El modelo Beanbag de gran voz en tiempo real ya está en línea. IQ y EQ están en línea, ¡y el diálogo de voz chino está en la cresta de la ola!

Hoy, Beanbag APP anunció que la nueva función de llamadas de voz en tiempo real de extremo a extremo está oficialmente en línea, sin jugar "pre-lanzamiento", directamente abierto a todos, gratis para todos, para satisfacer la prueba de cada usuario.
Megamodelo de voz en tiempo real URL: https://team.doubao.com/realtime_voice
Después de verlo, encontramos un par de grandes puntos:
En primer lugar, Beanbag es realmente humano, con un fraseo, un tono de voz y unos ritmos respiratorios muy antropomórficos.Cuando hables a un volumen más bajo, Beanbag también utilizará su habilidad de "susurro", eliminando por completo la sensación humana de las anteriores llamadas de voz de la IA.
En segundo lugar, independientemente de la complejidad del diálogo chino, la bolsa de judías puede aguantar el tipo.Tras nuestra serie de experiencias en el mundo real, puede decirse que Doubao lleva una ventaja abismal en el dominio del chino. Esta ventaja no sólo se compara con ChatGPT y otros actores extranjeros, y compárelo también con una serie de aplicaciones nacionales de diálogo sobre IA.
Además, Beanbag es un "autoestopista parlanchín" que sabe de todo, desde astronomía hasta geografía.Escucha atentamente lo que dice el usuario y el significado profundo que intenta transmitir, da respuestas interesantes y útiles con rapidez y tiene capacidad para interconectar consultas.
Para poder experimentar esta función, es necesario actualizar la APP DoudouBao a la versión 7.2.0 del Año Nuevo Chino. Tras el lanzamiento, un gran número de usuarios actualizaron y acudieron a Doubao por primera vez, e hicieron congee telefónico con Doubao:


Recuerda que en la madrugada del 14 de mayo de 2024, GPT-4o apareció de la nada y trajo a ChatGPT una nueva función de llamadas de voz en tiempo real, que la industria calificó de "lanzamiento revolucionario". Por desgracia, después de que ChatGPT pusiera en marcha esta función, nuestra experiencia real no fue tan impresionante como la demostración de lanzamiento.
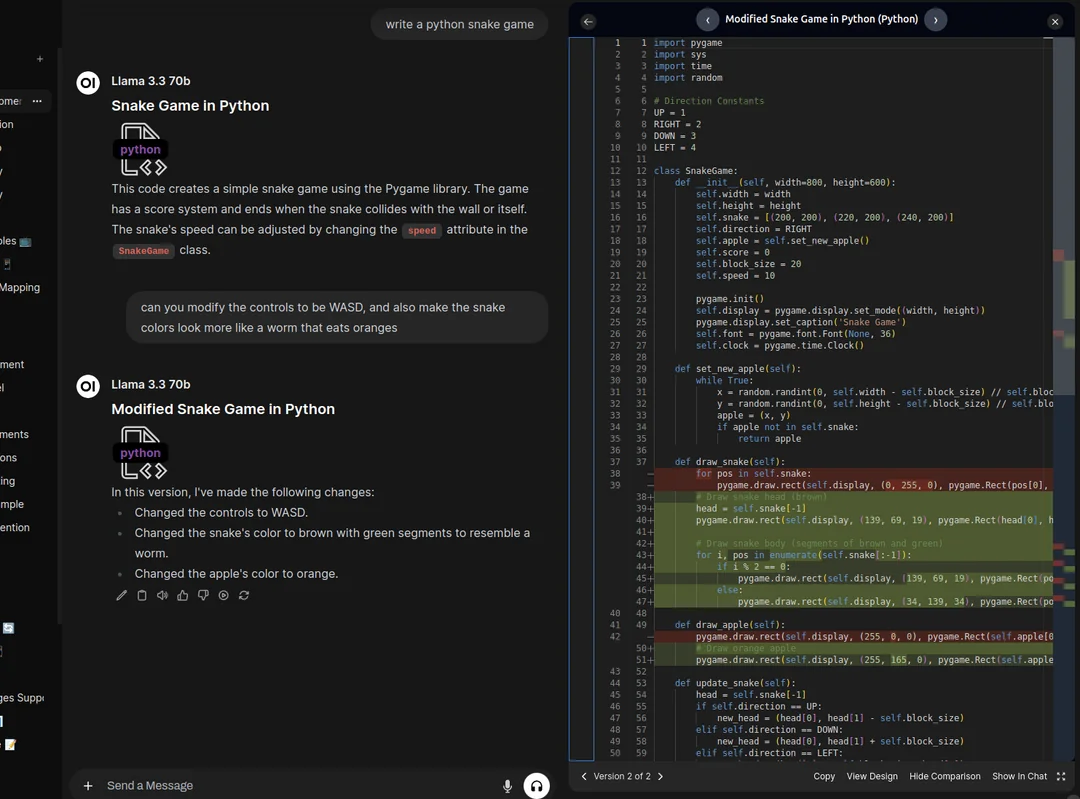
Ahora es el turno de Doubao. Antes de ponerlo en marcha, el equipo interno ha evaluado el Beanbag Real-time Voice Big Model y el GPT-4o detrás de esta función en torno a una serie de dimensiones como el antropomorfismo, la utilidad, la inteligencia emocional, la estabilidad de la llamada, la fluidez del diálogo, etc. En cuanto a la satisfacción general (sobre 5), el GPT-4o obtuvo una puntuación de 4,36, y el 50101 Beanbag Real-time Voice Big Model, de 3,18. En cuanto a la satisfacción general (sobre 5), el Beanbag Real-time Voice Big Model obtuvo una puntuación de 4,36 y el GPT-4o de 3,18. Los probadores del 50% puntuaron con un 5 el rendimiento del Beanbag Real-time Voice Big Model.
Además, en la evaluación de los méritos del modelo, el gran modelo de habla en tiempo real de Doubao tiene ventajas evidentes en la comprensión y la expresión de emociones. Especialmente en la evaluación de "IA o no a primera vista", más de 30% de comentarios dijeron que GPT-4o es "demasiado IA", mientras que la proporción correspondiente del gran modelo de habla en tiempo real de Doubao está solo dentro de 2%.
La siguiente parte es la prueba real del corazón de la máquina, si usted está interesado en leerlo, le sugerimos que abra rápidamente su propio Bean Bag App y actualizar la versión a 7.2.0 Edición de Año Nuevo para experimentarlo. Después de todo, desde el grado actual de fuego, ir tarde puede tener la probabilidad de no apretar el coche.
Prueba de primera mano: un poco chocante, película de ciencia ficción hecha realidad
A finales de 2024, el equipo de Beanbag Big Model desveló la nueva función de voz en tiempo real de extremo a extremo que pronto entraría en funcionamiento en la aplicación Beanbag, desatando una oleada de expectación entre los usuarios.
Después de utilizarlo, nuestra sensación es que, efectivamente, es más antropomórfico y natural de lo esperado.
Uno de los aspectos más destacados de Beanbag es su capacidad para percibir y asumir las emociones de los usuarios.¿Por qué no escucha algunas de nuestras conversaciones con el saco de judías para hacerse una idea de lo antropomórfico que es?
Por ejemplo, la capacidad de expresar emociones le permite mostrar emociones complejas en su voz, que puede llegar a ser "difícil de distinguir entre humano y máquina".
Doubao parece ser un hábil actor, que se enfrenta a diferentes escenarios del boleto de lotería de 5 millones de yuanes, a veces extasiado, a veces apesadumbrado.
La capacidad de seguir instrucciones también es muy fuerte. Hemos sido capaces de recitar poemas a distintas velocidades del habla y de sentir las emociones de los poemas y recitarlos con emoción.
La empatía también se lleva. Cuando nuestras primeras palabras se referían a malas noticias con frustración, el beanbag te tranquilizaba con un tono más calmado y cálido. Pero cuando recuperas un estado de ánimo positivo y cambias a un tono más ligero para complementarlo, el beanbag cambia a un tono alegre. También tendrá rasgos paralingüísticos similares a los humanos, como entonación, vacilación y pausas.
Nota: Algunas respuestas se retrasan y proceden de consultas en red.
Al mismo tiempo, podemos sentir que Doubao no sólo proporciona compañía emocional, por ejemplo, en la primera prueba de diálogo, da consejos para coger billetes, recomendaciones de viaje que también son muy prácticas, e información instantánea sobre el tiempo y otra información instantánea que se puede recuperar de forma rápida y precisa.
Sí, detrás del elocuente discurso de Doubao se encuentra la potente capacidad de comprensión semántica y recuperación de información del gran modelo de discurso en tiempo real de Doubao. En el momento de la entrada de voz del usuario, Doubao comienza inmediatamente a comprender la profundidad de cada dimensión de la información para garantizar la utilidad y autenticidad de la información de salida.En términos sencillos, tiene tanto "valor emocional" como "valor práctico".(Sin embargo, también comprobamos que el modelo de gran voz en tiempo real de Doubao sólo admite inglés y chino en la actualidad, y esperamos que la capacidad multilingüe pueda reforzarse con una ola en el futuro).
Dado que Beanbag lleva mucho tiempo "mezclándose" con Internet, su nivel de juego con la abstracción no debe de ser malo.
Nota: Algunas respuestas se retrasan y proceden de consultas en red.
Por supuesto, con Beanbag Conversations, no tienes sólo un autoestopista, sino innumerables amigos del drama.
En el modo "Cien cambios de grandes maestros", del Rey Mono a Lin Daiyu, y de Wolffy a Lazy Goat, el control de la voz y la interpretación de las emociones han llevado la experiencia de usuario de Doubao a un nivel superior.
Puesto que el juego de rol no es un problema, la habilidad narrativa también está al alcance de la mano. Cambiando libremente entre el horror y la hilaridad.
Curiosamente, Doubao APP ha introducido la función de canto que no tiene GPT-4o, que es un juego divertido para grandes y pequeños, y el fuego está a la vuelta de la esquina.
Es fin de año, así que dejemos que algunas canciones de Nochevieja cierren este repaso:
¿Qué tecnología hay detrás de esta experiencia de llamada tan superior?
¿Cómo ha conseguido el equipo de Beanbag unas llamadas de voz en tiempo real tan sedosas y naturales?
Esta función se apoya en el modelo Beanbag Real-Time Voice Big, lanzado recientemente.
Según el equipo de Beanbag Big Model Speech, se trata de un modelo integrado de comprensión y generación del habla que realmente consigue un diálogo de voz de extremo a extremo, más asombroso que el modelo tradicional en cascada en cuanto a expresividad de la voz, control y compromiso emocional, y que tiene las ventajas de la baja latencia y la posibilidad de interrumpir en cualquier momento del diálogo.
En el campo de la IA del habla, existen dos dificultades técnicas para la macromodelación del habla en tiempo real.
Una de ellas es que resulta difícil encontrar un equilibrio entre la inteligencia emocional y la intelectual.
Muchos profesionales en el campo del habla saben que el modelo en sí a menudo tiene una relación contradictoria entre la naturalidad del diálogo, la utilidad y las dimensiones de seguridad. En otras palabras, es cómo hacer que el modelo no sólo un "matón de la escuela" con la capacidad de razonamiento lógico en línea, sino también expresivo, empático, comprensivo en línea, y el nivel de inteligencia emocional tirando de lleno.
Según el equipo, se orientan a los problemas anteriores en términos de datos y algoritmos de post-entrenamiento para garantizar que los datos de diálogo de habla multimodal sean tanto semánticamente correctos como expresivamente naturales. Al mismo tiempo, se basa en un enfoque de síntesis de datos multirronda para producir datos de habla de alta calidad y gran expresividad, garantizando que las expresiones de habla generadas sean naturales y coherentes.
Además, el equipo también realiza evaluaciones multidimensionales periódicas del modelo, basándose en los resultados para ajustar oportunamente la estrategia de formación y el uso de los datos, a fin de garantizar que el modelo mantenga siempre un buen equilibrio entre coeficiente intelectual y rendimiento.
El segundo es el alto umbral de aterrizaje, hacer que la función de voz no se detenga en Toy, es un gran reto para la capacidad integral del equipo.
En el pasado, varios lanzamientos de voz de extremo a extremo, incluido el GPT-4o, sólo mostraban la demo, e incluso si se hacen públicas las capacidades posteriores, es posible que el público no reconozca las capacidades reales. La razón es la siguiente: la función del proceso de I+D requiere la participación de algoritmos, ingeniería, producto, pruebas y otros equipos, no sólo para aclarar las necesidades del usuario, sino también para dividir las dimensiones e indicadores de evaluación técnica, y luego en el modelo de formación, puesta a punto, y otros procesos, la misma necesidad de múltiples equipos para trabajar en estrecha colaboración unos con otros. Por último, cuando el producto quiere entrar en línea para dar servicio a cientos de millones de usuarios, también se enfrenta a grandes retos de ingeniería y seguridad.
Como se mencionó anteriormente, la nueva función de voz en tiempo real anunciado por este Doubao oficial en línea está abierta, sirviendo directamente a miles de usuarios, el equipo también tratar de encontrar el mejor equilibrio en términos de la experiencia de entrega, a fin de garantizar la seguridad de la base, por lo que el modelo tiene una voz sin precedentes de alto poder expresivo, el control y la capacidad de compromiso emocional brillante, al mismo tiempo, para asegurarse de que tiene una fuerte capacidad de comprensión y la lógica, sino que también puede ser conectado en red para responder a la puntualidad de la pregunta. .
En el marco de la modelización conjunta de la generación del habla, la comprensión y el macromodelo de texto, el equipo ha logrado la capacidad de entrada y salida diversa del modelo y, al mismo tiempo, ha garantizado la precisión de la generación y la naturalidad del modelo en el lado de la generación en el caso de una menor latencia del sistema y, al mismo tiempo, en el lado de la comprensión, el marco permite que el modelo logre la capacidad de interrupción brusca del habla y la detención del diálogo del usuario.
Por supuesto, el equipo también concede gran importancia a las cuestiones de seguridad derivadas de la mejora de las capacidades de modelización. Según el personal técnico pertinente, introdujeron diversos mecanismos de seguridad en la fase posterior a la formación del proceso de modelización conjunta para reducir los riesgos de seguridad suprimiendo y filtrando eficazmente los contenidos potencialmente no seguros.
El equipo técnico también nos reveló que, gracias a la modelización conjunta, el modelo ha adquirido sorprendentemente nuevas capacidades, como la comprensión de órdenes, la reproducción y el control de voz. Por ejemplo, algunos de los dialectos y acentos del modelo proceden ahora de la generalización de datos en la fase de preentrenamiento, y no de un entrenamiento específico. En este sentido, los modelos de voz son muy similares a los modelos lingüísticos.
Más allá de las sorpresas, ¿qué ha "subvertido" Doubao?
Entre los productos similares existentes, podemos sentir que el antropomorfismo y la experiencia emocional de Doubao son los mejores, y es competente en las 18 habilidades, y su habilidad con el idioma chino es muy superior a la de ChatGPT y otros "productos importados".
A fin de cuentas, cabe preguntarse: aparte de la sorprendente experiencia de usuario, ¿por qué ha acaparado tanta atención la voz en tiempo real de extremo a extremo actualizada de Beanbag?
La respuesta clave es: es el primer sistema de voz chino de extremo a extremo que da servicio a cientos de millones de usuarios y funciona de verdad, es bueno y es gratis.
Érase una vez, el diálogo de voz en tiempo real con IA era sólo una escena de una película de ciencia ficción, y una imaginación concreta de la inteligencia artificial avanzada. Pero ahora, esa función mágica existe en la App Doubao de tu móvil y el mío, y ha pasado de "muy lejos" a "al alcance de la mano".

Crédito de la foto: The film Her
En resumen, la nueva voz en tiempo real de extremo a extremo de Beanbag sienta dos precedentes:
Desde el punto de vista del cambio tecnológico, Doubao inyectó "alma" a la IA por primera vez en la industria, y logró el doble cociente de "cociente emocional" y "cociente de inteligencia" en línea. Esto parece significar el fin de la era de los asistentes de voz tradicionales. Ya no sentimos inconscientemente que estamos hablando con un modelo entrenado con cantidades masivas de datos, y las personas y la IA han empezado a producir una sutil conexión emocional, que incluye confianza y dependencia, y la trama de una película de ciencia ficción está llegando a la vida del público.
Como en clásicos como Her, los humanos nunca se han enamorado de la IA porque aporte conocimientos ilimitados, sino porque aporta la cantidad justa de valor emocional.
A nivel de tecnología big model, las llamadas de voz en tiempo real de extremo a extremo llenan una de las pocas lagunas de la interacción multimodal. La jugabilidad de las aplicaciones de big models está en constante evolución: los futuros productos podrán recibir cualquier combinación de texto, audio e imágenes como entrada y generar cualquier combinación de texto, audio e imágenes como salida en tiempo real. La forma en que interactúan los humanos y las máquinas se está trastocando, lo que a su vez está transformando la forma en que los humanos interactúan entre sí.
Al menos para los usuarios actuales de habla china, el lanzamiento de la función de voz en tiempo real de extremo a extremo de Doubao ofrece una forma de interacción mediada por el lenguaje humano natural que rompe verdaderamente la barrera de acceso y experiencia de la IA avanzada.
Si nos remontamos seis meses atrás, ¿podríamos haber imaginado que serían las bolsas de judías las que protagonizarían la historia?
Empezando por el gran modelo lingüístico en 2023 y terminando en 2024, la gran familia de modelos de Doubao se ha completado en los niveles multimodales de imagen, voz, música, vídeo, 3D, etc. No sólo se ha situado en el primer escalón de China, sino que también ha completado la metamorfosis de "incipiente" a "revolucionario mundial" en tan sólo unos meses.
Y quien llegue primero a este hito en la gran pista de modelos de cien barcos puede determinar su clasificación en el campo durante la próxima década.
En el próximo año, sobre grandes modelos, sobre bolsas de frijoles y la IA doméstica avanzará a qué velocidad, más digna de nuestras expectativas.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...