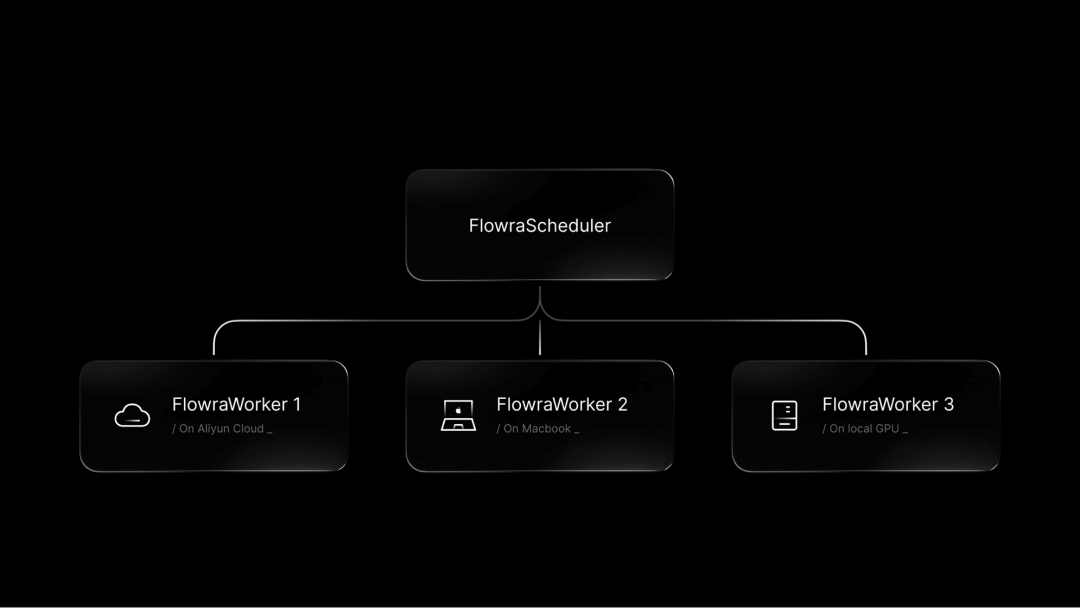
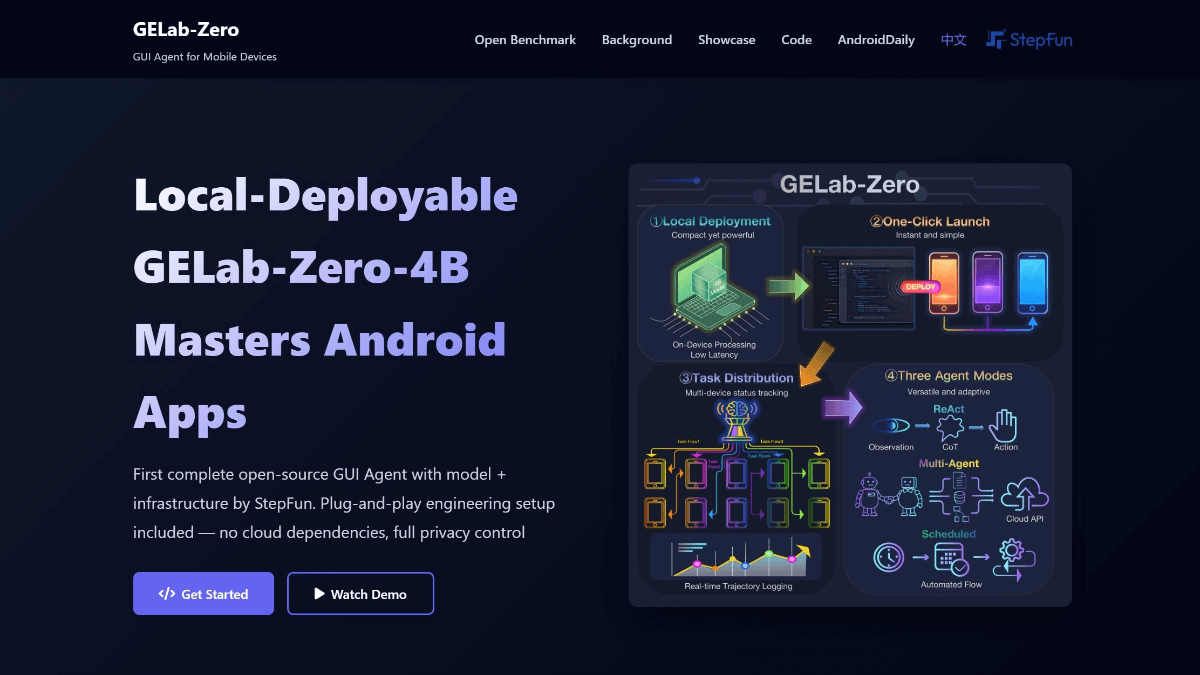
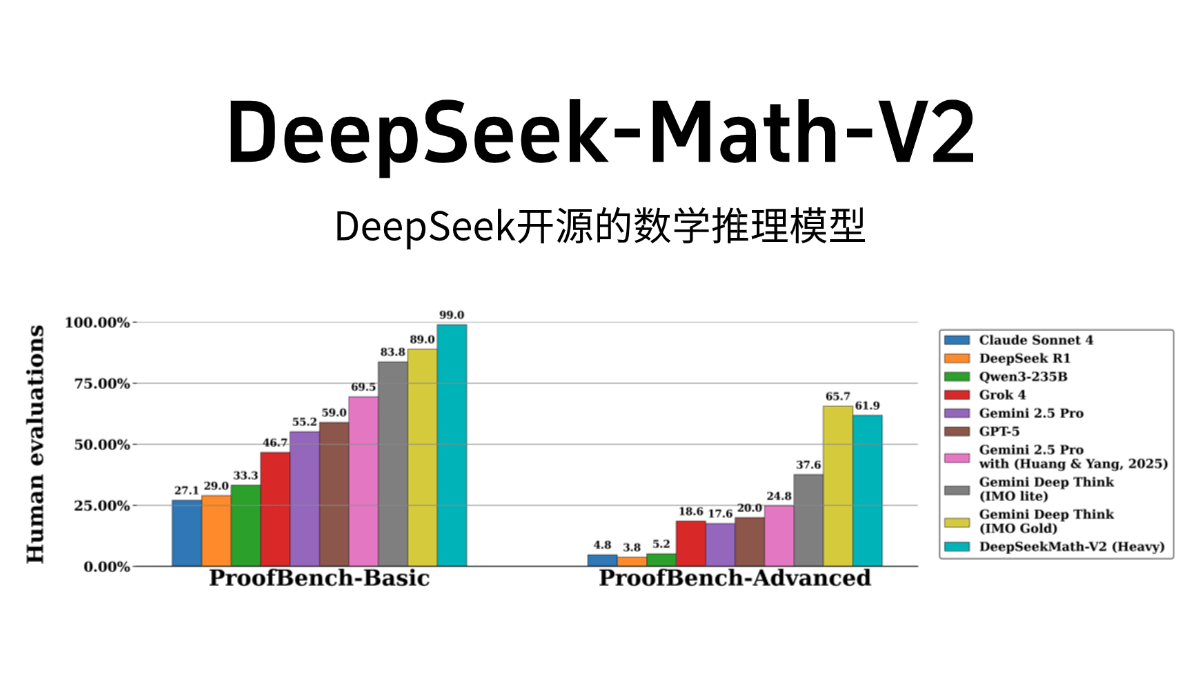
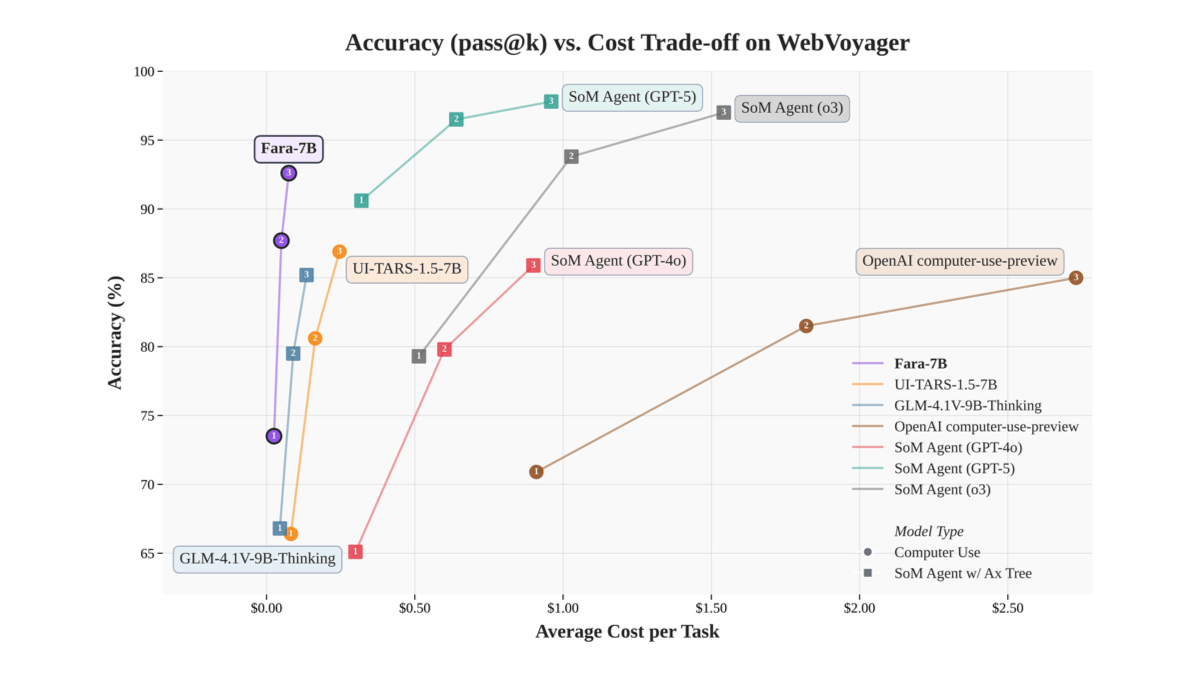
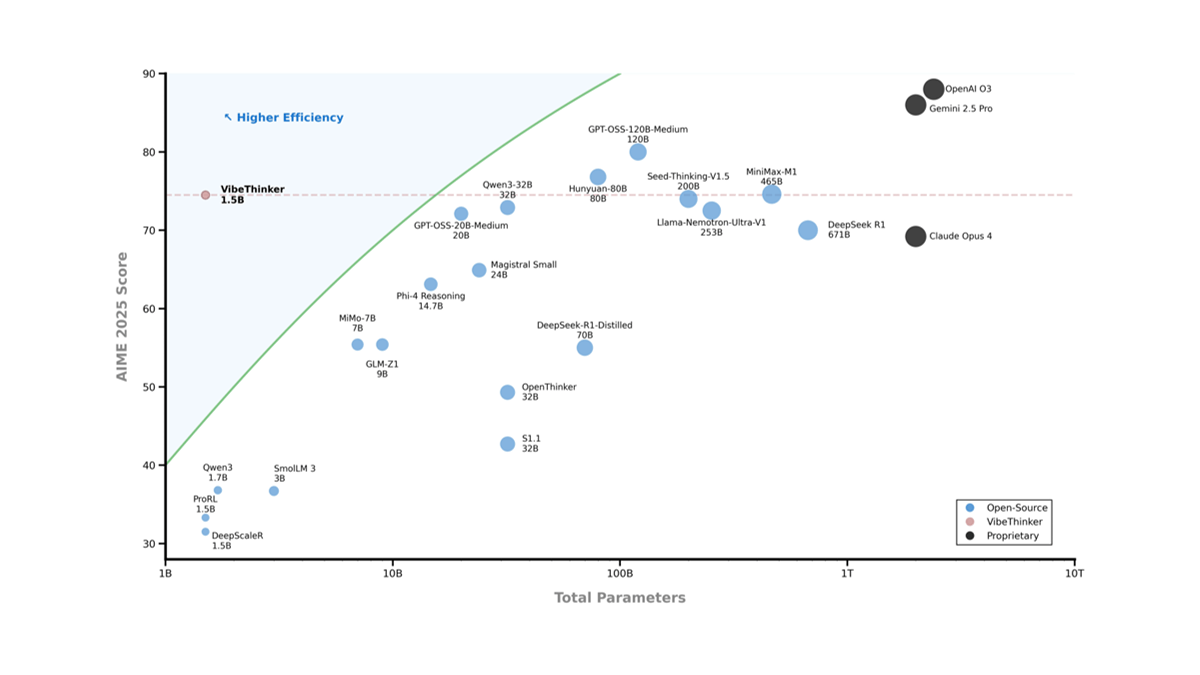
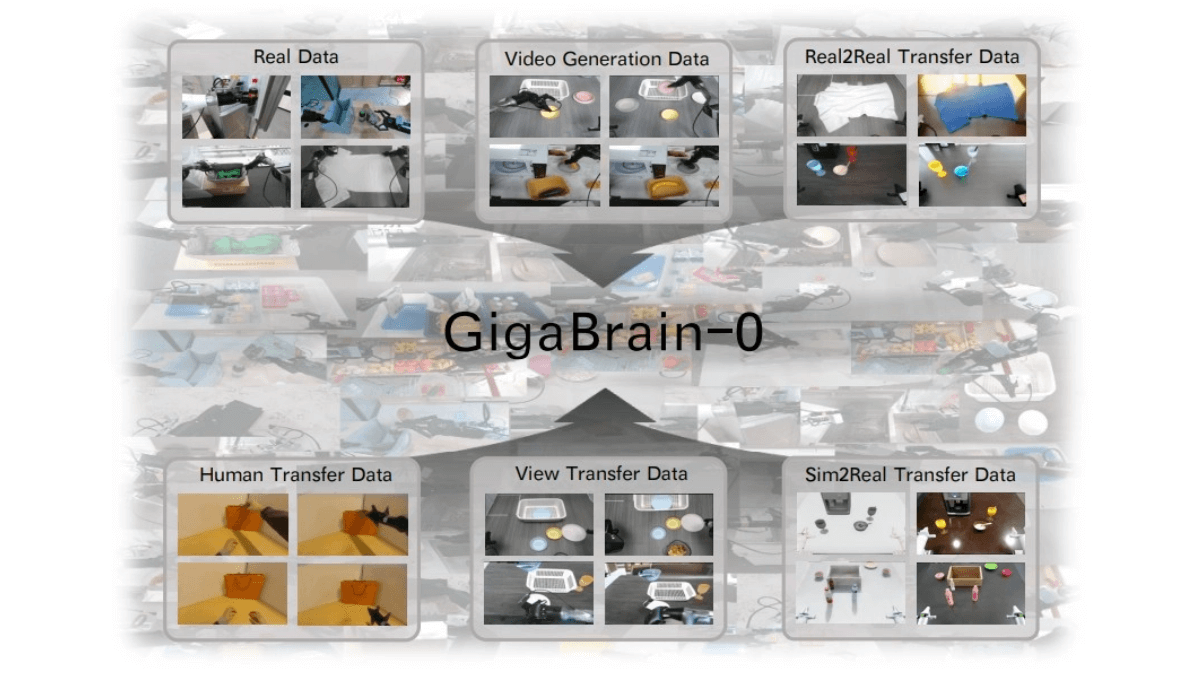
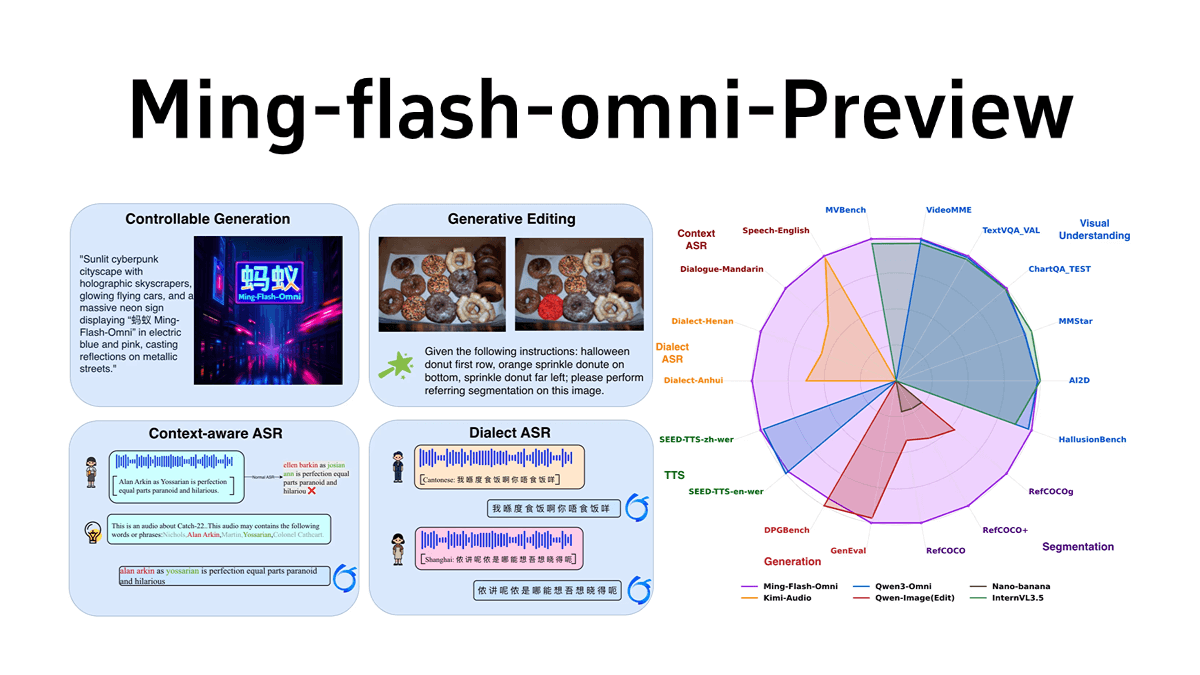
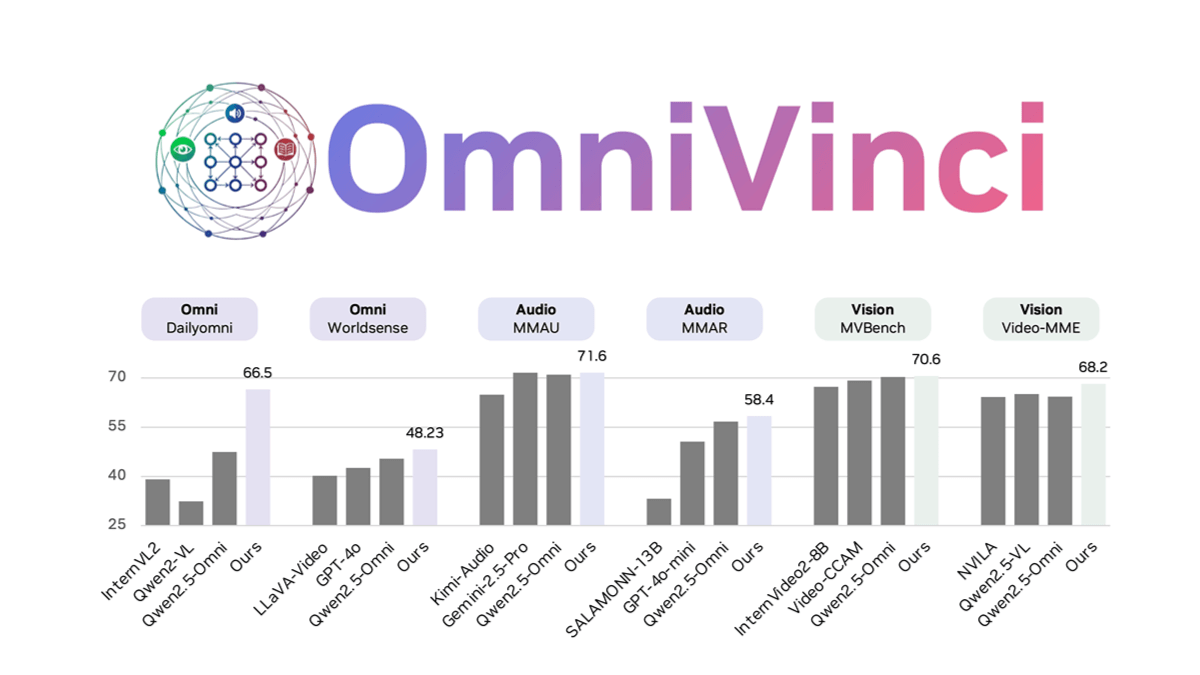
NewBie-image-Exp0.1 - NewBieAI-Lab open source experimental anime literate graphical models
NewBie-image-Exp0.1 is the first experimental anime text-born graph model open-sourced by the NewBieAI-Lab team, using the Next-DiT architecture with 3.5B parameters, optimized for the secondary style. The model is optimized for the secondary style by a dual text encoder (GEMMA3-4B...