El modelo mini de 1,6B de código abierto "Little Fox" supera a los modelos similares Qwen y Gemma


desde (un tiempo) Chatgpt Desde su creación, el número de parámetros LLM (Large Language Models) parece ser una carrera de fondo para cada empresa. El recuento de parámetros del GPT-1 era de 117 millones (117M), y el de su cuarta generación, el GPT-4, se ha actualizado hasta 1,8 billones (1800B).
Al igual que otros modelos LLM como Bloom (176 mil millones, 176B) y Chinchilla (70 mil millones, 70B), el número de parámetros también se dispara. El número de parámetros influye directamente en el rendimiento y la capacidad del modelo: a mayor número de parámetros, el modelo es capaz de manejar patrones lingüísticos más complejos, comprender información contextual más rica y mostrar mayores niveles de inteligencia en una amplia gama de tareas.
Sin embargo, estos enormes parámetros también afectan directamente al coste de formación y al entorno de desarrollo de los LLM, y limitan la exploración de los LLM por parte de la mayoría de las empresas de investigación general, lo que provoca que los grandes modelos lingüísticos se conviertan gradualmente en una carrera armamentística entre las grandes empresas.
Recientemente, la empresa emergente de IA TensorOpera lanzó elPequeños modelos lingüísticos de código abierto FOX, demostrando a la industria que los Small Language Models (SLM) también pueden mostrar suficiente fuerza en el campo de la inteligencia.

FOX es unaPequeños modelos lingüísticos diseñados para la computación en nube y de borde. A diferencia de los grandes modelos lingüísticos con decenas de miles de millones de parámetros, FOX Sólo 1.600 millones de parámetrosSin embargo, puede mostrar un rendimiento asombroso en múltiples tareas.
Título de la disertación:
INFORME TÉCNICO FOX-1
Enlace a la ponencia:
https://arxiv.org/abs/2411.05281

¿Quién es TensorOpera?
TensorOpera es una innovadora empresa de inteligencia artificial con sede en Silicon Valley, California. Anteriormente desarrollaron el ecosistema de IA generativa TensorOpera® AI Platform y la plataforma federal de aprendizaje y análisis TensorOpera® FedML. El nombre de la empresa, TensorOpera, es una combinación de tecnología y arte, que simboliza el eventual desarrollo por parte de GenAI de sistemas de IA compuestos multimodales y multimodelos.

El Dr. Jared Kaplan, cofundador y consejero delegado de TensorOpera, ha declarado: "El modelo FOX se diseñó originalmente para reducir significativamente los requisitos de recursos informáticos manteniendo un alto rendimiento. Esto no solo hace que la tecnología de IA sea más accesible, sino que también reduce la barrera de uso para las empresas."
¿Cómo funciona el modelo Fox?
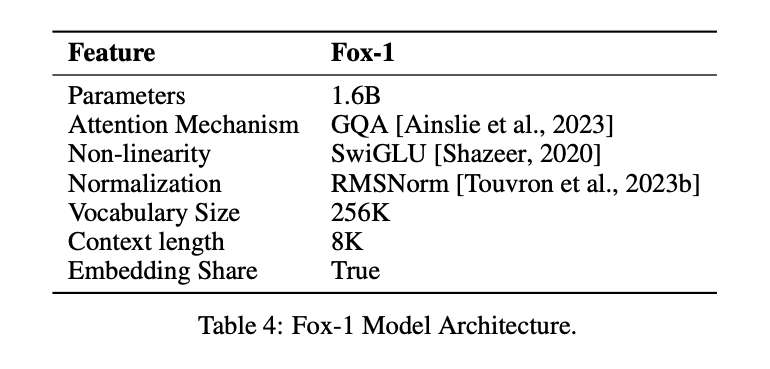
Para conseguir el mismo efecto que el LLM con un menor número de parámetros, el modelo Fox-1Sólo decodificadore introduce varias mejoras y rediseños para mejorar el rendimiento. Entre ellas se incluyen
① capa de redEn el diseño de arquitecturas de modelos, las redes neuronales más anchas y superficiales tienen mejores capacidades de memoria, mientras que las redes más profundas y delgadas presentan mayores capacidades de inferencia. Siguiendo este principio, Fox-1 utiliza una arquitectura más profunda que la mayoría de los SLM modernos. En concreto, Fox-1 consta de 32 capas autoatentivas, lo que supone 781 TP3T más que Gemma-2B (18 capas) y 331 TP3T más que StableLM-2-1.6B (24 capas) y Qwen1.5-1.8B (24 capas).
② Incrustación compartidaFox-1 utiliza 2.048 dimensiones ocultas para construir un total de 256.000 vocabularios con unos 500 millones de parámetros. Los modelos más grandes suelen utilizar capas de incrustación separadas para la capa de entrada (vocabulario a expresiones incrustadas) y la capa de salida (expresiones incrustadas a vocabulario). En el caso de Fox-1, sólo la capa de incrustación requiere 1.000 millones de parámetros. Para reducir el número total de parámetros, compartir las capas de incrustación de entrada y salida maximiza la utilización del peso.
(iii) prenormalizaciónFox-1 utiliza RMSNorm para normalizar las entradas de cada capa de transformación; RMSNorm es la opción preferida para la prenormalización en los modelos lingüísticos modernos a gran escala, y muestra una mayor eficacia que LayerNorm.
④ Codificación de posición rotativa (RoPE)Fox-1 acepta tokens de entrada de hasta 8K de longitud por defecto, y para mejorar el rendimiento en ventanas de contexto más largas, Fox-1 utiliza codificación posicional rotada, donde θ se fija en 10.000 para codificar ficha Dependencia posicional relativa entre
⑤ Atención a las Consultas en Grupo (GQA)Atención a consultas agrupadas: divide las cabezas de consulta de la capa de atención multicabezal en grupos, cada uno de los cuales comparte el mismo conjunto de cabezas clave-valor. Fox-1 está equipado con 4 cabezas clave-valor y 16 cabezas de atención para aumentar la velocidad de entrenamiento e inferencia y reducir el uso de memoria.
Además de modelar las mejoras estructurales.FOX-1 también mejora la tokenización y la formación..
la parte de la oración (en la gramática china)Fox-1 utiliza el clasificador Gemma basado en SentencePiece, que proporciona un vocabulario de 256K. Aumentar el tamaño del vocabulario tiene al menos dos ventajas principales. En primer lugar, la longitud de la información oculta en el contexto se amplía porque cada token codifica información más densa. Por ejemplo, un vocabulario de tamaño 26 sólo puede codificar un carácter en [a-z], pero un vocabulario de tamaño 262 puede codificar dos letras al mismo tiempo, lo que permite representar cadenas más largas en un token de longitud fija. En segundo lugar, un vocabulario de mayor tamaño reduce la probabilidad de que aparezcan palabras o frases desconocidas, lo que en la práctica se traduce en un mejor rendimiento en las tareas descendentes: el amplio vocabulario utilizado por Fox-1 produce menos tokens para un corpus de texto determinado, lo que se traduce en un mejor rendimiento en la inferencia.
Fox-1Datos previos al entrenamientoProcedentes de los conjuntos de datos Redpajama, SlimPajama, Dolma, Pile y Falcon, con un total de 3 billones de datos de texto. Para paliar la ineficacia del preentrenamiento para secuencias largas debido a su mecanismo de atención, Fox-1 introduce en la fase de preentrenamiento unUna estrategia de aprendizaje curricular en tres fasesFox-1 es un proceso de preentrenamiento de cursos en tres fases, en el que la longitud de los trozos de las muestras de entrenamiento aumenta gradualmente de 2.000 a 8.000 para garantizar una gran capacidad contextual con un coste reducido. Para ser coherente con el proceso de preentrenamiento de cursos en tres fases, Fox-1 reorganiza los datos brutos en tres conjuntos diferentes, que incluyen conjuntos de datos no supervisados y de ajuste de instrucciones, así como datos de diferentes dominios, como código, contenido web y documentos matemáticos y científicos.
El entrenamiento Fox-1 puede dividirse en tres fases.
- La primera fase consta de unas 39% muestras de datos totales a lo largo del proceso de preentrenamiento, donde el conjunto de datos de 1,05 billones de tokens se particiona en muestras de longitud 2.000, con un tamaño de lote de 2 M. En esta fase se utiliza un calentamiento lineal de 2.000epocs.
- La segunda fase incluye unas 591 muestrasTP3T con 1,58 billones de tokens y aumenta la longitud de los trozos de 2K a 4K y 8K. La longitud real de los trozos varía según las distintas fuentes de datos. Teniendo en cuenta que la segunda fase es la que lleva más tiempo e implica a distintas fuentes de diferentes conjuntos de datos, el tamaño del lote también se aumenta a 4M para mejorar la eficiencia del entrenamiento.
- Por último, en la tercera fase, el modelo Fox se entrena utilizando 6.200 millones de tokens (aproximadamente 0,02% del total) de datos de alta calidad, sentando las bases para diferentes capacidades de tareas posteriores, como el seguimiento de órdenes, las conversaciones triviales, las preguntas y respuestas específicas del dominio, etc.
¿Cómo le fue a Fox-1?
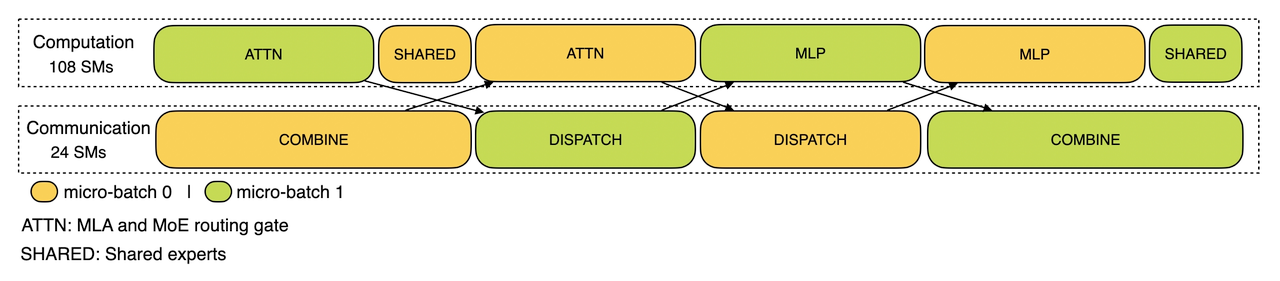
En comparación con los otros modelos SLM (Gemma-2B, Qwen1.5-1.8B, StableLM-2-1.6B y OpenELM1.1B), FOX-1 tiene más éxito en ARC Challenge (25 disparos), HellaSwag (10 disparos), TruthfulQA (0 disparos), MMLU (5 disparos), Winogrande (5 disparos), GSM8k (5 disparos), GSM8k (5 disparos) y GSM8k (5 disparos). MMLU (5 disparos), Winogrande (5 disparos), GSM8k (5 disparos)Las puntuaciones medias de la prueba comparativa para las seis tareas fueron las más altas y fueron significativamente mejores en el GSM8k.
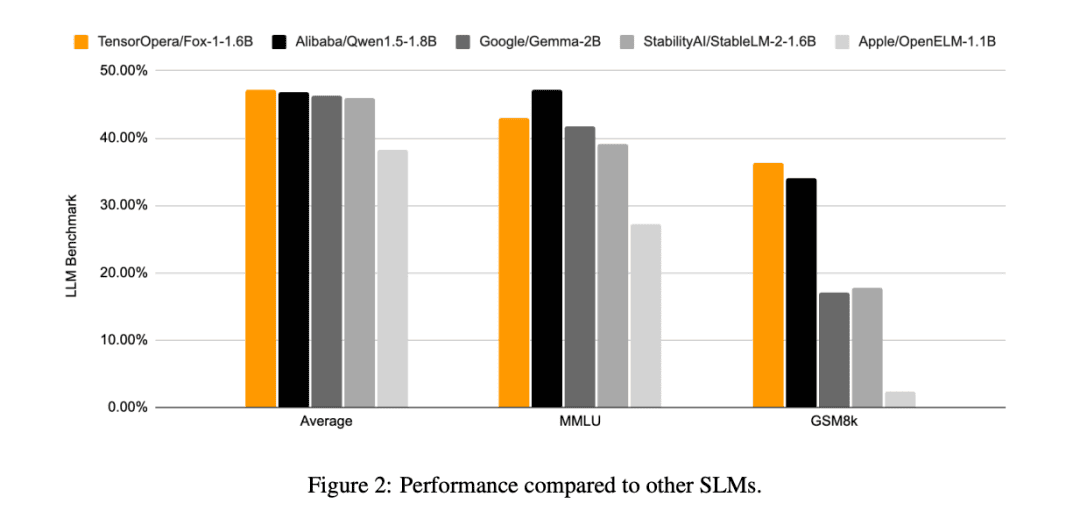
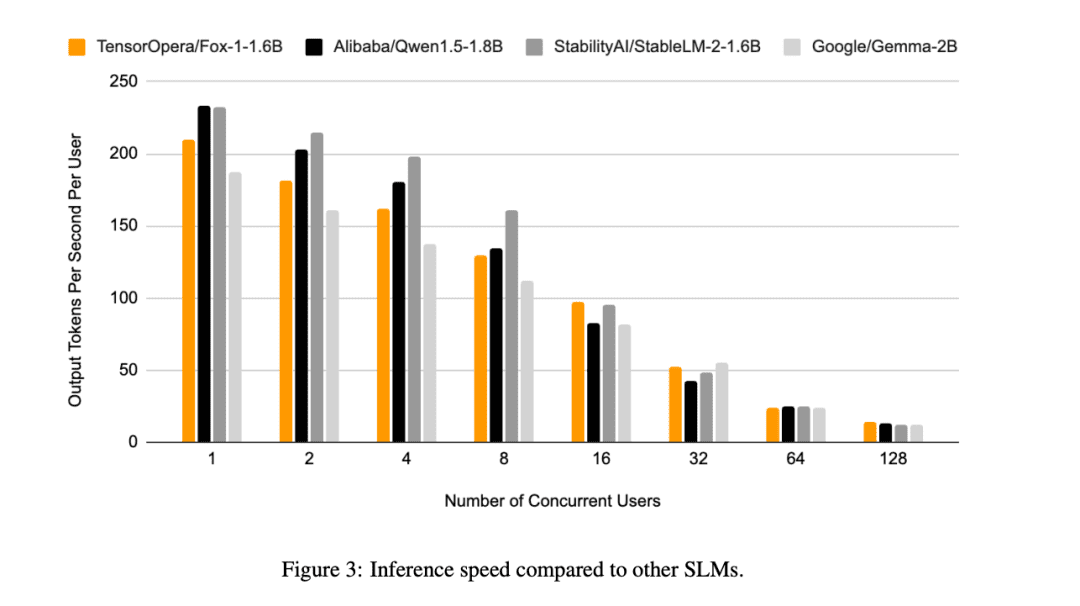
Además de esto, TensorOpera evaluó Fox-1, Qwen1.5-1.8B y Gemma-2B utilizando el programa vLLM Eficiencia de inferencia de extremo a extremo con la plataforma de servicios TensorOpera en una sola NVIDIA H100.
Fox-1 alcanza un rendimiento de más de 200 tokens por segundo, superando a Gemma-2B e igualando a Qwen1.5-1.8B en el mismo entorno de despliegue. Con precisión BF16, Fox-1 sólo necesita 3703MiB de memoria en la GPU, mientras que Qwen1.5-1.8B, StableLM-2-1.6B y Gemma-2B requieren 4739MiB, 3852MiB y 5379MiB, respectivamente.
Parámetros pequeños, pero competitivos
Mientras que todas las empresas de IA compiten ahora en modelos lingüísticos de gran tamaño, TensorOpera ha adoptado un enfoque diferente abriéndose paso en el ámbito de los SLM, logrando resultados similares a los de LLM con sólo 1,6B y obteniendo buenos resultados en diversas pruebas comparativas.
Incluso con recursos de datos limitados, TensorOpera puede preentrenar modelos lingüísticos con un rendimiento competitivo, proporcionando una nueva forma de pensar para que otras empresas de IA la desarrollen.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados




Sin comentarios...