Kimi lanza MoBA: ¡un gran avance para hacer posible el contexto infinito!

La mezcla de expertos y la atención dispersa hacen posibles contextos prácticamente ilimitados. Permite al agente de IA RAG devorar bases de código y documentos enteros sin limitaciones contextuales.
📌 El reto de la atención contextual prolongada
Los transformadores siguen enfrentándose a una pesada carga computacional cuando las secuencias se hacen muy grandes. El modelo de atención por defecto toma cada ficha La comparación con todos los demás tokens supone un aumento cuadrático del coste computacional. Esta sobrecarga se convierte en un problema cuando se leen bases de código completas, documentos de varios capítulos o grandes cantidades de texto legal.
📌 MoBA
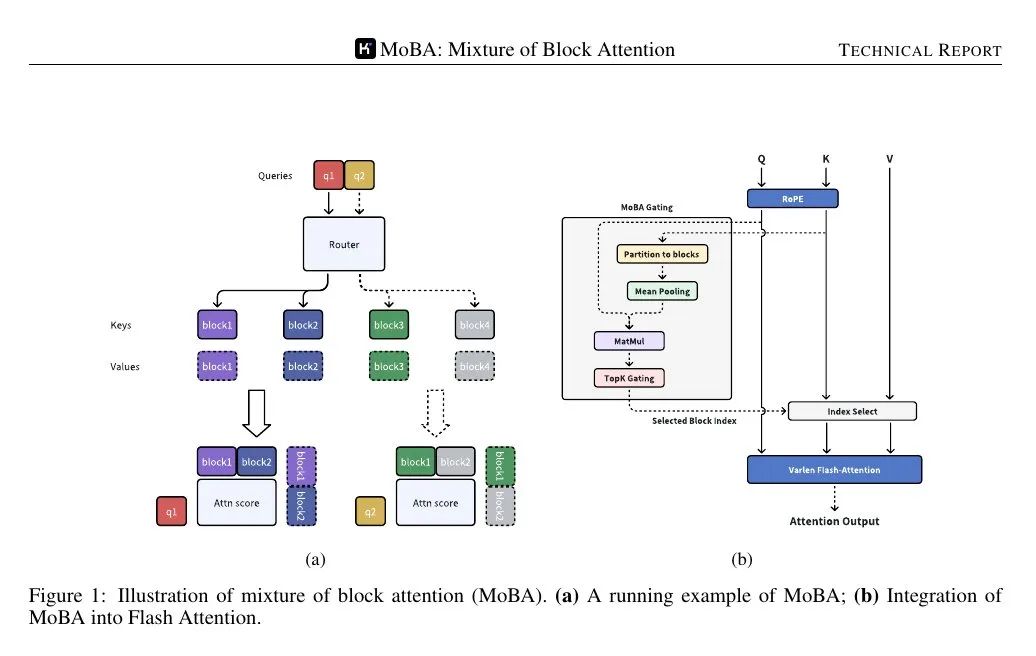
MoBA (Mixture of Block Attention) aplica el concepto de mezcla de expertos al mecanismo de atención. El modelo divide la secuencia de entrada en varios bloques y, a continuación, una función de compuerta entrenable calcula la puntuación de correlación entre cada símbolo de consulta y cada bloque. En el cálculo de la atención sólo se utilizan los bloques con mayor puntuación, evitando así prestar atención a cada uno de los tokens de la secuencia completa.
Los bloques se definen dividiendo la secuencia en tramos iguales. Cada token de consulta examina la representación agregada de las claves de cada bloque (por ejemplo, utilizando la agrupación de medias) y, a continuación, clasifica su importancia, seleccionando unos pocos bloques para el cálculo detallado de la atención. Siempre se selecciona el bloque que contiene la consulta. El enmascaramiento causal garantiza que las fichas no vean información futura, manteniendo un orden de generación de izquierda a derecha.
📌 Cambio fluido entre atención dispersa y atención plena
MoBA sustituye al mecanismo de atención estándar, pero no cambia el número de parámetros. Es similar a la norma Transformador Las interfaces son compatibles, de modo que la atención dispersa y la atención plena pueden alternarse entre distintas capas o fases de entrenamiento. Algunas capas pueden reservar la atención plena para tareas específicas (por ejemplo, el ajuste fino supervisado), mientras que la mayoría de las capas utilizan MoBA para reducir el coste computacional.
📌 Esto se aplica a pilas Transformer más grandes, sustituyendo a las llamadas de atención estándar. El mecanismo de compuerta garantiza que cada consulta sólo se centre en un pequeño número de bloques. La causalidad se gestiona filtrando los bloques futuros y aplicando una máscara local dentro del bloque actual de la consulta.
📌 La figura siguiente muestra que la consulta se dirige sólo a algunos bloques "expertos" de claves/valores, no a toda la secuencia. Este mecanismo asigna cada consulta al bloque más relevante, lo que reduce la complejidad del cálculo de la atención de cuadrática a subcuadrática.
📌 El mecanismo de compuerta calcula una puntuación de correlación entre cada consulta y la representación cohesiva de cada bloque. A continuación, selecciona los k bloques con mayor puntuación para cada consulta, independientemente de lo atrás que se encuentren en la secuencia.
Dado que sólo se procesan unos pocos bloques por consulta, el cálculo sigue siendo subcuadrático, pero el modelo puede saltar a tokens alejados del bloque actual si la puntuación de gating muestra una alta correlación.
Implementación de PyTorch
Este pseudocódigo divide las claves y los valores en bloques, calcula una representación media agrupada de cada bloque y calcula la puntuación de compuerta (S) multiplicando la consulta (Q) por la representación agrupada.
📌 A continuación, aplica máscaras causales para garantizar que las consultas no puedan centrarse en bloques futuros, utiliza el operador top-k para seleccionar los bloques más relevantes para cada consulta y organiza los datos para un cálculo eficiente de la atención.
📌 FlashAtención se aplicaron al bloque autoatento (posición actual) y al bloque MoBA-seleccionado, respectivamente, y finalmente las salidas se fusionaron utilizando softmax online.
📌 El resultado final es un mecanismo de atención dispersa que preserva la estructura causal y captura las dependencias de largo alcance al tiempo que evita el coste computacional cuadrático completo de la atención estándar.

Este código combina la lógica de la mezcla de expertos con la atención dispersa, de modo que cada consulta se centra sólo en unos pocos bloques.
El mecanismo de compuerta puntúa cada bloque y consulta y selecciona a los k mayores "expertos", reduciendo así el número de comparaciones clave/valor.
Esto mantiene la sobrecarga computacional de la atención en un nivel subcuadrático, lo que permite procesar entradas extremadamente largas sin aumentar la carga computacional o de memoria.
Al mismo tiempo, el mecanismo de compuerta garantiza que la consulta pueda seguir centrándose en tokens distantes cuando sea necesario, preservando así la capacidad del Transformer para procesar el contexto global.
Esta estrategia basada en bloques y compuertas es exactamente la forma en que MoBA implementa contextos casi infinitos en LLM.

Observaciones experimentales
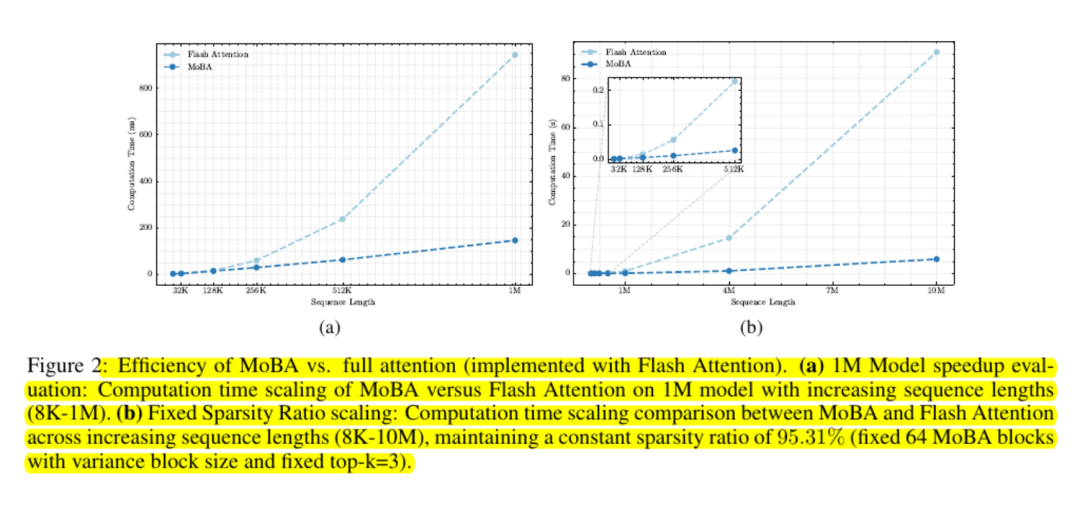
Los modelos que utilizan MoBA son casi comparables a los de atención plena en términos de pérdida de modelado del lenguaje y rendimiento en tareas posteriores. Los resultados son coherentes incluso con longitudes de contexto de cientos de miles o millones de tokens. Los experimentos evaluados con "tokens de cola" confirman que las dependencias importantes a larga distancia se siguen captando cuando la consulta identifica trozos relevantes.
Las pruebas de escalabilidad muestran que su curva de costes es subcuadrática. Los investigadores informan de aumentos de velocidad de hasta seis veces con un millón de fichas y mayores ganancias fuera de ese rango.
MoBA mantiene la facilidad de memoria evitando el uso de matrices de atención completas y utilizando núcleos de GPU estándar para el cálculo basado en bloques.
Observaciones finales
MoBA reduce la sobrecarga de atención con una idea sencilla: dejar que la consulta aprenda qué bloques son importantes e ignorar todos los demás.
Conserva la interfaz estándar de atención basada en softmax y evita imponer un modelo local rígido. Muchos modelos lingüísticos de gran tamaño pueden integrar este mecanismo de forma plug-and-play.
Esto hace que MoBA resulte muy atractivo para cargas de trabajo que necesitan tratar contextos extremadamente largos, como escanear una base de código completa o resumir documentos enormes, sin tener que realizar grandes cambios en los pesos de preentrenamiento o consumir mucha sobrecarga de reentrenamiento.

© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...