documentos tendrían dificultades para responder correctamente en un breve periodo de tiempo. Los expertos humanos sólo acertaron una media de 53,71 TP3T (251 TP3T al azar) en el tiempo límite de 15 minutos.
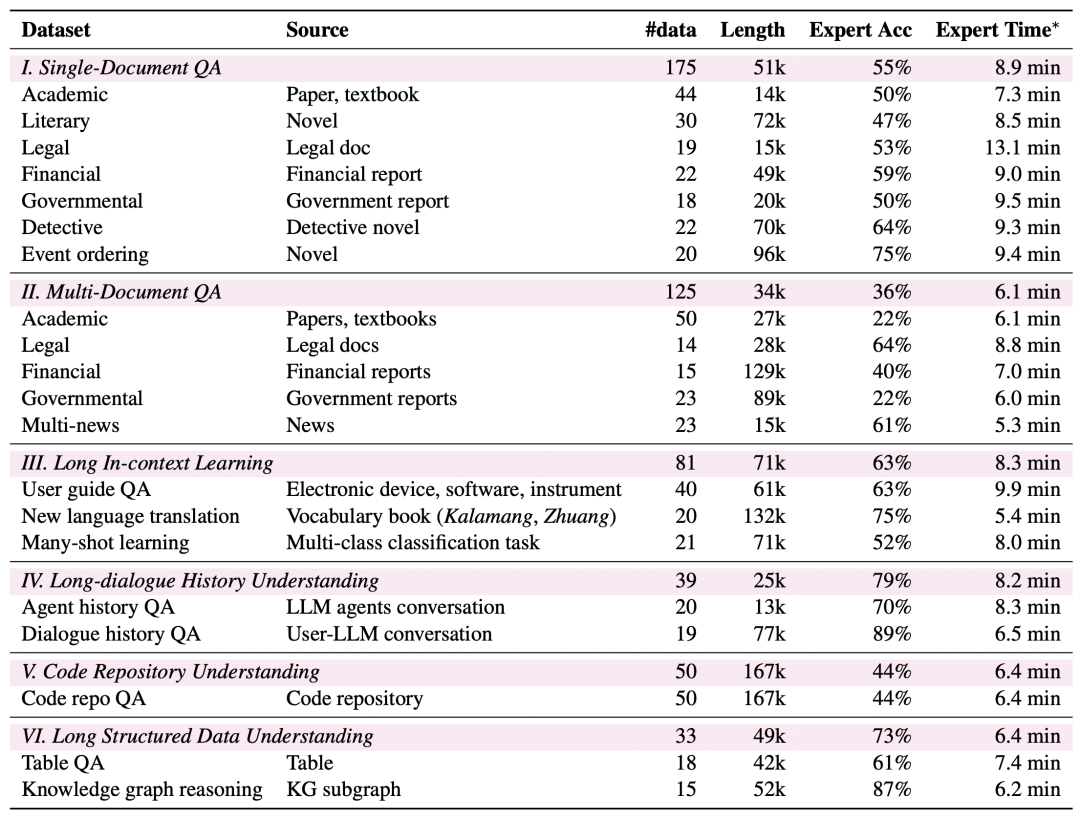
Cobertura de tareas más amplia: LongBench v2 abarca seis categorías de tareas principales, entre las que se incluyen el cuestionario de un solo documento, el cuestionario de varios documentos, el aprendizaje contextual de textos largos, la comprensión del historial de diálogos largos, la comprensión de repositorios de código y la comprensión de datos estructurados largos, con un total de 20 subtareas que cubren una gran variedad de escenarios del mundo real.
Mayor fiabilidad: Para garantizar la fiabilidad de la evaluación, todas las preguntas de LongBench v2 tienen formato de opción múltiple y se someten a un riguroso proceso manual de etiquetado y revisión para garantizar la alta calidad de los datos.
Proceso de recogida de datos
Para garantizar la calidad y dificultad de los datos, LongBench v2 emplea un riguroso proceso de recopilación de datos que consta de los siguientes pasos:
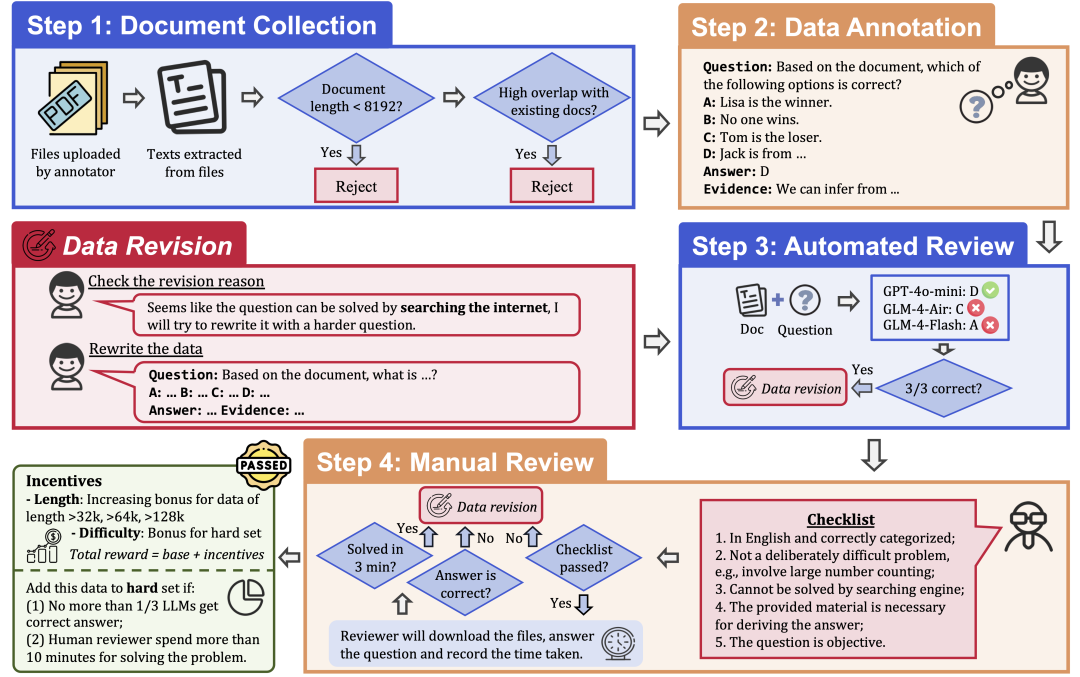
Recopilación de documentos: Contrate a 97 anotadores de las mejores universidades, con formación y grados académicos diversos, para que recopilen documentos extensos que hayan leído o utilizado personalmente, como trabajos de investigación, libros de texto, novelas, etc.
Etiquetado de datos: a partir de los documentos recopilados, el etiquetador formula una pregunta tipo test con cuatro opciones, una respuesta correcta y las pruebas correspondientes.
Revisión automática: Los datos anotados se revisaron automáticamente utilizando tres LLM (GPT-4o-mini, GLM-4-Air y GLM-4-Flash) con ventanas de contexto de 128k, y si los tres modelos respondían correctamente a la pregunta, ésta se consideraba demasiado simple y había que reetiquetarla.
Revisión humana: Los datos que superan la revisión automatizada son asignados a una revisión humana a cargo de 24 expertos humanos profesionales que intentan responder a la pregunta y determinar si la pregunta es adecuada y la respuesta es correcta. Si el experto es capaz de responder correctamente a la pregunta en 3 minutos, se considera que la pregunta es demasiado simple y debe ser reetiquetada. Además, si el experto considera que la pregunta en sí es inadecuada o que la respuesta es incorrecta, se devolverá para que se vuelva a calificar.
Revisión de datos: los datos que no superen la auditoría se devolverán al anotador para que los revise hasta que superen todos los pasos de la auditoría.
Resultados de la evaluación
El equipo evaluó 10 LLM de código abierto y 6 LLM de código cerrado utilizando LongBench v2. En la evaluación se consideraron dos escenarios: disparo cero frente a disparo cero+CoT (es decir, dejar que el modelo emita primero la cadena de pensamiento y, a continuación, dejar que el modelo emita la respuesta elegida).
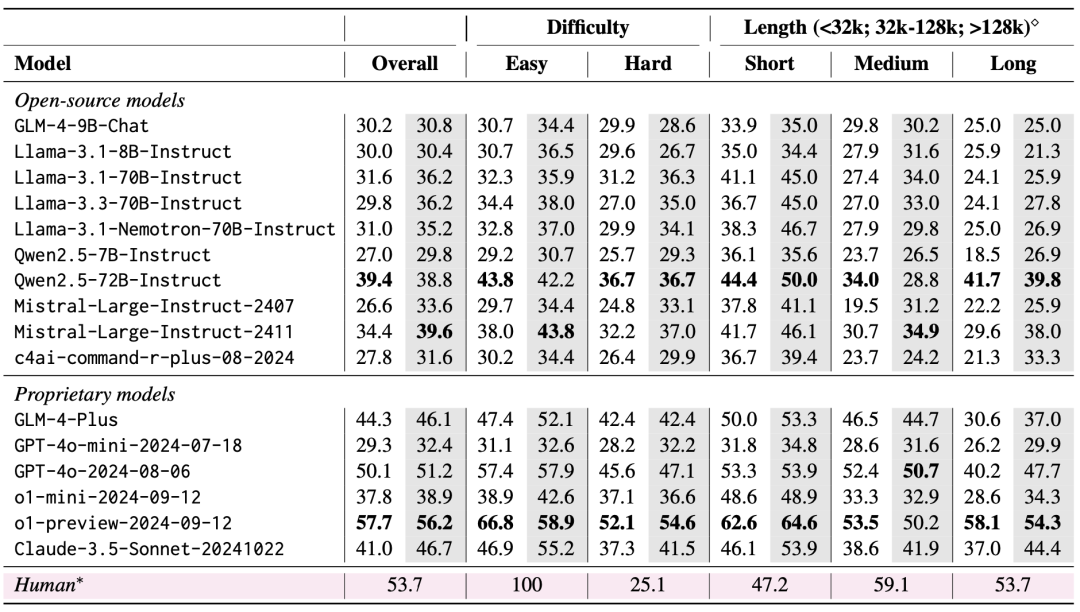
Los resultados de la evaluación muestran que LongBench v2 es un gran reto para los LLM actuales, ya que incluso el modelo con mejor rendimiento alcanza una precisión de sólo 50,1% con la salida de respuesta directa, mientras que el modelo o1-preview, que introduce una cadena de inferencia más larga, alcanza una precisión de 57,7%, que supera al experto humano en 4%.
1. Importancia de escalar el cálculo del tiempo de inferencia
Un hallazgo muy importante en los resultados de la evaluación es que el rendimiento de los modelos en LongBench v2 puede mejorarse significativamente escalando el cálculo del tiempo de inferencia. Por ejemplo, el modelo o1-preview consigue mejoras significativas en tareas como el cuestionario multidocumento, el aprendizaje contextual de textos largos y la comprensión de repositorios de código integrando más pasos de inferencia en comparación con GPT-4o.
Esto sugiere que LongBench v2 impone mayores exigencias a las capacidades de razonamiento de los modelos actuales, y que aumentar el tiempo dedicado a pensar y razonar sobre el razonamiento parece ser un paso natural y crítico para resolver retos de razonamiento textual tan largos.
2. RAG + Experimentos de contexto largo

Se observa que ambos modelos, Qwen2.5 y GLM-4-Plus, no muestran una mejora significativa del rendimiento o incluso lo degradan una vez que el número de bloques recuperados supera un determinado umbral (32k tokens, unos 64 bloques de 512 de longitud).
Esto sugiere que el simple aumento de la cantidad de información recuperada no siempre conduce a mejoras en el rendimiento. En cambio, GPT-4o es capaz de utilizar eficientemente contextos de recuperación más largos con un rendimiento óptimo. RAG El rendimiento se produce con una longitud de recuperación de 128k.
En resumen, la utilidad de la GAR es limitada cuando se enfrenta a tareas de preguntas y respuestas textuales largas que requieren una comprensión y un razonamiento profundos, especialmente cuando el número de bloques recuperados supera un determinado umbral. El modelo debe disponer de mayores capacidades de razonamiento, en lugar de basarse únicamente en la información recuperada, para poder afrontar con eficacia los difíciles problemas de LongBench v2.
Esto también implica que las futuras líneas de investigación también deben centrarse más en cómo mejorar las propias capacidades de comprensión y razonamiento de textos largos del modelo, en lugar de depender únicamente de la recuperación externa.
Esperamos que LongBench v2 amplíe los límites de las técnicas de comprensión y razonamiento de textos largos. No dude en leer nuestro artículo, utilizar nuestros datos y aprender más.
Página de inicio: https://longbench2.github.io
Tesis: https://arxiv.org/abs/2412.15204
Datos y códigos: https://github.com/THUDM/LongBench
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Puestos relacionados


Sin comentarios...