Baichuan Intelligence lanza el modelo grande omnimodal Baichuan-Omni-1.5, que supera al GPT-4o Mini en varias mediciones

Hacia finales de año, el sector nacional de los grandes modelos vuelve a dar buenas noticias. BCinks Intelligence ha lanzado recientemente una serie de productos de grandes modelos, siguiendo elModelo de inferencia profunda de escena completa Baichuan-M1-previewresponder cantandoMejora médica de código abierto Modelo Baichuan-M1-14BA continuación se relanzóModelo modal completo Baichuan-Omni-1.5.
Baichuan-Omni-1.5 es conocido como el "Gran Modelo Generalista", que marca el progreso significativo del gran modelo nacional en la tecnología de fusión multimodal.Baichuan-Omni-1.5 está equipado con una excelente capacidad de comprensión y generación omnimodal, que no sólo es capaz de procesar simultáneamenteTexto, imágenes, audio, vídeoy otra información multimodal, y más apoyo a losTexto y audioGeneración bimodal de contenidos.
Al mismo tiempo, Baichuan Intelligence también ha puesto en abiertoOpenMM-Medicalresponder cantandoOpenAudioBenchLos dos conjuntos de datos de evaluación de alta calidad tienen como objetivo promover el próspero desarrollo del ecosistema nacional de tecnología de modelos multimodales. Según los exhaustivos resultados de evaluación que se han hecho públicos, Baichuan-Omni-1.5 en una serie de capacidades multimodalesEl rendimiento general supera al del GPT-4o Mini, especialmente en el ámbito médico, donde la BCinks Intelligence ha seguido profundizando cada vez más.Las puntuaciones de la revisión de imágenes médicas son una ventaja significativaEsto demuestra plenamente la fuerte fuerza y firme determinación de BCinks Intelligence como líder en el campo de los modelos de gran tamaño. Esto demuestra plenamente Baichuan Inteligencia como un líder nacional en el campo de los modelos de gran tamaño, la fuerza fuerte y firme determinación en la innovación tecnológica y la industria de aterrizaje de aplicación.
Dirección del peso del modelo:
Baichuan-Omini-1.5: https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5 https://modelers.cn/models/Baichuan/Baichuan-Omni-1d5
Baichuan-Omini-1.5-Base: https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5-Base https://modelers.cn/models/Baichuan/Baichuan- Omni-1d5-Base
Dirección de GitHub: https://github.com/baichuan-inc/Baichuan-Omni-1.5
Informe técnico: https://github.com/baichuan-inc/Baichuan-Omni-1.5/blob/main/baichuan_omni_1_5.pdf
01 . Amplio avance en capacidades multimodales: rendimiento sobresaliente en la evaluación del procesamiento de texto, gráficos, audio y vídeo.
Las prestaciones más destacadas del Baichuan-Omni-1.5 pueden resumirse como "Funciones completas y alto rendimiento". La característica más notable del modelo es suexhaustivamenteLa capacidad de comprensión y generación multimodal, en concreto, no sólo comprende contenidos multimodales como texto, imagen, vídeo y audio, sino que también admite la generación bimodal de texto y audio.
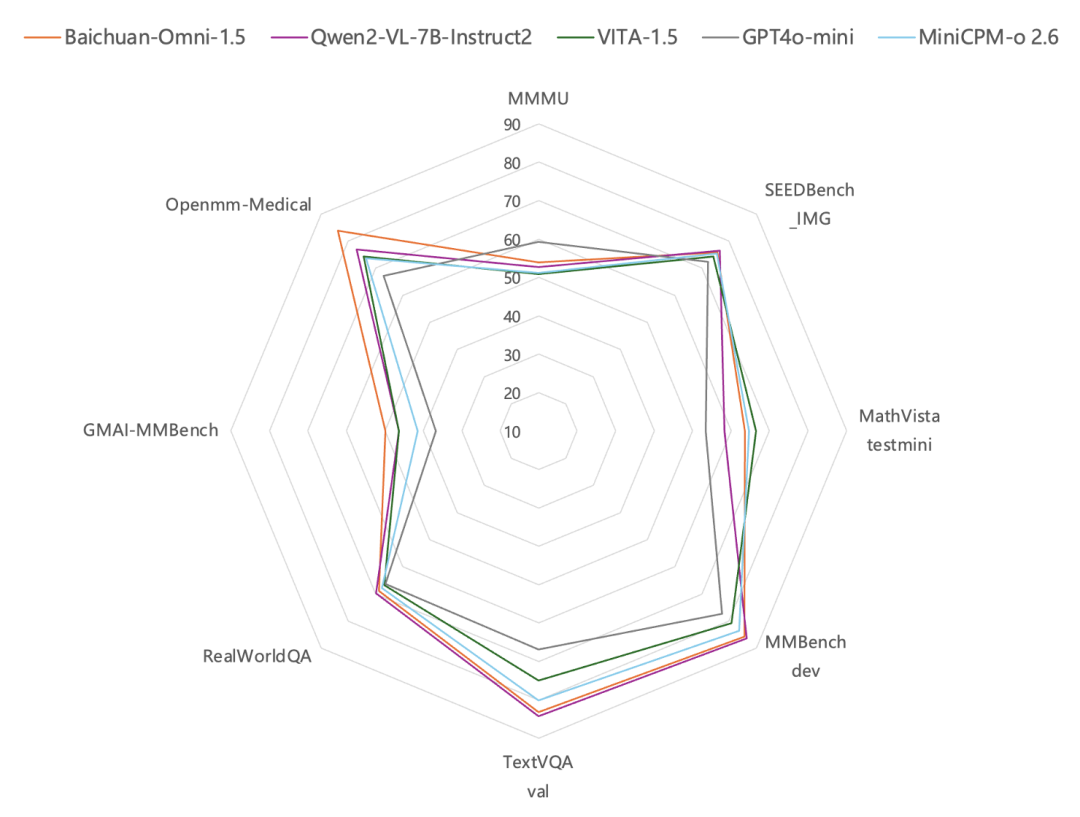
Por lo que respecta a la comprensión de imágenes, según los resultados de las pruebas realizadas con parámetros de evaluación de imágenes habituales, como MMBench-dev, TextVQA val, etc., el rendimiento de Baichuan-Omni-1.5Mejor que GPT-4o Mini. Resulta especialmente interesante el hecho de que, además de sus capacidades generales, el modelo omnicanal de Baichuan Intelligence es particularmente fuerte en el vertical de la sanidad. EnConjunto de datos de revisión de imágenes médicas Las revisiones en GMAI-MMBench y Openmm-Medical han demostrado que las capacidades de Baichuan-Omni-1.5 en comprensión de imágenes médicas han sidoSupera significativamente al GPT-4o Mini.
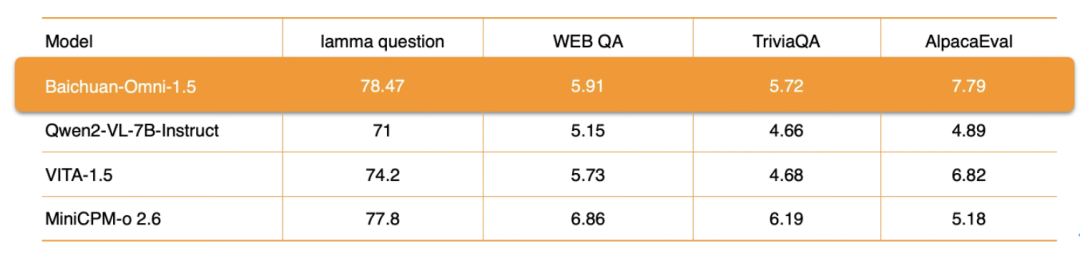
En cuanto al procesamiento de audio, Baichuan-Omni-1.5 no sólo admite eldiálogo multilingüeTambién se basa en sus capacidades de síntesis de audio de extremo a extremo, integrando la ASR (reconocimiento automático del habla) responder cantando TTS (texto a voz) funciones. Además, el modelo también admite la aplicación de laInteracción audio-vídeo en tiempo real. En términos de métricas de rendimiento específicas, el rendimiento global de Baichuan-Omni-1.5 en conjuntos de datos como lamma question y AlpacaEvalsignificativamente mejor que Qwen2-VL-2B-Instruct, VITA-1.5 y MiniCPM-o 2.6 son modelos similares.
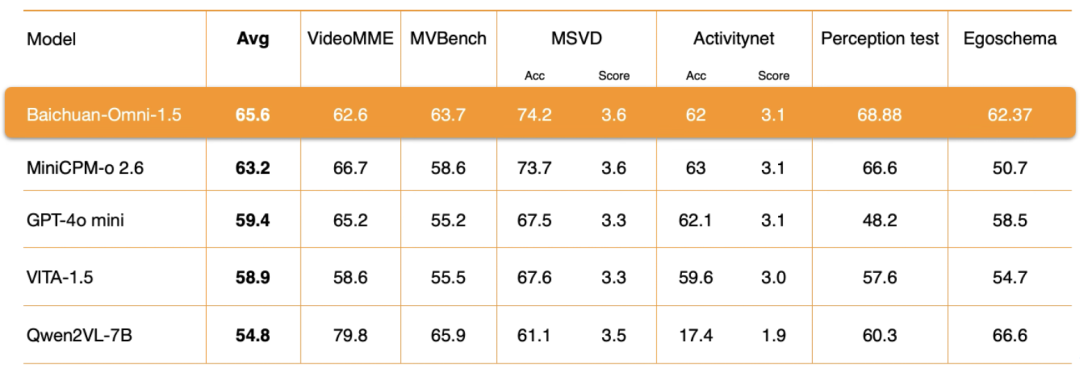
Comprensión del vídeoA nivel de Baichuan-Omni-1.5, Baichuan Intelligence ha llevado a cabo una optimización en profundidad de varios aspectos clave, como la arquitectura del codificador, la calidad de los datos de entrenamiento y la estrategia del método de entrenamiento. Los resultados de la evaluación muestran que su comprensión de vídeoEl rendimiento general también es significativamente superior al de la GPT-4o-mini..
En resumen, Baichuan-Omni-1.5 no sólo supera a GPT4o-mini en cuanto a capacidad de uso general en su conjunto, sino que, lo que es más importante, realiza laUnidad de comprensión y generación modal completaque sienta las bases para construir sistemas de IA más generalizados.
Para seguir avanzando en la investigación de modelos multimodales, Baichuan Intelligence ha puesto a disposición pública dos conjuntos de datos de reseñas profesionales:OpenMM-Medical y OpenAudioBench. Entre ellas OpenMM-Medical conjunto de datosDiseñado para evaluar el rendimiento del modelo en tareas médicas multimodalesIntegra datos de 42 conjuntos de datos de imágenes médicas de acceso público, como ACRIMA (imágenes de fondo de ojo), BioMediTech (imágenes de microscopio) y CoronaHack (radiografías), para un total de 88.996 imágenes.
Dirección de descarga:
https://huggingface.co/datasets/baichuan-inc/OpenMM_Medical
OpenAudioBench entonces es unUna plataforma de evaluación completa para evaluar eficazmente las capacidades de comprensión auditiva de los modelosContiene 5 conjuntos de subevaluación para la comprensión de audio de extremo a extremo, 4 de los cuales proceden de conjuntos de datos de evaluación públicos (Llama Question, WEB QA, TriviaQA, AlpacaEval), y el otro es un conjunto de evaluación de razonamiento lógico del habla autoconstruido por Baichuan Intelligence, que contiene 2.701 datos.
Dirección de descarga:
https://huggingface.co/datasets/baichuan-inc/OpenAudioBench
BCinks Intelligence ha participado activamente y fomentado la construcción y prosperidad del ecosistema nacional de código abierto. El conjunto de datos de evaluación de código abierto proporciona a investigadores y desarrolladores una herramienta de evaluación unificada y estandarizada, que ayuda a realizar un análisis comparativo objetivo y justo del rendimiento de distintos modelos multimodales, promoviendo así el desarrollo innovador de algoritmos de comprensión del lenguaje y arquitecturas de modelos de nueva generación.
02 . Optimización tecnológica integral: sinergia de datos, arquitectura y procesos para superar el cuello de botella de los modelos multimodales.
Desde el desarrollo inicial de modelos unimodales hasta la fusión multimodal, pasando por los actuales modelos omnidimodales, este viaje evolutivo tecnológico ha ampliado el espacio para la aplicación de la tecnología de IA en diversos sectores. Sin embargo, con el desarrollo en profundidad de la tecnología de IA, laCómo lograr eficazmente la unidad de comprensión y generación en los modelos multimodales se ha convertido en un punto clave y una dificultad técnica en la investigación actual en el campo de la multimodalidad..
Por un lado, la unidad de comprensión y generación es la clave para simular la interacción humana natural y lograr una comunicación persona-ordenador más natural y eficiente, así como un vínculo importante con la inteligencia artificial general (AGI); por otro lado, existen diferencias significativas entre los distintos datos modales en términos de representaciones de características, estructuras de datos y connotaciones semánticas, etc., por lo que cómo extraer eficazmente características multimodales y lograr una interacción y fusión eficaces de la información intermodal se reconoce como uno de los uno de los mayores retos a los que se enfrenta la formación de modelos multimodales.
El lanzamiento de Baichuan-Omni-1.5 demuestra que Baichuan Intelligence ha avanzado significativamente en la resolución de los problemas técnicos mencionados y ha explorado una vía técnica eficaz. Para superar el problema común de la "degradación intelectual" en el entrenamiento de modelos omnimodales, el equipo de investigación de Baichuan ha llevado a cabo una optimización en profundidad de todo el proceso, desde el diseño de la estructura del modelo, la optimización de la estrategia de entrenamiento y la construcción de los datos de entrenamiento, y finalmente ha logrado una unificación efectiva de la comprensión y la generación.
primero enmodelizaciónLa capa de entrada de Baichuan-Omni-1.5 admite varios datos modales, que se introducen en el modelo lingüístico a gran escala para su procesamiento a través del codificador/tokenizador correspondiente; en la capa de salida, el modelo adopta un diseño de salida intercalado texto-audio, que puede generar simultáneamente contenidos de texto y audio a través del tokenizador de texto y el decodificador de audio. En la capa de salida, el modelo adopta un diseño de salida intercalado texto-audio, a través del Tokenizador de Texto y el Decodificador de Audio, se pueden generar simultáneamente las modalidades de texto y audio. El tokenizador de audio se basa en el modelo de traducción y reconocimiento del habla de código abierto OpenAI. Susurro El modelo se entrena de forma incremental para proporcionar una extracción semántica avanzada y una reconstrucción de audio de alta fidelidad. Para que el modelo pueda manejar imágenes con distintas resoluciones, Baichuan-Omni-1.5 introduce el modelo NaViT, que admite entradas de imágenes de hasta 4K de resolución e inferencia multiimagen, lo que garantiza que el modelo pueda captar por completo la información de la imagen y comprender con precisión su contenido.
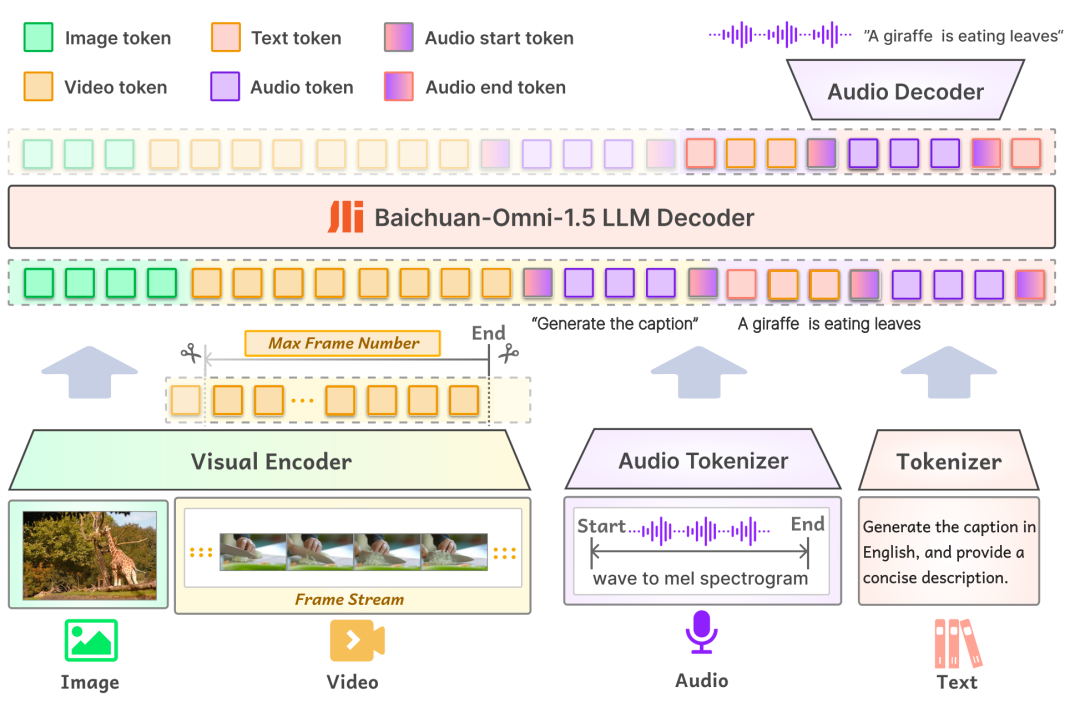
En segundo lugar, enNivel de datosBCI ha construido una enorme base de datos que contiene 340 millones de datos de imagen/vídeo-texto de alta calidad y casi un millón de horas de datos de audio, de los que se han seleccionado 17 millones de datos full-modal para la fase SFT (ajuste fino supervisado) del modelo. A diferencia de la composición de datos de los modelos tradicionales, el entrenamiento de los modelos full-modal requiere no sólo un gran tamaño de datos, sino también diversidad de tipos de datos e intercalación intermodal. En el mundo real, la información suele presentarse como una fusión de múltiples modalidades, y los datos de diferentes modalidades contienen información complementaria, y la fusión eficaz de datos multimodales ayuda al modelo a aprender patrones y leyes más generales, mejorando así la capacidad de generalización del modelo. Este es uno de los elementos clave para construir modelos multimodales de alto rendimiento.
Con el fin de mejorar la capacidad de comprensión intermodal del modelo, Baichuan Intelligence construyó datos intercalados de alta calidad visual-audio-texto y entrenó el modelo con alineación utilizando 16 millones de datos gráficos, 300.000 datos de texto sin formato, 400.000 datos de audio, así como los datos intermodales mencionados anteriormente. Además, para que el modelo pudiera realizar simultáneamente diversas tareas de audio como ASR, TTS, cambio de timbre y Q&A de audio de extremo a extremo, el equipo de investigación también construyó muestras de datos específicamente relacionadas con estas tareas en los datos alineados.
El tercer punto tecnológico clave esProceso de formaciónEl diseño óptimo del modelo es el eslabón central para garantizar que los datos de alta calidad puedan mejorar eficazmente el rendimiento del modelo. BCinks Intelligence adopta un esquema de entrenamiento multietapa tanto en la fase de preentrenamiento como en la de SFT para mejorar exhaustivamente el efecto del modelo. El proceso de entrenamiento se divide en cuatro fases: la primera se basa en el entrenamiento de datos gráficos; la segunda añade datos de audio para el preentrenamiento; la tercera introduce datos de vídeo para el entrenamiento; y la última es la fase de alineación multimodal, que en última instancia permite al modelo tener la capacidad de comprender de forma exhaustiva el contenido multimodal.
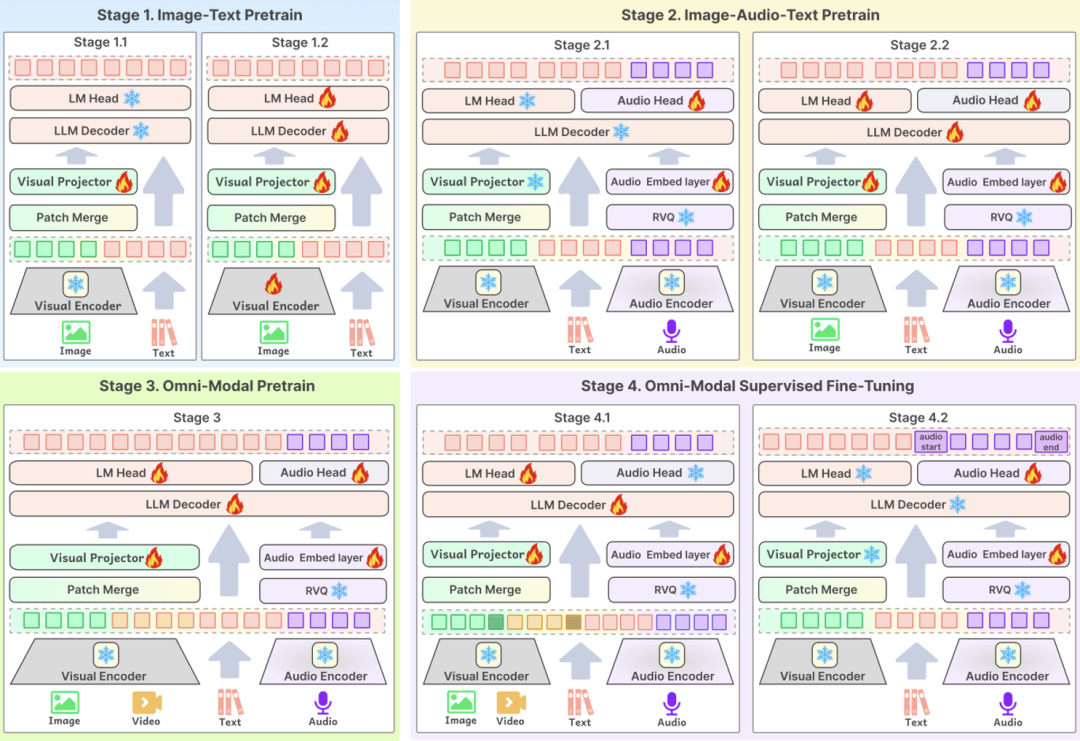
Sobre la base de la optimización técnica integral mencionada, la capacidad global de Baichuan-Omni-1.5 se ha mejorado significativamente en comparación con el modelo tradicional de gran lenguaje monomodal o el modelo multimodal. El lanzamiento de Baichuan-Omni-1.5 no sólo es otro hito importante en la investigación y el desarrollo tecnológico de Baichuan Intelligence, sino que también significa que el centro de desarrollo de la IA se está acelerando desde la mejora de la capacidad básica del modelo hasta la aplicación práctica.
Anteriormente, la mejora de la capacidad del gran modelo se centraba principalmente en capacidades básicas como la comprensión del lenguaje y el reconocimiento de imágenes, mientras que la potente capacidad de fusión multimodal de Baichuan-Omni-1.5 ayudará a la tecnología a lograr una integración más estrecha con los escenarios de aplicación del mundo real. Al mejorar las capacidades integrales del modelo en el procesamiento de información multimodal, como el lenguaje, la visión, el audio, etc., Baichuan-Omni-1.5 es capaz de responder eficazmente a tareas de aplicación práctica más complejas y diversas. Por ejemplo, en la industria médica, las potentes capacidades de comprensión y generación del modelo omnimodal pueden utilizarse para ayudar a los médicos en el diagnóstico de enfermedades, mejorando la precisión y la eficacia del diagnóstico, lo que tiene un gran valor de exploración para promover la aplicación en profundidad de la tecnología de IA en el campo médico. De cara al futuro, el lanzamiento de Baichuan-Omni-1.5 puede ser el comienzo de la aplicación de la tecnología de IA en los campos médico y sanitario en la era de la AGI, y tenemos motivos para esperar que la IA desempeñe un papel más importante en la medicina y otros campos en un futuro próximo, cambiando profundamente nuestras vidas.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados




Sin comentarios...