Step-Audio-EditX - Step-Star's first open source LLM-level audio editing large model

What is Step-Audio-EditX?
Step-Audio-EditX is an open source audio editing large model, developed by Step-Audio-Star team, focusing on the fine manipulation of audio content through artificial intelligence technology. The model can dynamically adjust the mood, speaking style (e.g. petulant, old man accent, etc.) and paralinguistic elements (e.g. laughter, sighs) of the audio, and supports multiple languages such as Chinese, English, Sichuanese, Cantonese, etc. The core technology is the use of large-scale synthesis data training. The core technology lies in the use of large-scale synthetic data training to achieve highly expressive editing across voices without relying on traditional embedded a priori knowledge. Experiments show that the model outperforms similar tools such as Minimax-2.6-HD and DouBao-Seed-TTS-2.0 in tasks such as emotion editing. The model and accompanying tools are available to users via Hugging Face and GitHub.

Features of Step-Audio-EditX
- The world's first open source LLM audio editor:A single card with 8 GB can run, and 4×A800 gets theater-quality sound.
- 30+ Emotional Sliders: The intensity of anger, happiness, sadness, etc. can be iterated many times, and the more you tune it, the more you get on top of it.
- 15 Speaking Styles: Spoiled, whispered, old man, child, serious, generous, exaggerated one-click switch, support overlay.
- 10 class sublanguage token: Breaths, laughs, sighs, oh, en, hnn, uhm inserted with the same precision as subtitles.
- Zero sample TTS: A cue to clone any tone, text plus "[Cantonese]" "[Szechuan]" seconds out of the dialect.
- Full Link Open Source: Inference code, training code, 8bit quantized weights, Gradio Demo, HF Space all at once.
- Large interval data driven: No need for additional encoder/adapter, SFT+PPO realizes attribute decoupling and iterative control.
- Unified frameworkThe audio creation is a one-stop shop for TTS, emotion editing, style migration, noise reduction, and speech rate adjustment.
Core Benefits of Step-Audio-EditX
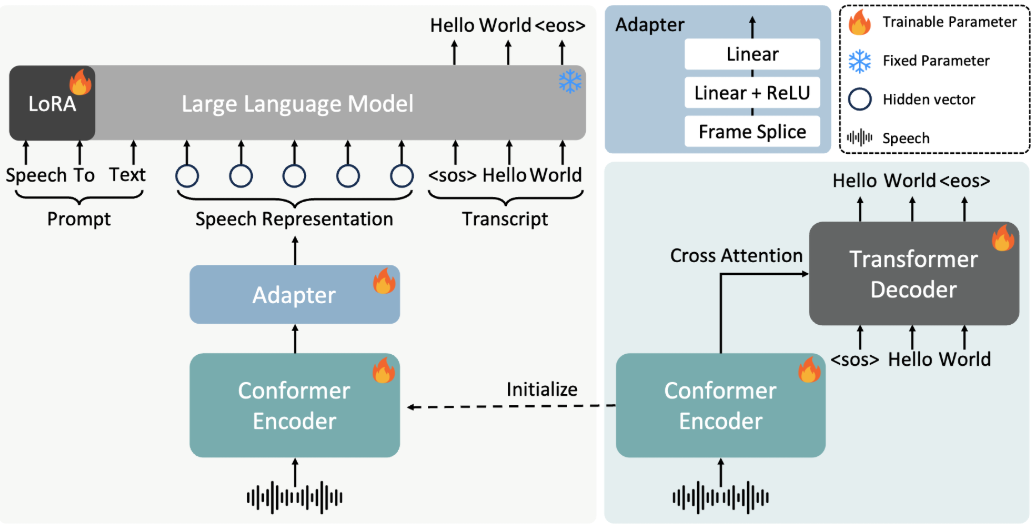
- The world's first open source LLM audio editorThe first to use the 3B large language model for speech editing, with open source code, weights, training scripts, and online demos, a single card with 8 GB of runtime, and 4×A800 for publication-grade sound quality.
- Large interval synthetic data drivenSFT+PPO: SFT+PPO is done only with "same text, different attribute" pairwise data, without additional encoder or adapter, realizing attribute decoupling and iterative control, and significantly reducing system complexity and inference cost.
- Three-axis fine-grained iterative control: Emotions (30+ tags), speaking styles (15+ tags), and paralanguage (10 types of tokens) can be overlaid or weakened multiple times, with a slider bar adjustment for intensity, the more you adjust, the more you get on top.
- Zero Sample TTS + Dialect CuttingThe following is an example of how to clone any tone: a single prompt can clone any tone; tags such as "[Szechuan]" and "[Cantonese]" are added in front of the text to output the dialect directly, without additional training.
- Outperforms closed-source competitors: In the Emotional Accuracy review, a single round of editing boosted the cloned speech of MiniMax-2.6-hd and Beanbag Seed-TTS-2.0 from a score of 50 to 70+, and it continues to lead after three rounds of its own iteration.
What is the official website for Step-Audio-EditX?
- Project website:: https://stepaudiollm.github.io/step-audio-editx/
- Github repository:: https://github.com/stepfun-ai/Step-Audio-EditX
- HuggingFace Model Library:: https://huggingface.co/stepfun-ai/Step-Audio-EditX
- arXiv Technical Paper:: https://arxiv.org/pdf/2511.03601
Who is Step-Audio-EditX for?
- Short Video / Film & TV Creators: Zero-sample clone timbre + emotional iteration to quickly generate multi-character, multi-emotion voiceovers, saving recording and post-production costs.
- Podcast / Audiobook ProducerOne-click overlay of "whispering/sweet/serious" styles, batch output of different versions of audio, and enhanced content immersion.
- Game Planning & Virtual Idol Operation: Insert laughs, breaths, and sighs in real time for NPCs and VTuber to create more vivid and interactive character voices.
- Advertising & Marketing TeamNo need to hire a voice actor, you can generate multiple versions of the same text in "passionate/high-end/dialect" to match different delivery channels.
- Educational Content and Language Learning Developers: Generate age-appropriate and localized readings using "old/child/dialect" tags to reduce teachers' recording workload.
- Intelligent customer service/voice assistant vendorsThe TTS can be edited directly on the original mood and style of the TTS, and can be quickly put on line for multiple scenarios, such as "soothing, promotional, and serious".
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...