Flying Paddles Los modelos de la serie PP son nuevos La nueva "abeja" para la comprensión de imágenes de documentos PP-DocBee

El objetivo de la tecnología de comprensión de imágenes de documentos es que los ordenadores puedan entender el contenido de las imágenes de los documentos tan bien como lo hacen los humanos. Consiste principalmente en analizar, procesar y comprender imágenes de documentos (por ejemplo, contratos en papel, páginas de libros, facturas, etc.) obtenidas mediante escaneado o fotografía, extraer información valiosa en ellas, como texto, tablas, gráficos, etc., y estructurar esta información. En la actual ola de transformación digital, la tecnología de comprensión de imágenes de documentos se utiliza ampliamente en el mundo empresarial, académico y en la vida cotidiana para mejorar la eficiencia y la precisión del procesamiento de documentos.
Anteriormente, en combinación con el Wenxin Big Model, FeiPaddle lanzó la solución de fusión de modelos de tamaño PP-ChatOCRv3, que primero utiliza la tecnología OCR para extraer el texto de la imagen y, a continuación, lo introduce en el Wenxin Big Model para analizar el cuestionario, lo que en última instancia mejora significativamente el análisis sintáctico de la disposición texto-imagen y el efecto de extracción de información. El sistema es muy preciso con el texto y las tablas, pero hay que seguir mejorando la capacidad de comprensión de las imágenes y los gráficos de los documentos. Por lo tanto, para satisfacer mejor las necesidades de los usuarios en tareas complejas y diversas de comprensión de imágenes de documentos, proponemos un nuevo esquema, PP-DocBee, basado en un gran modelo multimodal para lograr la comprensión integral de imágenes de documentos. Puede aplicarse eficazmente en todo tipo de escenarios, como comprensión de documentos, preguntas y respuestas sobre documentos, etc. Especialmente en los escenarios de comprensión de documentos chinos, como informes financieros, leyes y reglamentos, tesis, manuales, contratos, informes de investigación, etc., el rendimiento es muy excelente.
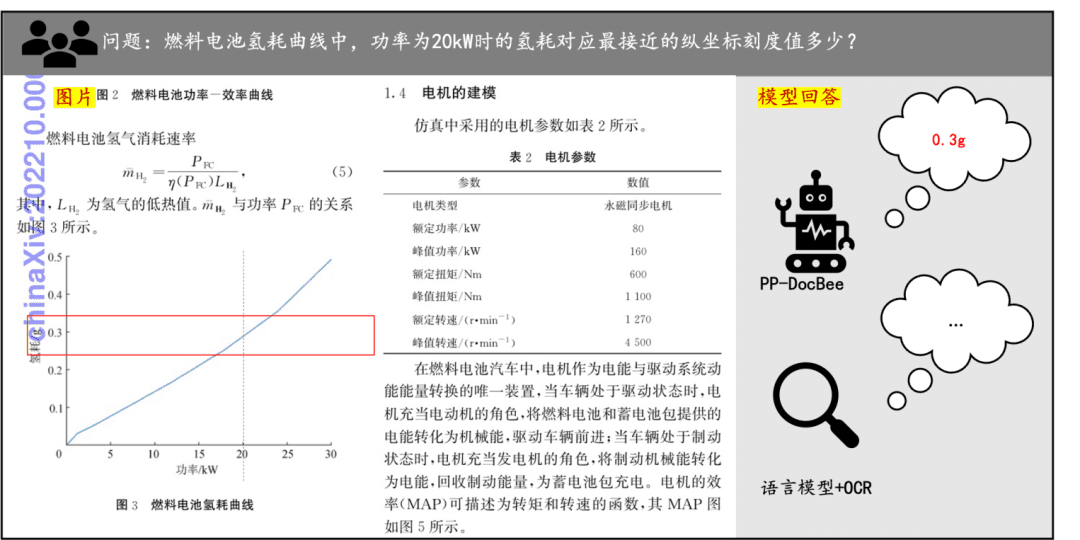
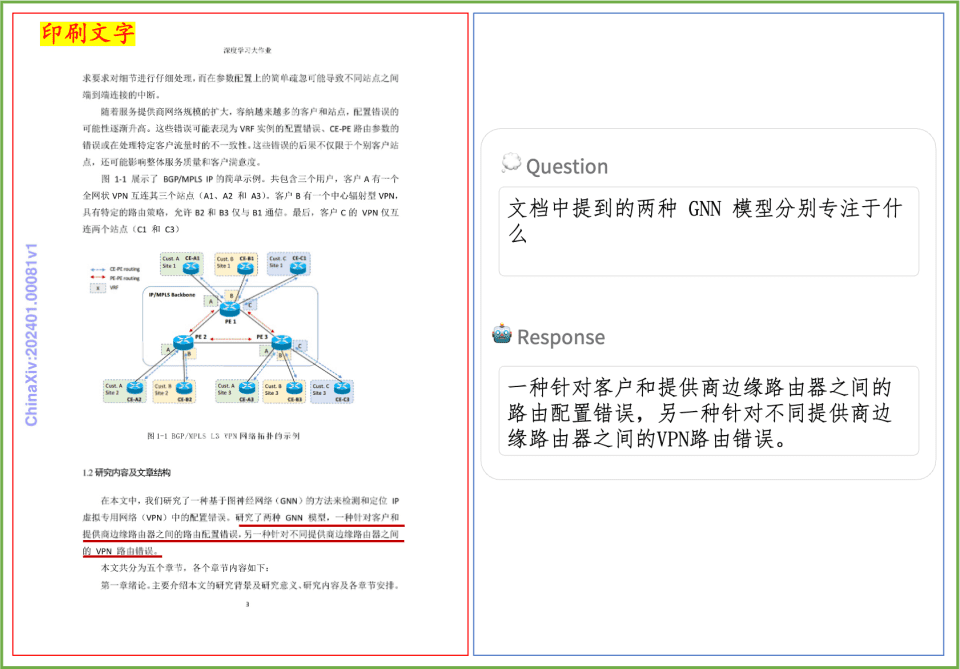
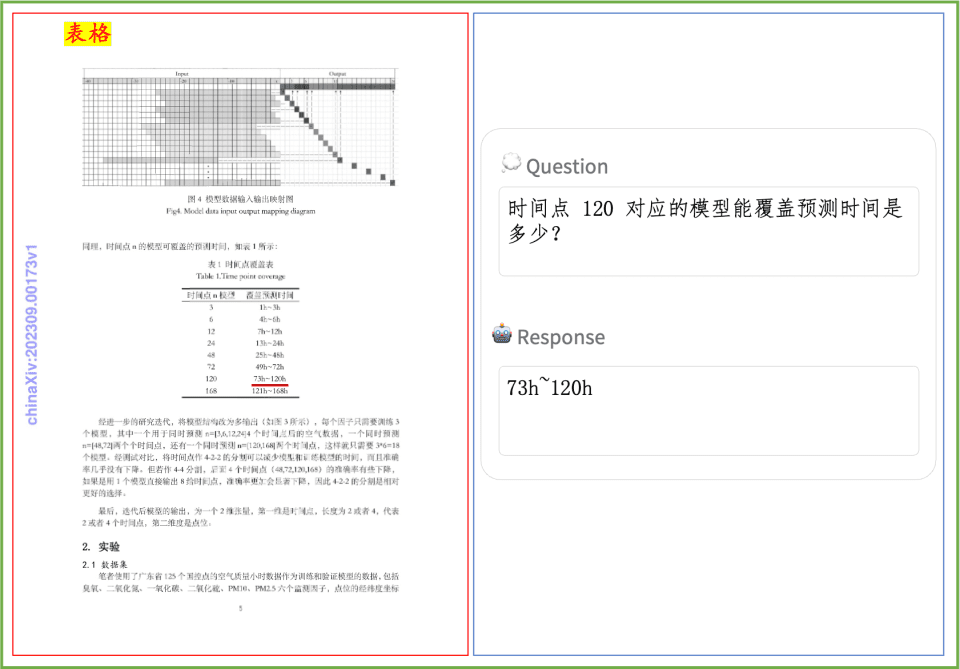
Ejemplo de comprensión de documentos Un rápido vistazo al efecto de PP-DocBee en la comprensión de textos impresos, tablas, gráficos y otros documentos:

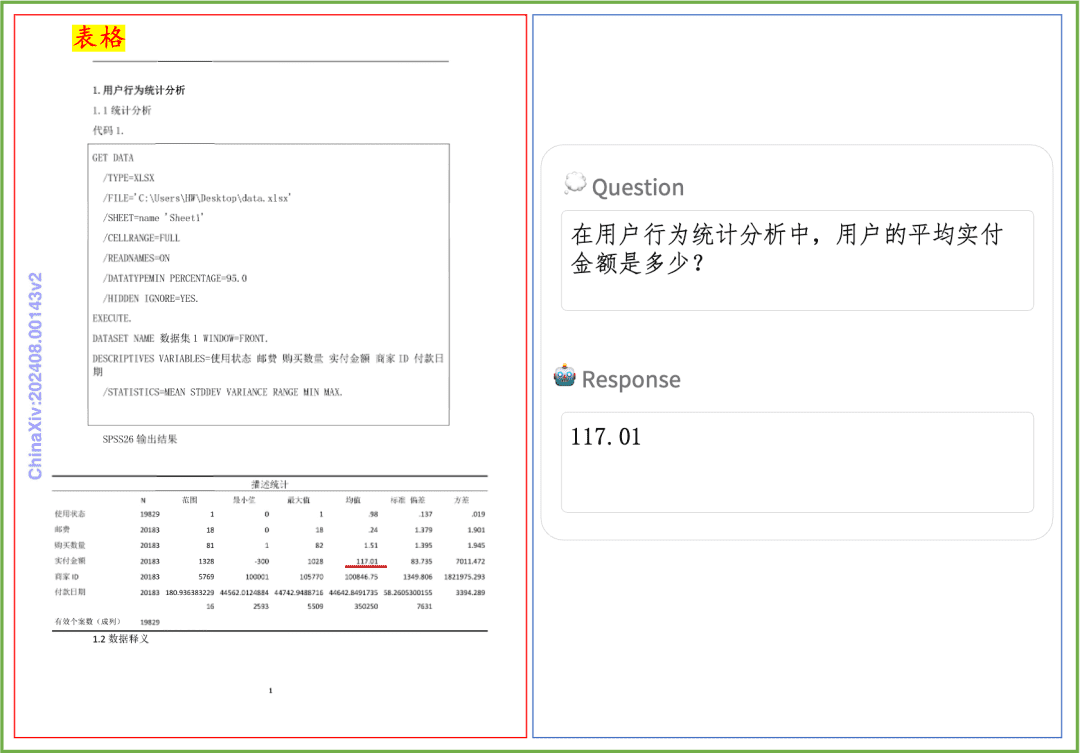

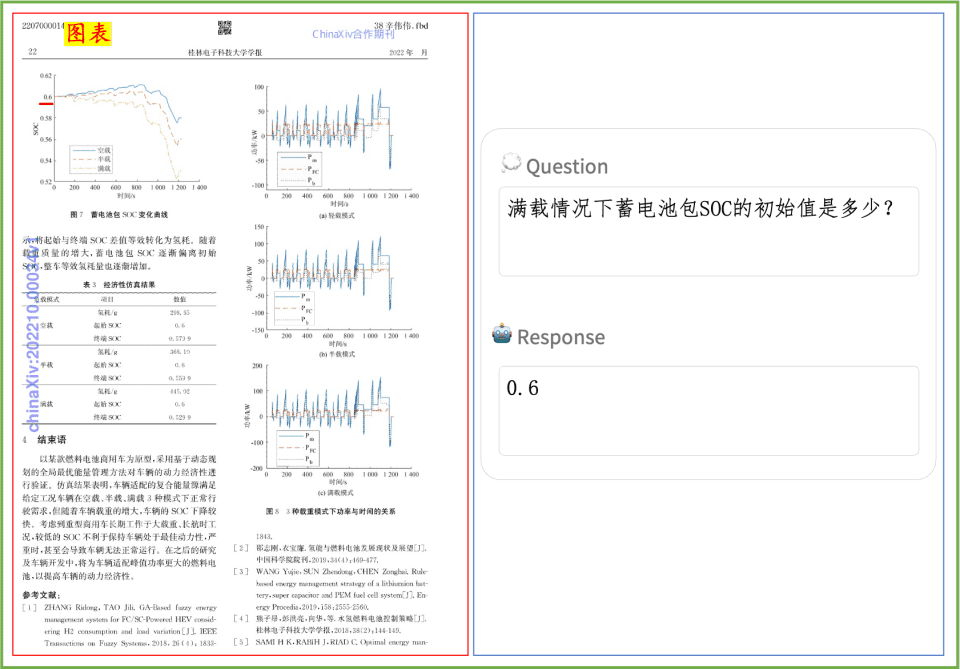
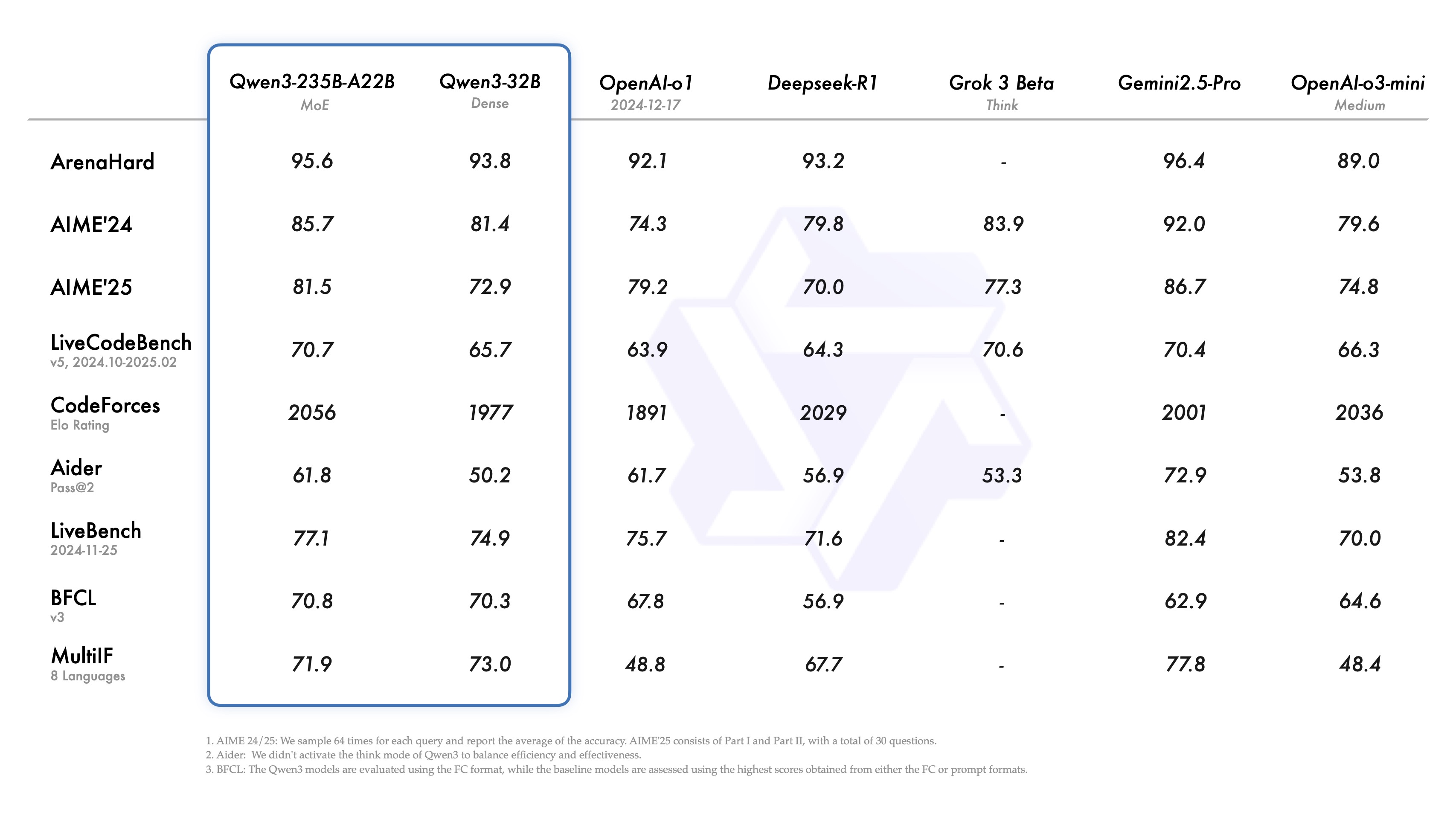
PP-DocBee ha logrado básicamente SOTA para modelos del mismo nivel de volumen de parámetros en varias listas autorizadas de revisión de comprensión de documentos en inglés en el ámbito académico.
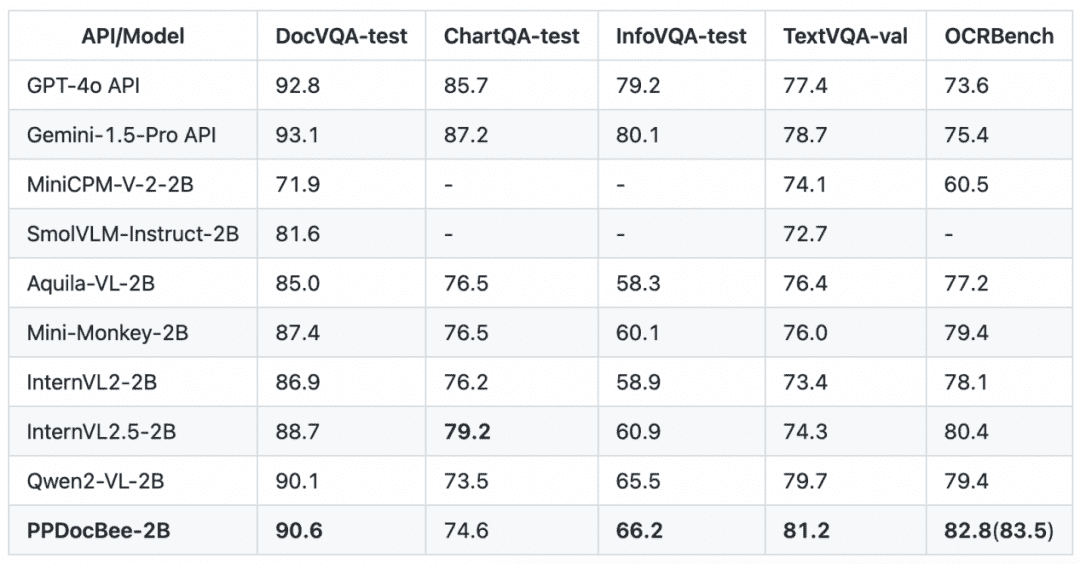
Lista de revisión de comprensión de documentos en inglés Comparación de competidores
Nota: Las métricas de OCRBench están normalizadas a una escala de 100 puntos, y las métricas de OCRBench de PPDocBee-2B tienen una puntuación de 82,8 para la evaluación de extremo a extremo y de 83,5 para la evaluación asistida por posprocesamiento de OCR. PP-DocBee también supera a los actuales modelos populares de código abierto y cerrado en la categoría de métricas del escenario empresarial interno chino.
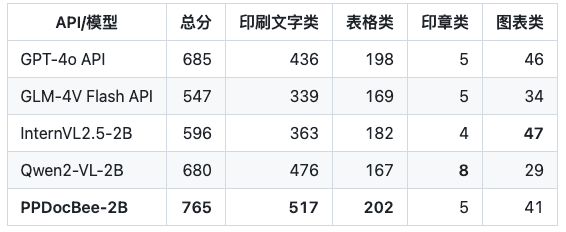
Escenario empresarial chino Comparación de competidores
Nota: El conjunto de escenarios chinos de evaluación para asuntos internos incluye escenarios de informes financieros, leyes y reglamentos, documentos científicos y técnicos, manuales, documentos de artes liberales, contratos, informes de investigación, etc., que se dividen en 4 categorías principales: texto impreso, formularios, sellos y gráficos.
Para mejorar aún más el rendimiento de inferencia de PP-DocBee, conseguimos una reducción del tiempo transcurrido de inferencia de 51,51 TP3T y una reducción del tiempo transcurrido total de extremo a extremo de 41,91 TP3T mediante la optimización de la fusión de operadores, como se muestra en la tabla siguiente.
| PP-DocBee | Tiempo medio de transmisión (s) | Tiempo medio de preprocesamiento (s) | Tiempo medio dedicado al razonamiento (s) |
| versión por defecto | 1.60 | 0.29 | 1.30 |
| Edición de alto rendimiento | 0.93 | 0.29 | 0.63 |
Nota: La versión de alto rendimiento tiene básicamente la misma cantidad de tokens de salida que la versión por defecto con la misma cantidad de tokens de entrada. Gracias a la optimización de alto rendimiento de la pala voladora, PP-DocBee responde más rápidamente manteniendo la calidad de las respuestas. Esta versión de razonamiento de alto rendimiento, para más detalles, puede consultarse en: https://github.com/PaddlePaddle/PaddleMIX/tree/develop/deploy/ppdocbee.
También proporcionamos un entorno de experiencia en línea para la Comunidad Flying Paddle Star River, donde podrá experimentar rápidamente las funciones de PP-DocBee a través del Centro de Aplicaciones de la Comunidad Flying Paddle Star River (https://aistudio.baidu.com/application/detail/60135).
Además, también proporcionamos el despliegue local de gradio, el despliegue del servicio OpenAI, así como instrucciones detalladas, los usuarios y entusiastas son bienvenidos a visitar la página principal del proyecto: https://github.com/PaddlePaddle/PaddleMIX/tree/develop/paddlemix/ examples/ppdocbee
Introducción al programa PP-DocBee
La estructura del modelo PP-DocBee se muestra en la siguiente figura, utilizando la arquitectura de ViT+MLP+LLM. Las ideas de optimización para escenarios de comprensión de documentos incluyenEstrategias de síntesis de datos, preprocesamiento de datos, métodos de formación y asistencia en el postprocesamiento de OCR.Al final, el modelo tiene tanto una comprensión genérica de documentos como una gran capacidad de análisis sintáctico de documentos para escenarios chinos.

Estructura del modelo PP-DocBee
En concreto, PP-DocBee incluye las siguientes mejoras importantes:
1. Estrategia de síntesis de datos
Para hacer frente a los problemas de la insuficiente capacidad lingüística en chino y la falta de datos de escena, hemos diseñado una solución de producción inteligente de datos de tipo documental, diseñado diferentes enlaces de generación de datos para cada uno de los tres tipos principales de conjuntos de datos, como Doc, Table, Chart, etc., y adoptado numerosas estrategias: combinación de modelo pequeño de OCR y modelo grande de LLM, producción de datos de imagen basada en el motor de renderizado y producción de datos personalizada para cada tipo de documento. plantillas rápidas, etc., lo que se traduce en una mayor calidad de Q&A y unos costes de generación controlables. Los detalles se muestran en la siguiente figura:
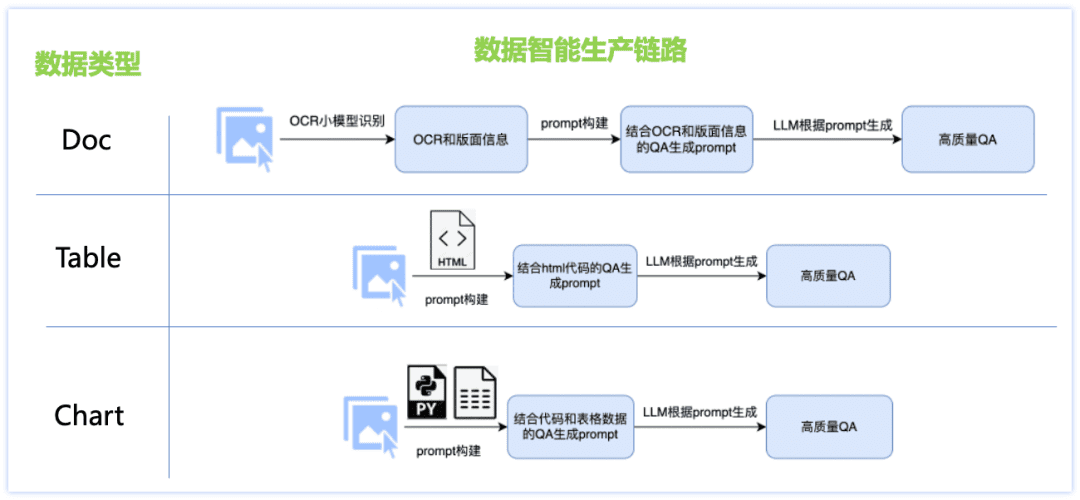
Datos de la clase Doc:
Picture: recopila y organiza documentos, informes financieros, trabajos de investigación y otros archivos pdf, combinados con herramientas de análisis de pdf para producir datos masivos de imágenes de documentos de una sola página;
Preguntas y respuestas: El modelo ocr pequeño extrae información detallada sobre el diseño de la imagen, compensando así las deficiencias de percepción visual del modelo grande, y al mismo tiempo utiliza la potente capacidad de comprensión de texto del modelo de lenguaje grande para corregir la inexactitud del reconocimiento de caracteres individuales del modelo ocr pequeño, la combinación de ambos puede producir un Q&A de mayor calidad y control tipográfico.
Datos de la clase de tabla:
Imagen: A partir de la imagen de tabla que contiene información de texto html, cambie el valor, el asunto y otra información del texto mediante el modelo de lenguaje grande, y obtenga la imagen de tabla de alta calidad rica en contenido mediante la herramienta de renderizado de tablas.
Preguntas y respuestas: el texto en formato html correspondiente a la imagen de la tabla se utiliza como información auxiliar de GT para garantizar la exactitud de las respuestas, y el diseño de indicaciones afinadas para producir preguntas y respuestas de alta calidad mediante un gran modelo lingüístico.
Datos de la clase de gráfico:
Imagen: a partir de los datos de origen del gráfico de alta calidad probados por la multitud (datos de imagen-código-tabla), cambie aleatoriamente los valores, ejes, leyendas, temas y otra información detallada del gráfico en el código a través del modelo de gran lenguaje, obtenga el código fuente con diversos contenidos y, a continuación, renderícelo a través de la herramienta de renderizado de gráficos (Matplotlib, Seaborn, Vega-Liteetc.) para obtener datos de imagen cartográfica de alta calidad;
Preguntas y respuestas: El código correspondiente a la imagen del gráfico y los datos de la tabla se utilizan como información auxiliar de GT para garantizar la precisión de la respuesta, y los tipos de preguntas correspondientes se diseñan para diferentes tipos de gráficos, y el prompt ajustado se diseña para producir preguntas y respuestas de alta calidad a través del gran modelo de lenguaje. Mediante el esquema de producción inteligente de datos de tipo de documento anterior, obtenemos una enorme cantidad de datos sintéticos, y filtramos algunos de ellos como uno de los datos de entrenamiento de PP-DocBee (la distribución de los datos se muestra en la figura siguiente), lo que mejora eficazmente la capacidad del modelo.
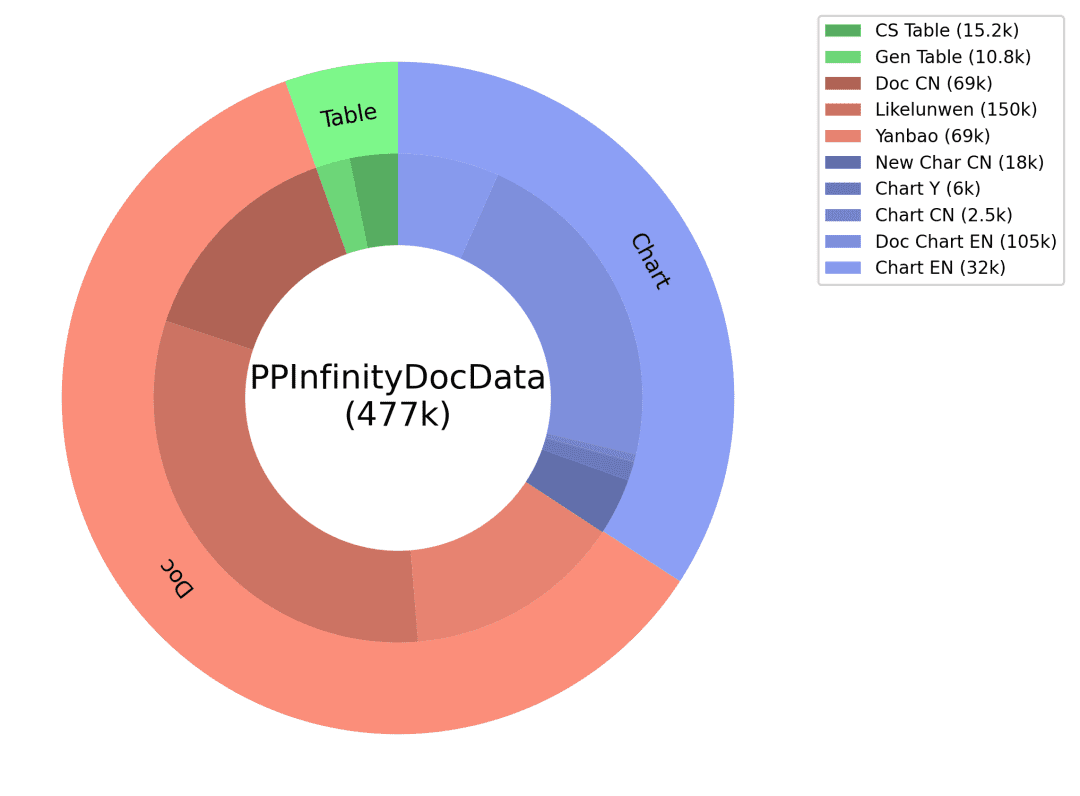
Distribución de datos sintéticos
2. Preprocesamiento de datos
Se incluyen dos estrategias: una consiste en fijar un umbral de redimensionamiento mayor durante el entrenamiento para aumentar la distribución general de la resolución del conjunto de datos, y la otra consiste en fijar un aumento igual de 1,1 a 1,3 veces para la mayoría de las imágenes regulares durante la inferencia, manteniendo inalterada la estrategia original de preprocesamiento de datos para las imágenes de resolución pequeña. Con estas dos estrategias se obtuvieron características visuales más adecuadas y completas, que mejoraron la comprensión final.
3. Métodos de formación
Se trata principalmente de una mezcla de varias clases de datos de comprensión de documentos, así como de un mecanismo de correspondencia de datos. Los distintos conjuntos de datos incluyen la clase genérica VQA, la clase OCR, la clase de diagramas, la clase de documentos ricos en texto, la clase de razonamiento matemático y complejo, la clase de datos sintéticos, los datos de texto sin formato, etc. El mecanismo de correspondencia de datos consiste en establecer proporciones de muestreo para los datos de distintas fuentes en diferentes clases e interclases con el fin de aumentar las ponderaciones de muestreo de los datos con mayores ganancias en varias clases, así como equilibrar las diferencias cuantitativas entre los distintos tipos de conjuntos de datos.
4.Asistencia al postprocesamiento del OCR
Principalmente a través de la herramienta de OCR o modelo de antemano para obtener el reconocimiento OCR de los resultados del texto, y luego como una información auxiliar a priori proporcionada en la imagen preguntas de la prueba, y luego dar PP-DocBee modelo de razonamiento, puede ser en el texto no es mucho y la imagen clara tiene algún efecto sobre la mejora.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Puestos relacionados



Sin comentarios...