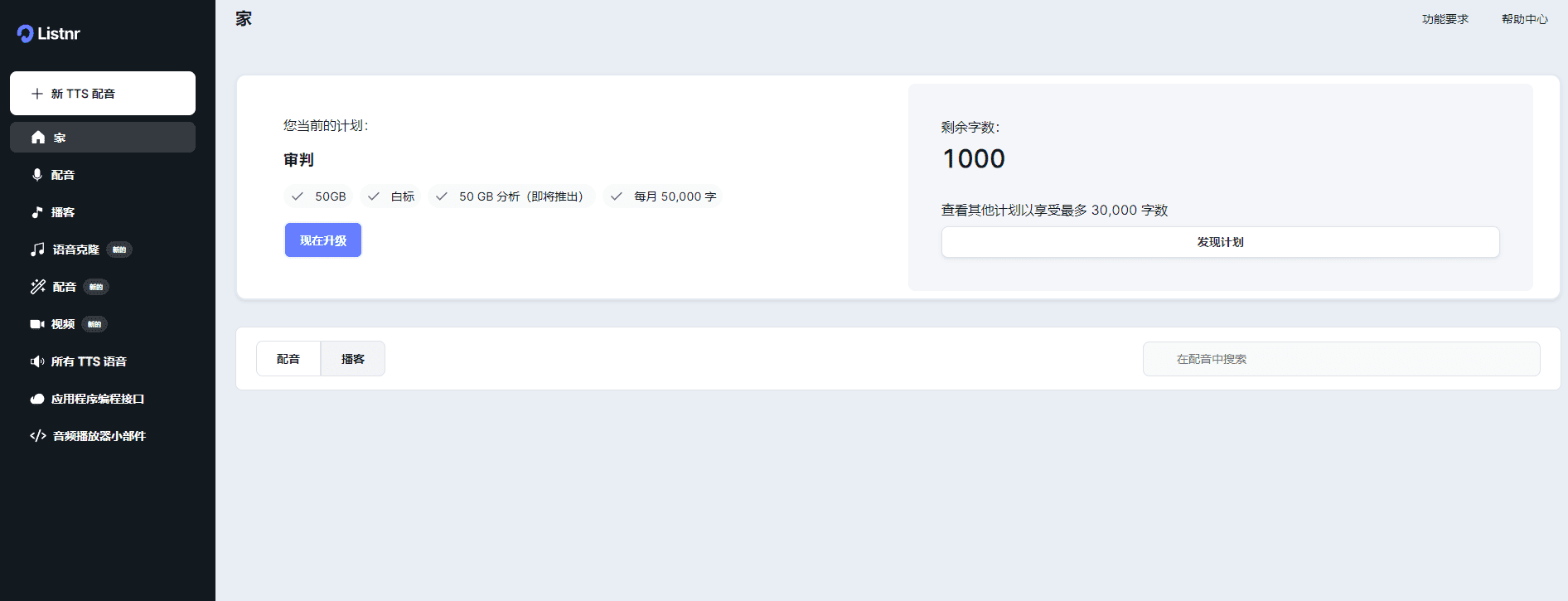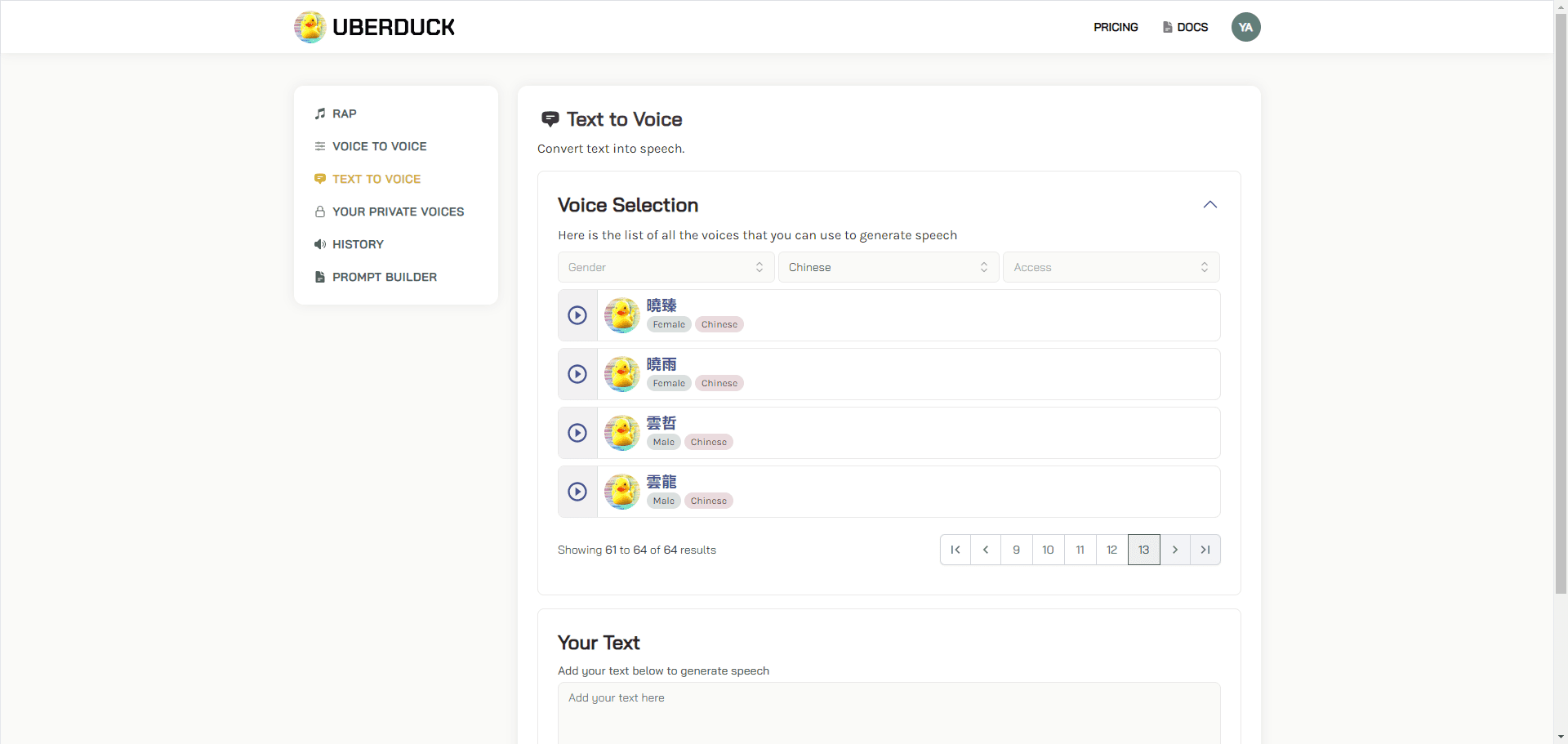
Muyan-TTS: Personalized Podcast Speech Training and Synthesis
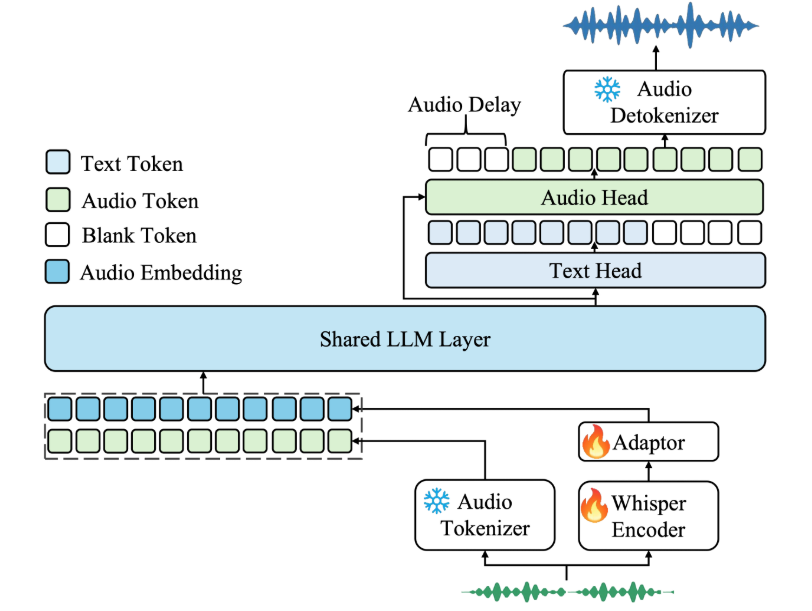
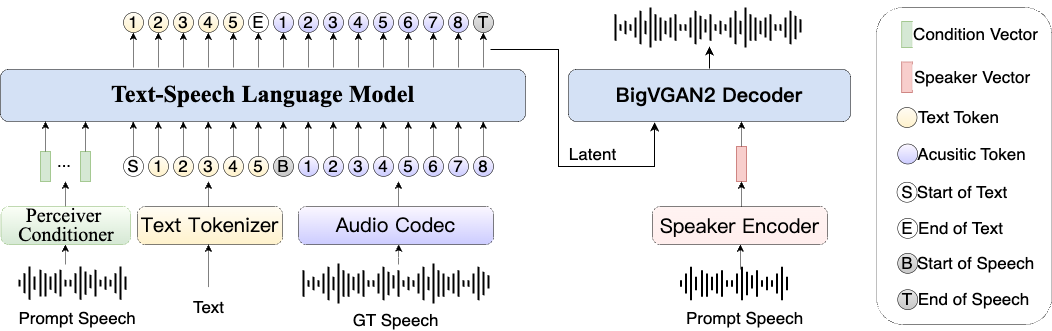
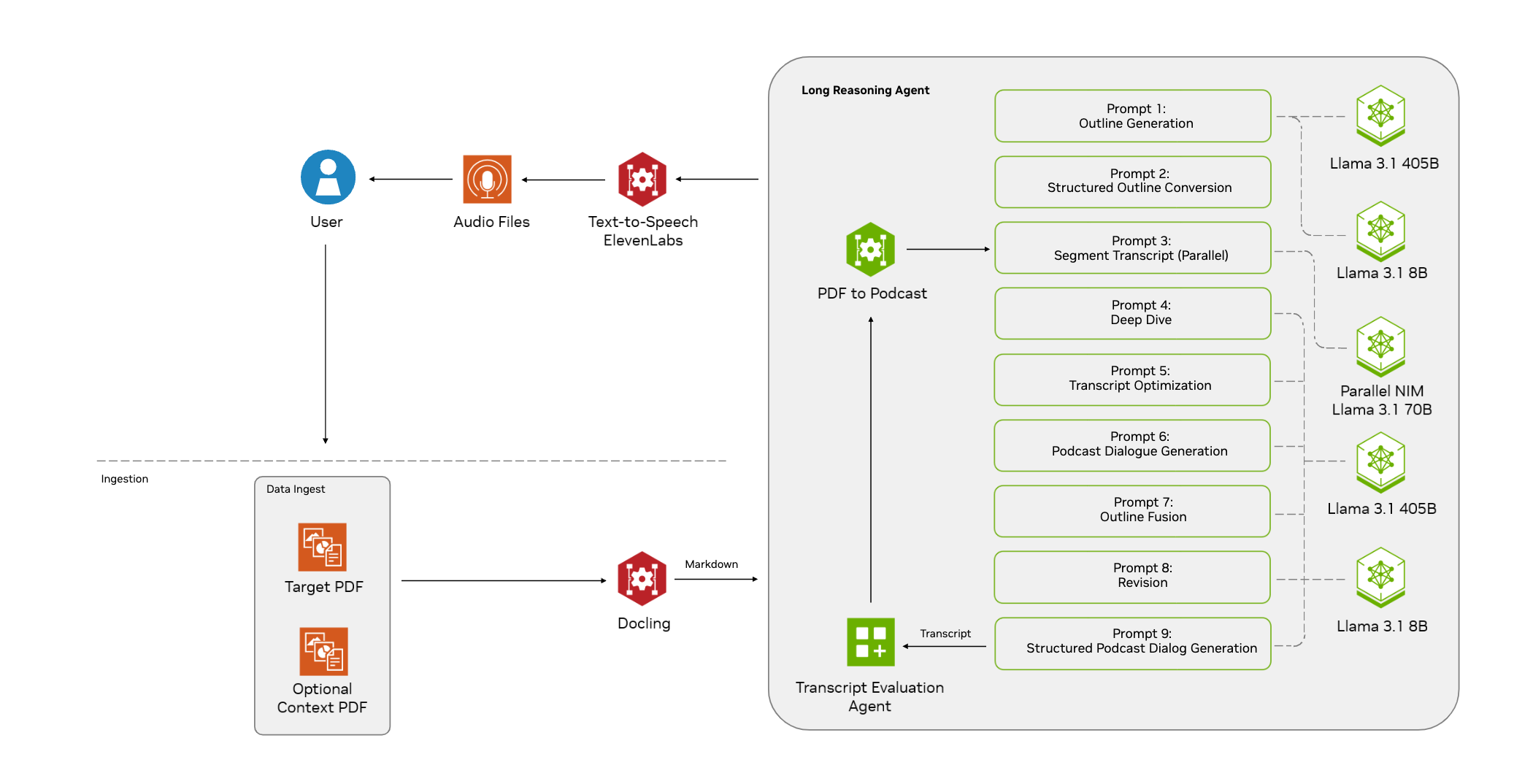
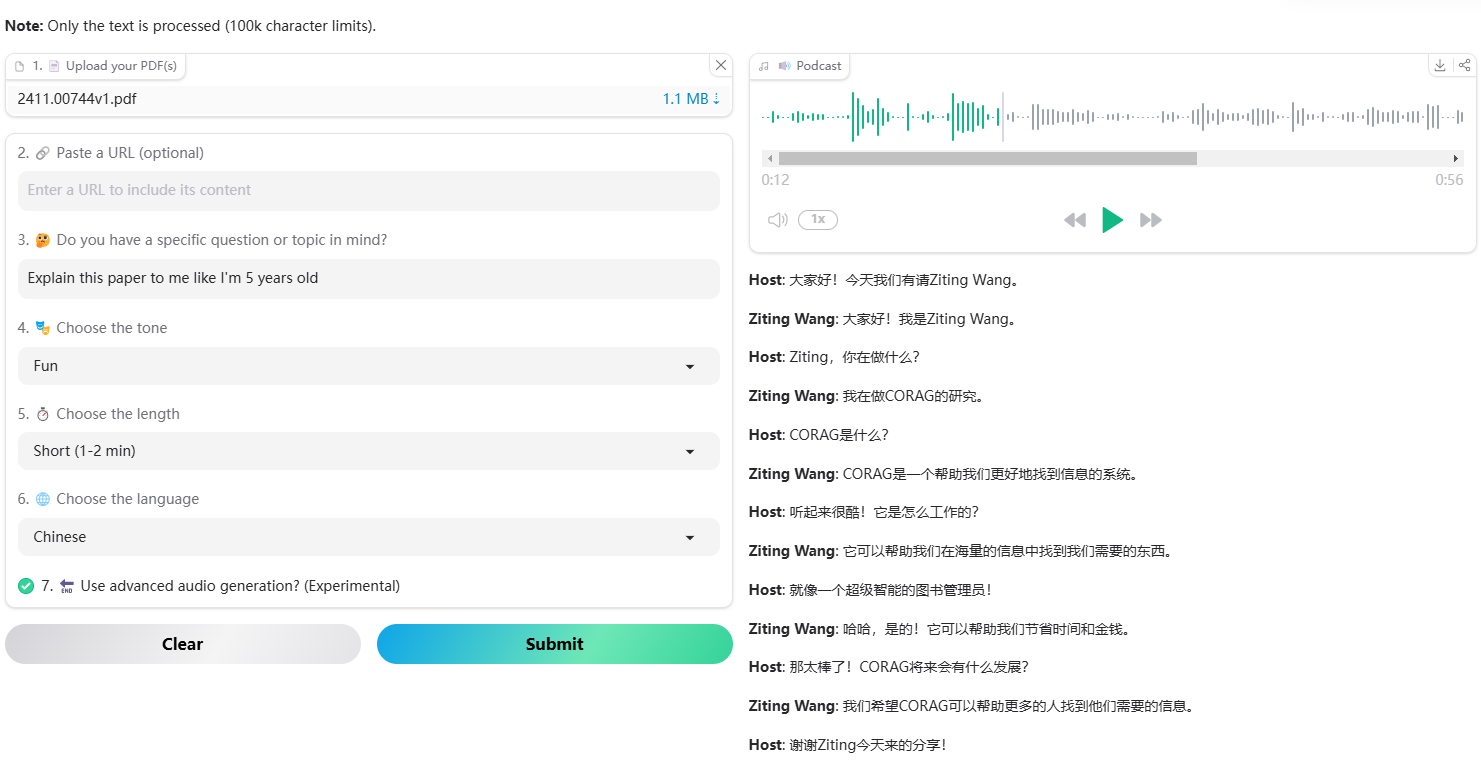
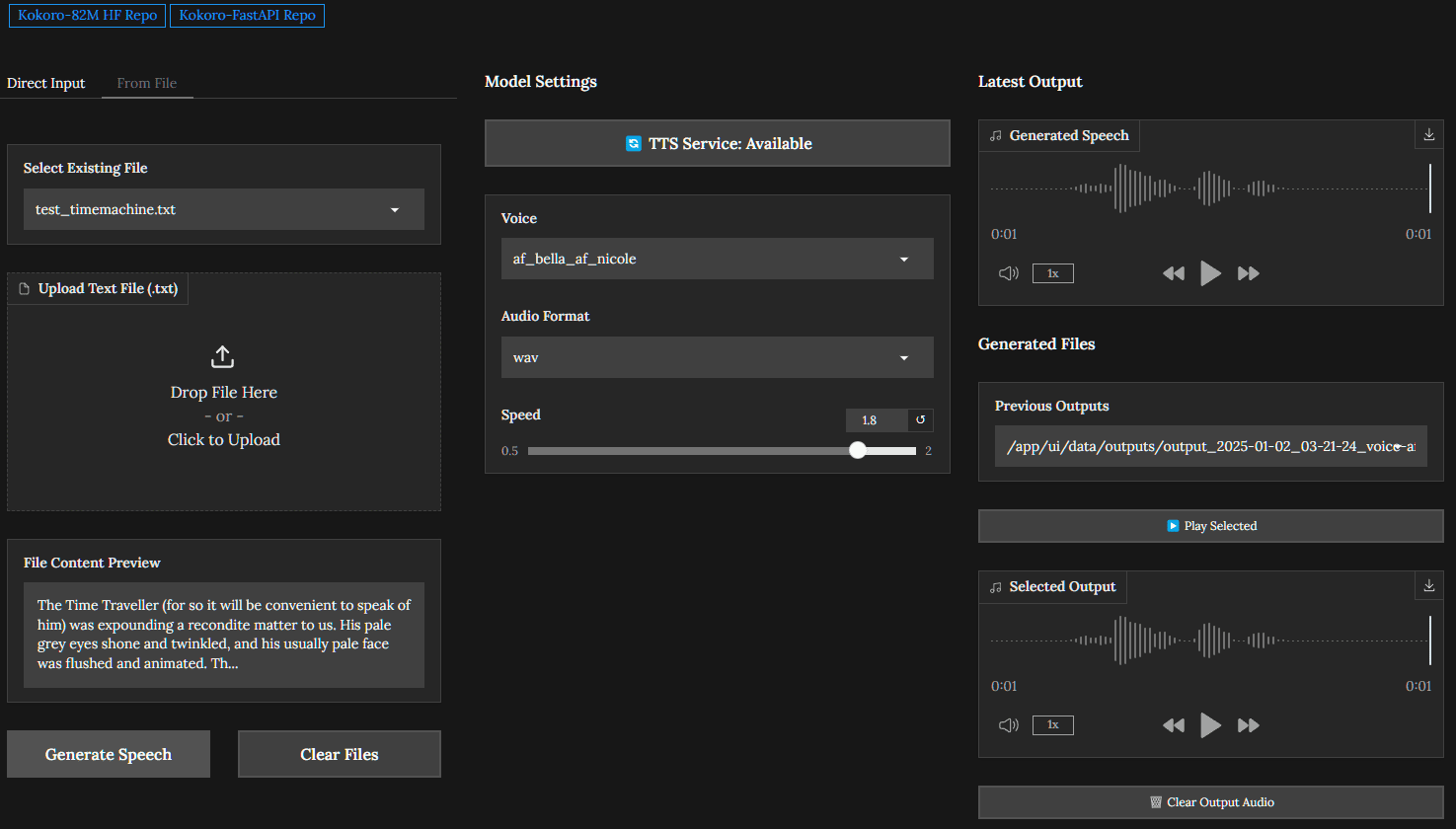
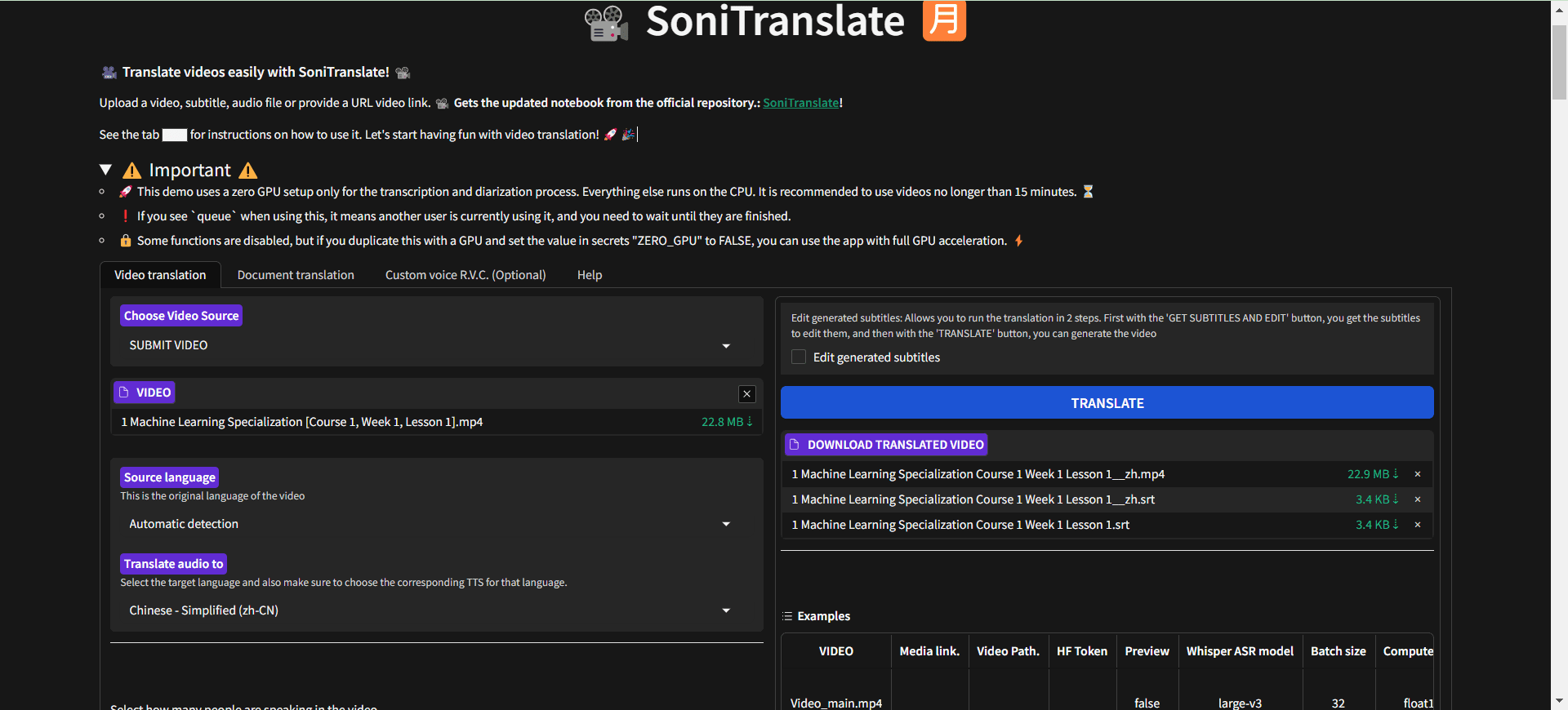
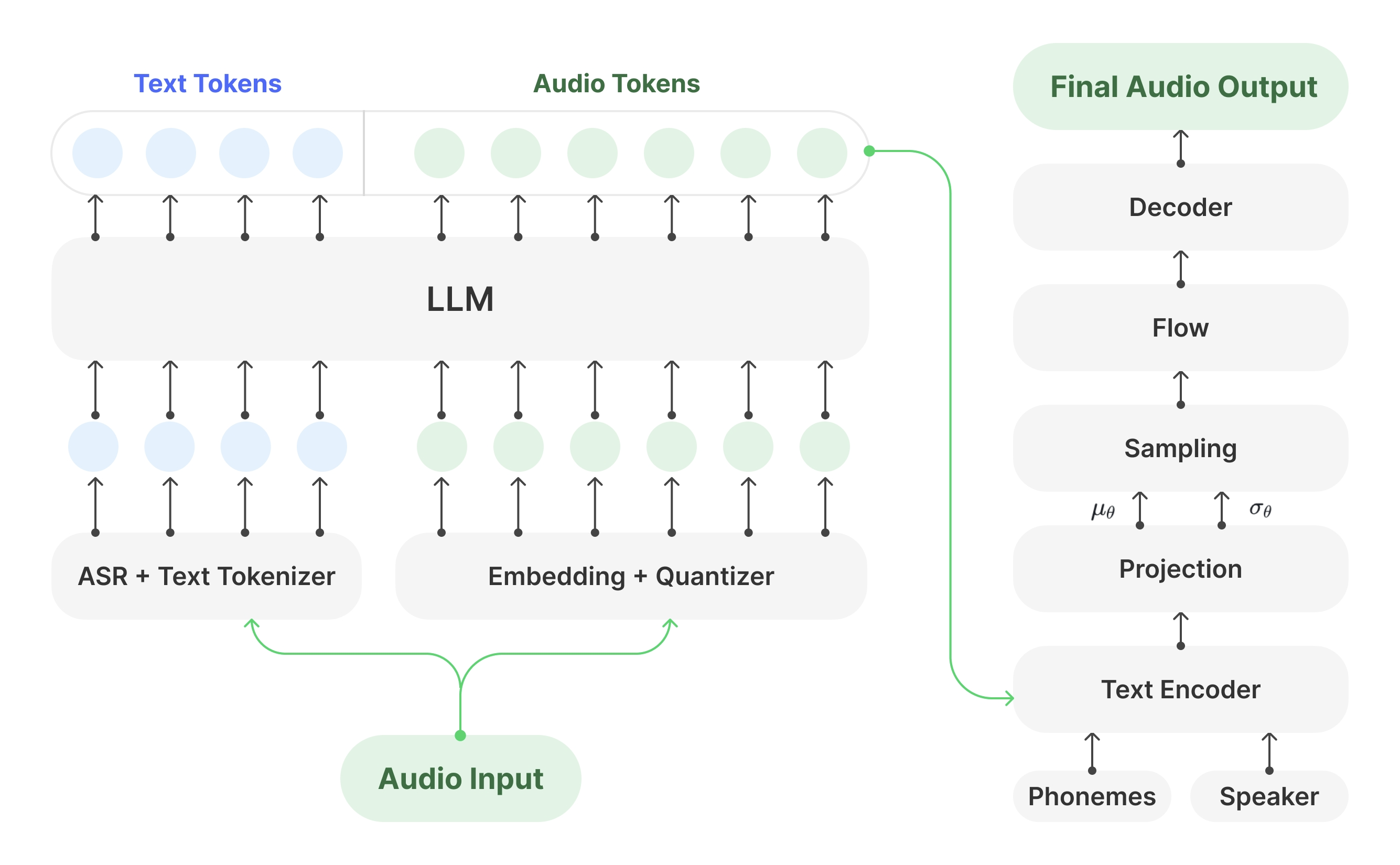
Synthesis Muyan-TTS is an open source text-to-speech (TTS) model designed for podcasting scenarios. It is pre-trained with over 100,000 hours of podcast audio data and supports zero-sample speech synthesis to generate high-quality natural speech. The model is based on Llama-3.2-3...