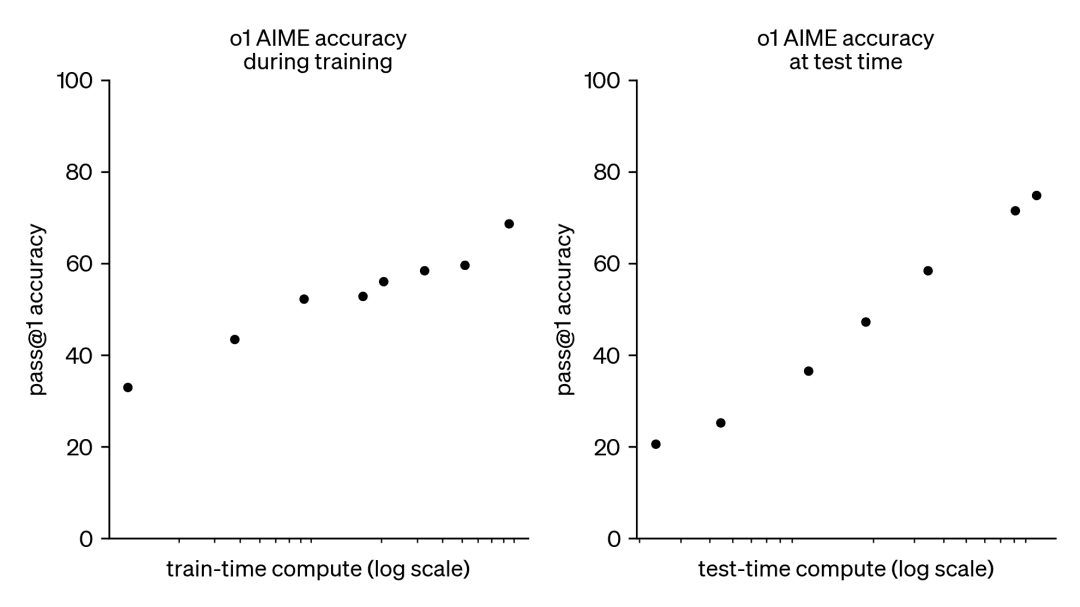
ChatGPT sigue encabezando muchas listas de IA, pero la competencia le sigue de cerca

¿Cómo se determinan los modelos de IA más potentes disponibles en la actualidad? Echa un vistazo a la clasificación para averiguarlo.
En los últimos meses se han popularizado en Internet las tablas de clasificación de modelos de inteligencia artificial compiladas por la comunidad, que ofrecen una ventana en tiempo real a la pugna entre los principales gigantes tecnológicos en el espacio de la inteligencia artificial.
Varias tablas de clasificación documentan qué modelos de IA son los más avanzados en la realización de determinadas tareas.Los modelos de IA son esencialmente un conjunto de fórmulas matemáticas envueltas en código diseñadas para lograr un propósito específico.
Como Gemini de Google (antes Bard) y las startups de París Mistral AI Nuevos participantes, como Mistral-Medium, han galvanizado la comunidad de la IA y se disputan el primer puesto de la clasificación.
Sin embargo, la GPT-4 de OpenAI sigue dominando.
A la gente le interesa lo último en tecnología", afirma Ying Sheng, estudiante de doctorado en informática de la Universidad de Stanford y cocreador de la tabla de clasificación de Chatbot Arena. Creo que a la gente le gusta ver cómo cambian las tablas. Demuestra que el juego sigue avanzando y que aún se puede mejorar".
Las clasificaciones se basan en pruebas de las capacidades de los modelos de IA, diseñadas para averiguar de qué es capaz normalmente la IA y qué modelos podrían ser más adecuados para aplicaciones específicas, como el reconocimiento de voz. Estas pruebas, a veces denominadas pruebas comparativas, miden el rendimiento de la IA a través de parámetros como la similitud de la vocalización de una IA con la voz humana o la humanidad de las respuestas de un chatbot de IA.
A medida que la IA sigue evolucionando, la mejora continua de estas pruebas es igualmente crítica.
Vanessa Parli, directora de investigación del Instituto de Inteligencia Artificial del Centro para la Dimensión Humana de la Universidad de Stanford, afirma: "Estos puntos de referencia no son perfectos, pero por ahora es la única forma que tenemos de evaluar el sistema".
El informe anual del Instituto sobre el Índice de Inteligencia Artificial de Stanford hace un seguimiento del rendimiento técnico de los modelos de IA a lo largo del tiempo según diversas métricas. Según Parli, en el informe del año pasado se investigaron 50 puntos de referencia, pero sólo se incluyeron 20. Este año, el informe eliminará algunas referencias obsoletas para centrarse en otras nuevas y más completas.
La clasificación Open LLM [Large Language Model] creada por Hugging Face, una plataforma de aprendizaje automático de código abierto, ha evaluado y clasificado más de 4.200 modelos a principios de febrero, todos ellos enviados por miembros de la comunidad.
Los modelos participan en siete pruebas de referencia clave diseñadas para evaluar su capacidad en diversas categorías, como la comprensión lectora y la resolución de problemas matemáticos. El proceso de evaluación incluye preguntas de matemáticas y ciencias de primaria que ponen a prueba el razonamiento de sentido común de los modelos y miden su tendencia a difundir información errónea. Algunas de las pruebas tienen un formato de elección múltiple, mientras que otras requieren que los modelos generen sus propias respuestas basándose en pistas.

ChatGPT-4, de OpenAI, encabeza la clasificación de LMSYS Chatbot Arena, seguido de cerca por Geminivia, de Google. LMSYS
Los visitantes pueden ver el rendimiento específico de cada modelo en una prueba de referencia concreta, así como su puntuación media total. Hasta ahora, ningún modelo ha logrado una puntuación perfecta de 100 en ninguna prueba de referencia. Smaug-72B, un modelo de IA desarrollado recientemente por la empresa de San Francisco Abacus.AI, se convirtió en el primer modelo en superar los 80 puntos de media.
Muchos modelos lingüísticos a gran escala ya han superado a los humanos en este tipo de pruebas, un fenómeno que los investigadores denominan "saturación", explica Thomas Wolf, cofundador y director científico de Hugging Face. Suele ocurrir cuando la capacidad del modelo aumenta más allá de una prueba concreta, como cuando un estudiante pasa de la enseñanza media a la secundaria y supera progresivamente la etapa anterior de aprendizaje, o cuando el modelo ha memorizado cómo responder a determinadas preguntas de la prueba, un concepto conocido como "sobreajuste".
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...