
¿450 para entrenar un "o1-preview"? UC Berkeley abre el modelo de inferencia de 32B Sky-T1, la comunidad de IA en ebullición

Un precio de 450 dólares no parece mucho a primera vista. Pero, ¿y si ese fuera el coste total del entrenamiento de un modelo de inferencia de 32B?
Sí, a medida que nos acercamos a 2025, los modelos de inferencia son cada vez más fáciles de desarrollar, y el coste está disminuyendo rápidamente hasta niveles que antes no podíamos imaginar.
Recientemente, NovaSky, un equipo de investigación del Sky Computing Lab de la Universidad de California en Berkeley, lanzó Sky-T1-32B-Preview.Curiosamente, el equipo afirma que "Sky-T1-32B-Preview cuesta menos de 450 dólares entrenarlo, lo que sugiere que es posible replicar de forma económica y eficiente las capacidades de razonamiento de alto nivel."

- Página de inicio del proyecto: https://novasky-ai.github.io/posts/sky-t1/
- Dirección de código abierto: https://huggingface.co/NovaSky-AI/Sky-T1-32B-Preview
Según la información oficial, este modelo de inferencia igualó a una versión anterior de OpenAI o1 en varias pruebas clave.

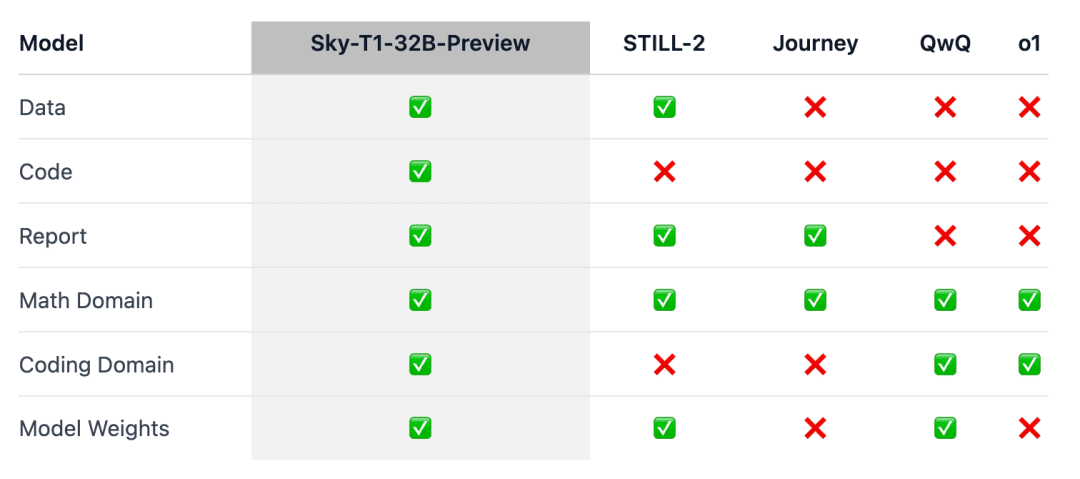
La cuestión es que Sky-T1 parece ser el primer modelo de inferencia realmente de código abierto, ya que el equipo ha publicado el conjunto de datos de entrenamiento, así como el código de entrenamiento necesario para que cualquiera pueda replicarlo desde cero.
La gente exclamó: "Qué asombrosa aportación de datos, código y pesos de modelos".
No hace mucho, el precio de entrenar un modelo con un rendimiento equivalente solía ascender a millones de dólares. Los datos de entrenamiento sintéticos o generados por otros modelos han permitido reducir considerablemente los costes.
Anteriormente, una empresa de IA, Writer, lanzó el Palmyra X 004, que se entrenó casi por completo con datos sintéticos y cuyo desarrollo costó sólo 700.000 dólares.
Imaginemos que este programa se ejecuta en el superordenador de IA Nvidia Project Digits, que cuesta 3.000 dólares (barato para un superordenador) y puede ejecutar modelos con hasta 200.000 millones de parámetros. En un futuro próximo, los modelos con menos de un billón de parámetros podrán ser ejecutados localmente por particulares.
La evolución de la tecnología de los grandes modelos en 2025 se está acelerando.
Visión general del modelo
Los razonamientos o1 y Géminis 2.0 Modelos como el pensamiento flash han resuelto tareas complejas y logrado otros avances generando largas cadenas internas de pensamiento. Sin embargo, los detalles técnicos y las ponderaciones de los modelos no están disponibles, lo que supone una barrera para el compromiso académico y de la comunidad de código abierto.
Con este fin, se han obtenido algunos resultados notables en el campo de las matemáticas para el entrenamiento de modelos de inferencia de ponderación abierta, como Still-2 y Journey.Mientras tanto, el equipo NovaSky de la Universidad de California, en Berkeley, ha estado explorando una variedad de técnicas para desarrollar las capacidades de inferencia tanto de los modelos de base como de los sintonizados por comandos.
En este trabajo, Sky-T1-32B-Preview, el equipo logró un rendimiento de inferencia competitivo no sólo en el aspecto matemático, sino también en el de codificación del mismo modelo.

Para garantizar que este trabajo "beneficie a la comunidad en general", el equipo puso a disposición pública todos los detalles (por ejemplo, datos, código, pesos del modelo) para que la comunidad pudiera reproducirlo y mejorarlo fácilmente:
- Infraestructura: creación de datos, formación y evaluación de modelos en un único repositorio;
- Datos: 17K de datos utilizados para entrenar Sky-T1-32B-Preview;
- Detalles técnicos: informes técnicos y registros wandb;
- Pesos del modelo: 32B Pesos del modelo.
Ficha técnica
Proceso de recopilación de datos
Para generar los datos de entrenamiento, el equipo utilizó QwQ-32B-Preview, un modelo de código abierto con capacidades de inferencia comparables a o1-preview. El equipo organizó la combinación de datos para cubrir los distintos ámbitos en los que era necesario realizar inferencias y utilizó un procedimiento de muestreo de rechazo para mejorar la calidad de los datos.
A continuación, inspirándose en Still-2, el equipo reescribió la traza QwQ en una versión estructurada utilizando GPT-4o-mini para mejorar la calidad de los datos y simplificar el análisis sintáctico.
Descubrieron que la simplicidad del análisis sintáctico era especialmente beneficiosa para los modelos de inferencia. Éstos están entrenados para responder en un formato específico, y los resultados suelen ser difíciles de analizar. Por ejemplo, en el conjunto de datos APPs, sin reformatear, el equipo sólo podía suponer que el código estaba escrito en el último bloque de código, y QwQ sólo podía alcanzar una precisión de unos 25%. Sin embargo, a veces el código puede estar escrito en el medio y, tras el reformateo, la precisión aumenta a más de 90%.
Rechazar muestra. Dependiendo de la solución proporcionada con el conjunto de datos, si la muestra QwQ es incorrecta, el equipo la descarta. Para los problemas matemáticos, el equipo realiza una comparación exacta con la solución real. Para los problemas de codificación, el equipo realiza las pruebas unitarias proporcionadas en el conjunto de datos. Los datos finales del equipo consisten en 5k de datos codificados de APPs y TACO, y 10k de datos matemáticos del subconjunto de Olimpiadas de los conjuntos de datos AIME, MATH y NuminaMATH. Además, el equipo conservó 1k de datos de ciencia y rompecabezas de STILL-2.
tren
El equipo utilizó los datos de entrenamiento para ajustar Qwen2.5-32B-Instruct, un modelo de código abierto sin capacidad de inferencia. El modelo se entrenó utilizando 3 épocas, una tasa de aprendizaje de 1e-5 y un tamaño de lote de 96. El entrenamiento del modelo se completó en 19 horas en 8 H100 utilizando una descarga DeepSpeed Zero-3 (con un precio de unos 450 dólares según Lambda Cloud). El equipo utilizó Llama-Factory para el entrenamiento.
Resultados de la evaluación
Sky-T1 superó a una versión previa de o1 en MATH500, un reto matemático de "nivel competitivo", y también a una versión previa de o1 en un conjunto de acertijos de LiveCodeBench, una evaluación de codificación. Sin embargo, Sky-T1 no es tan bueno como la versión preliminar de o1 en GPQA-Diamond, que contiene problemas relacionados con la física, la biología y la química que los graduados de doctorado deberían conocer.
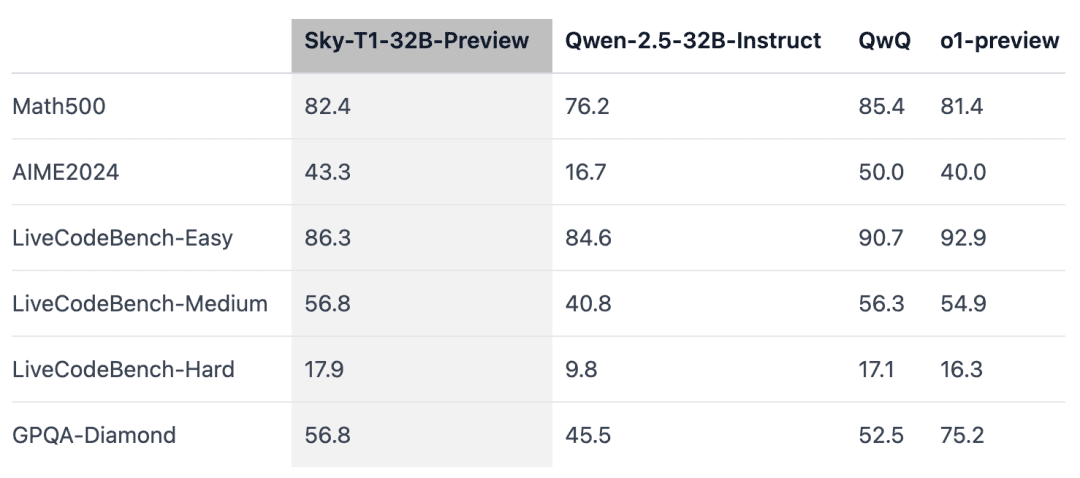
Sin embargo, la versión o1 GA de OpenAI es más potente que la versión preliminar de o1, y OpenAI espera lanzar un modelo de inferencia de mejor rendimiento, o3, en las próximas semanas.
Nuevos hallazgos que merecen atención
El tamaño del modelo importa.El equipo probó inicialmente a entrenar modelos más pequeños (7B y 14B), pero observó pocas mejoras. Por ejemplo, el entrenamiento de Qwen2.5-14B-Coder-Instruct en el conjunto de datos APPs mostró una ligera mejora en el rendimiento en LiveCodeBench, de 42,6% a 46,3%.Sin embargo, al examinar manualmente la salida de los modelos más pequeños (los menores de 32B), el equipo descubrió que a menudo generaban contenido duplicado, lo que lo que limitaba su eficacia.
La combinación de datos es importante.El equipo entrenó inicialmente el modelo 32B utilizando 3-4K problemas de matemáticas del conjunto de datos Numina (proporcionado por STILL-2), y la precisión de AIME24 mejoró significativamente de 16,7% a 43,3%. Sin embargo, cuando se incorporaron al proceso de entrenamiento los datos de programación generados a partir del conjunto de datos APPs, la precisión de AIME24 descendió a 36,7%. Es posible que este descenso se deba a los diferentes métodos de inferencia necesarios para las tareas matemáticas y de programación.
El razonamiento en programación suele implicar pasos lógicos adicionales, como la simulación de entradas de prueba o la ejecución interna de código generado, mientras que el razonamiento para problemas matemáticos tiende a ser más directo y estructurado.Para abordar estas diferencias, el equipo enriqueció los datos de entrenamiento con problemas matemáticos desafiantes del conjunto de datos NuminaMath y tareas de programación complejas del conjunto de datos TACO. Esta combinación equilibrada de datos permitió al modelo sobresalir en ambos dominios, recuperando una precisión de 43,3% en AIME24 al tiempo que mejoraba sus capacidades de programación.
Al mismo tiempo, algunos investigadores han expresado su escepticismo:


¿Qué opina la gente? Siéntase libre de discutirlo en la sección de comentarios.
Enlace de referencia: https://www.reddit.com/r/LocalLLaMA/comments/1hys13h/new_model_from_httpsnovaskyaigithubio/
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...