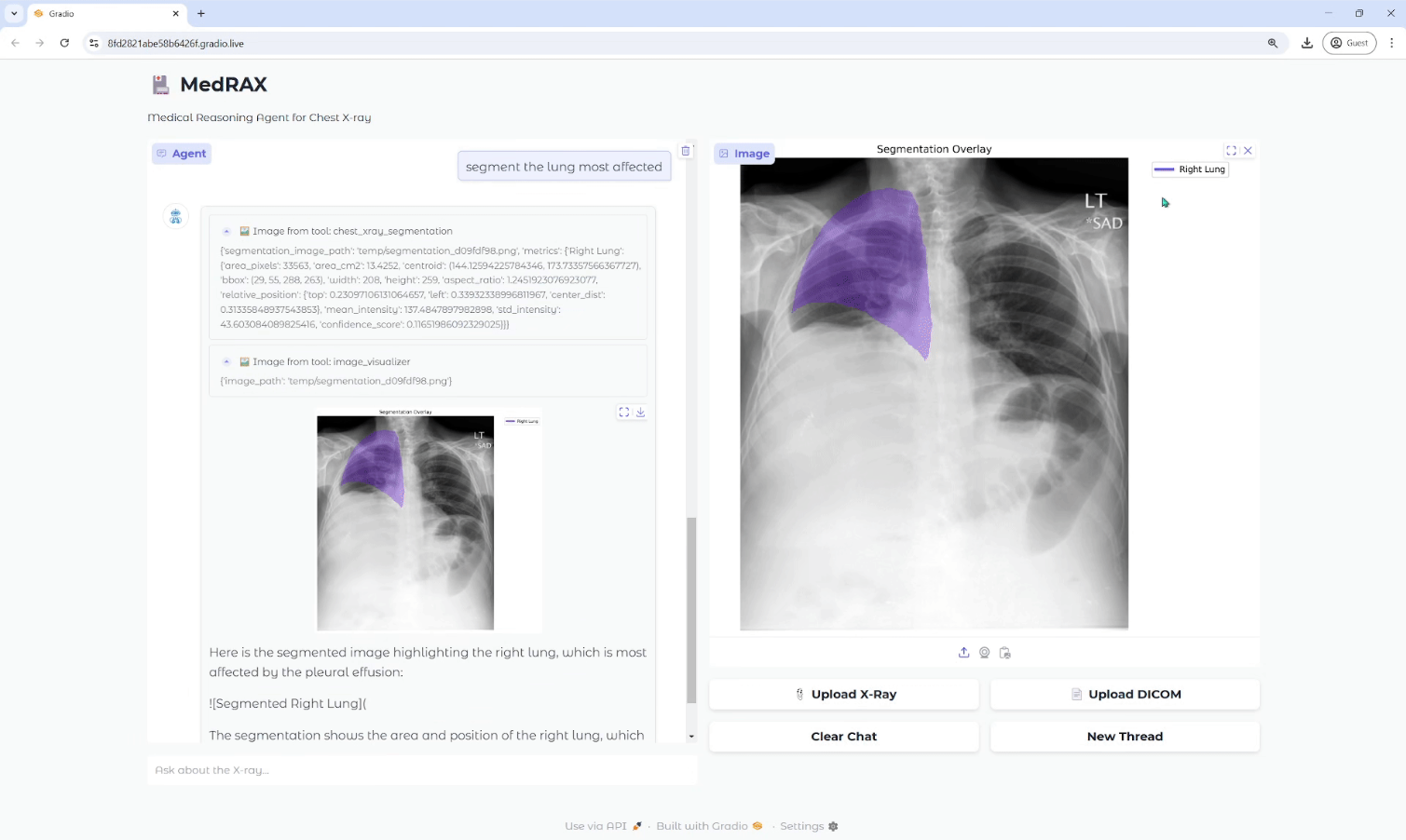
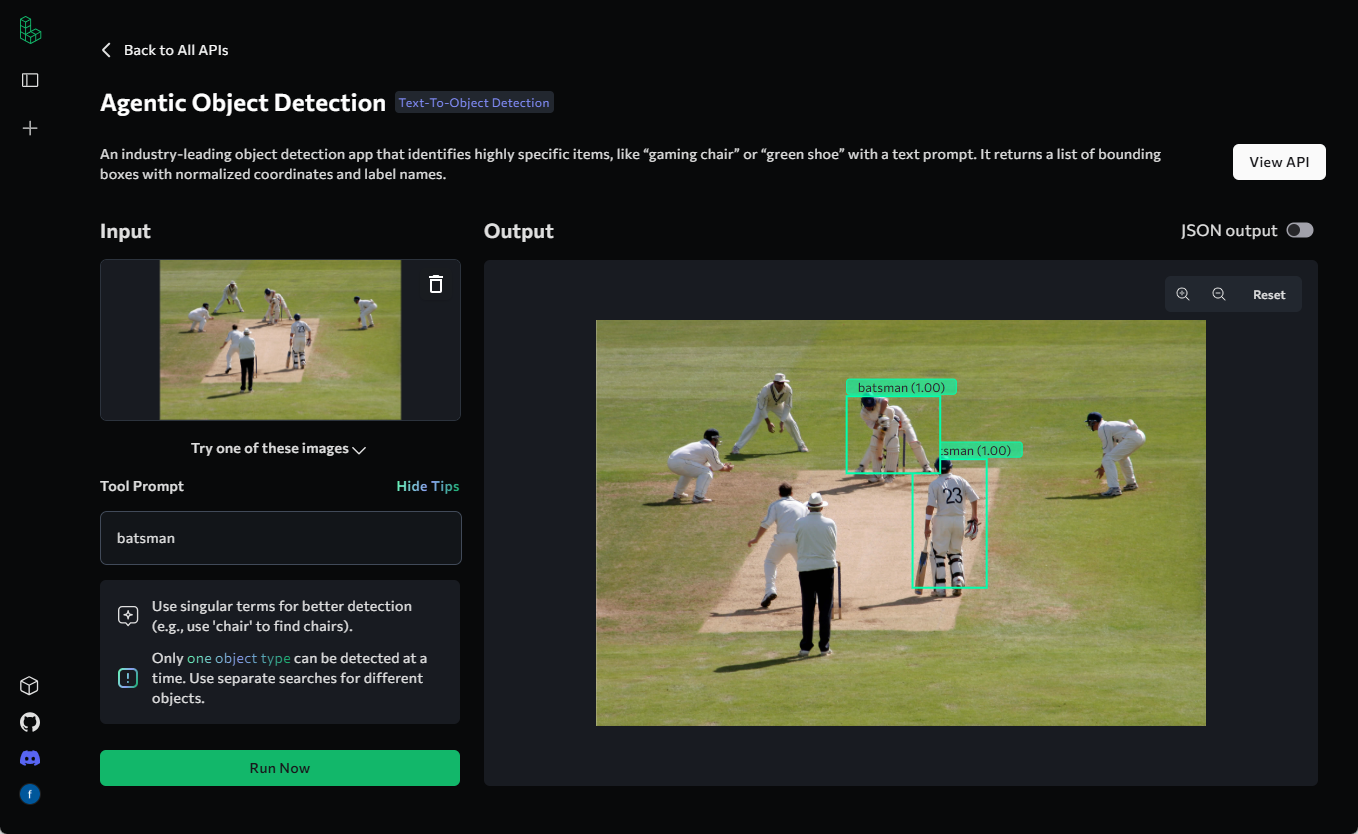
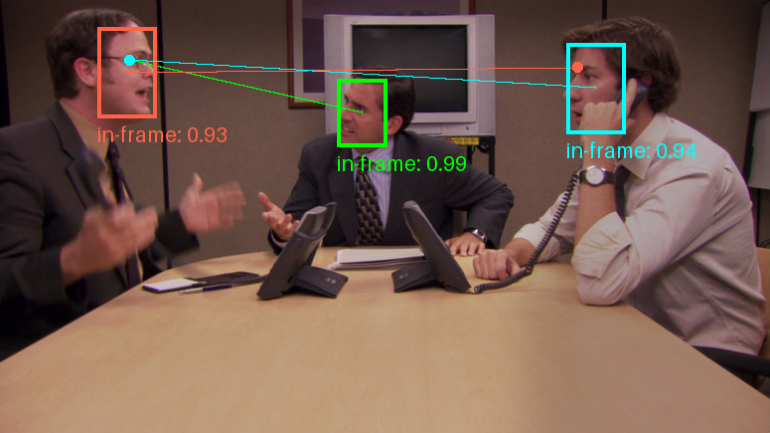
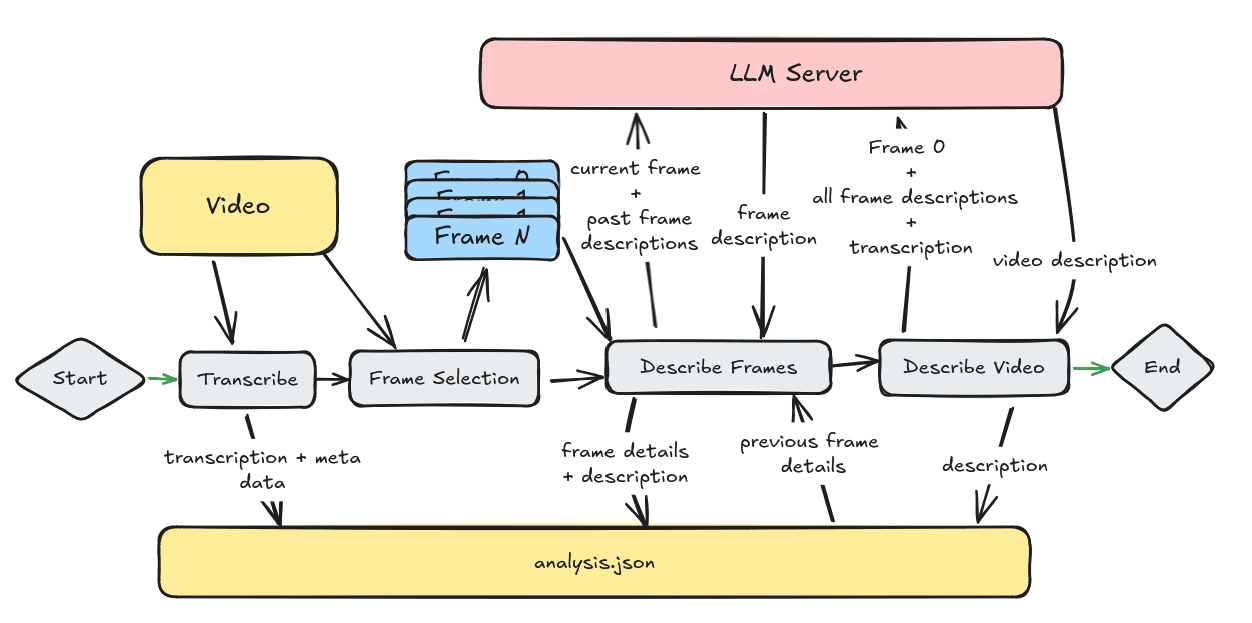
Trackers: open source tool library for video object tracking
General Introduction Trackers is an open source Python tool library focused on multi-object tracking in video. It integrates several leading tracking algorithms, such as SORT and DeepSORT, and allows users to combine different object detection models (such as YOLO...